Prometheus是一款面向雲原生應用程式的監控工具,本文介紹如何在阿里雲Kubernetes上部署Prometheus。
背景資訊
本文將討論在Kubernetes叢集中如何高效地監控系統組件和資源實體。監控對象可分為以下兩類:
資源監控:涉及節點和應用的資源使用方式。在Kubernetes環境中,這包括節點的資源使用率、叢集的資源使用率及Pod的資源使用率等。
應用監控:應用內部指標的監控,例如即時統計應用的線上人數,並通過連接埠暴露來實現應用業務層級的監控與警示等。
監控對象具體為:
系統組件:包括Kubernetes叢集內建的組件,如API Server、cloud-controller-manager、etcd等。可通過在設定檔中進行設定來實現對這些組件的監控。
靜態資源實體:如節點的資源狀態和核心事件等,其監控可在設定檔中指明。
動態資源實體:例如Deployment、DaemonSet、Pod等,是Kubernetes中抽象的工作負載實體。為了監控這些實體,可以採用Prometheus監控部署方案。
自訂應用:針對需要定製化監控的資料和指標的應用情況,需具體設定以滿足獨特的監控需求,通過連接埠暴露和Prometheus監控方案相結合的方式實現。
步驟一:部署開源Prometheus監控
登入Container Service管理主控台,在左側導覽列選擇叢集列表。
在叢集列表頁面,單擊目的地組群名稱,然後在左側導覽列,選擇。
在Helm頁面,單擊建立,在Chart地區搜尋並選中ack-prometheus-operator,其他設定保持預設,然後單擊下一步。
組件預設安裝在monitoring命名空間,並以組件名稱發布應用。
如需自訂應用程式名稱和命名空間,請根據頁面提示設定。
在參數配置頁面中,選擇Chart版本為12.0.0,並設定相應參數,然後單擊確定。
12.0.0版本支援警示配置,您可以通過內建功能設定監控警示條件。
您根據實際需求自訂以下選擇性參數:
警示配置:支援DingTalk警示和郵件警示。
Prometheus掛載自訂ConfigMap:支援配置個人化需求。
將Dashboard檔案掛載到Grafana:支援自訂儀錶盤增強資料視覺效果。
安裝後,可在Helm頁面的Helm Chart列表中查看組件的安裝狀態。
步驟二:查看Prometheus採集任務
登入Container Service管理主控台,在左側導覽列選擇叢集列表。
在叢集列表頁面,單擊目的地組群名稱,然後在左側導覽列,選擇。
在服務頁面選擇ack-prometheus-operator部署的命名空間(預設為monitoring),單擊ack-prometheus-operator-prometheus操作列下的更新。
在對話方塊中,選擇負載平衡(LoadBalancer)作為服務類型。選擇建立資源,將訪問方式配置為公網訪問;計費方式配置為隨用隨付(PayByCLCU),按照頁面提示提交配置的修改。
關於CLB的計費說明,請參見CLB計費概述。
更新完成後,複製其外部IP地址,然後在瀏覽器中通過
IP地址:連接埠號碼(如47.XX.XX.12:9090)訪問Prometheus。在Prometheus頁面,選擇功能表列,查看所有採集任務。
如果所有任務的狀態為UP,表明所有採集任務均已正常運行。

在功能表列單擊Alerts,查看當前的警示規則。

步驟三:查看Grafana資料彙總
登入Container Service管理主控台,在左側導覽列選擇叢集列表。
在叢集列表頁面,單擊目的地組群名稱,然後在左側導覽列,選擇。
在服務頁面選擇ack-prometheus-operator部署的命名空間(預設為monitoring),單擊名稱為ack-prometheus-operator-grafana的操作列下的更新。
