Log serviceを使用すると、NGINXアクセスログを収集および分析できます。 このトピックでは、Webサイトへのアクセスを監視、分析、診断、および最適化する方法について説明します。
前提条件
ログデータを収集済み。 詳細については、「NGINX設定モードを使用したテキストログの収集」をご参照ください。
インデックス作成機能が有効になり、設定されます。 詳細については、「インデックスの作成」をご参照ください。
背景情報
NGINXは、Webサイトの構築とホストに使用できる、無料のオープンソースで高性能なHTTPサーバーです。 NGINXアクセスログを収集して分析できます。 CNZZなどの従来の方法では、JavaScriptスクリプトがWebサイトのフロントエンドページに挿入され、ユーザーがWebサイトにアクセスしたときにトリガーされます。 ただし、この方法ではアクセス要求のみを記録できます。 ストリームコンピューティング、オフラインコンピューティング、およびオフライン分析を使用して、NGINXアクセスログを分析することもできます。 しかし、これらの方法は専用の環境を必要とし、ログ分析中に時間効率と柔軟性のバランスをとることは困難です。
Simple Log Serviceコンソールで、データインポートウィザードを使用してNGINXアクセスログを収集するための収集設定を作成できます。 次に、Simple Log Serviceは、NGINXアクセスログの収集と分析に役立つインデックスとNGINXダッシュボードを作成します。 ダッシュボードには、IPアドレスの分布、HTTPステータスコード、リクエスト方法、ページビュー (PV) と一意の訪問者 (UV) の統計、インバウンドとアウトバウンドトラフィック、ユーザーエージェント、トップ10のリクエストURL、リクエスト数によるトップ10のURI、リクエスト遅延によるトップ10のURIなどのメトリックが表示されます。 クエリ文を使用して、Webサイトのアクセス遅延を分析し、Webサイトのパフォーマンスをできるだけ早く最適化できます。 パフォーマンスの問題、サーバーエラー、トラフィックの変化を追跡するアラートを作成できます。 アラートのトリガー条件が満たされると、指定された受信者にアラート通知が送信されます。
Webサイトへのアクセスを分析する
Simple Log Serviceコンソールにログインします。
[プロジェクト] セクションで、管理するプロジェクトをクリックします。

左側のナビゲーションウィンドウで、 を選択します。 Logstoreを見つけて、その横にある > アイコンをクリックします。
視覚ダッシュボードの横にある> アイコンをクリックし、LogstoreName_Nginx_access_logをクリックします。
ダッシュボードには、次のメトリックが表示されます。
IPアドレスの分布: 次のSQL文を実行して、IPアドレスの分布に関する統計を収集します。
* | select count(1) as c, ip_to_province(remote_addr) as address group by address limit 100HTTPステータスコード: 次のSQL文を実行して、過去24時間に返された各HTTPステータスコードの割合を計算します。
