Container Service for Kubernetes支援AHPA(Advanced Horizontal Pod Autoscaler)彈效能力。AHPA可以根據歷史資料進行學習和分析,提前預測未來的資源需求,並據此動態調整Pod副本數量,確保在業務高峰到來之前完成資源的擴容和預熱操作,從而提高系統的響應速度和穩定性。同時,當預測到業務低穀時,也會適時縮容以節省資源成本。
前提條件
已開啟Prometheus監控,且Prometheus監控中至少已收集7天應用歷史資料(CPU、Memory等)。關於開啟Prometheus監控的具體操作,請參見接入與配置阿里雲Prometheus監控。
步驟一:安裝AHPA Controller
登入Container Service管理主控台,在左側導覽列選擇叢集列表。
在叢集列表頁面,單擊目的地組群名稱,然後在左側導覽列,單擊組件管理。
在組件管理頁面,定位AHPA Controller組件,然後在組件卡片上單擊安裝,按照頁面提示完成組件的安裝。
步驟二:配置Prometheus資料來源
登入ARMS控制台。
在左側導覽列選擇,進入可觀測監控 Prometheus 版的執行個體列表頁面。
在執行個體列表頁面頂部,選擇Prometheus執行個體所在的地區,然後單擊目標執行個體名稱(與ACK叢集同名)。
在當前設定頁面,在HTTP API地址(Grafana 讀取地址)地區記錄如下配置項的值。
(可選)如果開啟了Token,則需要設定訪問Token。
查看並記錄內網地址(Prometheus URL)。
在ACK叢集中設定Prometheus查詢地址。
使用以下內容,建立application-intelligence.yaml。
prometheusUrl:ARMS Prometheus訪問地址。token:Prometheus的訪問Token。
apiVersion: v1 kind: ConfigMap metadata: name: application-intelligence namespace: kube-system data: prometheusUrl: "http://cn-hangzhou-intranet.arms.aliyuncs.com:9443/api/v1/prometheus/da9d7dece901db4c9fc7f5b9c40****/158120454317****/cc6df477a982145d986e3f79c985a****/cn-hangzhou" token: "eyJhxxxxx"說明如需查看AHPA對應的Prometheus監控大盤,您還需要在此ConfigMap中配置如下欄位:
prometheus_writer_url:設定Remote Write內網地址。prometheus_writer_ak: 設定阿里雲帳號的AccessKeyID。prometheus_writer_sk:設定阿里雲帳號的AccessKeySecret。
更多資訊,請參見為AHPA開啟Prometheus大盤。
執行如下命令,部署application-intelligence。
kubectl apply -f application-intelligence.yaml
步驟三:部署測試服務
測試服務包括fib-deployment、fib-svc以及用於類比請求峰穀服務fib-loader,同時部署一個HPA資源用於與AHPA進行結果對比。
使用以下內容,建立demo.yaml。
apiVersion: apps/v1
kind: Deployment
metadata:
name: fib-deployment
namespace: default
annotations:
k8s.aliyun.com/eci-use-specs: "1-2Gi"
spec:
replicas: 1
selector:
matchLabels:
app: fib-deployment
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
creationTimestamp: null
labels:
app: fib-deployment
spec:
containers:
- image: registry.cn-huhehaote.aliyuncs.com/kubeway/knative-sample-fib-server:20200820-171837
imagePullPolicy: IfNotPresent
name: user-container
ports:
- containerPort: 8080
name: user-port
protocol: TCP
resources:
limits:
cpu: "1"
memory: 2000Mi
requests:
cpu: "1"
memory: 2000Mi
---
apiVersion: v1
kind: Service
metadata:
name: fib-svc
namespace: default
spec:
ports:
- name: http
port: 80
protocol: TCP
targetPort: 8080
selector:
app: fib-deployment
sessionAffinity: None
type: ClusterIP
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: fib-loader
namespace: default
spec:
progressDeadlineSeconds: 600
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
app: fib-loader
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
