ログ処理は、リアルタイムコンピューティング、データウェアハウジング、およびオフラインコンピューティングを対象としています。 このトピックでは、アップストリームとダウンストリームのビジネスシステムに障害が発生したり、トラフィック量が変動したりする場合でも、リアルタイムコンピューティングシナリオでデータの損失や繰り返し消費なしにログを順番に処理する方法について説明します。
このトピックでは、銀行の営業日を例として、ログの処理方法を説明します。 このトピックでは、Simple Log ServiceのLogstoreコンシューマーグループをSpark StreamingまたはStorm Spoutと一緒に使用してログを処理する方法についても説明します。
ログに抽象化できるデータ
半世紀前、船長とオペレーターは厚いノートブックに丸太を記録しました。 今日、コンピューターでは、あらゆる場所でログを生成および消費できます。 たとえば、GPS、注文、およびサーバー、ルーター、センサーなどのさまざまなデバイスは、さまざまな視点から私たちの生活を記録します。 ログの時刻を記録するタイムスタンプを含めるために使用されるキャプテン。 キャプテンは、テキスト、画像、気象条件、航海方向など、他のコンテンツもログに記録しました。 半世紀後、さまざまなシナリオでログが生成されます。 たとえば、注文、支払い、ページ訪問、およびデータベース操作のログが記録されます。
コンピュータサイエンスでは、一般的なログには、メトリック、リレーショナルおよびNoSQLデータベースのバイナリログ、イベント、監査ログ、およびアクセスログが含まれます。
このトピックでは、銀行でのユーザー操作は、名前、アカウント、操作時間、操作タイプ、およびトランザクション金額を含むログと見なされます。
例:
2016-06-28 08:00:00 Alice deposited USD 1,000
2016-06-27 09:00:00 Bob withdrew USD 20,000Logstoreデータモデル
このセクションでは、Simple Log ServiceのLogstoreデータモデルを例として使用します。
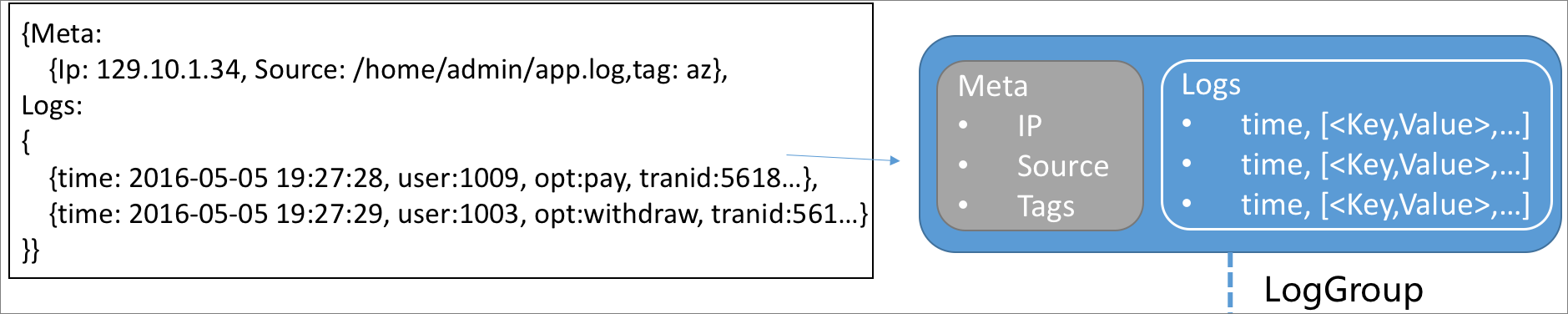
ログは、時点とキーと値のペアのグループで構成されます。
ロググループは、IPアドレスやデータソースなど、同じメタデータを持つログのコレクションです。
ログとロググループの関係を次の図に示します。
シャードは、ロググループの基本的な読み取りおよび書き込み単位です。 シャードは、48時間の先入れ先出し (FIFO) キューと見なすことができます。 各シャードでは、10メガバイト/秒のレートでデータを読み取り、5メガバイト/秒のレートでデータを書き込むことができます。 シャードの論理範囲は、BeginKeyパラメーターとEndKeyパラメーターによって指定されます。 この範囲では、他のシャードとは異なる種類のデータを含むことができます。
Logstore には、同じタイプのログデータが格納されます。 各Logstoreは、範囲が
[0000,FFFF ..)の1つ以上のシャードで構成されています。プロジェクトは、Logstore のコンテナを指します。
次の図は、ログ、ロググループ、シャード、ログストア、およびプロジェクト間の関係を示しています。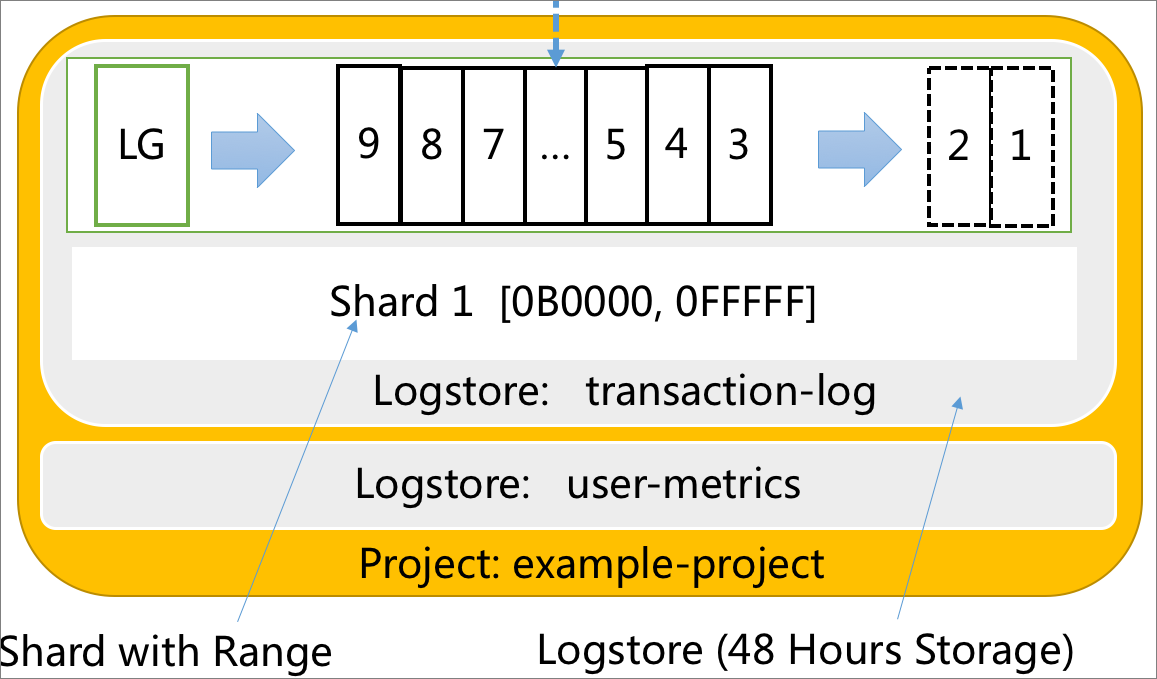