* | select count(1) as pv, status group by status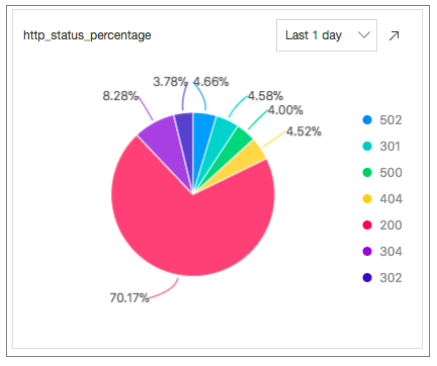
リクエストメソッド: 次のSQL文を実行して、過去24時間に使用された各リクエストメソッドの割合を計算します。
* | select count(1) as pv ,request_method group by request_method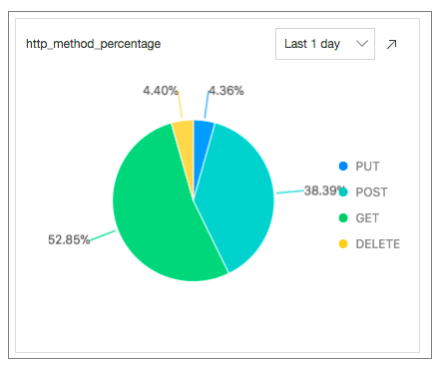
ユーザーエージェント: 次のSQL文を実行して、過去24時間に使用された各ユーザーエージェントの割合を計算します。
* | select count(1) as pv, case when http_user_agent like '%Chrome%' then 'Chrome' when http_user_agent like '%Firefox%' then 'Firefox' when http_user_agent like '%Safari%' then 'Safari' else 'unKnown' end as http_user_agent group by case when http_user_agent like '%Chrome%' then 'Chrome' when http_user_agent like '%Firefox%' then 'Firefox' when http_user_agent like '%Safari%' then 'Safari' else 'unKnown' end order by pv desc limit 10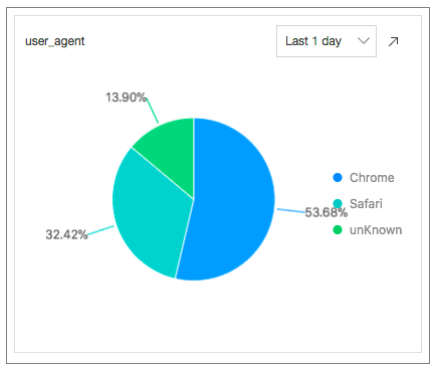
上位10個のリクエストURL: 次のSQL文を実行して、過去24時間で最も多くのPVを持つ上位10個のリクエストURLを示します。
* | select count(1) as pv , http_referer group by http_referer order by pv desc limit 10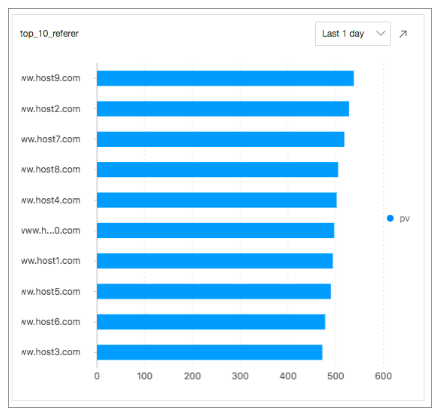
インバウンドトラフィックとアウトバウンドトラフィック: 次のSQL文を実行して、インバウンドトラフィックとアウトバウンドトラフィックの統計を収集します。
* | select sum(body_bytes_sent) as net_out, sum(request_length) as net_in ,date_format(date_trunc('hour', __time__), '%m-%d %H:%i') as time group by date_format(date_trunc('hour', __time__), '%m-%d %H:%i') order by time limit 10000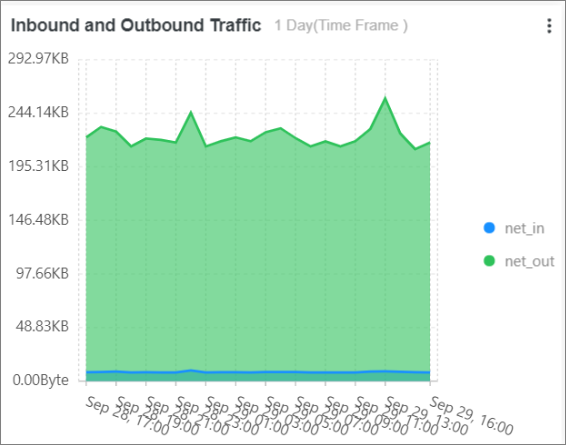
PVおよびUV統計: 次のSQL文を実行して、PVおよびUVの数を計算します。
