PolarDB for PostgreSQL (Compatible with Oracle) 互換の Flink CDC コネクタ (PolarDBO Flink CDC) は、PolarDB for PostgreSQL (Compatible with Oracle) データベースから完全スナップショットデータと変更データを読み取ります。具体的な特徴と使用方法については、コミュニティの Postgres CDC ドキュメントをご参照ください。
PolarDB for PostgreSQL (Oracle 互換) は、コミュニティ版 PostgreSQL と比べて一部のデータ型および組み込みオブジェクトの扱いのみが異なります。そのため、このトピックでは、コミュニティ版 PostgreSQL CDC をベースに、最小限のコード変更で PolarDB for PostgreSQL (Oracle 互換) をサポートする PolarDBO Flink CDC コネクタの適応およびパッケージング方法を説明します。
PolarDB for PostgreSQL (Oracle 互換) の DATE 型は 64 ビットですが、コミュニティ版 PostgreSQL の DATE 型は 32 ビットです。そのため、PolarDBO Flink CDC では DATE 型データの処理方法を調整しています。
PolarDBO Flink CDC コネクタのパッケージング
PolarDBO Flink CDC コネクタは、コミュニティ版 Postgres CDC をベースに開発されています。Alibaba Cloud は、お客様ご自身でパッケージングされた場合も、本トピックで提供される JAR パッケージを使用した場合も、PolarDBO Flink CDC コネクタに対してサービスレベル契約(SLA)による保証を提供しません。
前提条件
Flink-CDC のバージョンを確認します。
Alibaba Cloud Realtime Compute for Apache Flink を使用する場合は、対応する Ververica Runtime(VVR)バージョンと互換性のあるコミュニティ版 Flink-CDC バージョンを確認してください。詳細については、「CDC と VVR のバージョンマッピング」をご参照ください。
説明Flink-CDC のコードリポジトリについては、Flink-CDC をご参照ください。
Debezium のバージョンを確認します。
対応する Flink-CDC バージョンの
pom.xmlファイル内でキーワードdebezium.versionを検索し、Debezium のバージョンを確認します。説明Debezium のコードリポジトリについては、Debezium をご参照ください。
PgJDBC のバージョンを確認します。
対応する Postgres-CDC バージョンの
pom.xmlファイル内でキーワードorg.postgresqlを検索し、PgJDBC のバージョンを確認します。説明release-3.0 より前のバージョンの場合、ファイルパスは次のとおりです:
flink-connector-postgres-cdc/pom.xml。release-3.0 以降のバージョンの場合、ファイルパスは次のとおりです:
flink-cdc-connect/flink-cdc-source-connectors/flink-connector-postgres-cdc/pom.xml。PgJDBC のコードリポジトリについては、PgJDBC をご参照ください。
操作手順
パッケージ リリース 3.5
コミュニティ版 Flink-CDC release-3.5 は、Alibaba Cloud Realtime Compute for Apache Flink の vvr-11.4-jdk11-flink-1.20 と互換性があります。
対応するバージョンの PolarDB Flink CDC コネクタをパッケージングするには、以下の手順に従います。
指定されたバージョンの Flink-CDC、Debezium、および PgJDBC のソースコードをクローンします。
git clone -b release-3.5 --depth=1 https://github.com/apache/flink-cdc.git git clone -b REL42.7.3 --depth=1 https://github.com/pgjdbc/pgjdbc.git git clone -b v1.9.8.Final --depth=1 https://github.com/debezium/debezium.gitDebezium および PgJDBC から選択したファイルを Flink-CDC にコピーします。
mkdir -p flink-cdc/flink-cdc-connect/flink-cdc-source-connectors/flink-connector-postgres-cdc/src/main/java/org/postgresql/core/v3 mkdir -p flink-cdc/flink-cdc-connect/flink-cdc-source-connectors/flink-connector-postgres-cdc/src/main/java/org/postgresql/jdbc cp pgjdbc/pgjdbc/src/main/java/org/postgresql/core/v3/ConnectionFactoryImpl.java flink-cdc/flink-cdc-connect/flink-cdc-source-connectors/flink-connector-postgres-cdc/src/main/java/org/postgresql/core/v3 cp pgjdbc/pgjdbc/src/main/java/org/postgresql/core/v3/QueryExecutorImpl.java flink-cdc/flink-cdc-connect/flink-cdc-source-connectors/flink-connector-postgres-cdc/src/main/java/org/postgresql/core/v3 