模型訓練完成後,通常會被部署為推理服務。推理服務的調用量會隨著業務需求動態變化,因此需要伺服器具備彈性擴縮容能力以降低成本。在大規模高並發情境下,傳統部署方案往往難以滿足此類需求。阿里雲Container Service通過提供彈性節點池,支援基於彈性節點池部署模型推理服務,從而實現高效的Auto Scaling。本文將介紹如何基於ECS運行彈性推理工作負載。
前提條件
操作步驟
建立彈性節點池。
登入Container Service管理主控台,在左側導覽列選擇叢集列表。
在叢集列表頁面,單擊目的地組群名稱或者目的地組群右側操作列下的詳情。
在叢集管理頁左側導覽列,選擇。
在節點池頁面,單擊建立節點池。
在建立節點池對話方塊中配置參數,然後單擊確認配置。以下為重點參數配置,其他參數詳情請參見建立和管理節點池。
參數
說明
擴縮容模式
選中自動擴縮容模式,並配置相應執行個體數量。
付費類型
選擇搶佔式執行個體。
節點標籤
設定節點標籤的鍵為
inference,節點標籤的值為tensorflow。擴縮容策略
選擇成本最佳化策略,並設定按量執行個體所佔比例為30%。
將訓練模型上傳到OSS。具體操作,請參見控制台上傳檔案。
建立PV和PVC。
建立
pvc.yaml。apiVersion: v1 kind: PersistentVolume metadata: name: model-csi-pv spec: capacity: storage: 5Gi accessModes: - ReadWriteMany persistentVolumeReclaimPolicy: Retain csi: driver: ossplugin.csi.alibabacloud.com volumeHandle: model-csi-pv // 需要和PV名字一致。 volumeAttributes: bucket: "<Your Bucket>" url: "<Your oss url>" akId: "<Your Access Key Id>" akSecret: "<Your Access Key Secret>" otherOpts: "-o max_stat_cache_size=0 -o allow_other" --- apiVersion: v1 kind: PersistentVolumeClaim metadata: name: model-pvc spec: accessModes: - ReadWriteMany resources: requests: storage: 5Gi參數
說明
bucket
OSS的Bucket名稱,在OSS範圍內全域唯一。更多資訊,請參見儲存空間命名。
url
OSS檔案的訪問URL。更多資訊,請參見如何擷取單個或多個檔案的URL。
akId
訪問OSS的AccessKey ID和AccessKey Secret。建議使用RAM使用者訪問,更多資訊,請參見建立AccessKey。
akSecret
otherOpts
掛載OSS時支援定製化參數輸入。
-o max_stat_cache_size=0代表禁用屬性緩衝,每次訪問檔案都會從 OSS 中擷取最新的屬性資訊。-o allow_other代表允許其他使用者訪問掛載的檔案系統。
參數設定的更多資訊,請參見ossfs支援的設定參數選項。
執行以下命令,建立PV和PVC。
kubectl apply -f pvc.yaml
執行以下命令,部署推理服務。
arena serve tensorflow \ --name=bert-tfserving \ --model-name=chnsenticorp \ --selector=inference:tensorflow \ --gpus=1 \ --image=tensorflow/serving:1.15.0-gpu \ --data=model-pvc:/models \ --model-path=/models/tensorflow \ --version-policy=specific:1623831335 \ --limits=nvidia.com/gpu=1 \ --requests=nvidia.com/gpu=1參數
說明