*| select approx_distinct(remote_addr) as uv ,count(1) as pv , date_format(date_trunc('hour', __time__), '%m-%d %H:%i') as time group by date_format(date_trunc('hour', __time__), '%m-%d %H:%i') order by time limit 1000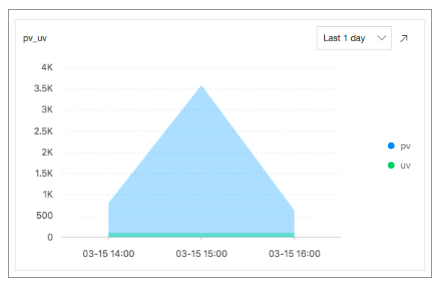
予測PV: 次のSQL文を実行して、次の4時間のPV数を予測します。
* | select ts_predicate_simple(stamp, value, 6, 1, 'sum') from (select __time__ - __time__ % 60 as stamp, COUNT(1) as value from log GROUP BY stamp order by stamp) LIMIT 1000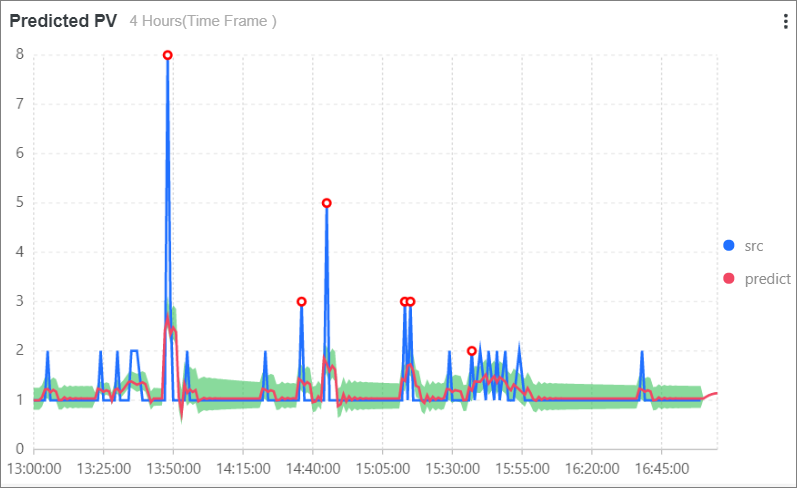
リクエスト数による上位10個のURL: 次のSQL文を実行して、過去24時間に最も多くのPVを持つリクエストされたURLの上位10個を示します。
* | select count(1) as pv, split_part(request_uri,'?',1) as path group by path order by pv desc limit 10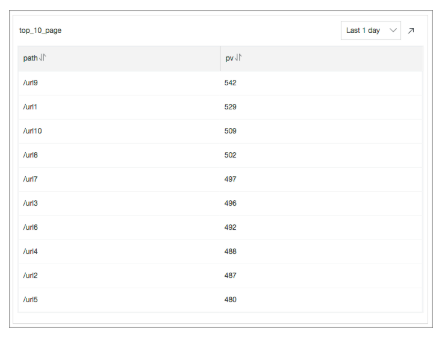
Webサイトへのアクセスの診断と最適化
一部のデフォルトのアクセス指標に加えて、NGINXアクセスログに基づいてアクセス要求を診断する必要もあります。 これにより、特定のページでレイテンシーの高いリクエストを見つけることができます。 クイック分析機能は、検索と分析ページで使用できます。 詳細については、「クエリと分析のクイックガイド」をご参照ください。
次のSQL文を実行して、5分ごとに平均レイテンシと最大レイテンシをカウントし、全体のレイテンシを取得します。
* | select from_unixtime(__time__ -__time__% 300) as time, avg(request_time) as avg_latency , max(request_time) as max_latency group by __time__ -__time__% 300次のSQL文を実行して、レイテンシが最も高い要求されたページを見つけ、ページの応答速度を最適化します。
* | select from_unixtime(__time__ - __time__% 60) , max_by(request_uri,request_time) group by __time__ - __time__%60次のSQL文を実行して、すべてのリクエストをアクセスレイテンシで10のグループに分割し、異なるレイテンシ範囲に基づいてリクエストの数をカウントします。
* |select numeric_histogram(10,request_time)次のSQL文を実行して、レイテンシが最も高い上位10件のリクエストと各リクエストのレイテンシを数えます。