cp pgjdbc/pgjdbc/src/main/java/org/postgresql/jdbc/PgDatabaseMetaData.java flink-cdc/flink-cdc-connect/flink-cdc-source-connectors/flink-connector-postgres-cdc/src/main/java/org/postgresql/jdbc cp pgjdbc/pgjdbc/src/main/java/org/postgresql/core/Oid.java flink-cdc/flink-cdc-connect/flink-cdc-source-connectors/flink-connector-postgres-cdc/src/main/java/org/postgresql/core cp debezium/debezium-connector-postgres/src/main/java/io/debezium/connector/postgresql/TypeRegistry.java flink-cdc/flink-cdc-connect/flink-cdc-source-connectors/flink-connector-postgres-cdc/src/main/java/io/debezium/connector/postgresqlFlink-CDC ディレクトリに移動し、タイムスタンプ変換のバグ修正 および 暗黙的動作(SELECT *)のバグ修正 を適用します。これらの修正は、コミュニティ版 3.6 リリースにマージされる予定です。
cd flink-cdc # Apply the timestamp conversion bug fix. It will be merged into the community 3.6 release. git fetch origin 2f32836a783f80f295c9dce339c11afec2a32dc2 git cherry-pick 2f32836a783f80f295c9dce339c11afec2a32dc2 git fetch origin 0d86de24494a855c2d83f9b1052c2e888e182cb1 git cherry-pick 0d86de24494a855c2d83f9b1052c2e888e182cb1PolarDB for PostgreSQL (Oracle 互換) のサポートを追加するパッチファイルを適用します。
git apply release-3.5_support_polardbo.patch説明上記で使用するパッチファイルは、release-3.5_support_polardbo.patch です。
Maven を使用して PolarDB for PostgreSQL Flink CDC コネクタをパッケージングします。
mvn clean install -DskipTests -Dcheckstyle.skip=true -Dspotless.check.skip # After packaging, find the JAR file in flink-cdc-connect/flink-cdc-pipeline-connectors/flink-cdc-pipeline-connector-postgres/target.
上記の手順に従い、JDK 11 を使用して PolarDBO Flink CDC コネクタの JAR パッケージをビルドします:flink-cdc-pipeline-connector-polardbo-3.5-SNAPSHOT-20260212.jar。
パッケージ リリース-3.1
コミュニティ版 Flink-CDC release-3.1 は、Alibaba Cloud Realtime Compute for Apache Flink の vvr-8.0.x-flink-1.17 と互換性があります。
対応するバージョンの PolarDB Flink CDC コネクタをパッケージングするには、以下の手順に従います。
Flink-CDC、Debezium、および PgJDBC のコードファイルをクローンします。
git clone -b release-3.1 --depth=1 https://github.com/apache/flink-cdc.git git clone -b REL42.5.1 --depth=1 https://github.com/pgjdbc/pgjdbc.git git clone -b v1.9.8.Final --depth=1 https://github.com/debezium/debezium.gitDebezium および PgJDBC から特定のファイルを Flink-CDC にコピーします。
mkdir -p flink-cdc/flink-cdc-connect/flink-cdc-source-connectors/flink-connector-postgres-cdc/src/main/java/org/postgresql/core/v3 mkdir -p flink-cdc/flink-cdc-connect/flink-cdc-source-connectors/flink-connector-postgres-cdc/src/main/java/org/postgresql/jdbc cp pgjdbc/pgjdbc/src/main/java/org/postgresql/core/v3/ConnectionFactoryImpl.java flink-cdc/flink-cdc-connect/flink-cdc-source-connectors/flink-connector-postgres-cdc/src/main/java/org/postgresql/core/v3 cp pgjdbc/pgjdbc/src/main/java/org/postgresql/core/v3/QueryExecutorImpl.java