銀行での営業日
たとえば、19世紀のある日、ある都市の何人かのユーザーが銀行に行き、お金を預けたり引き出したりしました。 銀行には複数の銀行員がいます。 当時、コンピュータが発明されていなかったため、トランザクションデータをリアルタイムで同期させることができませんでした。 各店員は取引データを勘定帳に記録し、毎晩取引データを確認した。 このケースでは、ユーザーがデータの作成者であり、預金と引き落としはユーザーの操作とされ、銀行員がデータの取得者となります。
分散ログ処理システムでは、クラークは、固定メモリおよびコンピューティング能力を有するスタンドアロンサーバと見なされる。 ユーザーは、さまざまなデータソースからのリクエストと見なされます。 銀行ホールは、ユーザーがデータを読み書きできるログストアとして機能します。

次のリストでは、関連するロールについて説明します。
ログまたはロググループ: 入金や出金などのユーザー操作。
ユーザー:操作の実行者。
店員: 銀行でリクエストを処理する従業員。
バンクホール (Logstore): リクエストが受信され、処理のために店員に割り当てられる場所。
シャード: 銀行マネージャーが銀行ホールでリクエストを分類する方法。
1 つ目の課題:順序
2人の店員、店員Aと店員Bが銀行で働いていました。 アリスは預けました カウンターAで1,000米ドル。書記官AはアカウントブックAに取引金額を記録しました。 午後、アリスはお金を引き出すためにカウンターBに行きました。 ただし、書記官BはアカウントブックBでアリスの預金記録を見つけることができませんでした。
この例では、入金と出金は厳密に注文する必要があります。 同じユーザーからのリクエストは、ユーザー操作のステータスが一貫していることを確認するために、同じクラークが処理する必要があります。
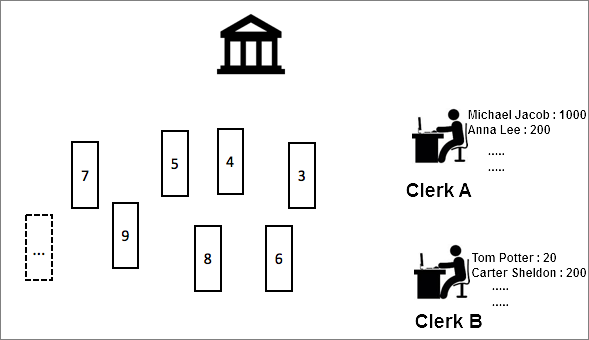
リクエストの順序を保持するために、リクエストをソートし、FIFOの原則に基づいてリクエストを処理するようにClerk aを割り当てるシャードを作成できます。 しかし、この方法は非効率的である。 例えば、1,000のユーザが操作を実行し、10人の店員が利用可能である場合、10人のうち1人の店員だけが操作を処理するように割り当てられるので、プロセスは依然として非効率的である。 効率を向上させるには、次のソリューションを使用できます。
10個のクラークに対して10個のシャードを作成し、各シャードでリクエストを処理するためにクラークを割り当てます。 同じアカウントの操作を確実に順序付けするには、コンシステントハッシングを使用してリクエストをマップします。 たとえば、銀行口座やユーザーの名前に基づいて、ユーザーからのリクエストを特定のシャードにマップします。 この場合、公式hash(Alice) = Aは、Aliceからの要求を、範囲がAを含むシャードにマッピングするために使用される。クラークAのようなクラークは、このシャード内の要求を処理するために割り当てられる。
多くのユーザーがAliceという名前の場合、ソリューションを調整できます。 たとえば、ハッシュ関数を使用して、ユーザーのアカウントIDまたは郵便番号に基づいて、ユーザーからのリクエストをシャードにマップします。 次に、リクエストを各シャードに均等に分散できます。
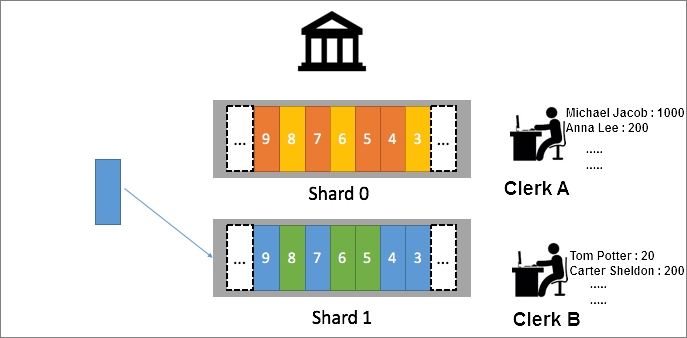
