ハッシュ結合は、MySQL Community Edition 8.0で導入された新しい結合実行方法です。 分析クエリの実行パフォーマンスを大幅に向上させることができます。 PolarDB for MySQLは、ハッシュ結合の並列実行を8.0サポートしています。 より多くの並列実行ポリシーが開発中であり、将来リリースされる予定です。 このトピックでは、PolarDBの並列クエリにハッシュ結合を使用する方法について説明します。
単純ハッシュ結合
前提条件
Cluster EditionクラスターのPolarDB for MySQL 8.0が使用され、クラスターのリビジョンバージョンは8.0.2.1.0以降です。 クラスターバージョンを確認する方法の詳細については、「エンジンバージョン5.6、5.7、8.0」をご参照ください。
Parallel executionポリシー 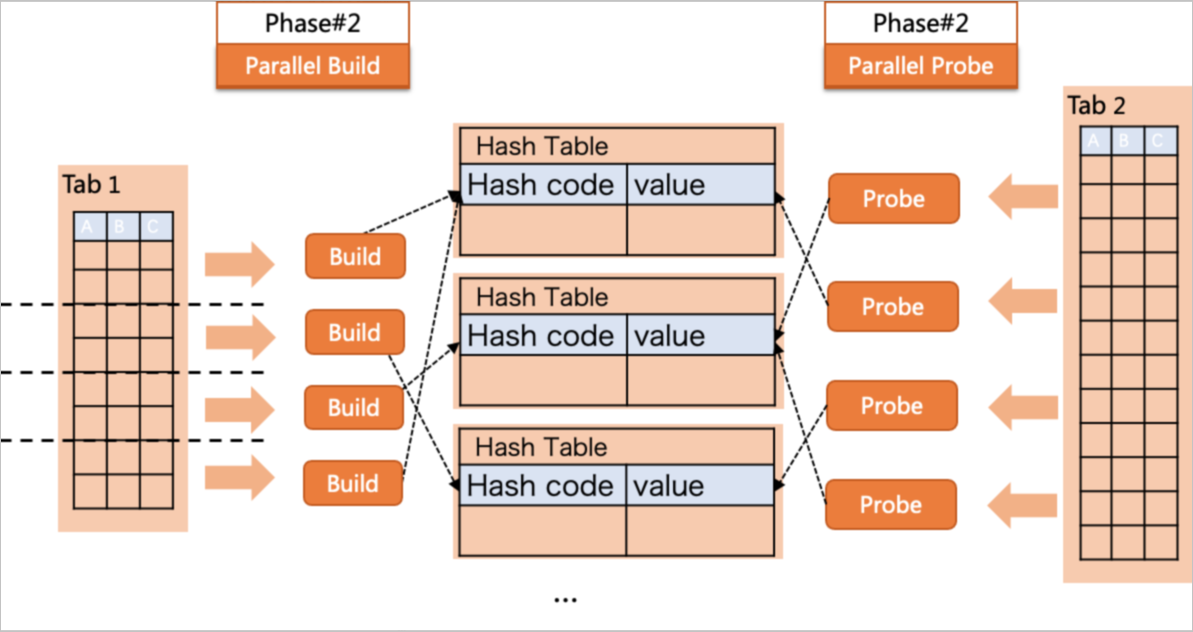
上記の実行プランでは、並列度 (DOP) が4に設定されています。これは、PolarDBが4つのワーカーを使用して並列クエリを実行することを示しています。 まず、4人の作業員がテーブルt1を並行してスキャンする。 各ワーカーは、テーブルt1のデータの一部のみを使用してハッシュテーブルを作成します。 次に、4つのハッシュテーブルとテーブルt2との間でJOIN演算が実行される。 最後に、リーダーは結合された結果を収集して最終クエリ結果を生成します。
使用法
構文:
PolarDBでは、
EXPLAIN FORMAT=TREEステートメントのみを実行して、ハッシュ結合が使用されているかどうかを確認できます。例:
次の例では、2つのテーブルが作成され、データがテーブルに挿入されます。
CREATE TABLE t1 (c1 INT, c2 INT); CREATE TABLE t2 (c1 INT, c2 INT); INSERT t1(c1, c2) WITH RECURSIVE seq AS ( SELECT 1 AS a, 1 AS b UNION ALL SELECT a + 1, b + 1 FROM seq WHERE a < 1000 ) SELECT a,b FROM seq; INSERT INTO t2 SELECT * FROM t1;次のSELECTステートメントの実行プランを照会します。
EXPLAIN FORMAT=TREE SELECT /* + PQ_DISTRIBUTE(t1 PQ_NONE) PQ_DISTRIBUTE(t2 PQ_NONE) */ * FROM t1 JOIN t2 ON t1.c1 = t2.c2;次の例は、ハッシュ結合を使用する場合のこれら2つのテーブルの実行計画を示しています。
EXPLAIN FORMAT=TREE EXPLAIN -> Gather (slice: 1; workers: 4) (cost=10.82 rows=4) -> Parallel inner hash join (t2.c2 = t1.c1) (cost=0.57 rows=1) -> Parallel table scan on t2, with parallel partitions: 1 (cost=0.03 rows=1) -> Parallel hash -> Parallel table scan on t1, with parallel partitions: 1 (cost=0.16 rows=1)上記の実行計画では、DOPが4に設定されています。これは、PolarDBが4つのワーカーを使用して並列クエリを実行することを示しています。 まず、4人の作業員がテーブル
