ROLLUP構文を使用して、1つのクエリステートメントのみを使用して、データを異なるディメンションにグループ化した後のすべてのデータの統計結果と全体的な値を計算できます。 このトピックでは、ROLLUP構文の使用方法について説明します。
前提条件
お使いのクラスターはPolarDB for MySQL 8.0で、リビジョンバージョンは8.0.1.1.0以降です。 クラスターのバージョンを照会する方法の詳細については、「エンジンクラスターの照会」をご参照ください。
構文
ROLLUPシンタックスは、GROUP BYシンタックスの拡張とみなすことができる。 GROUP BYで指定した元の列の後にWITH ROLLUPを追加するだけです。 例:
SELECT年、国、製品、SUM (利益) として利益
販売から
年、国、ROLLUPのプロダクトによるグループ; ROLLUPは、GROUP BYで指定された列ごとに集計結果を生成し、すべてのデータが集計されるまで、より高いレベルの集計結果を右から左に計算します。 上記の例では、総収益は、GROUP BY year、country、product (最優先) GROUP BY year、country (2次優先) 、GROUP BY year (最低優先) の句の順序に基づいて計算されます。 次に、売上テーブル全体の総収益が計算されます。 テーブルの総収益の計算中、GROUP BYは無視されます。
ROLLUPオプションには、次の利点があり。
ROLLUPは、多次元統計分析を容易にし、多次元分析のためのSQLクエリの複雑さを低減する。
ROLLUPはクエリの処理効率を向上させます。
ROLLUPを使用すると、サーバーはすべての集計操作を実行できます。 クライアントは、統計を収集するために一度だけデータにアクセスできます。 これにより、クライアントの処理負荷とネットワークトラフィックが削減されます。 ROLLUPを使用しない場合は、複数のクエリを実行して同じ統計を収集する必要があります。
ROLLUPを使用した後の並列クエリのパフォーマンスのテスト
PolarDBは、ROLLUPを使用して並列クエリの機能を向上させます。 ROLLUPを使用すると、複数のスレッドがデータを並行して集計し、集計結果を生成できます。 これにより、ステートメントの実行効率が向上します。
TPCベンチマークH (TPC-H) をテストに使用します。 次の例では、最初のSQLクエリが使用されています。 次のステートメントでは、GROUP BY句にROLLUPが追加されています。
この例では、TPC-Hベンチマークに基づくテストが実装されていますが、TPC-Hベンチマークテストのすべての要件を満たしているわけではありません。 そのため、テスト結果は TPC-H のベンチマークテストの公開結果と一致しない可能性があります。
select
l_returnflag、
l_linestatus,
sum(l_quantity) as sum_qty,
sum(l_extendedprice) as sum_base_price,
sum(l_extendedprice * (1 - l_discount)) as sum_disc_price,
sum(l_extendedprice * (1 - l_discount) * (1 + l_tax)) as sum_charge,
avg(l_quantity) をavg_qtyとして、
avg(l_extendedprice) as avg_price,
avg(l_discount) as avg_disc,
count(*) as count_order
から
lineitem
ここで
l_shipdate <= date_sub('1998-12-01 '、間隔':1' 日)
グループによって
l_returnflag、
l_linestatus
ロールアップ付き
による注文
l_returnflag、
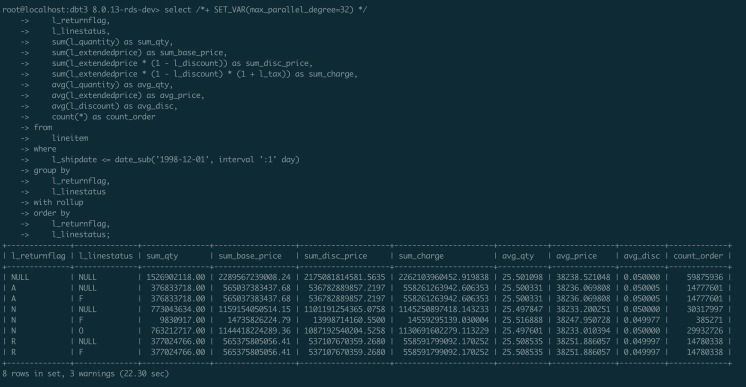
l_linestatus; 並列クエリを無効にすると、318.73が使用されてステートメントが実行されます。
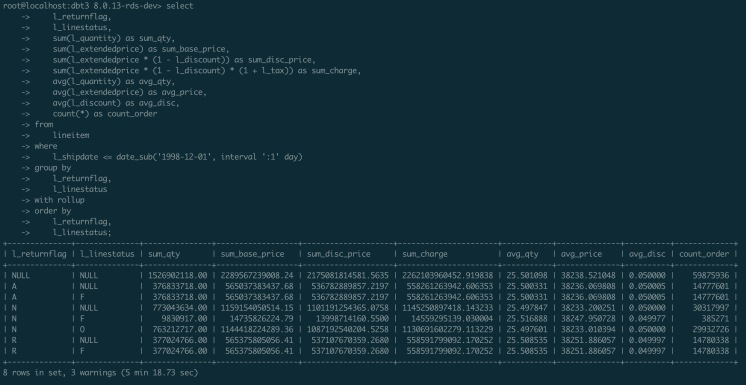
並列クエリを有効にすると、22.30が使用されてステートメントが実行されます。 ステートメントの実行効率は14倍以上向上します。