flink-cdc/flink-cdc-connect/flink-cdc-source-connectors/flink-connector-postgres-cdc/src/main/java/org/postgresql/core/v3 cp pgjdbc/pgjdbc/src/main/java/org/postgresql/jdbc/PgDatabaseMetaData.java flink-cdc/flink-cdc-connect/flink-cdc-source-connectors/flink-connector-postgres-cdc/src/main/java/org/postgresql/jdbc cp debezium/debezium-connector-postgres/src/main/java/io/debezium/connector/postgresql/TypeRegistry.java flink-cdc/flink-cdc-connect/flink-cdc-source-connectors/flink-connector-postgres-cdc/src/main/java/io/debezium/connector/postgresqlPolarDB for PostgreSQL (Oracle 互換) との互換性を確保するためのパッチファイルを適用します。
git apply release-3.1_support_polardbo.patch説明PolarDBO Flink CDC 互換性用のパッチファイルは、release-3.1_support_polardbo.patch です。
Maven を使用して PolarDBO Flink CDC コネクタをパッケージングします。
mvn clean install -DskipTests -Dcheckstyle.skip=true -Dspotless.check.skip -Drat.skip=true # After the packaging is complete, find the JAR package in the target folder of flink-sql-connector-postgres-cdc
上記のプロセスに従い、JDK 8 を使用して PolarDB Flink CDC コネクタの JAR ファイルをパッケージングします:flink-sql-connector-postgres-cdc-3.1-SNAPSHOT.jar。
release-2.3 のパッケージング
コミュニティ版 Flink-CDC release-2.3 は、Alibaba Cloud Realtime Compute for Apache Flink の vvr-4.0.15-flink-1.13 から vvr-6.0.2-flink-1.15 と互換性があります。
対応するバージョンの PolarDB-O Flink CDC コネクタをパッケージングするには、以下の手順に従います。
対応するバージョンの Flink-CDC、Debezium、および PgJDBC のソースコードをクローンします。
git clone -b release-2.3 --depth=1 https://github.com/apache/flink-cdc.git git clone -b REL42.2.26 --depth=1 https://github.com/pgjdbc/pgjdbc.git git clone -b v1.6.4.Final --depth=1 https://github.com/debezium/debezium.gitDebezium および PgJDBC から選択したファイルを Flink-CDC にコピーします。
mkdir -p flink-cdc/flink-connector-postgres-cdc/src/main/java/org/postgresql/core/v3 mkdir -p flink-cdc/flink-connector-postgres-cdc/src/main/java/org/postgresql/jdbc mkdir -p flink-cdc/flink-connector-postgres-cdc/src/main/java/io/debezium/connector/postgresql cp pgjdbc/pgjdbc/src/main/java/org/postgresql/core/v3/ConnectionFactoryImpl.java flink-cdc/flink-connector-postgres-cdc/src/main/java/org/postgresql/core/v3 cp pgjdbc/pgjdbc/src/main/java/org/postgresql/core/v3/QueryExecutorImpl.java flink-cdc/flink-connector-postgres-cdc/src/main/java/org/postgresql/core/v3 cp pgjdbc/pgjdbc/src/main/java/org/postgresql/jdbc/PgDatabaseMetaData.java flink-cdc/flink-connector-postgres-cdc/src/main/java/org/postgresql/jdbc cp debezium/debezium-connector-postgres/src/main/java/io/debezium/connector/postgresql/TypeRegistry.java flink-cdc/flink-connector-postgres-cdc/src/main/java/io/debezium/connector/postgresqlPolarDB for PostgreSQL (Oracle 互換) との互換性を確保するためのパッチファイルを適用します。
git apply release-2.3_support_polardbo.patch説明上記で使用するパッチファイルは、release-2.3_support_polardbo.patch です。
