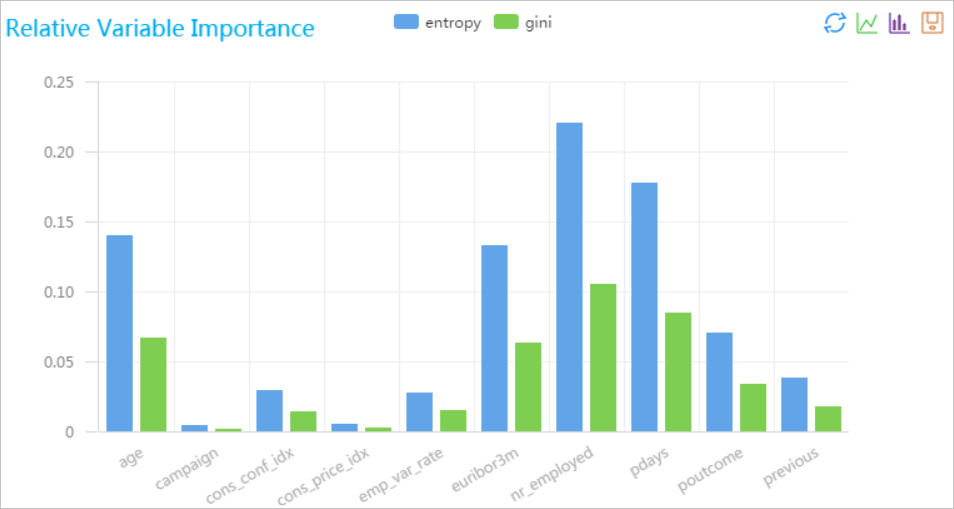
ランダムフォレストにおける特徴重要性評価は、ランダムフォレストモデルにおける予測結果に対する各特徴の寄与を分析するために使用される方法である。 この方法は、各特徴がすべての決定木にわたって平均不純物をどれだけ減少させるか、またはどれだけ置換がモデルの精度を減少させるかを計算することによって、モデルの重要性を決定する。 このように、本方法は、モデル性能に最も重要な特徴を識別するのに役立つことができる。
コンポーネントの設定
方法1: パイプラインページでコンポーネントを設定する
Machine Learning Designerのパイプラインの詳細ページで、ランダムフォレストフィーチャの重要性評価コンポーネントをパイプラインに追加し、次の表に示すパラメーターを設定します。
タブ | パラメーター | 説明 |
フィールド設定 | フィーチャー列 | 必要に応じて、 トレーニング用に入力テーブルから選択されたフィーチャ列。 デフォルトでは、ラベル列以外のすべての列が選択されます。 |
ターゲット列 | 必須。 ラベル列。
| |
パラメーター設定 | 並列計算コア | 必要に応じて、 並列コンピューティングで使用されるコアの数。 |
コアあたりのメモリサイズ | 必要に応じて、 各コアのメモリサイズ。 単位:MB。 |
方法2: PAIコマンドを使用する
PAIコマンドを使用してコンポーネントパラメータを設定します。 SQLスクリプトコンポーネントを使用してPAIコマンドを呼び出すことができます。 詳細については、「シナリオ4: SQLスクリプトコンポーネント内でPAIコマンドを実行する」をご参照ください。
pai -name feature_importance -project algo_public
-DinputTableName=pai_dense_10_10
-DmodelName=xlab_m_random_forests_1_20318_v0
-DoutputTableName=erkang_test_dev.pai_temp_2252_20319_1
-DlabelColName=y
-DfeatureColNames="pdays,previous,emp_var_rate,cons_price_idx,cons_conf_idx,euribor3m,nr_employed,age,campaign,poutcome"
-Dlifecycle=28 ;パラメーター | 必須 / 任意 | デフォルト値 | 説明 |
inputTableName | 対象 | デフォルト値なし | 入力テーブルの名前。 |