在對話方塊中,選擇負載平衡(LoadBalancer)作為服務類型。選擇建立資源,將訪問方式配置為公網訪問,計費方式配置為隨用隨付(PayByCLCU),按照頁面提示提交配置的修改。
關於CLB的計費說明,請參見CLB計費概述。
更新完成後,複製其外部IP地址,然後在瀏覽器中通過
IP地址:連接埠號碼(連接埠號碼預設為80,如47.XX.XX.12:80)訪問Grafana,按照頁面提示查看大盤。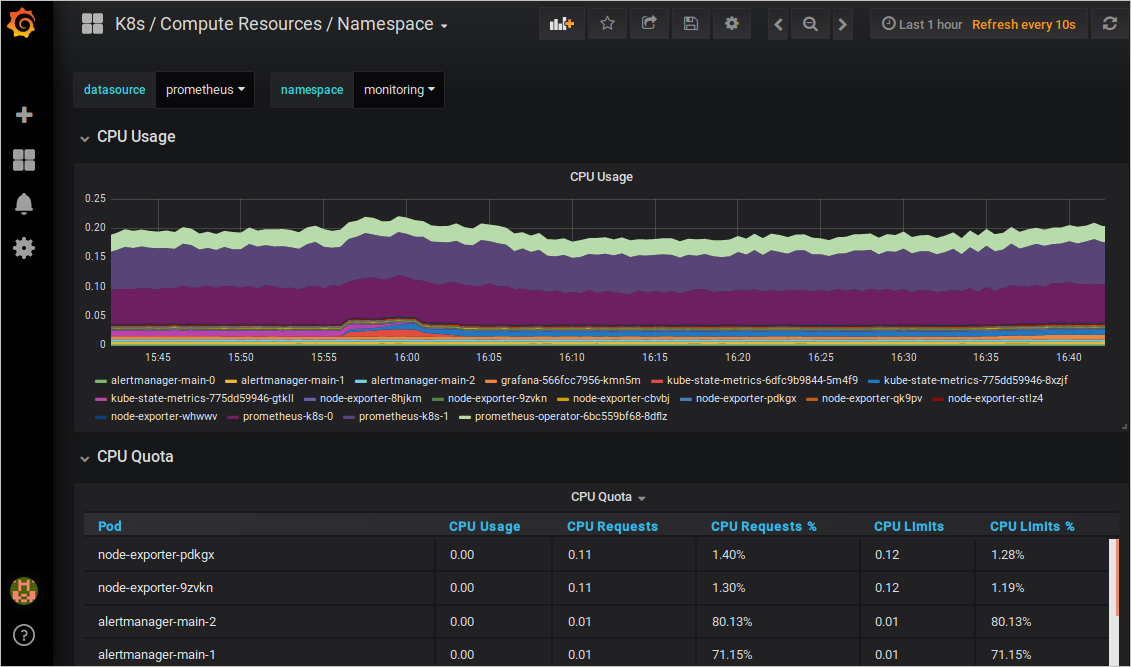
警示配置
ack-prometheus-operator支援DingTalk警示和郵件警示。配置入口如下。
登入Container Service管理主控台,在左側導覽列選擇叢集列表。
在叢集列表頁面,單擊目的地組群名稱,然後在左側導覽列,選擇。
單擊建立,定位ack-prometheus-operator,按照頁面提示進入下一步,在參數配置頁面選擇Chart 版本後,在參數地區參見下文進行配置。
如果您已經安裝了ack-prometheus-operator,也可以在Helm Chart列表單擊組件名稱,然後單擊參數配置進行配置。流程類似。
配置DingTalk警示
在設定檔中找到
dingtalk欄位,將enabled設定為true。在
token欄位中填入DingTalk的Webhook地址。擷取Webhook地址請參見使用DingTalk機器人:使用DingTalk機器人實現Kubernetes監控警示。
在
alertmanager的config欄位下的receiver配置中,填寫您在receivers中定義的DingTalk警示名稱(預設為webhook)。例如您有兩個DingTalk機器人,操作樣本如下:
替換DingTalk的
token配置在DingTalk機器人中,將Webhook地址分別替換為dingtalk1和dingtalk2的地址,即使用Webhook地址替換下圖中的
https://oapi.dingtalk.com/robot/send?access_token=xxxxxxxxxx。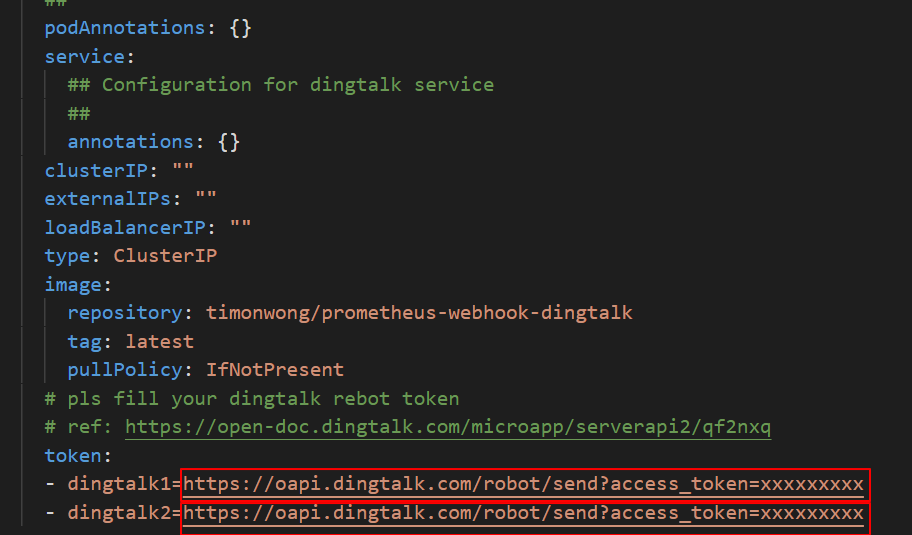
修改
receiversalertmanager的config欄位中找到receiver,填寫您receivers中對應的DingTalk警示名稱。本樣本中分別為webhook1和webhook2。修改URL的值
將URL中的值替換成實際的dingtalk的值,本例中為
dingtalk1和dingtalk2。
說明如需添加多個DingTalk機器人,請將前面的Webhook依次遞增。
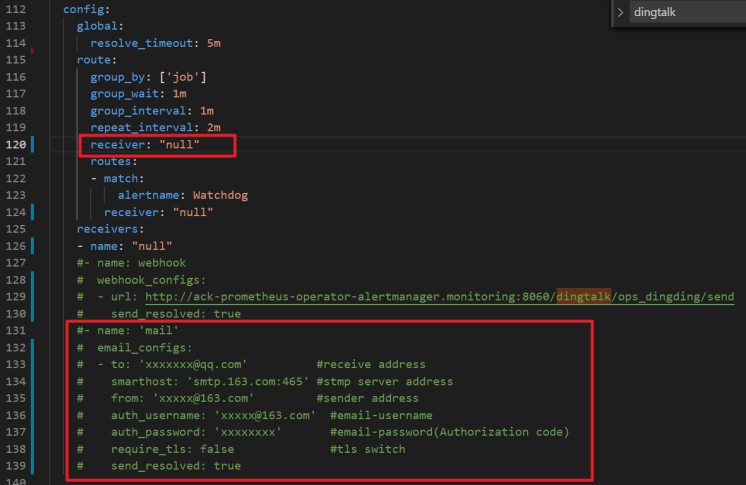
配置郵件警示
在關於郵件資訊的紅色選框內,補充完整的郵件資訊。
在設定檔的
alertmanager部分中找到config欄位,定位到receiver並填寫您在receivers中定義的郵件警示名稱(預設是mail)。
設定警示接收模板
您可以在alertmanager的templateFiles中自訂警示模板。樣本如下。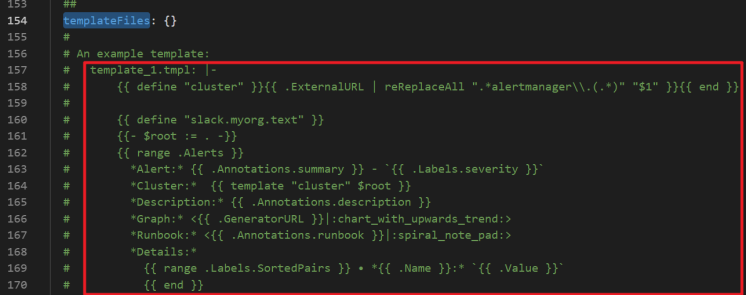
Prometheus掛載自訂ConfigMap
以下展示如何在 Prometheus 中通過名為 special-config 的 ConfigMap 掛載設定檔,並在 Pod 啟動時將其指定為 --config.file 參數。
建立ConfigMap。

掛載ConfigMap。
在參數配置頁面,在
configmaps欄位中添加以下內容,將指定的 ConfigMap 掛載到 Prometheus Pod 的/etc/prometheus/configmaps/路徑下。
prometheus的configmaps欄位配置樣本如下。
Grafana配置
將Dashboard檔案掛載到Grafana