Maven を使用して PolarDB for PostgreSQL Flink CDC コネクタをパッケージングします。
mvn clean install -DskipTests -Dcheckstyle.skip=true -Dspotless.check.skip -Drat.skip=true # After packaging completes, find the JAR file in the target folder of flink-sql-connector-postgres-cdc
上記の手順に従い、JDK 8 を使用して PolarDBO Flink CDC コネクタの JAR をパッケージングします:flink-sql-connector-postgres-cdc-2.3-SNAPSHOT.jar。
使用方法
PolarDBO Flink CDC コネクタは、PolarDB for PostgreSQL (Oracle 互換) データベースから論理レプリケーションを使用して変更ストリームデータを読み取ります。以下の条件を満たす必要があります。
wal_levelパラメーターをlogicalに設定します。これにより、先行書き込みログ(WAL)に論理レプリケーションをサポートするために必要な情報が追加されます。説明wal_level パラメーターはコンソールで設定できます。詳細な操作手順については、「クラスターパラメーターの設定」をご参照ください。このパラメーターを変更するとクラスターが再起動します。ビジネス運用に影響を与えないよう、事前に計画を立てて慎重に操作してください。
ALTER TABLE schema.table REPLICA IDENTITY FULL;コマンドを実行し、サブスクライブするテーブルのREPLICA IDENTITYをFULLに設定します。これにより、テーブルのデータ同期の一貫性が保証され、出力される INSERT イベントおよび UPDATE イベントにテーブルのすべての列の古い値が含まれるようになります。説明REPLICA IDENTITY は PostgreSQL におけるテーブル単位の固有設定です。INSERT および UPDATE イベント時に論理デコーディングプラグインが影響を受けたテーブル列の古い値を含めるかどうかを決定します。各値の意味の詳細については、REPLICA IDENTITY をご参照ください。
サブスクライブするテーブルの
REPLICA IDENTITYをFULLに設定すると、テーブルがロックされる可能性があり、ビジネス運用に影響を与えることがあります。パラメーターを変更する前にビジネス運用を計画してください。現在の設定がFULLであるかを確認するには、次のコマンドを使用します。SELECT relreplident = 'f' FROM pg_class WHERE relname = 'tablename';
max_wal_senders および max_replication_slots パラメーターの両方の値が、現在使用中のデータベースレプリケーションスロット数と Flink ジョブに必要なスロット数の合計よりも大きいことを確認します。
完全データクエリのために、特権アカウントまたは LOGIN 権限および REPLICATION 権限、さらにサブスクライブするテーブルに対する SELECT 権限を持つアカウントを使用します。
PolarDB クラスターのプライマリエンドポイントにのみ接続します。クラスターエンドポイントは論理レプリケーションをサポートしていません。
Release-3.5 以降のバージョンでは、パーティションテーブルの親テーブルの直接同期がサポートされています。以下のとおり設定します。特定の操作については、「Postgres CDC コミュニティ ドキュメント」をご参照ください。
scan.include-partitioned-tables.enabledをtrueに設定します。データベース内に
publish_via_partition_root=trueオプション付きで手動でPUBLICATIONを作成します。また、debezium.publication.nameパラメーターを使用してtable-nameを指定します。table-nameでは親テーブルのみを指定できます。正規表現で子テーブルに一致しないようにしてください。一致すると、完全データが重複して取得されます。
さらに、リリース 3.5 以降のバージョンでは、スナップショットデータおよび増分データの読み取りを可能にするパイプライン コネクタがサポートされており、エンドツーエンドの完全なデータベース データ同期機能を提供します。ただし、パイプライン コネクタは現在、テーブル スキーマの変更の同期をサポートしていません。詳細については、「Postgres CDC パイプライン コネクタのコミュニティ ドキュメント」をご参照ください。
PolarDBO Flink CDC コネクタと Postgres CDC の比較
PolarDBO Flink CDC コネクタは、Postgres CDC に基づいてパッケージ化されています。 構文とパラメーターの詳細については、「Postgres CDC」をご参照ください。 ただし、以下の主な相違点があります。
WITH 句内のコネクタパラメーターは、静的フィールド
polardbo-cdcに設定する必要があります。PolarDBO Flink CDC は、PolarDB for PostgreSQL のすべてのバージョン、PolarDB for PostgreSQL (Oracle 互換) 1.0、および PolarDB for PostgreSQL (Oracle 互換) 2.0 と互換性があります。
説明PolarDB for PostgreSQL を使用する場合は、コミュニティの Postgres CDC を直接使用することをお勧めします。
PolarDB for PostgreSQL (Oracle 互換) 1.0 および PolarDB for PostgreSQL (Oracle 互換) 2.0 の
