ApsaraDB RDS for SQL Server は、ローカルの SQL Server データベースを ApsaraDB RDS for SQL Server インスタンスに移行するためのソリューションを提供します。ローカルの SQL Server データベースの完全バックアップデータを Alibaba Cloud Object Storage Service (OSS) にアップロードできます。その後、ApsaraDB RDS コンソールを使用して、完全バックアップデータを指定の ApsaraDB RDS for SQL Server インスタンスに移行できます。このソリューションは、データバックアップ、データ移行、ディザスタリカバリなどのシナリオに適しています。
前提条件
ApsaraDB RDS for SQL Server インスタンスは、次の要件を満たす必要があります。
インスタンスの残りのストレージ領域は、移行するデータファイルよりも大きい必要があります。ストレージ領域が不足している場合は、インスタンスストレージをアップグレードできます。
SQL Server 2012 以降、またはクラウドディスクを使用する SQL Server 2008 R2 を実行するインスタンスの場合: インスタンスに、移行するデータベースと同じ名前のデータベースが含まれていないことを確認してください。
ハイパフォーマンスローカルディスクを使用する SQL Server 2008 R2 を実行するインスタンスの場合: 移行するデータベースと同じ名前のデータベースがインスタンス上に作成されていることを確認してください。
Resource Access Management (RAM) ユーザーを使用する場合、次の条件を満たす必要があります。
RAM ユーザーには AliyunOSSFullAccess および AliyunRDSFullAccess 権限が必要です。RAM ユーザーに権限を付与する方法の詳細については、「RAM を使用した OSS 権限の管理」および「RAM を使用した ApsaraDB RDS 権限の管理」をご参照ください。
Alibaba Cloud アカウントが ApsaraDB RDS サービスアカウントに OSS リソースへのアクセス権限を付与している必要があります。
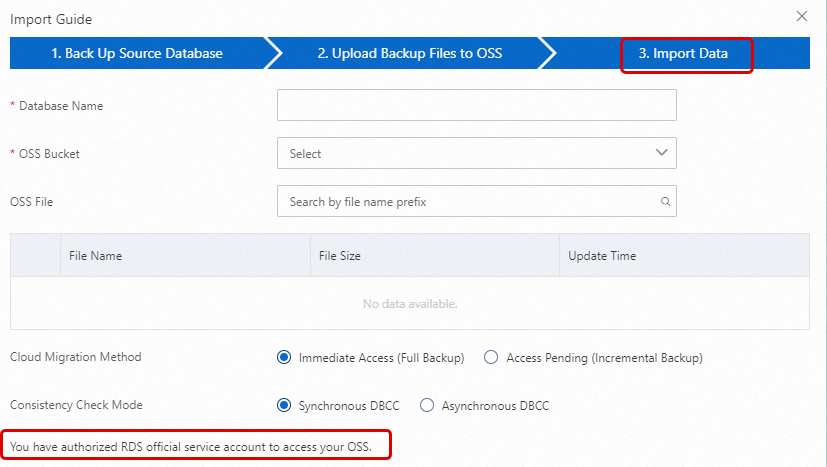
ApsaraDB RDS インスタンスの [バックアップと復元] ページに移動し、[OSS バックアップから復元] をクリックします。
[データインポートウィザード] で、[次へ] を 2 回クリックして、ステップ [3. データインポート] に進みます。
ページの左下隅にメッセージ [公式 RDS サービスアカウントに OSS リソースへのアクセスを承認しました] が表示されている場合、権限付与は完了しています。そうでない場合は、ページの [権限付与 URL] をクリックして権限を付与します。
Alibaba Cloud アカウントは、手動でアクセスポシーを作成し、そのポリシーを RAM ユーザーにアタッチする必要があります。
注意事項
移行レベル: このソリューションはデータベースレベルの移行のみをサポートします。複数のデータベースまたはすべてのデータベースを移行するには、インスタンスレベルの移行ソリューションを使用してください。
バージョンの互換性: ローカル SQL Server インスタンスのバックアップファイルから、それより古いバージョンの SQL Server を実行している ApsaraDB RDS for SQL Server インスタンスにデータを移行することはできません。
権限管理: ApsaraDB RDS サービスアカウントに OSS へのアクセス権限を付与すると、RAM コンソールのロール管理に
AliyunRDSImportRoleという名前のロールが作成されます。このロールを変更したり削除したりしないでください。変更または削除すると、移行タスクは失敗します。誤操作を行った場合は、データ移行ウィザードを使用して権限を再付与する必要があります。アカウント管理: 移行が完了すると、元のデータベースアカウントは使用できなくなります。ApsaraDB RDS コンソールで新しいアカウントを作成する必要があります。
OSS ファイルの保持: 移行タスクが完了する前に OSS からバックアップファイルを削除しないでください。削除すると、タスクは失敗します。
バックアップファイルの要件:
ファイル名の制限: ファイル名に
!@#$%^&*()_+-=などの特殊文字を含めることはできません。含めると、移行は失敗します。ファイル名拡張子: ApsaraDB RDS は、
.bak(完全バックアップ)、.diff(差分バックアップ)、.trn、または.log(ログバックアップ) 拡張子を持つバックアップファイルをサポートします。システムは他のファイルタイプを識別できません。ファイルタイプ: 完全バックアップファイルのみがアップロード可能です。差分バックアップとログバックアップはサポートされていません。
ファイルソース: ソースデータが ApsaraDB RDS for SQL Server からダウンロードした完全バックアップファイルで、デフォルトで
.zip形式の場合、データを移行する前にファイルを.bakファイルに解凍する必要があります。
課金
このソリューションでは、次の図に示すように、OSS 関連の料金のみが発生します。
シナリオ | 説明 |
ローカルデータバックアップファイルを OSS にアップロード | 料金は発生しません。 |
OSS にバックアップファイルを保存 | OSS ストレージ料金が発生します。詳細については、「OSS の料金」をご参照ください。 |
OSS から ApsaraDB RDS にバックアップファイルを移行 |
|
準備
ローカルデータベース環境で、DBCC CHECKDB 文を実行して、データベースに allocation errors または consistency errors がないことを確認します。次の結果は、コマンドが正常に実行されたことを示します。
...
