您可以將備份中心接入Prometheus,通過Prometheus監控備份倉庫及任務狀態,實現即時監控。本文介紹如何監控備份中心和配置警示。
前提條件
已安裝migrate-controller備份服務元件,且組件為v1.7.10及以上版本。具體操作,請參見安裝migrate-controller備份服務元件並配置許可權、升級組件。
1.20以下版本的叢集無法升級至最新版本的migrate-controller組件,如需使用備份中心監控功能,請先升級叢集版本。具體操作,請參見手動升級叢集。
叢集已開啟阿里雲Prometheus監控。
計費說明
migrate-controller備份服務元件會將監控指標發送至阿里雲Prometheus服務,這些指標將被視為自訂指標。使用自訂指標會產生額外的費用。
為避免產生額外的費用,建議啟用前閱讀計費概述,瞭解自訂指標的收費策略。費用將根據您的叢集規模和應用數量等因素產生變動。您可以通過資源消耗統計,監控和管理您的資源使用方式。
將備份中心接入Prometheus
您可以通過阿里雲Prometheus監控當前叢集關聯的備份倉庫及備份任務的狀態。
登入ARMS控制台。
在左側導覽列,單擊接入中心,在基礎設施頁簽,搜尋Ack 備份中心服務監控,然後單擊選中Ack 備份中心服務監控進入接入介面。
在開始接入頁簽,選擇已經安裝了備份中心的目標Container Service叢集,然後單擊確定。
接入狀態檢查完成後,您可以在Container Service控制台或ARMS控制台查看大盤資料。
查看備份中心監控大盤
大盤入口
登入Container Service管理主控台,在左側導覽列選擇叢集列表。
在叢集列表頁面,單擊目的地組群名稱,然後在左側導覽列,選擇。
在Prometheus監控頁面,單擊其他頁簽,在ACK BackupCenter下查看備份中心監控大盤。
通過ARMS控制台查看監控大盤的相關操作,請參見開箱即用大盤。
大盤介紹
備份中心監控大盤包含備份倉庫監控資訊(Backup Locations)、備份任務監控資訊(Backup Operation Status)以及工作群組件狀態監控資訊(Addon Status)三部分。
Backup Locations
該大盤用於監控備份倉庫的基本資料,展示了叢集當前關聯的備份倉庫詳情(Backuplocation Detail)。
備份倉庫用於存放建立的備份,顯示叢集備份中心與OSS Bucket的關聯資訊。當對應備份倉庫狀態為Available時,才能通過備份中心完成備份、製作快照、恢複等任務。Backuplocation Detail的監控指標如下:
監控指標 | 說明 |
Backuplocation | 備份倉庫名稱。 |
OSS Bucket | 備份倉庫關聯的OSS Bucket名稱。 |
Region | OSS Bucket所在地區,例如cn-hangzhou。 |
NetworkPolicy | 備份倉庫與OSS Bucket間的網路連通方式,取值:
|
Phase | 備份倉庫的狀態,取值:
|
Backup Operation Status