DATE型の列について、Flink SQL のソーステーブルおよび結果テーブルで対応する型をTIMESTAMPとして指定する必要があります。decoding.plugin.nameパラメーターをpgoutputに設定します。設定しない場合、UTF-8 以外のエンコードを使用しているデータベースで増分解析時に文字化けが発生する可能性があります。詳細については、コミュニティドキュメント をご参照ください。
型のマッピング
PolarDB PostgreSQL と Flink 間のフィールド型のマッピングは、DATE 型を除き、コミュニティ版 PostgreSQL と同一です。具体的なマッピングは以下のとおりです。
PolarDB for PostgreSQL のフィールド型 | Flink のフィールド型 |
SMALLINT | SMALLINT |
INT2 | |
SMALLSERIAL | |
SERIAL2 | |
INTEGER | INT |
SERIAL | |
BIGINT | BIGINT |
BIGSERIAL | |
REAL | FLOAT |
FLOAT4 | |
FLOAT8 | DOUBLE |
DOUBLE PRECISION | |
NUMERIC(p, s) | DECIMAL(p, s) |
DECIMAL(p, s) | |
BOOLEAN | BOOLEAN |
DATE |
|
TIME [(p)] [WITHOUT TIMEZONE] | TIME [(p)] [WITHOUT TIMEZONE] |
TIMESTAMP [(p)] [WITHOUT TIMEZONE] | TIMESTAMP [(p)] [WITHOUT TIMEZONE] |
CHAR(n) | STRING |
CHARACTER(n) | |
VARCHAR(n) | |
CHARACTER VARYING(n) | |
TEXT | |
BYTEA | BYTES |
使用例
ソースコネクタ
以下の例では、PolarDB for PostgreSQL (Oracle 互換) 2.0 クラスターの flink_source データベースにある shipments テーブルを、PolarDBO Flink CDC を使用して flink_sink データベースの shipments_sink テーブルに同期する方法を示します。
この例では、パッケージ化された PolarDBO Flink CDC が PolarDB for PostgreSQL(Oracle互換) 上で実行できることのみを検証しています。本番環境での使用に際しては、コミュニティの Postgres CDC ドキュメントを参照し、必要に応じてパラメーターを設定してください。
前提条件
PolarDB for PostgreSQL (Oracle 互換) の準備
PolarDB クラスター購入ページで PolarDB for PostgreSQL (Oracle 互換) 2.0 クラスターを購入します。
特権アカウントを作成します。
クラスターのプライマリエンドポイントを確認します。PolarDB クラスターと Realtime Compute for Apache Flink が同一の仮想プライベートクラウド(VPC)内にある場合は、プライベートエンドポイントを直接使用できます。それ以外の場合は、パブリックエンドポイントを申請してください。
クラスターホワイトリストを設定します:PolarDB クラスターホワイトリストに Flink インスタンスのアドレスを追加します。
コンソールでソースデータベース flink_source およびターゲットデータベース flink_sink を作成します。詳細な手順については、「データベースの作成」をご参照ください。
ソースデータベース flink_source に shipments テーブルを作成し、データを挿入するための次の文を実行します。
CREATE TABLE public.shipments ( shipment_id INT, order_id INT, origin TEXT, destination TEXT, is_arrived BOOLEAN, order_time DATE, PRIMARY KEY (shipment_id) ); ALTER TABLE public.shipments REPLICA IDENTITY FULL; INSERT INTO public.shipments SELECT 1, 1, 'test1', 'test1', false, now();ターゲットデータベース flink_sink に shipments_sink テーブルを作成するための次の文を実行します。
CREATE TABLE public.shipments_sink ( shipment_id INT, order_id INT, origin TEXT, destination TEXT, is_arrived BOOLEAN, order_time TIMESTAMP, PRIMARY KEY (shipment_id) );
Realtime Compute for Apache Flink の準備
Realtime Compute コンソールにログインし、Realtime Compute for Apache Flink インスタンスを購入します。詳細については、「Realtime Compute for Apache Flink の購入」をご参照ください。
説明Realtime Compute for Apache Flink のリージョンおよび仮想プライベートクラウド(VPC)は、PolarDB クラスターと一致させることを推奨します。接続アドレスとして、PolarDB クラスターのプライマリエンドポイントのプライベートエンドポイントを直接使用できます。
カスタムコネクタを作成し、パッケージング済みの PolarDBO Flink CDC をアップロードします。フォーマット は debezium-json に設定します。詳細な手順については、「カスタムコネクタの作成」をご参照ください。
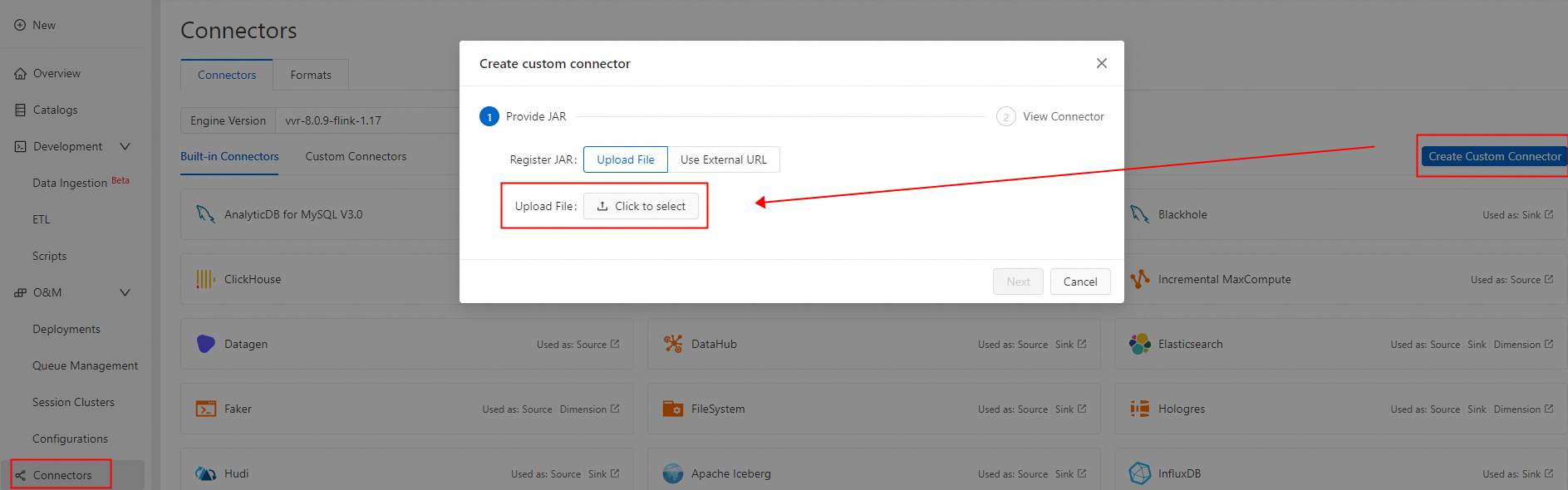
-
Flink ジョブの作成
-