CHECKDB found 0 allocation errors and 0 consistency errors in database 'xxx'.
DBCC execution completed. If DBCC printed error messages, contact your system administrator.1. ローカルデータベースのバックアップ
ApsaraDB RDS for SQL Server インスタンスのバージョンに基づいて方法を選択します。
SQL Server 2012 以降、またはクラウドディスクを使用する SQL Server 2008 R2
ローカルデータベースの完全バックアップを実行する前に、データベースへのデータ書き込みを停止してください。バックアッププロセス中に書き込まれたデータはバックアップされません。
バックアップスクリプトをダウンロードし、SQL Server Management Studio (SSMS) で開きます。
スクリプトで、
YOU HAVE TO INIT PUBLIC VARIABLES HEREの下にある SELECT 文のパラメーターを変更します。構成項目
説明
@backup_databases_list
バックアップするデータベース。複数のデータベースはセミコロン (;) またはカンマ (,) で区切ります。
@backup_type
バックアップタイプ。有効値:
FULL: 完全バックアップ。
DIFF: 差分バックアップ。
LOG: ログバックアップ。
@backup_folder
バックアップファイルが保存されるローカルディレクトリ。ディレクトリが存在しない場合は自動的に作成されます。
@is_run
バックアップを実行するかどうかを指定します。有効値:
1: バックアップを実行します。
0: チェックのみを実行し、バックアップは実行しません。
バックアップスクリプトを実行します。
ハイパフォーマンスローカルディスクを使用する SQL Server 2008 R2
Microsoft SQL Server Management Studio (SSMS) クライアントを開きます。
移行するデータベースにログインします。
次のコマンドを実行して、ソースデータベースの現在の復元モデルを確認します。
USE master; GO SELECT name, CASE recovery_model WHEN 1 THEN 'FULL' WHEN 2 THEN 'BULK_LOGGED' WHEN 3 THEN 'SIMPLE' END model FROM sys.databases WHERE name NOT IN ('master','tempdb','model','msdb'); GO結果の
modelの値がFULLでない場合は、ステップ 4 に進みます。結果の
modelの値がFULLの場合は、ステップ 5 に進みます。
次のコマンドを実行して、ソースデータベースの復元モデルを
FULLに設定します。ALTER DATABASE [dbname] SET RECOVERY FULL; GO ALTER DATABASE [dbname] SET AUTO_CLOSE OFF; GO重要復元モデルを
FULLに設定すると、SQL Server のログ情報量が増加します。十分なディスク領域があることを確認してください。次のコマンドを実行して、ソースデータベースをバックアップします。
次の例は、dbtest データベースを backup.bak ファイルにバックアップする方法を示しています。
USE master; GO BACKUP DATABASE [dbtest] to disk ='d:\backup\backup.bak' WITH COMPRESSION,INIT; GO次のコマンドを実行して、バックアップファイルの整合性を検証します。
USE master GO RESTORE FILELISTONLY FROM DISK = N'D:\backup\backup.bak';重要結果セットが返された場合、バックアップファイルは有効です。
エラーが報告された場合は、再度バックアップを実行してください。
オプション: 次のコマンドを実行して、データベースの元の復元モデルを復元します。
重要データベースの復元モデルが既に
FULLである場合、このステップを実行する必要はありません。ALTER DATABASE [dbname] SET RECOVERY SIMPLE; GO