該大盤用於監控備份任務的狀態,包含備份任務總覽(Backup Overview)和失敗狀態的備份任務詳情(Failed Backup Detail)兩部分。

Backup Overview:通過柱狀圖展示了該叢集的各個備份倉庫中建立備份任務的數量,其中,備份任務的來源為通過立即備份建立、或通過備份計劃定時建立的單個備份。X軸為備份倉庫名稱,Y軸為備份任務數量。Backup Overview的監控指標如下:
監控指標
說明
Backup(Failed)
通過紅色柱狀圖展示失敗狀態的備份任務數量。
Backup(Completed)
通過綠色柱狀圖展示成功狀態的備份任務數量。
Failed Backup Detail:通過表格展示了該叢集中處於失敗狀態的備份任務的基本資料。Failed Backup Detail的監控指標如下:
監控指標
說明
Backup
備份任務名稱。
Backuplocation
備份任務所處的備份倉庫名稱。
BackupType
備份任務的備份類型,取值:
AppBackup:僅備份應用,即YAML備份。
AppAndPvBackup:備份應用及資料,即YAML和PV內資料備份。
DataType
資料備份的類型,取值:
snapshot:備份的PV為純雲端硬碟儲存。
hbr:備份的PV為HostPath本機存放區、NAS或OSS等類型的檔案儲存體。
all:備份的PV同時包含雲端硬碟儲存及檔案系統儲存。
none:開啟了資料備份,但所選命名空間下未使用PV儲存。
FromSchedule
備份任務來源。
空值:由立即備份建立。
非空值:由備份計劃定時建立,取值為對應備份計劃名稱。
Addon Status
該大盤用於監控工作群組件csdr-controller和csdr-velero的工作狀態。您需要確保這些工作群組件的正常運行,才能通過備份中心進行備份、製作快照、恢複等操作。
當備份中心組件migrate-controller安裝完成後會對叢集進行預檢查,檢查完成後,將在備份中心工作的命名空間csdr下部署工作群組件csdr-controller和csdr-velero。
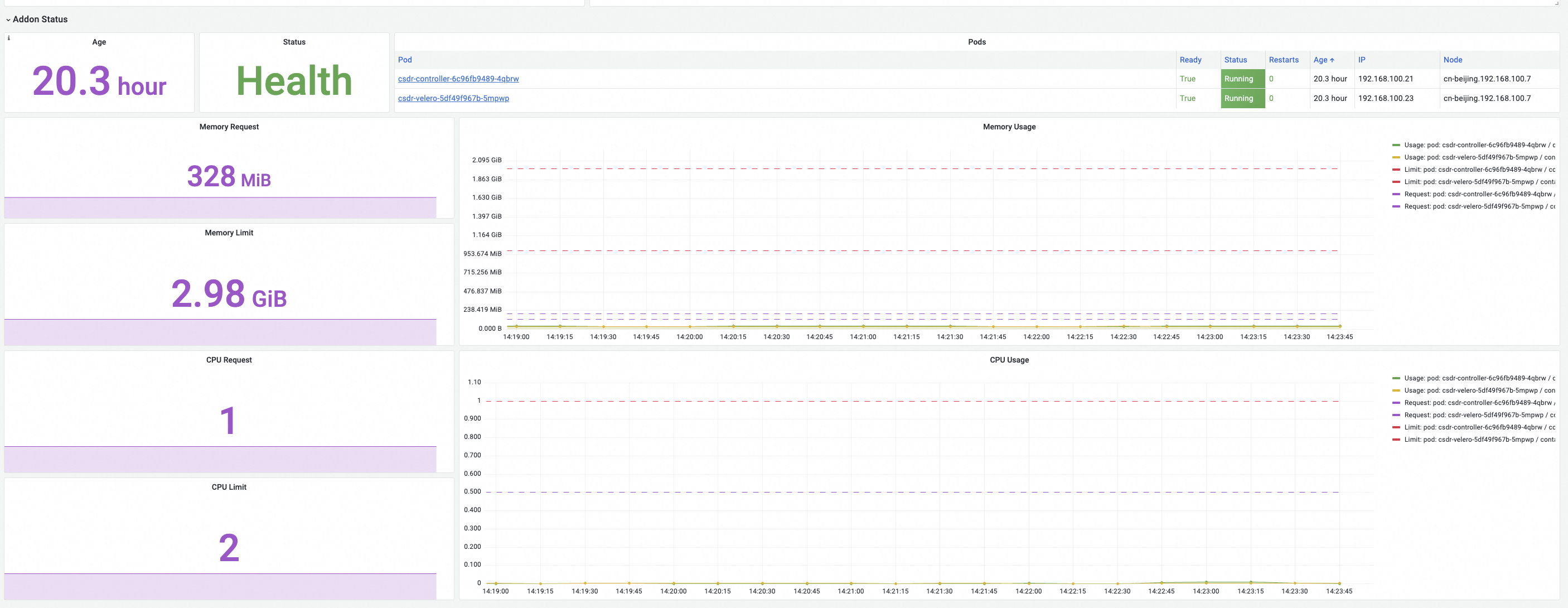
備份中心的工作群組件通過Deployment(Pods)形式展示,包含csdr-controller與csdr-velero兩個組件。Addon Status的監控指標如下:
監控指標 | 說明 |
Age | 工作群組件的建立時間長度。 |
Status | 工作群組件的狀態,取值:
|
Pods | 工作群組件Pods詳情。 |
Memory Request | 為工作群組件預留的記憶體資源額度。 |
CPU Request | 為工作群組件預留的CPU資源額度。 |
Memory Limit | 工作群組件所需記憶體的資源上限。 |
CPU Limit | 工作群組件所需CPU的資源上限。 |
配置備份任務失敗警示
備份任務失敗警示是基於事件的警示,與備份任務對應的CRD為csdr.alibabacloud.com資源群組下的applicationbackups,當備份任務失敗時,同名資源將建立Warn事件。
查詢備份任務失敗的Warn事件
執行以下命令,查詢失敗的備份任務的Warn事件。