Realtime Compute コンソールにログインし、新しい SQL ジョブの下書きを作成します。ガイドについては、「ジョブ開発マップ」をご参照ください。以下の Flink SQL 文を使用します。PolarDB クラスターのプライマリエンドポイント、ポート、ユーザー名、パスワードを実際の値に置き換えてください。
説明PolarDB for PostgreSQL (Oracle 互換) の DATE 型は 64 ビットです。一方、Flink SQL およびほとんどのデータベースの DATE 型は 32 ビットです。そのため、ソーステーブルの DATE 型の列は、Flink SQL のソーステーブルおよび結果テーブルの両方で TIMESTAMP として定義する必要があります。定義しない場合、「
“java.time.DateTimeException: Invalid value for EpochDay (valid values -365243219162 - 365241780471): 1720891573000”」などの型不一致エラーによりジョブが失敗します。CREATE TEMPORARY TABLE shipments ( shipment_id INT, order_id INT, origin STRING, destination STRING, is_arrived BOOLEAN, order_time TIMESTAMP, PRIMARY KEY (shipment_id) NOT ENFORCED ) WITH ( 'connector' = 'polardbo-cdc', 'hostname' = '<yourHostname>', 'port' = '<yourPort>', 'username' = '<yourUserName>', 'password' = '<yourPassWord>', 'database-name' = 'flink_source', 'schema-name' = 'public', 'table-name' = 'shipments', 'decoding.plugin.name' = 'pgoutput', 'slot.name' = 'flink' ); CREATE TEMPORARY TABLE shipments_sink ( shipment_id INT, order_id INT, origin STRING, destination STRING, is_arrived BOOLEAN, order_time TIMESTAMP, PRIMARY KEY (shipment_id) NOT ENFORCED ) WITH ( 'connector' = 'jdbc', 'url' = 'jdbc:postgresql://<yourHostname>:<yourPort>/flink_sink', 'table-name' = 'shipments_sink', 'username' = '<yourUserName>', 'password' = '<yourPassWord>' ); INSERT INTO shipments_sink SELECT * FROM shipments; -
ジョブをデプロイして開始します。

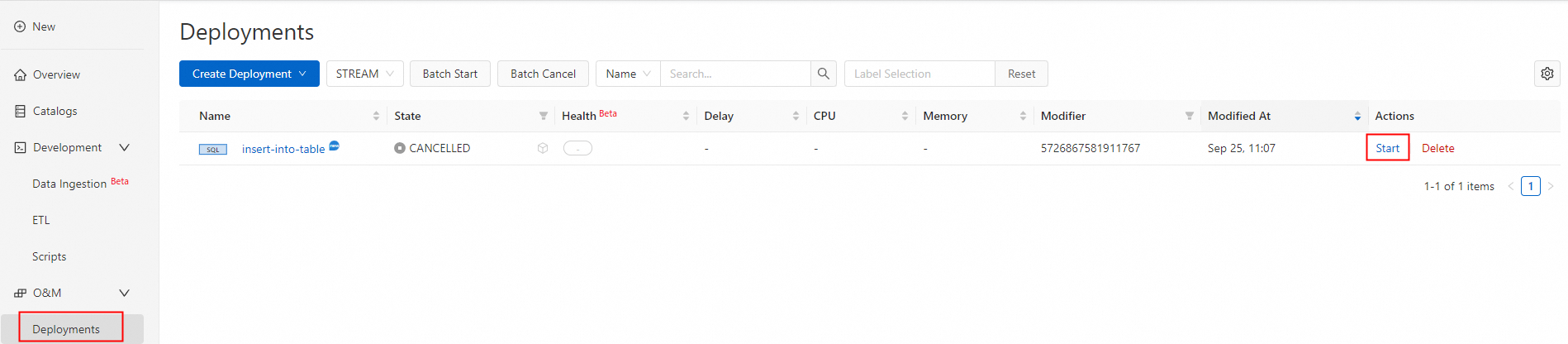
-
テストおよび検証を行います。
-
ジョブが正常にデプロイされ、ステータスが実行中に変わると、shipments テーブルのデータがターゲットデータベース flink_sink の shipments_sink テーブルに同期されます。
SELECT * FROM public.shipments_sink;結果は以下のとおりです。
shipment_id | order_id | origin | destination | is_arrived | order_time -------------+----------+--------+-------------+------------+--------------------- 1 | 1 | test1 | test1 | f | 2024-09-18 05:45:08 (1 row) -
ソースデータベース flink_source の shipments テーブルに対して DML 文を実行します。新しい挿入および更新はリアルタイムで同期されます。
INSERT INTO public.shipments SELECT 2, 2, 'test2', 'test2', false, now(); UPDATE public.shipments SET is_arrived = true WHERE shipment_id = 1; DELETE FROM public.shipments WHERE shipment_id = 2; INSERT INTO public.shipments SELECT 3, 3, 'test3', 'test3', false, now(); UPDATE public.shipments SET is_arrived = true WHERE shipment_id = 3;shipments テーブルのデータは、ターゲットデータベース flink_sink の shipments_sink テーブルに同期されます。
SELECT * FROM public.shipments_sink;結果は以下のとおりです。
shipment_id | order_id | origin | destination | is_arrived | order_time -------------+----------+--------+-------------+------------+--------------------- 1 | 1 | test1 | test1 | t | 2024-09-18 05:45:08 3 | 3 | test3 | test3 | t | 2024-09-18 07:33:23 (2 rows)
-
-
パイプラインコネクタ