2. バックアップファイルを OSS にアップロードする
ApsaraDB RDS for SQL Server インスタンスのバージョンに基づいて方法を選択します。
SQL Server 2012 以降、またはクラウドディスクを使用する SQL Server 2008 R2
バックアップファイルを OSS にアップロードする前に、OSS にバケットを作成する必要があります。
OSS にバケットが既に存在する場合、次の要件を満たしていることを確認してください:
OSS にバケットが存在しない場合は、作成する必要があります。 (OSS を有効化していることを確認してください。)
OSS コンソールにログインし、[バケット] をクリックしてから、[バケットの作成] をクリックします。
次の主要なパラメーターを設定します。他のパラメーターはデフォルト値のままにすることができます。
重要バケットは主にこのデータ移行のために作成されます。主要なパラメーターのみを設定する必要があります。移行が完了したら、データ漏洩を防ぎコストを削減するためにバケットを削除できます。
バケットを作成する際、サーバ側暗号化を有効にしないでください。
パラメーター
説明
例
バケット名
バケットの名前。名前はグローバルに一意である必要があり、バケット作成後は変更できません。
命名規則:
名前には小文字、数字、ハイフン (-) のみを含めることができます。
名前は小文字または数字で始まり、終わる必要があります。
名前の長さは 3~63 文字である必要があります。
migratetest
リージョン
バケットが存在するリージョン。ECS インスタンスからイントラネット経由でバケットにデータをアップロードし、イントラネット経由で ApsaraDB RDS インスタンスにデータを復元する場合、バケット、ECS インスタンス、および ApsaraDB RDS インスタンスは同じリージョンにある必要があります。
中国 (杭州)
ストレージタイプ
標準ストレージを選択します。このトピックの移行操作は、他のストレージタイプのバケットをサポートしていません。
標準
バックアップファイルを OSS にアップロードします。
ローカルデータベースをバックアップした後、ApsaraDB RDS インスタンスと同じリージョンにある OSS バケットにバックアップファイルをアップロードします。バケットとインスタンスが同じリージョンにある場合、イントラネット相互通信に内部ネットワークを使用できます。この方法では、インターネット経由のアウトバウンドトラフィックが無料で、データアップロード速度も速くなります。次のいずれかの方法を使用できます。
ossbrowser をダウンロードします。
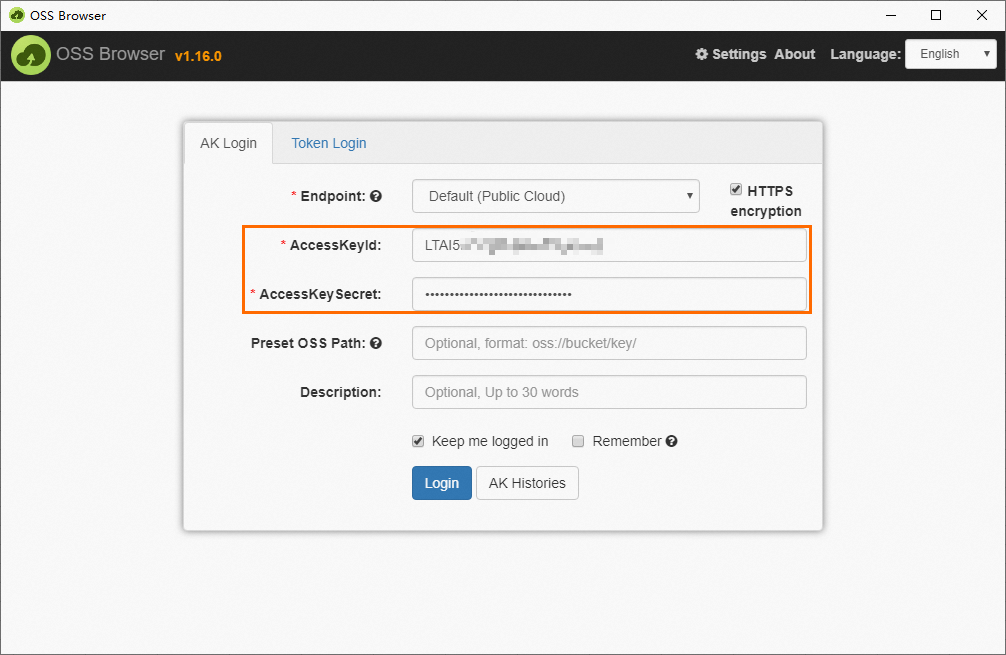
次の手順では、Windows x64 オペレーティングシステムを例として使用します。ダウンロードした
oss-browser-win32-x64.zipパッケージを解凍し、oss-browser.exeアプリケーションをダブルクリックします。[AK でログイン] を選択し、[AccessKeyId] と [AccessKeySecret] パラメーターを設定し、他のパラメーターはデフォルト値のままにして、[ログイン] をクリックします。
説明AccessKey ペアは ID 検証に使用されます。データセキュリティを確保するために、AccessKey ペアは機密情報として扱ってください。
宛先バケットをクリックします。

 をクリックし、アップロードするバックアップファイルを選択して、[開く] をクリックします。ローカルファイルが OSS にアップロードされます。
をクリックし、アップロードするバックアップファイルを選択して、[開く] をクリックします。ローカルファイルが OSS にアップロードされます。
説明バックアップファイルが 5 GB 未満の場合は、OSS コンソールからアップロードすることをお勧めします。
OSS コンソールにログインします。
[バケット] をクリックし、宛先バケットの名前をクリックします。
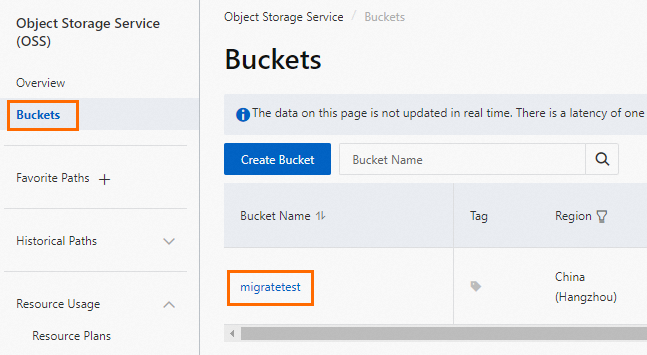
[ファイル] リストで、[ファイルのアップロード] をクリックします。
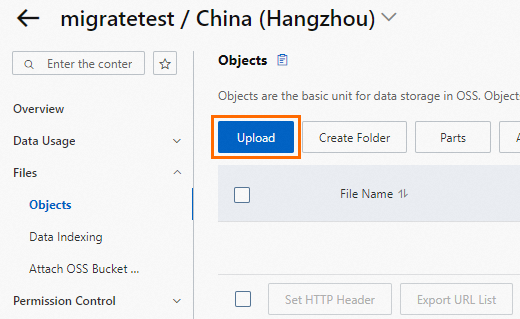
バックアップファイルを [アップロードするファイル] エリアにドラッグするか、[ファイルのスキャン] をクリックしてファイルを選択します。
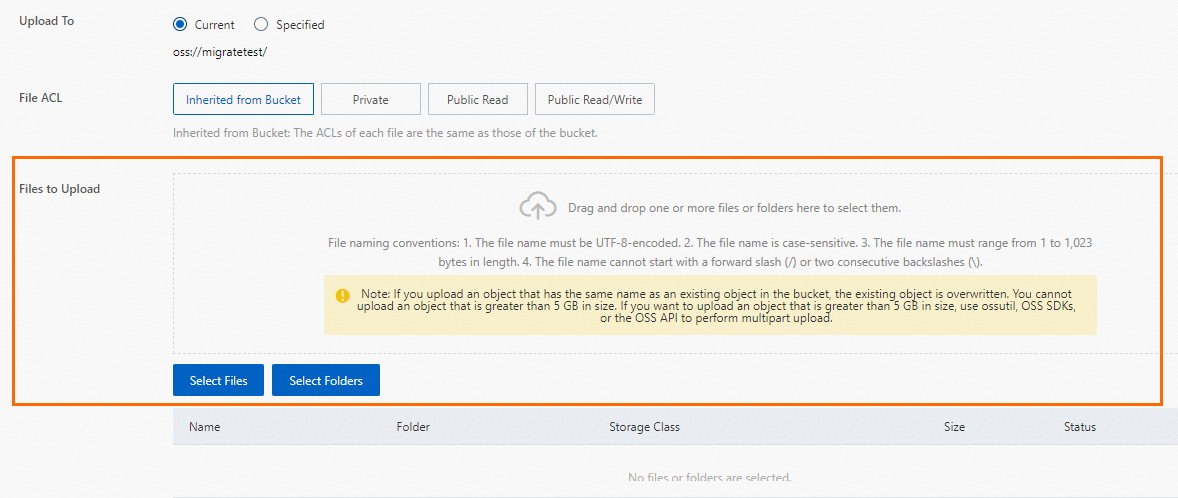