* | select max(request_time,10)要求されたページを最大のレイテンシで最適化します。
/url2ページのレイテンシが最も高いとします。 /url2ページの応答速度を最適化するには、/url2ページの次のメトリックをカウントします。PVおよびUVの数、各リクエストメソッドが使用された回数、各HTTPステータスコードが返された回数、各ブラウザータイプが使用された回数、平均レイテンシ、および最大レイテンシ。
request_uri:"/url2" | select count(1) as pv, approx_distinct(remote_addr) as uv, histogram(method) as method_pv, histogram(status) as status_pv, histogram(user_agent) as user_agent_pv, avg(request_time) as avg_latency, max(request_time) as max_latency今日と昨日のPVを比較する:
* | select diff [1] as today, round((diff [3] -1.0) * 100, 2) as growth FROM ( SELECT compare(pv, 86400) as diff FROM ( SELECT COUNT(1) as pv FROM log ) )今日と昨日のPVの日々の比較を計算します。
* | select t, diff [1] as today, diff [2] as yestoday, diff [3] as percentage from( select t, compare(pv, 86400) as diff from ( select count(1) as pv, date_format(from_unixtime(__time__), '%H:%i') as t from log group by t limit 10000 ) group by t order by t limit 10000 )
アラートルールの作成
アラートルールを作成して、パフォーマンスの問題、サーバーエラー、トラフィックの変更を追跡できます。 詳細については、「アラートルールの設定」をご参照ください。
サーバー警告
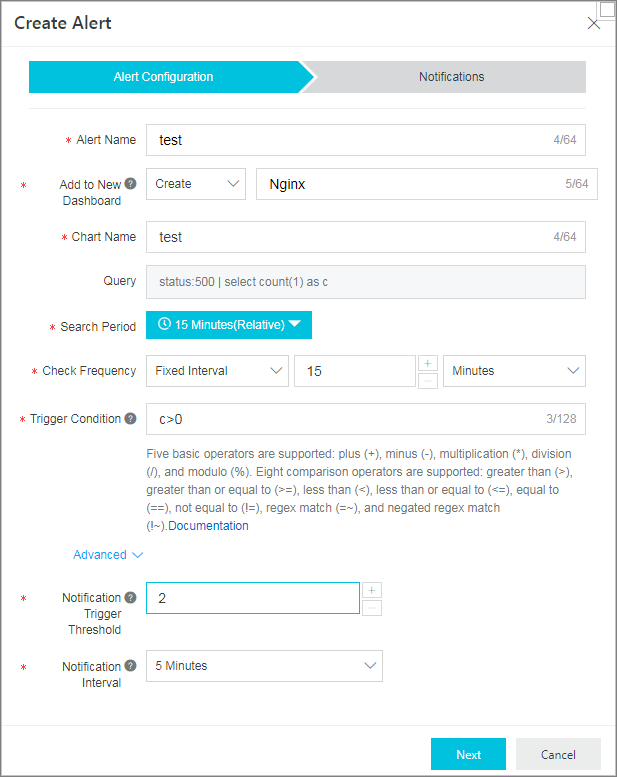
HTTPステータスコードが500のサーバーエラーに注目する必要があります。 次のSQL文を実行して、単位時間あたりのエラー数cを照会し、アラートルールのトリガー条件をc > 0に設定できます。
status:500 | select count(1) as c説明アクセストラフィックの多いサービスでは、500エラーが発生することがあります。 この場合、通知トリガーしきい値パラメーターを2に設定できます。 条件が2回連続して満たされた場合にのみアラートがトリガーされることを示します。
パフォーマンス警告
サーバーの実行中にレイテンシが増加した場合は、アラートルールを作成できます。 たとえば、次のSQL文を実行することで、操作
