スコアカードは、信用リスク評価の分野で使用される一般的なモデリングツールです。 スコアカードは、変数の離散化を実装するためにビニングを実行し、線形およびロジスティック回帰モデルなどの線形モデルを使用してモデルをトレーニングします。 モデルトレーニングプロセスは、特徴選択およびスコア変換を含む。 スコアカードを使用すると、モデルトレーニング中に変数に制約を追加することもできます。
ビニングなしでスコアカードを使用する場合、スコアカードのトレーニングはロジスティックまたは線形回帰と同等です。
制限事項
Scorecard Trainingコンポーネントを使用して生成された一時モデルは、MaxComputeの一時テーブルにのみデータを格納できます。 Machine Learning Studioの一時テーブルのデフォルトのライフサイクルは369日です。 デフォルトのライフサイクルは、Machine Learning Designerの現在のワークスペースで指定した一時テーブルの保持期間と同じです。 詳細については、「ワークスペースの管理」をご参照ください。 長期的なビジネスで一時モデルを使用する場合は、テーブルの書き込みを使用してデータを保持する必要があります。 詳細については、「FAQ about algorithm components」をご参照ください。
用語
次のセクションでは、スコアカードのトレーニングに関連する用語について説明します。
機能エンジニアリング
スコアカードと通常の線形モデルの主な違いは、スコアカードが線形モデルをトレーニングする前に機能エンジニアリングを実行することです。 スコアカードトレーニングコンポーネントは、機能エンジニアリングのために次の方法をサポートします。
ビニングコンポーネントは、フィーチャ離散化を実装するために使用されます。 そして、ビニング結果に基づいて変数毎にワンホット符号化を行い、N個のダミー変数を生成する。 Nは、ビンの数を表す。
説明元の変数をダミー変数に変換するときに、これらのダミー変数の制約を指定できます。
ビニングコンポーネントは、フィーチャ離散化を実装するために使用されます。 次に、変数の元の値を、その変数が入るビンのWOE値に置き換えるために、証拠の重み (WOE) 変換が実行される。
スコア変換
クレジットスコアリングなどのシナリオでは、線形変換を実行して、予測サンプルのオッズをスコアに変換する必要があります。 次の図は、線形変換に使用される式を示しています。
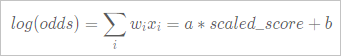 次のパラメーターを使用して、線形変換の関係を指定できます。
次のパラメーターを使用して、線形変換の関係を指定できます。scaledValue: スケーリングされたスコアを指定します。
odds: スケーリングされたスコアのオッズを指定します。
pdo: オッズが2倍になるポイントを指定します。
たとえば、scaledValueパラメーターを800、oddsパラメーターを50、pdoパラメーターを25に設定します。 この場合、線に対して次の2つのドットが決定されます。
log(50)=a × 800 + b log(100)=a × 825 + baとbの値を計算し、線形変換を実行してaとbのスコアを取得します。
スケーリング情報は、
-Dscaleパラメーターを使用してJSON形式で指定します。{"scaledValue":800,"odds":50,"pdo":25}-Dscaleパラメーターを指定する場合は、scaledValue、odds、およびpdoも指定する必要があります。トレーニング中の制約の追加
スコアカードのトレーニング中に、変数に制約を追加できます。 たとえば、特定のビンのスコアを固定値として指定したり、特定の比例関係を満たすように2つのビンのスコアを指定したり、ビンのスコアをWOE値でソートするなど、ビン間のスコアを制限したりできます。 制約の実装は、制約を含む基礎となる最適化アルゴリズムに依存する。 AIコンソールのMachine Learning PlatformのBinningコンポーネントで制約を指定できます。 制約を指定すると、BinningコンポーネントはJSON形式で制約を生成し、接続されたトレーニングコンポーネントに自動的に転送します。 システムは次のJSON制約をサポートしています。
"<": 変数の重みは昇順にソートする必要があります。
">": 変数の重みは降順にソートする必要があります。
"=": 特定の変数の重みは固定値でなければなりません。
「 % 」: 2つの変数の重みは比例関係を満たす必要があります。