kubectl -n csdr get events --field-selector='type!=Normal' 預期輸出:
VaultError: backup vault is unavailable: oss: service returned error: StatusCode=403, ErrorCode=AccessDenied, ErrorMessage="The bucket you access does not belong to you.", RequestId=668516BC35F915******其中,VaultError為備份任務失敗的原因。
配置叢集重要事件警示規則感知備份任務失敗Warn事件
通過叢集警示配置功能進行配置。具體操作,請參見Container Service警示管理。
如何定位監控資料異常問題
查詢工作群組件不存在或狀態異常(UnHealth)的原因
安裝備份中心後,工作群組件不存在或反覆部署。
執行以下命令,查詢migrate-controller組件運行狀態。
kubectl -n kube-system get pod -l app=migrate-controller若組件處於
CrashLoopBackOff狀態或反覆重啟,即叢集預檢查不通過,通常是由於叢集使用了Flexvolume儲存外掛程式或註冊叢集未配置相關許可權,相關排查請參見備份中心FAQ及註冊叢集。工作群組件狀態長期為UnHealth,Pods儀錶盤無資料或狀態異常。
工作群組件的Pod無法正常啟動,相關排查請參見Pod異常問題排查。
工作群組件狀態為Health,但Pods儀錶盤Restarts次數不為0。
csdr-velero的記憶體使用量情況在備份期間將出現峰值,容易發生OOM(Out of Memory)問題,導致組件異常退出重啟,您可以提高記憶體資源使用上限來解決。
說明備份過程中,若工作群組件的Pod異常退出,將導致任務失敗或長期處於InProgress狀態。
查詢備份倉庫狀態異常(Unavailable)的原因
執行以下命令,查詢錯誤Message。
其中,<unavailable-backuplocation-name>為異常狀態備份倉庫的名稱。
kubectl -n csdr describe backuplocation <unavailabe-backuplocation-name> 關於備份倉庫異常狀態處理,請參見備份中心FAQ。
查詢備份任務失敗(Failed)的原因
命令列方式查詢
執行以下命令,查詢錯誤Message。
其中,<failed-applicationbackup-name>為失敗的備份任務的名稱。
kubectl -ncsdr describe applicationbackup <failed-applicationbackup-name> 關於備份任務失敗處理,請參見備份中心FAQ。
控制台方式查詢
登入Container Service管理主控台,在左側導覽列選擇叢集列表。
在叢集列表頁面,單擊目的地組群名稱,然後在左側導覽列,選擇。
在應用備份頁面,單擊備份記錄頁簽,定位對應的備份任務,單擊狀態列的Failed查看錯誤Message。