/adduserのすべての書き込み要求Postのレイテンシを計算できます。 次に、アラートルールをl > 300000に設定します。 平均レイテンシが300ミリ秒を超えるとアラートが送信されることを示します。Method:Post and URL:"/adduser" | select avg(Latency) as l平均レイテンシ値を使用してアラートを作成できます。 しかしながら、高いレイテンシ値はより低い値に平均化されるため、これは真の状況を反映しない可能性がある。 トリガー条件として、数学統計のパーセンタイル (最大のレイテンシは99%) を使用できます。
Method:Post and URL:"/adduser" | select approx_percentile(Latency, 0.99) as p991日の1分ごとのレイテンシ (1,440分) 、50パーセンタイルのレイテンシ、および90パーセンタイルのレイテンシを計算できます。
* | select avg(Latency) as l, approx_percentile(Latency, 0.5) as p50, approx_percentile(Latency, 0.99) as p99, date_trunc('minute', time) as t group by t order by t desc limit 1440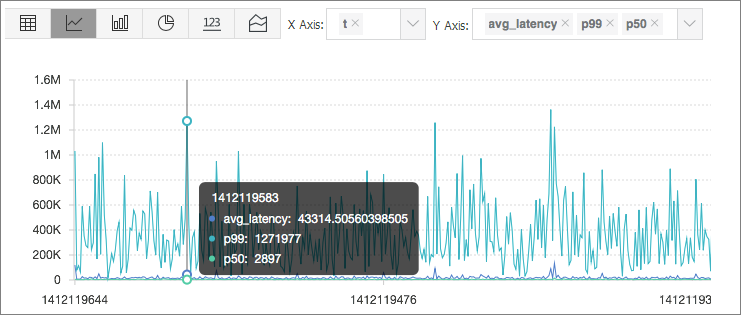
交通アラート
短時間でのトラフィックの急激な減少または増加は異常です。 トラフィックの変化率を計算し、突然のトラフィックの変化を監視するアラートルールを作成できます。 突然のトラフィックの変化は、次のメトリックに基づいて検出されます。
前の期間: 現在の期間のデータと前の期間のデータを比較します。
前日の同じ期間: 現在の期間のデータと前日の同じ期間のデータを比較します。
前の週の同じ期間: 現在の期間のデータを前の週の同じ期間のデータと比較します。
最後のウィンドウは、トラフィック変化率を計算するために次の例で使用されます。 この例では、時間範囲は5分に設定されています。
計算ウィンドウを定義します。
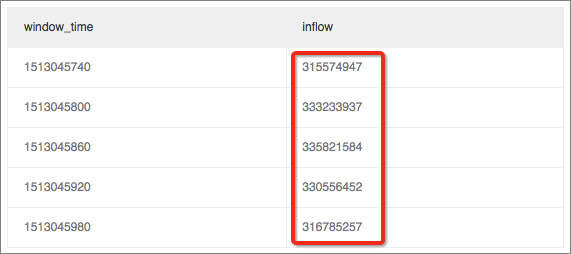
1 分間のウィンドウを定義して、この時間の受信トラフィックサイズを計算します。
* | select sum(inflow)/(max(__time__)-min(__time__)) as inflow , __time__-__time__%60 as window_time from log group by window_time order by window_time limit 15結果は、平均インバウンドトラフィックがすべてのウィンドウで均等に分散されることを示しています。
ウィンドウで値の違いを計算します。
ウィンドウ内の最大または最小トラフィックサイズと平均トラフィックサイズの差を計算します。 max_ratioメトリックは例として使用されます。
計算されたmax_ratioは1.02である。 アラートルールをmax_ratio > 1.5に設定できます。 変更率が50% を超えるとアラートが送信されることを示します。