t1を並行してスキャンする。 各ワーカーは、テーブルt1のデータの一部のみを使用してハッシュテーブルを作成します。 次に、4つのハッシュテーブルとテーブルt2との間でJOIN演算が実行される。 最後に、リーダーは結合された結果を収集して最終クエリ結果を生成します。
シャッフルハッシュ参加
前提条件
Cluster EditionクラスターのPolarDB for MySQL 8.0が使用され、クラスターのリビジョンバージョンは8.0.2.2.0以降です。 クラスターバージョンを確認する方法の詳細については、「エンジンバージョン5.6、5.7、8.0」をご参照ください。
Parallel executionポリシー 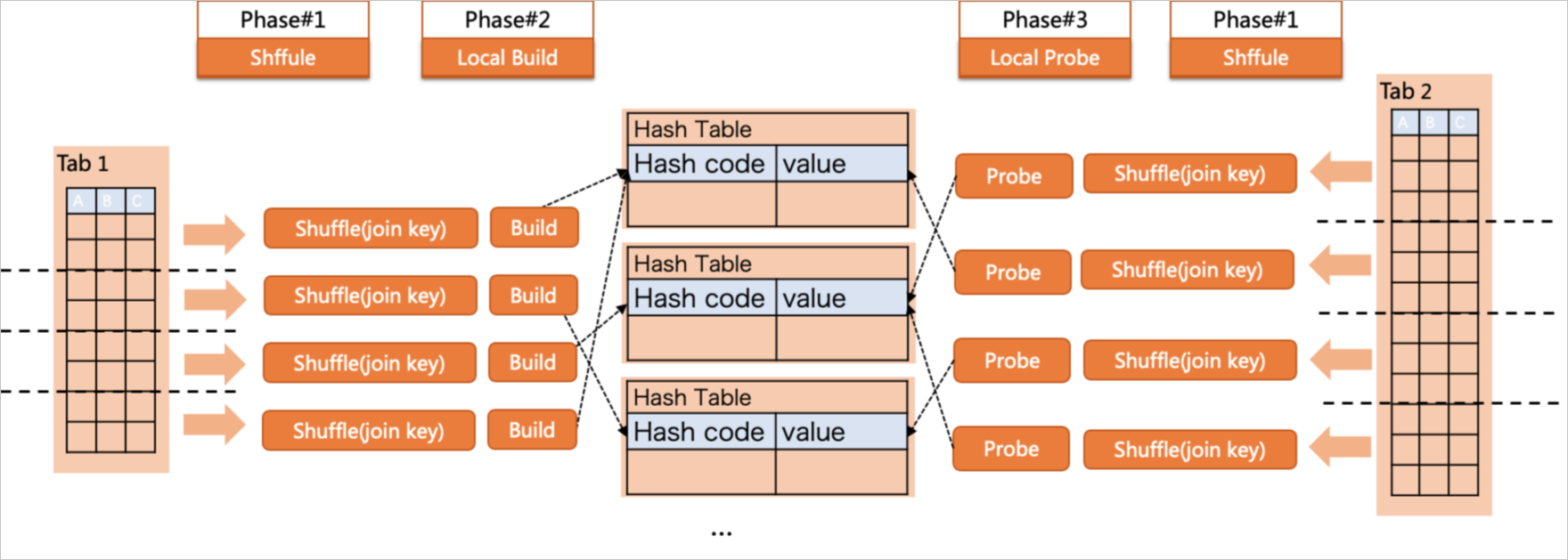
Parallel hash joinは、ビルドフェーズとプローブフェーズの両方で並列実行を実装します。 ただし、共有ハッシュテーブルが大きすぎると、I/O操作が実行されてデータがディスクにダンプされ、並列クエリの効率に影響します。 この問題を解決するために、パーティションハッシュ結合が使用されます。 上記の実行計画では、4つのワーカーがテーブルt1を並行してスキャンし、結合キーに基づいて次のフェーズのワーカーにデータを分割して配布し、各パーティションに小さなハッシュテーブルを作成します。 構築段階が完了した後、4つのワーカーは、テーブルt2をスキャンし、結合キーに基づいてデータを分割し、スモールハッシュテーブルの構築を完了したワーカーにデータを配布する。 プローブ操作が完了した後、リーダーは結合された結果を収集して最終クエリ結果を生成します。
使用法
構文:
PolarDBでは、
EXPLAIN FORMAT=TREEステートメントのみを実行して、ハッシュ結合が使用されているかどうかを確認できます。例:
次の例では、2つのテーブルが作成され、データがテーブルに挿入されます。
CREATE TABLE t1 (c1 INT, c2 INT); CREATE TABLE t2 (c1 INT, c2 INT); INSERT t1(c1, c2) WITH RECURSIVE seq AS ( SELECT 1 AS a, 1 AS b UNION ALL SELECT a + 1, b + 1 FROM seq WHERE a < 1000 ) SELECT a,b FROM seq; INSERT INTO t2 SELECT * FROM t1;次のSELECTステートメントの実行プランを照会します。
EXPLAIN FORMAT=TREE SELECT * FROM t1 JOIN t2 ON t1.c1 = t2.c2;次の例は、ハッシュ結合を使用する場合のこれら2つのテーブルの実行計画を示しています。
EXPLAIN FORMAT=TREE EXPLAIN | -> Gather (slice: 1; workers: 2) (cost=33.38 rows=4) -> Inner hash join (t2.c1 = t1.c1) (cost=23.08 rows=2) -> Repartition (hash keys: t2.c1; slice: 2; workers: 1) (cost=11.35 rows=2) -> Parallel table scan on t2, with parallel partitions: 1 (cost=0.65 rows=4) -> Hash -> Repartition (hash keys: t1.c1; slice: 3; workers: 1) (cost=11.35 rows=2) -> Parallel table scan on t1, with parallel partitions: 1 (cost=0.65 rows=4)