Machine Learning Designer of Platform for AI (PAI) では、DataWorksタスクを使用してパイプラインをオフラインでスケジュールし、モデルを定期的に更新し、モデルトレーニング用のパイプラインを作成できます。 このトピックでは、DataWorksタスクを使用して、機械学習デザイナーパイプラインをオフラインで定期的にスケジュールし、タスクスケジューリング中にPAIモデルをObject Storage Service (OSS) に自動的に同期する方法について説明します。
前提条件
パイプライン内のすべてのノードが正常に実行されます。
DataWorksがアクティブ化され、ワークフローが作成されます。 詳細については、「ワークフローの作成」をご参照ください。
ワークフローが存在するワークスペースは、Machine Learning Designerパイプラインのワークスペースと同じである必要があります。 それ以外の場合、オフラインスケジューリングタスクを作成するときにワークフローにPathパラメーターを設定することはできません。
DataWorksワークフローが存在するワークスペースが標準モードの場合、MaxComputeデータは開発環境と本番環境の間で分離されているため、定期的なタスクがスケジュールされる前に、オフライントレーニングによって生成されたモデルを本番環境に同期します。 詳細については、「バッチ予測パイプラインを定期的にスケジュールする」をご参照ください。
手順
DataWorksのPAI-DesignerパイプラインとDesignerノードの比率は1:Nです。つまり、同じPAI-Designerパイプラインに基づいて、DataWorksに複数のDesignerノードを作成できます。
PAIコンソールにログインし、目的のワークスペースを選択し、視覚化モデリングを入力 (デザイナー)をクリックします。 表示されるページで、目的のパイプラインをダブルクリックします。
(オプション) 定期的なタスクスケジューリング中にMachine Learning DesignerのモデルをOSSに同期する必要がある場合は、Model Exportコンポーネントを追加します。
[パイプライン属性] タブで、[データストレージ] をモデルファイルが保存されているOSSパスに設定します。
PMML形式でモデルファイルをエクスポートする必要がある場合は、[バイナリ分類のロジスティック回帰] コンポーネントなどの目的のモデルコンポーネントをクリックし、コンポーネントの [フィールド設定] タブで [PMMLを生成するかどうか] を選択します。
説明特定のモデルコンポーネントのみが、PMML形式のモデルファイルのエクスポートをサポートします。 この機能をサポートしていないモデルコンポーネントの場合は、この手順をスキップします。
モデルコンポーネントを下流のモデルエクスポートコンポーネントに接続します。 詳細については、「モデルのエクスポート」をご参照ください。
DataWorksタスクを使用して、Machine Learning Designerパイプラインをオフラインでスケジュールします。