outputTableName | 対象 | デフォルト値なし | 出力テーブルの名前。 |
labelColName | 対象 | デフォルト値なし | 入力テーブルのラベル列の名前。 |
modelName | 対象 | デフォルト値なし | 入力モデルの名前。 |
featureColNames | 非対象 | ラベル列以外のすべての列 | トレーニング用に入力テーブルから選択されたフィーチャ列。 |
inputTablePartitions | 非対象 | すべてのパーティション | トレーニング用に入力テーブルから選択されたパーティション。 |
ライフサイクル | 非対象 | 指定なし | 出力テーブルのライフサイクル。 |
coreNum | 非対象 | システムによって決定される | コアの数。 |
memSizePerCore | 非対象 | システムによって決定される | 各コアのメモリサイズ。 単位:MB。 |
例:
次のSQL文を実行してトレーニングデータを生成します。
この例では、bank_dataテーブルの上位10個のデータレコードを選択して、pai_dense_10_10という名前のテーブルを作成します。 ビジネス要件に基づいてテーブルを作成できます。
drop table if exists pai_dense_10_10; create table pai_dense_10_10 as select age,campaign,pdays, previous, poutcome, emp_var_rate, cons_price_idx, cons_conf_idx, euribor3m, nr_employed, y from bank_data limit 10;次の図に示す実験を作成します。 詳細については、「カスタムパイプライン」をご参照ください。
データソースはpai_dense_10_10です。 yはランダムフォレストモデルのラベル列で、その他の列はフィーチャ列です。 [変換強制列] パラメーターの [年齢] と [キャンペーン] を選択します。 これは、2つの列が列挙された機能として処理され、他の列のデフォルト設定が保持されることを示します。
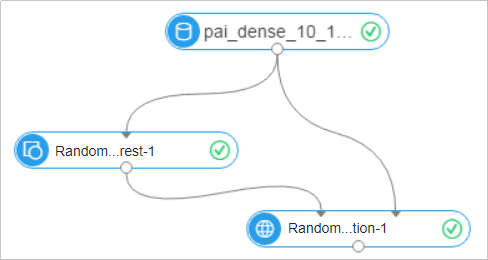
実験を実行し、予測結果を表示します。
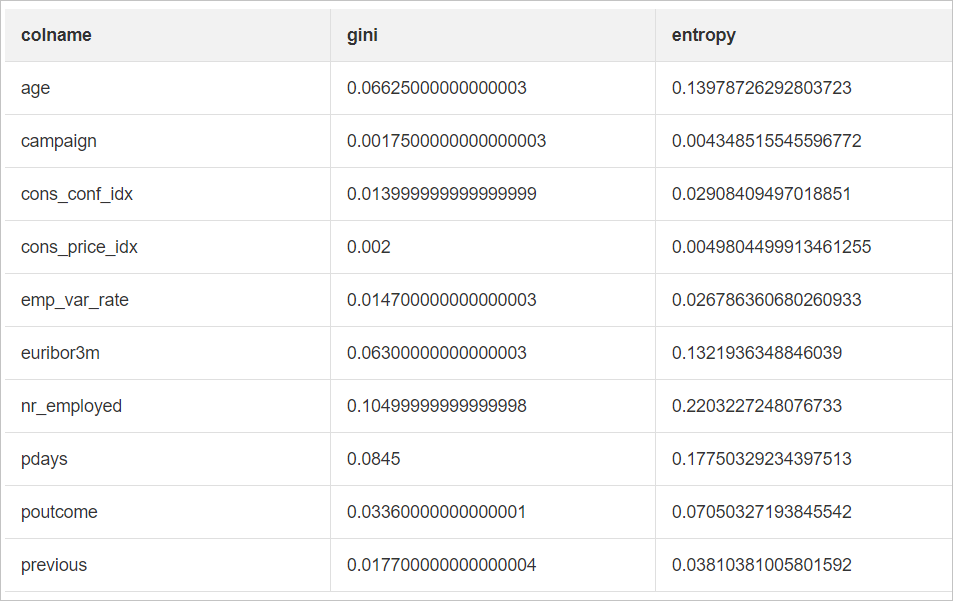
実験の実行後、[ランダムフォレストフィーチャの重要性評価] コンポーネントを右クリックし、[分析レポートの表示] を選択して結果を表示します。