「UP」: 変数の重みの上限。 たとえば、値0.5は、トレーニング後の変数の重みが最大で0.5であることを示します。
「LO」: 変数の重みの下限。 たとえば、値0.5は、トレーニング後の変数の重みが少なくとも0.5であることを示します。
各JSON制約は、文字列としてテーブルに格納されます。 テーブルには、1つの行と1つの列のみが含まれます。 例:
{ "name": "feature0", "<": [ [0,1,2,3] ], ">": [ [4,5,6] ], "=": [ "3:0","4:0.25" ], "%": [ ["6:1.0","7:1.0"] ] }組み込みの制約
元の各変数には、組み込みの制約があります。各変数について、母集団の平均スコアは0でなければなりません。 制約のために、スコアカードモデルのインターセプトオプションのscaled_weightパラメーターの値は、すべての変数に関する母集団の平均スコアに等しくなります。
最適化アルゴリズム
[パラメータ設定] タブで、[詳細オプション] を選択します。 次に、スコアカードのトレーニング中に使用される最適化アルゴリズムを設定できます。 システムは、次の最適化アルゴリズムをサポートします。
L-BFGS: このアルゴリズムは、大量の特徴データを処理するために使用される一次最適化アルゴリズムです。 アルゴリズムは制約を含まない。 このアルゴリズムを選択すると、システムは指定した制約を自動的に無視します。
ニュートンの方法: このアルゴリズムは、古典的な2次最適化アルゴリズムです。 収束が速く、正確です。 しかし、このアルゴリズムは、2次のヘッセ行列を計算する必要があるため、大量の特徴データを処理するのには適していない。 アルゴリズムは制約を含まない。 このアルゴリズムを選択すると、システムは指定した制約を自動的に無視します。
バリア法: このアルゴリズムは、二次最適化アルゴリズムである。 アルゴリズムが制約を含まない場合、それはニュートン法アルゴリズムと完全に同等である。 バリア法アルゴリズムは、SQPアルゴリズムとほぼ同じ計算性能と精度を提供します。 ほとんどの場合、SQPを選択することを推奨します。
SQP
このアルゴリズムは、二次最適化アルゴリズムである。 アルゴリズムが制約を含まない場合、それはニュートン法アルゴリズムと完全に同等である。 SQPアルゴリズムは、バリア法アルゴリズムとほぼ同じ計算性能と精度を提供します。 ほとんどの場合、SQPを選択することを推奨します。
説明L-BFGSとニュートン法は、制約のない最適化アルゴリズムです。 バリア法とSQPは、制約付きの最適化アルゴリズムです。
最適化アルゴリズムに慣れていない場合は、[最適化方法] パラメーターを [自動選択] に設定することを推奨します。 この場合、システムは、データ量と制約に基づいて最適なアルゴリズムを選択する。
フィーチャーの選択
スコアカードトレーニングコンポーネントは、段階的な特徴選択をサポートします。 段階的特徴選択は、前方選択と後方選択の組み合わせである。 システムが順方向選択を実行して新しい変数を選択し、それをモデルに追加するたびに、システムは逆方向選択も実行する。 逆方向選択は、重要度が要件を満たさない変数を除去するために使用される。 ステップごとの特徴選択は、さまざまな関数と特徴変換方法をサポートします。 したがって、段階的特徴選択も複数の選択標準をサポートします。 以下の標準がサポートされています。
限界寄与: この標準は、すべての機能と機能エンジニアリング手法に適用できます。
モデルAには変数Xが含まれておらず、モデルBにはモデルAのすべての変数に加えて変数Xが含まれています。最終収束における2つのモデルの関数の違いは、モデルBの他のすべての変数に対する変数Xのわずかな寄与です。変数がダミー変数に変換されるシナリオでは、すなわち、変数Xの限界寄与は、モデルAにおける全てのダミー変数の関数とモデルBにおける全てのダミー変数の関数との間の差である。
限界寄与は柔軟であり、特定のタイプのモデルに限定されない。 関数に寄与する変数のみがモデルに渡されます。 統計的有意性と比較すると、わずかな寄与には欠点があります。 通常、0.05は統計的有意性の閾値として使用される。 限界貢献は、初心者に推奨されるしきい値を提供しません。 しきい値を10E-5に設定することを推奨します。
スコアテスト: この標準は、機能エンジニアリングなしでWOE変換とロジスティック回帰のみをサポートします。