キャンバスの左上隅にある [定期スケジューリング] をクリックします。 表示されるダイアログボックスで、[スケジューリングノードの作成] をクリックします。 DataWorksの [ノードの作成] ダイアログボックスで、ノード名を指定し、[確認] をクリックします。
ノードの編集ページで、PAIデザイナー実験を選択ドロップダウンリストからMachine Learning Designerで作成したパイプラインを選択します。
Machine Learning Designerでパイプラインを変更する場合は、[PAI Designerで編集] をクリックします。
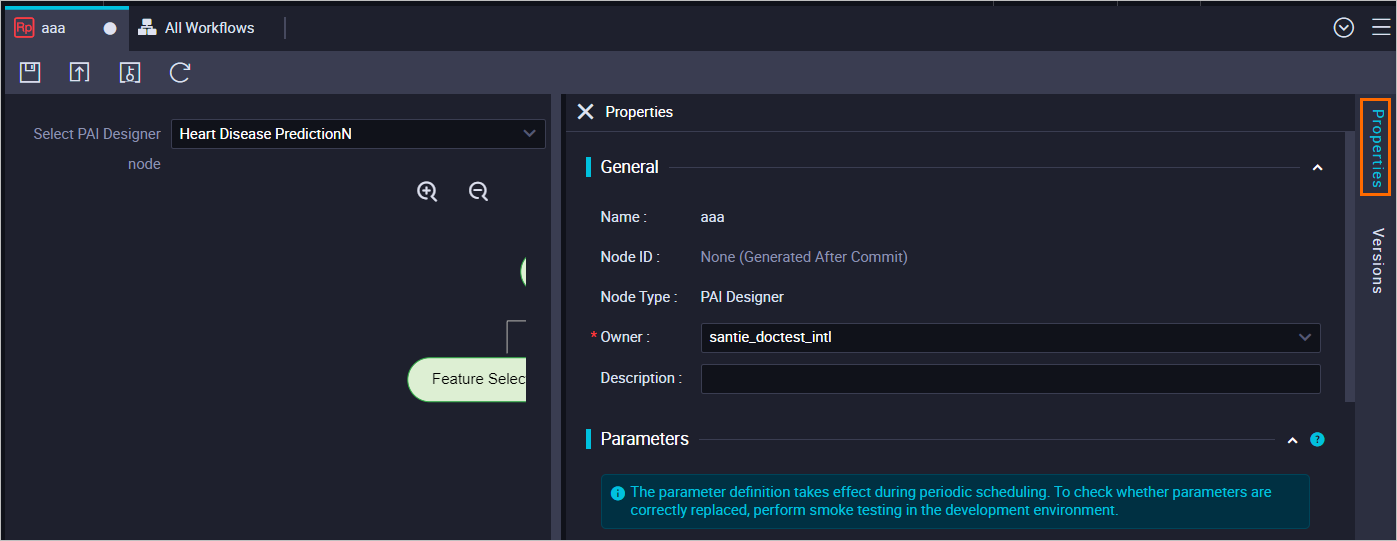
ノードの編集タブで、右側のナビゲーションウィンドウで [プロパティ] タブをクリックします。 [プロパティ] パネルで、ノードのスケジューリングプロパティを設定します。
[プロパティ] パネルには、[全般] 、[スケジューリングパラメーター] 、[スケジュール] 、[リソースグループ] 、[依存関係] の各セクションがあります。 [スケジュール] セクションでスケジューリングサイクルを指定できます。 DataWorksは、指定したスケジューリングサイクルに基づいてパイプラインを自動的に実行します。 詳細については、「スケジューリングプロパティの設定」をご参照ください。
説明DataWorksでのスケジューリング中に、「Start Container timeout」に関連するエラーが報告されることがあります。 これは、タイムアウトの問題が時々発生するためです。 時間プロパティを設定するときは、[失敗時の自動再実行] 機能を有効にすることを推奨します。 この機能を有効にすると、スケジューリングシステムは、指定された再実行回数と再実行間隔に基づいて、失敗したパイプラインを自動的に再実行します (ユーザーが停止したパイプラインは除外します) 。
ツールバーの
 と
と アイコンをクリックして画面の指示に従ってノードを保存およびコミットします。 重要
アイコンをクリックして画面の指示に従ってノードを保存およびコミットします。 重要ノードをコミットする前に、[プロパティ] パネルで [再実行] パラメーターと [親ノード] パラメーターを設定する必要があります。
使用するワークスペースが標準モードの場合、ノードをコミットした後、ページ上部の [デプロイ] をクリックします。 詳細については、「ノードのデプロイ」をご参照ください。
ページの上部にある操作センターをクリックして、機械学習タスクのステータスと操作ログを表示します。
ノードのデータをバックフィルし、パイプラインをテストすることもできます。 詳細については、「自動トリガータスクの表示と管理」をご参照ください。
参考情報
モデルの予測とデプロイの詳細については、「モデルの予測とデプロイ」をご参照ください。
Machine Learning Designerでは、Update EAS Service(Beta) コンポーネントを使用してオンラインモデルサービスを更新できます。 詳細については、「オンラインモデルサービスの定期更新」をご参照ください。