如需將Dashboard檔案以ConfigMap的方式掛載到Grafana Pod中,您可以在參數配置嚮導中,定位extraConfigmapMounts欄位。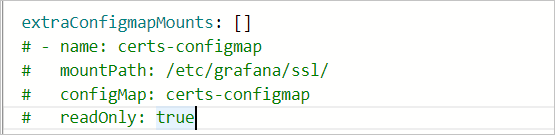 需確保:
需確保:
Dashboard以ConfigMap的形式存在於叢集中,且ConfigMap的Labels與其他ConfigMap格式保持一致。
在Grafana的
extraConfigmapMounts欄位中填入Dashboard的ConfigMap資訊和掛載資訊。mountPath:配置為/tmp/dashboards/。ConfigMap:自訂的ConfigMap的名稱。name:Dashboard的JSON名稱。
實現Dashboard持久化
如需Dashboard匯出到本地,您可將需要儲存的Dashboard匯出為JSON檔案,將其儲存到本地。更多資訊,請參見Grafana匯出。
登入Container Service管理主控台,在左側導覽列單擊叢集列表。
在叢集列表頁面,單擊目的地組群名稱,然後在左側導覽列,選擇。
定位ack-prometheus-operator,單擊右側的更新。在
grafana欄位的persistence選項中,按照下圖完成配置。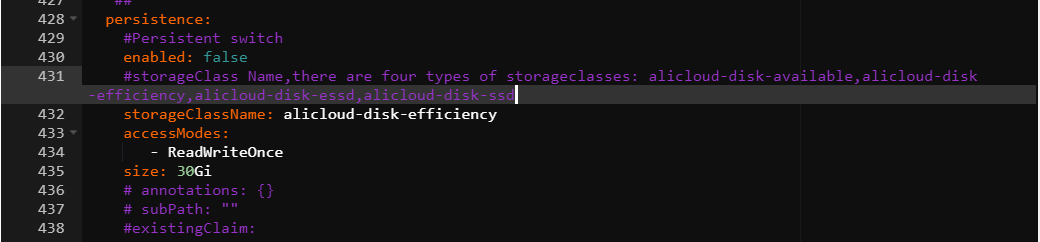
相關操作
卸載開源Prometheus
請根據Helm Chart版本參見以下流程卸載開源Prometheus,以避免資源殘留,繼而產生非預期行為。需要手動清理的資源套件括相關的Helm Release、命名空間、CRD和kubelet Service資源。
卸載ack-prometheus-operator但無法自動刪除關聯的kubelet Service是社區已知問題,需參見下文手動卸載。問題詳細描述,請參見#1523。
Chart v12.0.0
控制台
登入Container Service管理主控台,在左側導覽列選擇叢集列表。
在叢集列表頁面,單擊目的地組群名稱,然後在左側導覽列選擇不同介面,完成對應操作。
卸載Helm Release:選擇,在Helm Release列表的操作列,定位到ack-prometheus-operator對應的刪除,按照頁面提示完成刪除並清除發布記錄。
刪除命名空間:單擊命名空間與配額,在命名空間列表,定位並勾選monitoring,按照頁面提示完成刪除。
刪除CRD:選擇,單擊資源定義(CustomResourceDefinition)頁簽,按照頁面提示定位並刪除
monitoring.coreos.comAPI組下的所有CRD資源,包括:AlertmanagerConfig
Alertmanager
PodMonitor
Probe
Prometheus
PrometheusRule
ServiceMonitor
ThanosRuler
刪除kubelet Service:選擇網路 > 服務,按照頁面提示,在kube-system命名空間下定位並刪除ack-prometheus-operator-kubelet。
kubectl
卸載Helm release
helm uninstall ack-prometheus-operator -n monitoring刪除命名空間
kubectl delete namespace monitoring刪除CRD
kubectl delete crd alertmanagerconfigs.monitoring.coreos.com kubectl delete crd alertmanagers.monitoring.coreos.com kubectl delete crd podmonitors.monitoring.coreos.com kubectl delete crd probes.monitoring.coreos.com kubectl delete crd prometheuses.monitoring.coreos.com kubectl delete crd prometheusrules.monitoring.coreos.com kubectl delete crd servicemonitors.monitoring.coreos.com kubectl delete crd thanosrulers.monitoring.coreos.com刪除kubelet Service