creationTimestamp: null
labels:
app: fib-loader
spec:
containers:
- args:
- -c
- |
/ko-app/fib-loader --service-url="http://fib-svc.${NAMESPACE}?size=35&interval=0" --save-path=/tmp/fib-loader-chart.html
command:
- sh
env:
- name: NAMESPACE
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: metadata.namespace
image: registry.cn-huhehaote.aliyuncs.com/kubeway/knative-sample-fib-loader:20201126-110434
imagePullPolicy: IfNotPresent
name: loader
ports:
- containerPort: 8090
name: chart
protocol: TCP
resources:
limits:
cpu: "8"
memory: 16000Mi
requests:
cpu: "2"
memory: 4000Mi
---
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: fib-hpa
namespace: default
spec:
maxReplicas: 50
minReplicas: 1
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: fib-deployment
targetCPUUtilizationPercentage: 50
---步驟四:部署AHPA
您可以通過提交AdvancedHorizontalPodAutoscaler資源配置彈性策略,具體操作如下。
使用以下內容,建立ahpa-demo.yaml。
apiVersion: autoscaling.alibabacloud.com/v1beta1 kind: AdvancedHorizontalPodAutoscaler metadata: name: ahpa-demo spec: scaleStrategy: observer metrics: - type: Resource resource: name: cpu target: type: Utilization averageUtilization: 40 scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: fib-deployment maxReplicas: 100 minReplicas: 2 stabilizationWindowSeconds: 300 prediction: quantile: 0.95 scaleUpForward: 180 instanceBounds: - startTime: "2021-12-16 00:00:00" endTime: "2031-12-16 00:00:00" bounds: - cron: "* 0-8 ? * MON-FRI" maxReplicas: 15 minReplicas: 4 - cron: "* 9-15 ? * MON-FRI" maxReplicas: 15 minReplicas: 10 - cron: "* 16-23 ? * MON-FRI" maxReplicas: 20 minReplicas: 15部分參數說明如下:
參數
是否必選
說明
scaleTargetRef
是
指定目標Deployment。
metrics
是
用於配置彈性Metrics,當前支援CPU、GPU、Memory、QPS、RT等指標。
target
是
目前閾值,例如
averageUtilization: 40表示CPU使用目標閾值為40%。scaleStrategy
否
用於設定Auto Scaling模式。預設值為observer。
auto:由AHPA負責擴縮容。
observer:只觀察,但不進行真正的伸縮動作。您可以通過這種方式觀察AHPA的工作是否符合預期。
proactive:只生效主動預測。
reactive:只生效被動預測。
maxReplicas
是
最大擴容執行個體數。
minReplicas
是
最小縮容執行個體數。
stabilizationWindowSeconds
否
縮容冷卻時間,預設300秒。
prediction. quantile
是
預測分位元,業務指標實際值低於設定目標值的機率越大表示越保守。取值範圍為0~1,支援兩位小數,預設值為0.99。推薦取值範圍為0.90~0.99。
prediction. scaleUpForward
是
Pod達到Ready狀態所需要的時間(冷啟動時間)。
instanceBounds
否
擴縮容時間段執行個體數邊界。
startTime:表示開始時間。
endTime:表示結束時間。
instanceBounds. bounds. cron
否
用於配置定時任務,Cron運算式表示一個時間集合,使用5個空格分隔的欄位表示,例如
- cron: "* 0-8 ? * MON-FRI"表示每月星期一到星期五晚上12點到早上8點執行任務。Cron運算式的欄位解釋如下,更多資訊,請參見Cron定時任務。
欄位名
是否必須
允許的值
允許的特定字元
分(Minutes)
是
0~59
* / , -
時(Hours)
是
0~23
* / , -
日(Day of Month)
是
1~31
* / , – ?
月(Month)
是
1~12或JAN~DEC
* / , -
星期(Day of Week)
否
0~6或SUN~SAT
* / , – ?