問題2: 少なくとも1回処理
アリスはカウンターAにお金を預けました。店員Aがこの預け入れ要求を処理していたときに、店員aは電話を受けました。 呼び出しの後、店員Aは、アリスの預金要求が処理されたと誤って考え、次のユーザからの要求を処理し始めた。 その結果、アリスの入金要求が失われました。
コンピュータは店員と同じ間違いを犯すことはなく、より長い期間より確実に動作することができます。 ただし、コンピューターは障害や過負荷によりデータの処理に失敗する場合があります。 そのような理由による預金の損失は受け入れられません。 このシナリオでは、次のソリューションを使用してデータの損失を回避することができます。
店員Aは、アカウントブックaとは異なるノートブックに現在の要求の進行状況を記録する。そして、店員Aは、アリスの預金要求が処理された後にのみ、次のユーザを呼び出す。

この解決策は繰り返しにつながる可能性があります。 たとえば、書記官Aがアリスの預金要求を処理し、アカウントブックAのデータを更新した後、書記官Aは呼び出され、現在の要求の進行状況をノートブックに記録しませんでした。 書記官Aが戻ってきて、アリスからの要求の進行をノートブックで見つけられなかった場合、書記官Aは、要求を再び処理することができる。
問題3: ちょうど一度の処理
繰り返しは問題にならないかもしれません。
べき等演算を複数回実行しても、プロセスの繰り返しは結果に影響しません。 たとえば、残高照会は、ユーザーが実行する読み取り専用操作です。 ユーザがこの操作を繰り返す場合、問い合わせ結果は影響を受けない。 ユーザーログオフなどの一部の非読み取り専用操作も、操作結果に影響を与えることなく繰り返し実行できます。
実際のシナリオでは、入金や出金などのほとんどの操作はべき等ではありません。 これらの操作の繰り返しは、結果に大きな影響を与えます。 繰り返しを避けるために、次のソリューションを使用できます。 クラークAがリクエストを処理した後、クラークaはアカウントブックAのデータを更新し、ノートブックに現在のリクエストの進行状況を記録し、データ更新と進行状況のレコードをチェックポイントに結合します。
書記官Aが一時的または永続的に退場する場合、他の書記官は次の方法で続行できます。現在の要求に対してチェックポイントが記録されている場合は、次の要求に進みます。 現在のリクエストに対してチェックポイントが記録されていない場合は、このリクエストを処理します。 これにより、操作の原子性が保証されます。

チェックポイントは、シャード内の要素の位置または時間をキーとして保存して、要素が処理されたことを示すことができる永続的なオブジェクトです。
ビジネスにおける課題
前述の問題で説明した原理は複雑ではありません。 しかしながら、現実世界におけるユーザ数およびワークロード量の変化および不確実性は、上記の問題をさらに複雑にする。 例:
ユーザーの数は、支払い日に大幅に増加します。
コンピューターとは異なり、店員は休憩と昼食を必要とします。
ユーザーエクスペリエンスを向上させるために、銀行のマネージャーは店員の数を増やす必要があります。 これは、条件を評価して店員の数を増やすという課題を提起します。
店員は、勘定科目とチェックポイントを効率的に引き渡す必要があります。
現代の銀行での営業日
銀行は午前8時に営業を開始します。
すべてのリクエストはShard0という名前の唯一のシャードに割り当てられます。 要求を処理するために店員Aが割り当てられる。