kubectl delete service ack-prometheus-operator-kubelet -n kube-system
Chart v65.1.1
控制台
登入Container Service管理主控台,在左側導覽列選擇叢集列表。
在叢集列表頁面,單擊目的地組群名稱,然後在左側導覽列選擇不同介面,完成對應操作。
卸載Helm Release:選擇,在Helm Release列表的操作列,定位ack-prometheus-operator對應的刪除,按照頁面提示完成刪除並清除發布記錄。
刪除命名空間:單擊命名空間與配額,在命名空間列表,定位並勾選monitoring,按照頁面提示完成刪除。
刪除CRD:選擇,單擊資源定義(CustomResourceDefinition)頁簽,按照頁面提示定位並刪除
monitoring.coreos.comAPI組下的所有CRD資源,包括:AlertmanagerConfig
Alertmanager
PodMonitor
Probe
PrometheusAgent
Prometheus
PrometheusRule
ScrapeConfig
ServiceMonitor
ThanosRuler
刪除kubelet Service:選擇網路 > 服務,按照頁面提示,在kube-system命名空間下定位並刪除ack-prometheus-operator-kubelet。
kubectl
卸載Helm release
helm uninstall ack-prometheus-operator -n monitoring刪除命名空間
kubectl delete namespace monitoring刪除CRD
kubectl delete crd alertmanagerconfigs.monitoring.coreos.com kubectl delete crd alertmanagers.monitoring.coreos.com kubectl delete crd podmonitors.monitoring.coreos.com kubectl delete crd probes.monitoring.coreos.com kubectl delete crd prometheusagents.monitoring.coreos.com kubectl delete crd prometheuses.monitoring.coreos.com kubectl delete crd prometheusrules.monitoring.coreos.com kubectl delete crd scrapeconfigs.monitoring.coreos.com kubectl delete crd servicemonitors.monitoring.coreos.com kubectl delete crd thanosrulers.monitoring.coreos.com刪除kubelet Service
kubectl delete service ack-prometheus-operator-kubelet -n kube-system
設定警示壓制
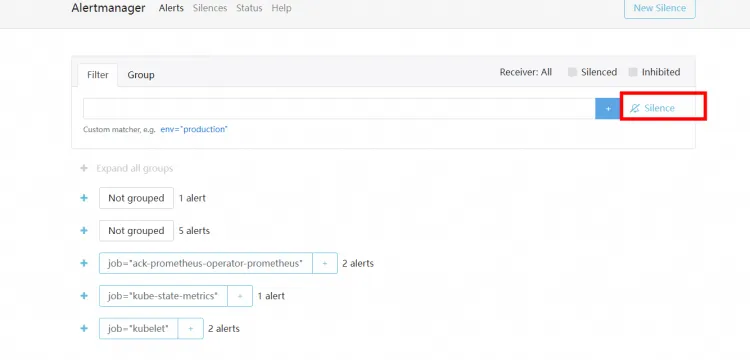