說明月(Month)和星期(Day of Week)欄位的值不區分大小寫,例如
SUN、Sun和sun效果一致。若星期(Day of Week)欄位未配置,預設為
*。特定字元說明:
*:表示所有可能的值。/:表示指定數值的增量。,:表示列出枚舉值。-:表示範圍。?:表示不指定值。
執行以下命令,建立AHPA彈性策略。
kubectl apply -f ahpa-demo.yaml
步驟五:查看預測結果
查看AHPA彈性預測效果,可以為AHPA開啟Prometheus大盤。
由於預測需要歷史7天的資料,上述樣本部署完成之後,需要運行7天才可以看到預測結果。如果已有線上的應用可以直接在AHPA中指定該應用即可。
本文以Auto Scaling模式配置為observer模式(觀察者模式)為例,與使用HPA策略(可作為應用運行實際所需的資源量進行參考)進行對比,觀察AHPA預測結果是否符合預期。
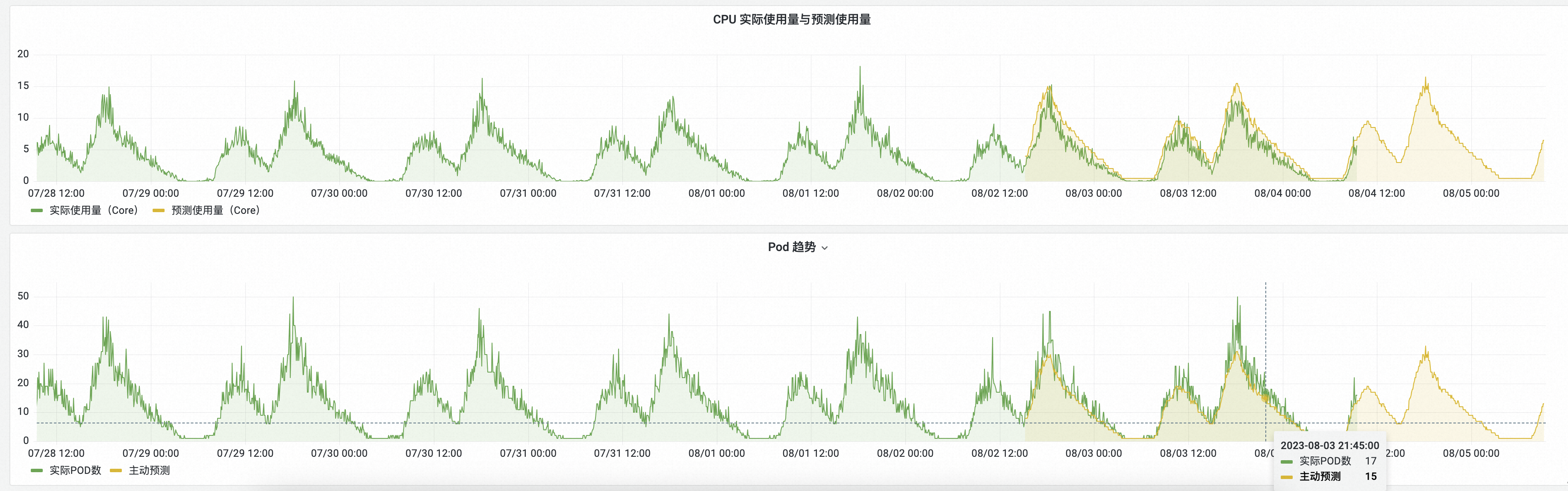
CPU實際使用量與預測使用量:綠色表示HPA實際的CPU使用量,黃色表示AHPA預測出來的CPU使用量。
黃色曲線大於綠色,表明預測的CPU容量充足。
黃色曲線提前於綠色,表明提前準備好了所需資源。
Pod趨勢:綠色表示使用HPA實際的擴縮容Pod數,黃色表示AHPA預測出來的擴縮容Pod數。
黃色曲線小於綠色,表明預測的Pod數量更少。
黃色曲線比綠色更為平滑,表明通過AHPA擴縮容波動更平緩,提升業務穩定性。
通過預測結果表明,彈性預測趨勢符合預期。若經過觀察後,符合預期,您可以將Auto Scaling模式設定為auto,由AHPA負責擴縮容。
相關文檔
如需通過阿里雲Prometheus監控觀測GPU指標,實現基於GPU指標的AHPA彈性預測,請參見基於GPU指標實現AHPA彈性預測。
如需查看阿里雲Prometheus監控提供的監控大盤,請參見為AHPA開啟Prometheus大盤。