ページ下部の [ファイルのアップロード] ボタンをクリックして、ローカルバックアップファイルを OSS にアップロードします。
ハイパフォーマンスローカルディスクを使用する SQL Server 2008 R2
バックアップファイルを OSS にアップロードする前に、OSS にバケットを作成する必要があります。
OSS にバケットが既に存在する場合、次の要件を満たしていることを確認してください:
OSS にバケットが存在しない場合は、作成する必要があります。 (OSS を有効化していることを確認してください。)
OSS コンソールにログインし、[バケット] をクリックしてから、[バケットの作成] をクリックします。
次の主要なパラメーターを設定します。他のパラメーターはデフォルト値のままにすることができます。
重要バケットは主にこのデータ移行のために作成されます。主要なパラメーターのみを設定する必要があります。移行が完了したら、データ漏洩を防ぎコストを削減するためにバケットを削除できます。
バケットを作成する際、サーバ側暗号化を有効にしないでください。
パラメーター
説明
例
バケット名
バケットの名前。名前はグローバルに一意である必要があり、バケット作成後は変更できません。
命名規則:
名前には小文字、数字、ハイフン (-) のみを含めることができます。
名前は小文字または数字で始まり、終わる必要があります。
名前の長さは 3~63 文字である必要があります。
migratetest
リージョン
バケットが存在するリージョン。ECS インスタンスからイントラネット経由でバケットにデータをアップロードし、イントラネット経由で ApsaraDB RDS インスタンスにデータを復元する場合、バケット、ECS インスタンス、および ApsaraDB RDS インスタンスは同じリージョンにある必要があります。
中国 (杭州)
ストレージタイプ
標準ストレージを選択します。このトピックの移行操作は、他のストレージタイプのバケットをサポートしていません。
標準
バックアップファイルを OSS にアップロードします。
ローカルデータベースをバックアップした後、ApsaraDB RDS インスタンスと同じリージョンにある OSS バケットにバックアップファイルをアップロードします。バケットとインスタンスが同じリージョンにある場合、イントラネット相互通信に内部ネットワークを使用できます。この方法では、インターネット経由のアウトバウンドトラフィックが無料で、データアップロード速度も速くなります。次のいずれかの方法を使用できます。
ossbrowser をダウンロードします。
次の手順では、Windows x64 オペレーティングシステムを例として使用します。ダウンロードした
oss-browser-win32-x64.zipパッケージを解凍し、oss-browser.exeアプリケーションをダブルクリックします。[AK でログイン] を選択し、[AccessKeyId] と [AccessKeySecret] パラメーターを設定し、他のパラメーターはデフォルト値のままにして、[ログイン] をクリックします。
説明AccessKey ペアは ID 検証に使用されます。データセキュリティを確保するために、AccessKey ペアは機密情報として扱ってください。
宛先バケットをクリックします。
- をクリックし、アップロードするバックアップファイルを選択して、[開く] をクリックします。ローカルファイルが OSS にアップロードされます。
説明バックアップファイルが 5 GB 未満の場合は、OSS コンソールからアップロードすることをお勧めします。
OSS コンソールにログインします。
[バケット] をクリックし、宛先バケットの名前をクリックします。
[ファイル] リストで、[ファイルのアップロード] をクリックします。
バックアップファイルを [アップロードするファイル] エリアにドラッグするか、[ファイルのスキャン] をクリックしてファイルを選択します。
ページ下部の [ファイルのアップロード] ボタンをクリックして、ローカルバックアップファイルを OSS にアップロードします。
バックアップファイルリンクの有効期間を設定し、ファイルの URL を取得します。
OSS コンソールにログインします。
[バケット] をクリックします。次に、宛先バケットの名前をクリックします。
左側のナビゲーションウィンドウで、[ファイル管理] > [ファイル] を選択します。