您可通過配置靜默規則(Silence Rule) 特定警示進行壓制。當警示與規則中的條件匹配時,對應警示不會發送通知或啟用,直至壓制時間結束或壓制規則被手動刪除。
執行以下命令,將 Alertmanager 暴露到本地 9093 連接埠,並允許外部存取。
kubectl --address 0.0.0.0 port-forward svc/alertmanager-operated 9093 -n monitoring將EIP綁定至ECS執行個體,然後在瀏覽器中使用
<EIP>:9093進行訪問。訪問測試時,請確保ECS執行個體安全性群組已允許存取您的本機IP和9093連接埠。具體操作,請參見添加安全性群組規則。
單擊Silence,按照頁面提示設定警示壓制。
常見問題
DingTalk配置後,沒有收到警示
擷取DingTalk的webhook地址。請參見事件監控。
找到dingtalk欄位,將enabled設定為true,將Token欄位填入DingTalk的webhook地址。請參見警示配置中的DingTalk警示配置。
部署prometheus-operator時報錯
報錯資訊如下
Can't install release with errors: rpc error: code = Unknown desc = object is being deleted: customresourcedefinitions.apiextensions.k8s.io "xxxxxxxx.monitoring.coreos.com" already exists在卸載prometheus-operator的時候沒有將上一次部署的自訂資源(CRD)及時清理掉,執行如下命令,刪除CRD並重新部署。
kubectl delete crd prometheuses.monitoring.coreos.com
kubectl delete crd prometheusrules.monitoring.coreos.com
kubectl delete crd servicemonitors.monitoring.coreos.com
kubectl delete crd alertmanagers.monitoring.coreos.com郵件警示沒有生效
郵件警示沒有生效,有可能是因為smtp_auth_password填寫的是您的登入密碼,而非授權碼。另外SMTP的伺服器位址需要加連接埠號碼。
單擊YAML更新時,出現當前叢集暫時無法訪問,請稍後重試或提交工單反饋
此問題原因是tiller的設定檔過大,導致的叢集無法訪問,您可以先將部分注釋刪除,再將設定檔以ConfigMap形式,掛載到pod中,目前prometheus-operator只支援prometheus和alertmanager pod的掛載,詳情請參見Prometheus掛載自訂ConfigMap中的方法二。
部署prometheus-operator後,如何開啟其中的功能
當部署好prometheus-operator後,如果要開啟部分功能,在叢集資訊頁面,選擇,在ack-prometheus-operator右側,單擊更新,找到對應的開關,進行相應的設定,然後單擊確定開啟您想要的功能。
TSDB和阿里雲雲端硬碟如何選擇。
TSDB支援的地區比較少,而阿里雲雲端硬碟是全域支援,資料回收策略請參見以下配置。
Grafana Dashboard顯示有問題
在叢集資訊頁面選擇,在ack-prometheus-operator右側,單擊更新,查看clusterVersion的值是否為正確的叢集版本。Kubernetes叢集是1.16以前的版本,這裡請填寫1.14.8-aliyun.1,1.16及以後的版本,請填寫1.16.6-aliyun.1。
刪除ack-prometheus的命名空間後,重新安裝ack-prometheus失敗
只刪除ack-prometheus的命名空間,會導致資源刪除後有殘留配置,影響再次安裝。您可以執行以下操作,刪除殘餘配置。