以下の例では、PolarDB for PostgreSQL (Oracle 互換) 2.0 クラスターの flink_source データベースにある shipments1 および shipments2 テーブルを、PolarDBO Flink CDC パイプラインコネクタを使用して同期する方法を示します。デバッグ中は、Print コネクタ を使用します。本番環境では、必要に応じて適切なコネクタを選択してください。
この例では、パッケージ化された PolarDBO Flink CDC が PolarDB for PostgreSQL(Oracle互換) 上で実行できることのみを検証しています。本番環境での使用に際しては、コミュニティの Postgres CDC パイプライン コネクタ のドキュメントを参照し、実際のビジネス要件を満たすように関連パラメーターを設定してください。
前提条件
PolarDB for PostgreSQL (Oracle 互換) の準備
PolarDB クラスター購入ページで PolarDB for PostgreSQL (Oracle 互換) 2.0 クラスターを購入します。
特権アカウントを作成します。
クラスターのプライマリエンドポイントを確認します。PolarDB クラスターと Realtime Compute for Apache Flink が同一の仮想プライベートクラウド(VPC)内にある場合は、プライベートエンドポイントを直接使用できます。それ以外の場合は、パブリックエンドポイントを申請してください。
クラスターホワイトリストを設定します:PolarDB クラスターホワイトリストに Flink インスタンスのアドレスを追加します。
コンソールでソースデータベース flink_source を作成します。詳細な手順については、「データベースの作成」をご参照ください。
ソースデータベース flink_source に shipments1 および shipments2 テーブルを作成し、データを挿入するための次の文を実行します。
CREATE TABLE public.shipments1 ( shipment_id INT, order_id INT, origin TEXT, destination TEXT, is_arrived BOOLEAN, order_time DATE, PRIMARY KEY (shipment_id) ); ALTER TABLE public.shipments1 REPLICA IDENTITY FULL; INSERT INTO public.shipments1 SELECT 1, 1, 'test1', 'test1', false, now(); CREATE TABLE public.shipments2 ( shipment_id INT, order_id INT, origin TEXT, destination TEXT, is_arrived BOOLEAN, order_time DATE, PRIMARY KEY (shipment_id) ); ALTER TABLE public.shipments2 REPLICA IDENTITY FULL; INSERT INTO public.shipments2 SELECT 1, 1, 'test1', 'test1', false, now();
Realtime Compute for Apache Flink の準備
Realtime Compute コンソールにログインし、Realtime Compute for Apache Flink インスタンスを購入します。詳細な操作手順については、「Realtime Compute for Apache Flink の有効化」をご参照ください。
説明Realtime Compute for Apache Flink のリージョンおよび仮想プライベートクラウド(VPC)は、PolarDB クラスターと一致させることを推奨します。接続アドレスとして、PolarDB クラスターのプライマリエンドポイントのプライベートエンドポイントを直接使用できます。
Flink ジョブの作成
Realtime Compute コンソールにログインし、新しいデータインジェストの下書きを作成します。「Flink CDC データインジェストジョブ クイックスタート」をご参照ください。以下のデータインジェスト構成を使用し、PolarDB クラスターのプライマリエンドポイント、ポート、アカウント、パスワードを変更します。
source: type: polardbo name: PolarDB Oracle Source hostname: '<yourHostname>' port: '<yourPort>' username: '<yourUserName>' password: '<yourPassWord>' tables: flink_source.public.shipments[12] decoding.plugin.name: pgoutput slot.name: pgtest sink: type: values name: values Sink print.enabled: true左側の詳細設定に、正常にパッケージングされたパイプラインコネクタを追加します。

ジョブをデプロイして開始します。
右上隅のデプロイをクリックします。

ジョブの O&M ページに移動し、開始をクリックします。

テストおよび検証を行います。
ジョブが正常にデプロイされ実行状態になると、 ログに完全データフェーズの CreateTableEvent および DataChangeEvent が表示されます。
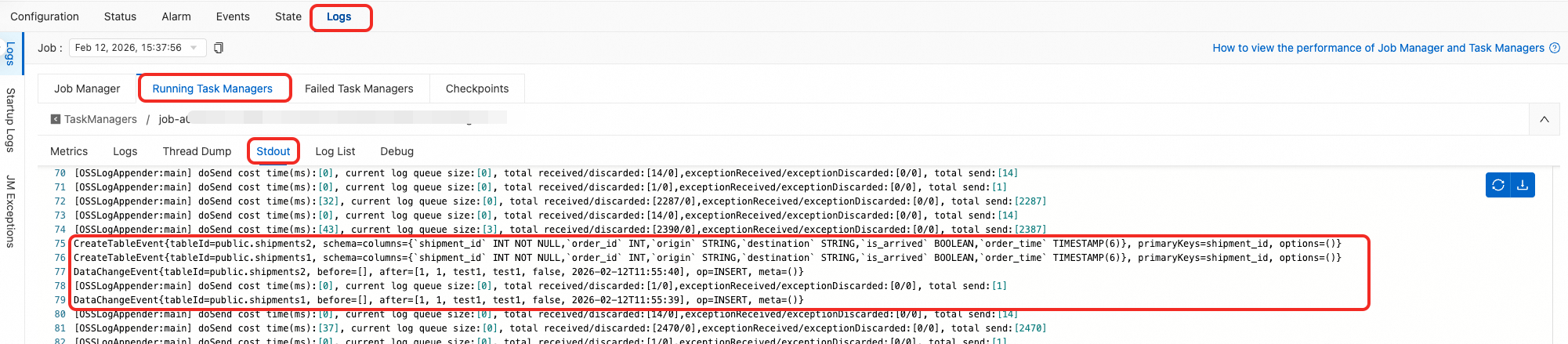