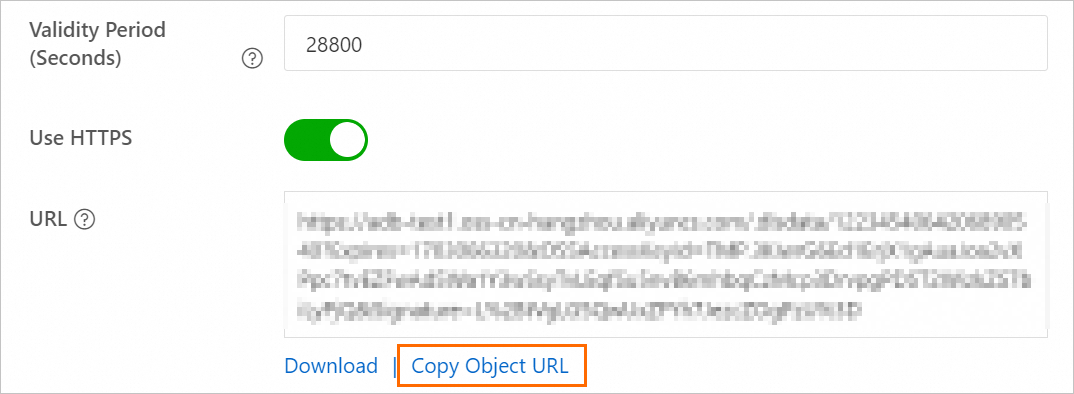
宛先データベースバックアップファイルの [操作] 列で、[詳細] をクリックします。表示されるパネルで、[有効期限 (秒)] を 28800 (8 時間) に設定します。
重要OSS から ApsaraDB RDS にバックアップファイルを移行する場合、バックアップファイルの URL を使用する必要があります。リンクが期限切れになると、データ移行は失敗します。
[ファイル URL のコピー] をクリックして、ファイル URL をコピーします。
取得したデータバックアップファイルの URL を変更します。
デフォルトでは、ファイルのパブリックエンドポイントが取得されます。内部ネットワーク経由でデータを移行するには、ファイル URL のエンドポイントを内部エンドポイントに変更する必要があります。
たとえば、バックアップファイルの URL が
http://rdstest.oss-cn-shanghai.aliyuncs.com/testmigraterds_20170906143807_FULL.bak?Expires=15141****&OSSAccessKeyId=TMP****の場合、URL のoss-cn-shanghai.aliyuncs.comをoss-cn-shanghai-internal.aliyuncs.comに変更する必要があります。重要内部エンドポイントは、ネットワークタイプとリージョンによって異なります。詳細については、「エンドポイントとデータセンター」をご参照ください。
3. OSS バックアップデータを ApsaraDB RDS にインポートする
ApsaraDB RDS for SQL Server インスタンスのバージョンに基づいて方法を選択します。
SQL Server 2012 以降、またはクラウドディスクを使用する SQL Server 2008 R2
[インスタンス] ページに移動します。上部のナビゲーションバーで、RDS インスタンスが存在するリージョンを選択します。次に、RDS インスタンスを見つけて、インスタンスの ID をクリックします。
左側のナビゲーションウィンドウで、[バックアップと復元] をクリックします。
ページの上部にある [OSS バックアップから復元] ボタンをクリックします。
[データインポートウィザード] で、[次へ] を 2 回クリックしてデータインポートステップに進みます。
説明[OSS バックアップから復元] 機能を初めて使用する場合、ApsaraDB RDS に OSS へのアクセスを承認する必要があります。[権限付与 URL] をクリックし、必要な権限を付与します。この権限が付与されていない場合、[OSS バケット] ドロップダウンリストは空になります。
このページで宛先ファイルが見つからない場合は、OSS のバックアップファイルのファイル名拡張子が要件を満たしているか確認してください。詳細については、このトピックの「注意事項」セクションをご参照ください。また、ApsaraDB RDS インスタンスと OSS バケットが同じリージョンにあることを確認してください。
次のパラメーターを設定します。
構成項目
説明
データベース名
RDS インスタンス上の宛先データベースの名前を入力します。宛先データベースは、自己管理 SQL Server インスタンス上のソースデータベースから移行されたデータを保存するために使用されます。宛先データベースの名前は、オープンソース SQL Server の要件を満たす必要があります。
重要移行前に、宛先 RDS インスタンス上のデータベースの名前が、指定されたバックアップファイルを使用して復元したいデータベースの名前と異なることを確認する必要があります。さらに、指定されたバックアップファイルを使用して復元したいデータベースと同じ名前のデータベースファイルが、宛先 RDS インスタンス上のデータベースに追加されていないことを確認してください。両方の要件が満たされている場合、バックアップセット内のデータベースファイルを使用してデータベースを復元できます。データベースファイルは、復元したいデータベースと同じ名前でなければならないことに注意してください。
バックアップファイルで指定されたデータベースと同じ名前のデータベースが宛先インスタンスに既に存在する場合、または同じ名前の未アタッチのデータベースファイルがある場合、復元操作は失敗します。
OSS バケット
バックアップファイルが保存されている OSS バケットを選択します。
OSS ファイルリスト
右側の