順方向選択中、インターセプトオプションのみを有するモデルが最初にトレーニングされる。 後続の各反復において、モデルに渡されない変数のスコアカイ二乗が測定される。 最大のスコアカイ二乗を有する変数がモデルに渡される。 さらに、カイ二乗分布に基づいて、最大スコアカイ二乗を有する変数のp値が計算される。 変数のp値が所与のSLENTRY値よりも大きい場合、変数はモデルに渡されず、特徴選択は終了する。
前方選択が完了した後、モデルに渡される変数に対して後方選択が実行されます。 変数のWaldカイ二乗および関連するp値が計算される。 p値が指定されたSLSTAY値より大きい場合、変数はモデルから削除されます。 次に、システムは新しい反復を開始する。
Fテスト: この標準は、機能エンジニアリングなしでWOE変換と線形回帰のみをサポートします。
順方向選択中、インターセプトオプションのみを有する変数が最初にトレーニングされる。 後続の各反復において、モデルに渡されない変数のF値が計算される。 F値の計算は、限界寄与の計算と同様である。 変数のF値を計算するには、2つのモデルをトレーニングする必要があります。 F値はF分布に従う。 関連するp値は、F分布の確率密度関数に基づいて計算することができる。 p値が所与のSLENTRY値よりも大きい場合、変数はモデルに渡されず、順方向選択は終了する。
逆方向選択の間、F値は、スコア検定と同様の方法で変数の有意性を計算するために使用される。
モデルに渡す変数の強制的な選択
フィーチャの選択を実行する前に、モデルに強制的に渡す変数を指定できます。 指定された変数に対して前方または後方の選択は実行されません。 これらの変数は、その重要性にかかわらず、モデルに直接渡されます。 -Dselectedパラメーターを使用して、反復回数と有意性のしきい値を指定できます。 このパラメーターはJSON形式で指定します。 例:
{"max_step":2, "slentry": 0.0001, "slstay": 0.0001}-Dselectedパラメーターが空の場合、またはmax_stepパラメーターが0に設定されている場合、機能の選択は実行されません。
パラメータ設定
Machine Learning Designerを使用すると、視覚化された方法でスコアカードトレーニングコンポーネントを設定できます またはMachine Learning Platform for AIコマンドを実行します。 次のコードは、サンプルコマンドを提供します。
pai -name=linear_model -project=algo_public
-DinputTableName=input_data_table
-DinputBinTableName=input_bin_table
-DinputConstraintTableName=input_constraint_table
-DoutputTableName=output_model_table
-DlabelColName=label
-DfeatureColNames=feaname1,feaname2
-Doptimization=barrier_method
-Dloss=logistic_regression
-Dlifecycle=8パラメーター | 説明 | 必須 | デフォルト |
inputTableName | 入力フィーチャテーブルの名前。 | 可 | N/A |
inputTablePartitions | 入力フィーチャテーブルから選択されたパーティション。 | 不可 | フルテーブル |
inputBinTableName | ビニング結果テーブルの名前。 このパラメーターを指定すると、システムはビニング結果テーブルのビニング規則に基づいてフィーチャの離散化を自動的に実行します。 | 不可 | N/A |
featureColNames | 入力テーブルから選択されたフィーチャ列。 | 不可 | ラベル列を除くすべての列 |
labelColName | ラベル列の名前。 | 可 | N/A |
outputTableName | 出力モデルテーブルの名前。 | 可 | N/A |
inputConstraintTableName | 制約を格納するテーブルの名前。 制約は、テーブルのセルに格納されるJSON文字列です。 | 不可 | N/A |
最適化 | 最適化アルゴリズム。 有効な値:
sqpとbarrier_methodのみが制約をサポートしています。 最適化パラメーターをautoに設定すると、ユーザーデータと関連パラメーター設定に基づいて適切な最適化アルゴリズムが自動的に選択されます。 最適化アルゴリズムに慣れていない場合は、最適化パラメーターをautoに設定することを推奨します。 | 不可 | auto |