selectorselector參數根據標籤選擇用於選擇TensorFlow訓練任務所需的Pods。本例設定為inference: tensorflow。limits: nvidia.com/gpu最多可使用的GPU卡數量。
requests: nvidia.com/gpu需要使用的GPU卡數量。
model-name模型的名稱。
model-path模型的訪問路徑。
建立HPA(Horizontal Pod Autoscaler)。HPA可以根據不同負載情況,自動調整Kubernetes中的Pod副本數量。
建立
hpa.yaml。apiVersion: autoscaling/v2beta1 kind: HorizontalPodAutoscaler metadata: name: bert-tfserving-hpa spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: bert-tfserving-202107141745-tensorflow-serving minReplicas: 1 maxReplicas: 10 metrics: - type: External external: metricName: sls_ingress_qps metricSelector: matchLabels: sls.project: "k8s-log-c210fbedb96674b9eaf15f2dc47d169a8" sls.logstore: "nginx-ingress" sls.ingress.route: "default-bert-tfserving-202107141745-tensorflow-serving-8501" targetAverageValue: 10參數
說明
scaleTargetRef設定當前HPA綁定的對象,配置為推理服務對應的Deployment名稱。
minReplicas最小副本數。
maxReplicas最大副本數。
sls.project叢集的記錄項目名稱,配置規則為
k8s-log-{cluster id}。sls.logstore日誌庫的名稱,預設值為
nginx-ingress。sls.ingress.routeIngress路由,配置規則為
{namespace}-{service name}-{service port}。metricname指標名稱,本文配置為
sls_ingress_qps。targetaverageValue觸發彈性擴容的QPS值。本文配置為
10,表示當QPS大於10時,觸發彈性擴容。執行以下命令,部署HPA。
kubectl apply -f hpa.yaml
配置公網Ingress。
通過
arena serve tensorflow命令部署的推理服務預設使用 ClusterIP類型,無法直接通過公網訪問。因此,需要為推理服務建立一個公網Ingress,以便實現便捷的訪問。登入Container Service管理主控台,在左側導覽列選擇叢集列表。
在叢集列表頁面,單擊目的地組群名稱,然後在左側導覽列,選擇。
在路由頁面上方,選擇推理服務所在的命名空間,然後單擊建立Ingress,配置如下參數。關於參數的更多資訊,請參見建立Nginx Ingress。
名稱:本文配置為
bert-tfserving。規則:
網域名稱:自訂網域名,例如:
test.example.com。路徑映射
路徑:不做配置,保留根路徑
/。匹配規則:預設(ImplementationSpecific)。
服務名稱:通過執行
kubectl get service命令擷取。連接埠:本文配置為8501。
- 路由建立成功後,您可以在路由頁面的規則列擷取到Ingress地址。

使用擷取的Ingress地址對推理服務進行壓測。
登入營運控制台。具體操作,請參見訪問AI營運控制台。
重要在登入營運控制台前,您需要安裝和配置訪問方式,具體步驟,請參見安裝雲原生AI套件。
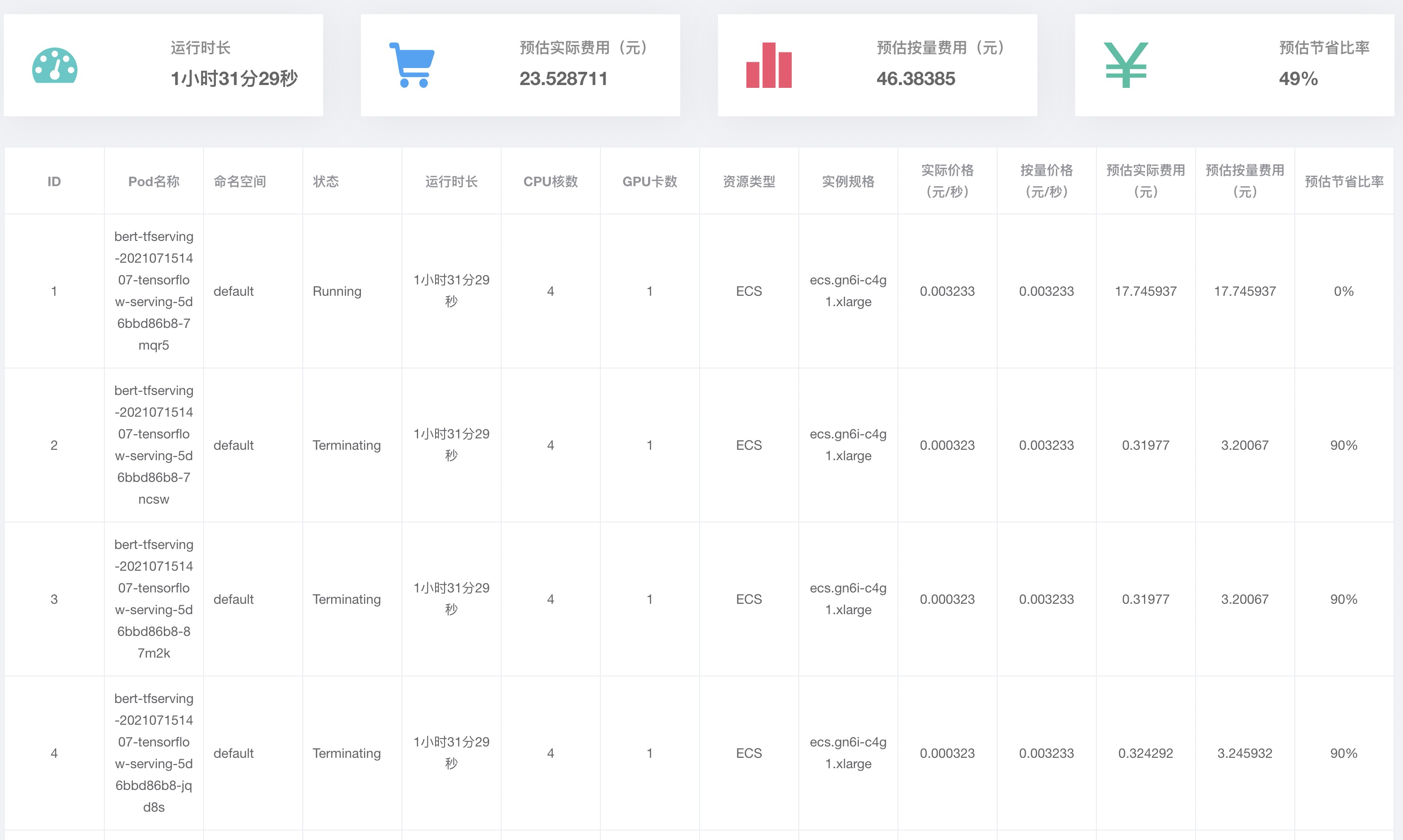
在營運控制台導覽列選擇,單擊推理任務頁簽,查看推理服務的詳情。
擴容得到的Pod,都運行在ECS執行個體上。其中既有隨用隨付執行個體,也有搶佔式執行個體(Spot),且數量比例等於建立節點池時配置的比例。