刪除RBAC許可權。
刪除ClusterRole。
kubectl delete ClusterRole ack-prometheus-operator-grafana-clusterrole kubectl delete ClusterRole ack-prometheus-operator-kube-state-metrics kubectl delete ClusterRole psp-ack-prometheus-operator-kube-state-metrics kubectl delete ClusterRole psp-ack-prometheus-operator-prometheus-node-exporter kubectl delete ClusterRole ack-prometheus-operator-operator kubectl delete ClusterRole ack-prometheus-operator-operator-psp kubectl delete ClusterRole ack-prometheus-operator-prometheus kubectl delete ClusterRole ack-prometheus-operator-prometheus-psp刪除ClusterRoleBinding。
kubectl delete ClusterRoleBinding ack-prometheus-operator-grafana-clusterrolebinding kubectl delete ClusterRoleBinding ack-prometheus-operator-kube-state-metrics kubectl delete ClusterRoleBinding psp-ack-prometheus-operator-kube-state-metrics kubectl delete ClusterRoleBinding psp-ack-prometheus-operator-prometheus-node-exporter kubectl delete ClusterRoleBinding ack-prometheus-operator-operator kubectl delete ClusterRoleBinding ack-prometheus-operator-operator-psp kubectl delete ClusterRoleBinding ack-prometheus-operator-prometheus kubectl delete ClusterRoleBinding ack-prometheus-operator-prometheus-psp
刪除CRD。
kubectl delete crd alertmanagerconfigs.monitoring.coreos.com kubectl delete crd alertmanagers.monitoring.coreos.com kubectl delete crd podmonitors.monitoring.coreos.com kubectl delete crd probes.monitoring.coreos.com kubectl delete crd prometheuses.monitoring.coreos.com kubectl delete crd prometheusrules.monitoring.coreos.com kubectl delete crd servicemonitors.monitoring.coreos.com kubectl delete crd thanosrulers.monitoring.coreos.com