 ボタンをクリックして、バックアップファイル名のプレフィックスであいまい検索を実行します。ファイル名、ファイルサイズ、更新時刻が表示されます。移行したいバックアップファイルを選択します。
ボタンをクリックして、バックアップファイル名のプレフィックスであいまい検索を実行します。ファイル名、ファイルサイズ、更新時刻が表示されます。移行したいバックアップファイルを選択します。移行ソリューション
データベースを開く (完全バックアップファイルが 1 つのみ): このオプションは完全移行用で、完全バックアップファイルが 1 つだけ移行されるシナリオに適しています。この場合、[データベースを開く] を選択します。CreateMigrateTask 操作の BackupMode パラメーターは
FULLに設定され、IsOnlineDB パラメーターはTrueに設定されます。データベースを開かない (差分バックアップまたはログファイルが存在する): このオプションは増分移行用で、完全バックアップファイルに加えてログバックアップ (または差分バックアップファイル) が移行されるシナリオに適しています。この場合、CreateMigrateTask 操作の BackupMode パラメーターは
UPDFに設定され、IsOnlineDB パラメーターはFalseに設定されます。
整合性チェック方法
DBCC を非同期で実行: システムはデータベースを開くときに DBCC CheckDB を実行しません。代わりに、データベースが開かれた後に非同期で DBCC CheckDB を実行します。これにより、データベースを開く時間的オーバーヘッドが削減され (DBCC CheckDB は大規模なデータベースでは非常に時間がかかります)、ビジネスのダウンタイムが最小限に抑えられます。ビジネスのダウンタイムに非常に敏感で、DBCC CheckDB の結果を気にしない場合は、このオプションを使用することをお勧めします。この場合、CreateMigrateTask 操作の CheckDBMode パラメーターは
AsyncExecuteDBCheckに設定されます。DBCC を同期的に実行: 非同期実行と比較して、一部のユーザーはオンプレミスデータベースのデータ整合性エラーを特定するために DBCC CheckDB の結果を非常に気にします。この場合、このオプションを選択することをお勧めします。影響として、データベースを開くのにかかる時間が長くなります。この場合、CreateMigrateTask 操作の CheckDBMode パラメーターは
SyncExecuteDBCheckに設定されます。
[OK] をクリックします。
移行タスクが完了するのを待ちます。[更新] をクリックしてタスクのステータスを確認できます。タスクが失敗した場合は、その説明を使用してエラーのトラブルシューティングを行います。詳細については、このトピックの「一般的なエラー」セクションをご参照ください。
説明データ移行が完了すると、システムは自動バックアップポリシーに基づいて、指定されたバックアップ時間に ApsaraDB RDS インスタンスをバックアップします。バックアップ時間は手動で調整できます。結果のバックアップセットには移行されたデータが含まれ、ApsaraDB RDS インスタンスの [バックアップと復元] ページで利用できます。
スケジュールされたバックアップ時間より前にクラウドでバックアップを生成するには、手動バックアップを実行することもできます。
ハイパフォーマンスローカルディスクを使用する SQL Server 2008 R2
ApsaraDB RDS コンソールにログインし、[インスタンス] ページに移動します。上部のナビゲーションバーで、RDS インスタンスが存在するリージョンを選択します。次に、RDS インスタンスを見つけて、インスタンスの ID をクリックします。
左側のナビゲーションウィンドウで、[データベース管理] をクリックします。
宛先データベースについて、[操作] 列の [OSS バックアップファイルからインポート] をクリックします。

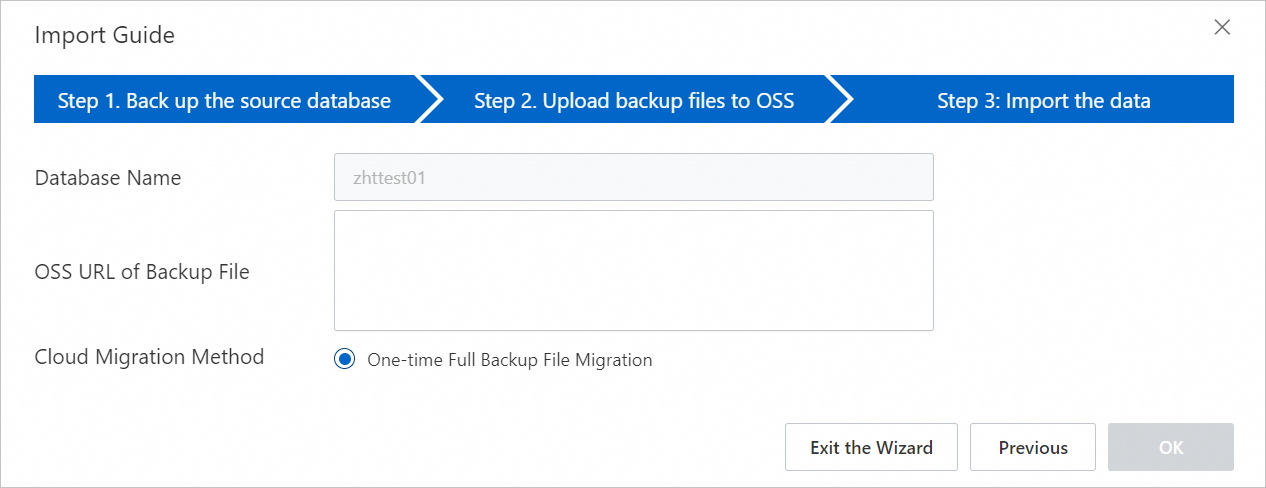
[データインポートウィザード] ダイアログボックスで、情報を確認し、[次へ] をクリックします。
OSS アップロードのプロンプトを確認し、[次へ] をクリックします。
[バックアップファイルの OSS URL] フィールドに、バックアップファイルの OSS URL を入力し、[OK] をクリックします。
 説明