ピーク時間は午前10時から始まります。
銀行のマネージャーは、午前10時からShard0をShard1とShard2に分割することにしました。 また、銀行の管理者は、次の規則に基づいて、2つのシャードにリクエストを割り当てる。名前がaからWの文字で始まるユーザーからのリクエストをShard1に割り当て、名前が
[X, Y, Z]で始まるユーザーからのリクエストをShard2に割り当てる。 名前がaからWまでの文字で始まるユーザーの総数は、名前がX、Y、またはZで始まるユーザーの総数とほぼ同じです。次の図は、シャード内の10:00から12:00までのリクエストのステータスを示しています。

書記官Aが2つのシャードで要求を処理するのが困難な場合、銀行のマネージャーは書記官Bと書記官Cを派遣します。書記官Bはシャードの1つを引き継ぎます。 店員Cはアイドルである。
ユーザー数は12:00以降に増加します。
銀行管理者は、Shard1をShard3とShard4に分割し、書記官AをShard3の要求の処理に割り当て、書記官CをShard4の要求の処理に割り当てる。 12:00以降、元々Shard1に割り当てられていたリクエストはShard3とShard4に再割り当てされます。
次の図は、12:00以降のシャード内のリクエストのステータスを示しています。

ユーザー数は16:00から減少します。
銀行のマネージャーは、書記官Aと書記官Bに休憩をとるように依頼し、書記官CにShard2、Shard3、およびShard4の要求を処理するように依頼します。 その後、銀行のマネージャーは、Shard2とShard3を組み合わせてShard5という名前のシャードにし、Shard5とShard4を組み合わせてShard6という名前のシャードにします。 Shard6のすべての要求が処理された後、銀行は閉じられます。
ログ処理
前述のプロセスは、一般的なログ処理シナリオに抽象化できます。 銀行のビジネス要件を満たすために、柔軟で柔軟なログフレームワークを使用して、次の機能を提供できます。
シャードは自動的にスケールインまたはスケールアウトされます。
シャードは、消費者が消費者グループに追加または除去されるときに、消費者グループの消費者に自動的に適合される。 これにより、データの整合性が確保され、ログが順番に処理されます。
ログは1回だけ処理されます。 これにより、消費者は注文をサポートする必要があります。
実際の要件に基づいてコンピューティングリソースが確実に割り当てられるように、消費プロセスが監視されます。
より多くのソースからのログを収集できます。 現代の銀行の例では、ユーザは、オンラインバンキング、モバイルバンキング、および電子小切手などの複数のチャネルから要求を送信することができる。
上記のシナリオでは、Logstoreコンシューマーグループを使用してログをリアルタイムで処理できます。 これにより、リソーススケーリングやフェイルオーバーについて心配することなく、ビジネスロジックに集中できます。 詳細については、「コンシューマーグループを使用したデータの消費」をご参照ください。
Spark Streamingを使用して、コンシューマーグループを使用してSimple log Serviceのログデータを消費することもできます。 詳細については、「Spark Streamingを使用したログデータの消費」をご参照ください。