CreateTableEvent{tableId=public.shipments2, schema=columns={`shipment_id` INT NOT NULL,`order_id` INT,`origin` STRING,`destination` STRING,`is_arrived` BOOLEAN,`order_time` TIMESTAMP(6)}, primaryKeys=shipment_id, options=()} CreateTableEvent{tableId=public.shipments1, schema=columns={`shipment_id` INT NOT NULL,`order_id` INT,`origin` STRING,`destination` STRING,`is_arrived` BOOLEAN,`order_time` TIMESTAMP(6)}, primaryKeys=shipment_id, options=()} DataChangeEvent{tableId=public.shipments2, before=[], after=[1, 1, test1, test1, false, 2026-01-07T16:30:44], op=INSERT, meta=()} DataChangeEvent{tableId=public.shipments1, before=[], after=[1, 1, test1, test1, false, 2026-01-07T16:30:44], op=INSERT, meta=()}ソースデータベース flink_source の shipments1 および shipments2 テーブルに対して DML を実行します。新しい追加および変更もリアルタイムで同期されます。
INSERT INTO public.shipments1 SELECT 2, 2, 'test2', 'test2', false, now(); UPDATE public.shipments1 SET is_arrived = true WHERE shipment_id = 1; DELETE FROM public.shipments1 WHERE shipment_id = 2; INSERT INTO public.shipments1 SELECT 3, 3, 'test3', 'test3', false, now(); UPDATE public.shipments1 SET is_arrived = true WHERE shipment_id = 3; INSERT INTO public.shipments2 SELECT 2, 2, 'test2', 'test2', false, now(); UPDATE public.shipments2 SET is_arrived = true WHERE shipment_id = 1; DELETE FROM public.shipments2 WHERE shipment_id = 2; INSERT INTO public.shipments2 SELECT 3, 3, 'test3', 'test3', false, now(); UPDATE public.shipments2 SET is_arrived = true WHERE shipment_id = 3;ログに増分データフェーズの DataChangeEvent が表示されます。
DataChangeEvent{tableId=public.shipments1, before=[], after=[2, 2, test2, test2, false, 2026-01-07T16:44:50], op=INSERT, meta=()} DataChangeEvent{tableId=public.shipments1, before=[1, 1, test1, test1, false, 2026-01-07T16:30:44], after=[1, 1, test1, test1, true, 2026-01-07T16:30:44], op=UPDATE, meta=()} DataChangeEvent{tableId=public.shipments1, before=[2, 2, test2, test2, false, 2026-01-07T16:44:50], after=[], op=DELETE, meta=()} DataChangeEvent{tableId=public.shipments1, before=[], after=[3, 3, test3, test3, false, 2026-01-07T16:44:50], op=INSERT, meta=()} DataChangeEvent{tableId=public.shipments1, before=[3, 3, test3, test3, false, 2026-01-07T16:44:50], after=[3, 3, test3, test3, true, 2026-01-07T16:44:50], op=UPDATE, meta=()} DataChangeEvent{tableId=public.shipments2, before=[], after=[2, 2, test2, test2, false, 2026-01-07T16:44:50], op=INSERT, meta=()} DataChangeEvent{tableId=public.shipments2, before=[1, 1, test1, test1, false, 2026-01-07T16:30:44], after=[1, 1, test1, test1, true, 2026-01-07T16:30:44], op=UPDATE, meta=()} DataChangeEvent{tableId=public.shipments2, before=[2, 2, test2, test2, false, 2026-01-07T16:44:50], after=[], op=DELETE, meta=()} DataChangeEvent{tableId=public.shipments2, before=[], after=[3, 3, test3, test3, false, 2026-01-07T16:44:50], op=INSERT, meta=()} DataChangeEvent{tableId=public.shipments2, before=[3, 3, test3, test3, false, 2026-01-07T16:44:50], after=[3, 3, test3, test3, true, 2026-01-07T16:44:50], op=UPDATE, meta=()}