説明ハイパフォーマンスローカルディスクを使用する ApsaraDB RDS for SQL Server 2008 R2 インスタンスは、完全バックアップファイルの 1 回限りのインポートのみをサポートします。
4. 移行の進捗状況の表示
ApsaraDB RDS for SQL Server インスタンスのバージョンに基づいて方法を選択します。
SQL Server 2012 以降、またはクラウドディスクを使用する SQL Server 2008 R2
ApsaraDB RDS インスタンスの [バックアップと復元] ページに移動します。[クラウドへのデータ移行レコード] タブで、タスクのステータス、開始時刻、終了時刻などの移行レコードを表示できます。デフォルトでは、先週のレコードが表示されます。必要に応じて時間範囲を調整できます。

[タスクステータス] が [失敗] の場合、[タスクの説明] を確認するか、[ファイル詳細の表示] をクリックして失敗の原因を特定します。問題を解決した後、データ移行タスクを再実行してください。
ハイパフォーマンスローカルディスクを使用する SQL Server 2008 R2
ApsaraDB RDS インスタンスの [クラウドへのデータ移行] ページで、宛先移行タスクを見つけてその進捗状況を表示します。
[タスクステータス] が [失敗] の場合、[タスクの説明] を確認するか、[ファイル詳細の表示] をクリックして失敗の原因を特定します。問題を解決した後、データ移行タスクを再実行してください。
一般的なエラー
各移行レコードには、タスク失敗の原因を特定するために使用できるタスクの説明が含まれています。以下は一般的なエラーメッセージです:
同じ名前のデータベースが既に存在する
エラーメッセージ 1: データベース (xxx) は RDS にすでに存在します。バックアップしてから削除し、もう一度お試しください。
エラーメッセージ 2: データベース 'xxx' は既に存在します。別のデータベース名を選択してください。
原因: データセキュリティを確保するため、ApsaraDB RDS for SQL Server は既存のデータベースと同じ名前のデータベースの移行をサポートしていません。
解決策: 既存のデータベースを上書きするには、既存のデータをバックアップし、データベースを削除してから、データ移行タスクを再実行します。
差分バックアップファイルの使用
エラーメッセージ: バックアップセット (xxx.bak) はデータベース差分バックアップです。完全バックアップのみ受け付けます。
原因: 提供されたバックアップファイルは差分バックアップであり、完全バックアップではありません。この移行方法は完全バックアップファイルのみをサポートします。
ログバックアップファイルの使用
エラーメッセージ: バックアップセット (xxx.trn) はトランザクションログバックアップですが、フルバックアップのみ受け付けます。
原因: 提供されたバックアップファイルはログバックアップであり、完全バックアップではありません。この移行方法は完全バックアップファイルのみをサポートします。
バックアップファイルの検証に失敗した
エラーメッセージ: xxx.bak の検証に失敗しました。バックアップファイルが破損しているか、RDS より新しいエディションです。
原因: バックアップファイルが破損しているか、ソースデータベースの SQL Server バージョンが宛先 ApsaraDB RDS for SQL Server インスタンスのバージョンよりも新しいです。このバージョンの非互換性により、検証が失敗します。たとえば、SQL Server 2016 のバックアップを ApsaraDB RDS for SQL Server 2012 インスタンスに復元しようとすると、このエラーが報告されます。
解決策: バックアップファイルが破損している場合は、ソースデータベースの新しい完全バックアップを作成し、新しい移行タスクを作成します。バージョンに互換性がない場合は、ソースデータベースのバージョンと同じかそれ以降のバージョンを実行する ApsaraDB RDS for SQL Server インスタンスを使用します。
説明既存の ApsaraDB RDS for SQL Server インスタンスを新しいバージョンにアップグレードするには、「データベースエンジンバージョンのアップグレード」をご参照ください。
DBCC CHECKDB に失敗した
エラーメッセージ: DBCC checkdb failed.