損失 | 損失タイプ。 有効な値: logistic_regressionおよびleast_square。 | 不可 | logistic_regression |
反復 | 最適化の最大反復回数。 | 不可 | 100 |
l1Weight | L1正則化のパラメーターの重み。 このパラメーターは、最適化パラメーターがlbfgsに設定されている場合にのみ有効です。 | 不可 | 0 |
l2Weight | L2正則化のパラメータの重み。 | 不可 | 0 |
m | L-BFGSアルゴリズムを使用して実行される最適化の履歴ステップサイズ。 このパラメーターは、最適化パラメーターがlbfgsに設定されている場合にのみ有効です。 | 不可 | 10 |
scale | スコアカードの重みスケーリング情報。 | 不可 | Empty |
選択済み | スコアカードトレーニング中にフィーチャ選択を有効にするかどうかを指定します。 | 不可 | Empty |
convergenceTolerance | コンバージェンス公差。 | 不可 | 1e-6 |
positiveLabel | サンプルが陽性サンプルかどうかを指定します。 | いいえ | 1 |
ライフサイクルの設定 (Set lifecycle) | 出力テーブルのライフサイクル。 | 不可 | N/A |
coreNum | コアの数。 | 不可 | システムによって決定される |
memSizePerCore | 各コアのメモリサイズ。 単位:MB。 | 不可 | システムによって決定される |
Output
スコアカードトレーニングコンポーネントは、モデルレポートへのデータを生成します。 モデルレポートは、ビニング情報、ビニング制約、WOE値、および限界寄与情報などの基本的なモデル評価統計を含む。 次の表に、モデルレポートの列を示します。
列 | データ型 | 説明 |
feaname | STRING | フィーチャーの名前。 |
binid | BIGINT | ビンのID。 |
bin | STRING | ビンの間隔を示すビンの説明。 |
制約 | STRING | トレーニング中にビンに追加される制約。 |
重み | DOUBLE | ビニング変数の重み。 ビニングのない非スコアカードモデルの場合、このフィールドはモデル変数の重みを示します。 |
scaled_weight | DOUBLE | スコアカードトレーニングのビニング変数の重みから線形変換されたスコア。 |
悲惨 | DOUBLE | メトリック。 これは、トレーニングセット内のビンのWOE値を示します。 |
貢献 | DOUBLE | メトリック。 これは、トレーニングセット内のビンの限界寄与値を示します。 |
合計 | BIGINT | メトリック。 これは、トレーニングセット内のビン内のサンプルの総数を示します。 |
ポジティブ | BIGINT | メトリック。 これは、トレーニングセット内のビン内の陽性サンプルの数を示す。 |
ネガティブ | BIGINT | メトリック。 これは、トレーニングセット内のビン内の陰性サンプルの数を示す。 |
percentage_pos | DOUBLE | メトリック。 これは、訓練セット中の全陽性サンプルに対するビン中の陽性サンプルの割合を示す。 |
percentage_neg | DOUBLE | メトリック。 これは、訓練セット中の陰性サンプルの合計に対するビン中の陰性サンプルの割合を示す。 |
test_woe | DOUBLE | メトリック。 これは、テストセット内のビンのWOE値を示します。 |
test_contribution | DOUBLE | メトリック。 これは、テストセット内のビンの限界寄与値を示します。 |
test_total | BIGINT | メトリック。 これは、テストセット内のビン内のサンプルの総数を示します。 |
test_positive | BIGINT | メトリック。 これは、試験セット中のビン中の陽性サンプルの数を示す。 |
test_negative | BIGINT | メトリック。 これは、試験セット内のビン内の陰性サンプルの数を示す。 |
test_percentage_pos | DOUBLE | メトリック。 これは、試験セット中の全陽性サンプルに対するビン中の陽性サンプルの割合を示す。 |
test_percentage_neg | DOUBLE | メトリック。 これは、試験セット中の陰性サンプル全体に対するビン中の陰性サンプルの割合を示す。 |