* | select max(inflow)/avg(inflow) as max_ratio from (select sum(inflow)/(max(__time__)-min(__time__)) as inflow , __time__-__time__%60 as window_time from log group by window_time order by window_time limit 15)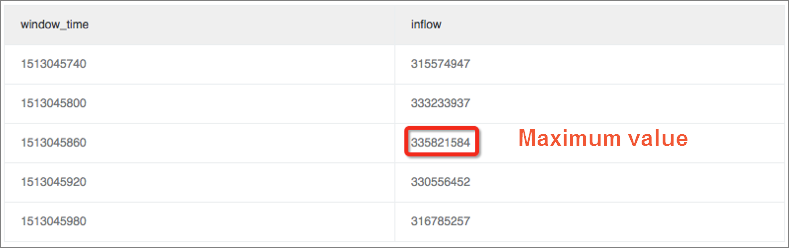
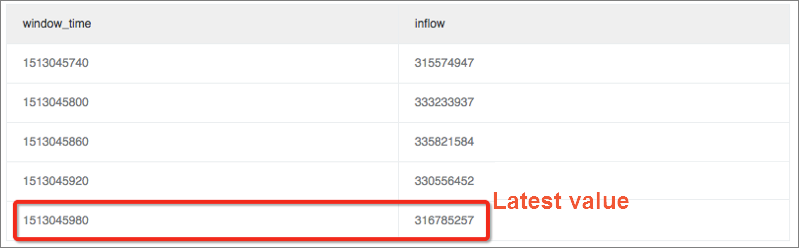
latest_ratioメトリックを計算して、最新の値が変動するかどうかを確認します。
ウィンドウ内の最大トラフィックサイズを計算するには、max_by関数を使用します。 この例では、latest_ratioは0.97です。
* | select max_by(inflow, window_time)/1.0/avg(inflow) as latest_ratio from (select sum(inflow)/(max(__time__)-min(__time__)) as inflow , __time__-__time__%60 as window_time from log group by window_time order by window_time limit 15)説明max_by関数の計算結果は文字型です。 数値型に変換する必要があります。 変更の相対比率を計算するには、SELECT句を (1.0-max_by(inflow, window_time)/1.0/avg(inflow)) as latest_ratioに置き換えます。
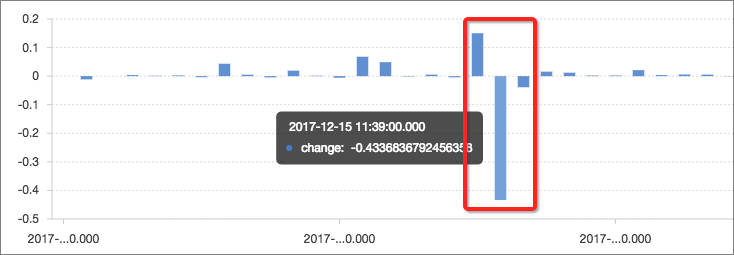
変動率を計算します。 これは、現在の値とウィンドウの前の値との間の変化比である。
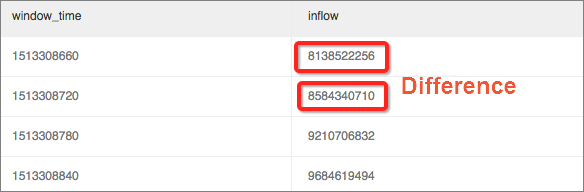
計算にはウィンドウ関数 (lag) を使用します。 現在のインバウンドトラフィックと前のサイクルのインバウンドトラフィックを抽出し、lag(inflow, 1, inflow)over() を使用して差を計算します。 そして、算出した差分値を電流値で除算して変化率を求める。 この例では、11:39にトラフィックが比較的大幅に減少し、変化率は40% を超えています。
説明絶対変化率を定義するには、ABS関数を使用して絶対値を計算し、計算結果を統合します。
* | select (inflow- lag(inflow, 1, inflow)over() )*1.0/inflow as diff, from_unixtime(window_time) from (select sum(inflow)/(max(__time__)-min(__time__)) as inflow , __time__-__time__%60 as window_time from log group by window_time order by window_time limit 15)