原因: DBCC CHECKDB 操作中にエラーが発生しました。これは、ソースデータベースにエラーが存在することを示します。
解決策: 次のコマンドを実行してソースデータベースのエラーを修正し、再度データを移行します。
重要このコマンドを実行してエラーを修正すると、データが失われる可能性があります。
DBCC CHECKDB (DBName, REPAIR_ALLOW_DATA_LOSS) WITH NO_INFOMSGS, ALL_ERRORMSGS
容量不足 1
エラーメッセージ: 復元に必要なディスク容量が不足しています (空き容量 (xxx MB) < 必要な容量 (xxx MB))。
原因: ApsaraDB RDS インスタンスの残りのストレージ領域が、バックアップファイルの移行に不足しています。
解決策: インスタンスストレージをアップグレードします。
容量不足 2
エラーメッセージ: ディスク容量不足 (空き容量 xxx MB < bak ファイル xxx MB)。
原因: ApsaraDB RDS インスタンスの残りのストレージ領域がバックアップファイルのサイズよりも小さいです。
解決策: インスタンスストレージをアップグレードします。
ログインアカウントの権限が不十分
エラーメッセージ: ログインで要求されたデータベース "xxx" を開くことができません。ログインに失敗しました。
原因: ApsaraDB RDS インスタンスにログインするために使用されたユーザーアカウントに、データベースへのアクセス権限がありません。
解決策: ApsaraDB RDS インスタンスの [アカウント管理] ページで、ユーザーアカウントにデータベースへのアクセスまたは操作権限を付与します。詳細については、「アカウントへの権限付与」および「異なるアカウントタイプでサポートされる権限」をご参照ください。
特権アカウントがない
エラーメッセージ: お使いの RDS にはまだ初期アカウントがありません。初期アカウントを作成し、RDS コンソールでこの移行されたデータベース (xxx) に権限を付与してください。
原因: ApsaraDB RDS インスタンスに特権アカウントがないため、データ移行タスクはどのユーザーに権限を付与すればよいかわかりません。ただし、バックアップファイルは宛先インスタンスに正常に復元されたため、タスクのステータスは成功です。
解決策: 特権アカウントを作成します。
RAM ユーザーの操作権限が不十分
Q1: データ移行タスクの作成のステップ 5 で、すべての構成パラメーターを入力しましたが、[OK] ボタンがグレーアウトしています。なぜですか?
A1: ボタンが利用できないのは、権限が不十分な RAM ユーザーを使用しているためかもしれません。詳細については、このトピックの前提条件セクションを参照して、必要な権限が付与されていることを確認してください。
Q2: RAM ユーザーを使用して
AliyunRDSImportRoleに権限を付与しようとすると、permission deniedエラーが返されます。これを解決するにはどうすればよいですか?A2: Alibaba Cloud アカウントを使用して、RAM ユーザーに AliyunRAMFullAccess 権限を一時的に追加します。
一般的なリターンメッセージ
タスクタイプ | タスクステータス | タスクの説明 | 説明 |
完全バックアップファイルの 1 回限りのインポート | 成功 |
| 移行は成功です。 |
失敗した |
| OSS ダウンロード URL が期限切れのため、移行に失敗しました。 | |
| バックアップファイルが破損しているか、ApsaraDB RDS インスタンスよりも新しいバージョンであるため、移行に失敗しました。 | ||
| DBCC CHECKDB コマンドが失敗したため、移行に失敗しました。 | ||
| ファイルがログバックアップであるため、移行に失敗しました。 | ||
| ファイルが差分バックアップであるため、移行に失敗しました。 |
関連 API 操作
API | 説明 |
OSS から ApsaraDB RDS for SQL Server インスタンスにバックアップファイルを復元し、データ移行タスクを作成します。 | |
ApsaraDB RDS for SQL Server データ移行タスクのデータベースを開きます。 | |
ApsaraDB RDS for SQL Server インスタンスのデータ移行タスクのリストを照会します。 | |
ApsaraDB RDS for SQL Server データ移行タスクのファイル詳細を照会します。 |