PyAlinkスクリプトコンポーネントを使用すると、コードを記述してAlinkのすべてのアルゴリズムを呼び出すことができます。 たとえば、PyAlinkスクリプトコンポーネントを使用して、関連する目的でAlinkの分類、回帰、または推奨アルゴリズムを呼び出すことができます。 PyAlinkスクリプトコンポーネントをMachine Learning Designerの他のアルゴリズムコンポーネントと一緒に使用して、パイプラインを作成し、その効果を検証することもできます。 このトピックでは、PyAlinkスクリプトコンポーネントの使用方法について説明します。
背景情報
PyAlinkスクリプトコンポーネントを単独で使用することも、PyAlinkスクリプトコンポーネントを他のアルゴリズムコンポーネントと一緒に使用することもできます。 PyAlink Scriptは何百ものAlinkコンポーネントをサポートしており、コードを記述することでさまざまな種類のデータを読み書きできます。 詳細については、「方法1: PyAlinkスクリプトコンポーネントを単独で使用する」、「方法2: PyAlinkスクリプトコンポーネントをMachine Learning Designerの他のアルゴリズムコンポーネントと共に使用する」、および「PyAlinkスクリプトコンポーネントがさまざまな種類のデータを読み書きする方法」をご参照ください。 PyAlinkスクリプトコンポーネントによって生成されたPipelineModelをElastic Algorithm service (EAS) のサービスとしてデプロイできます。 詳細については、「例: PyAlinkスクリプトコンポーネントによって生成されたモデルをEASのサービスとしてデプロイする」をご参照ください。
基本概念
PyAlinkスクリプトコンポーネントを使用する前に、次の表で説明する概念をよく理解してください。
期間 | 説明 |
演算子 | Alinkでは、演算子はアルゴリズムコンポーネントです。 演算子は、バッチ演算子またはストリーム演算子です。 たとえば、次のロジスティック回帰関連演算子は、バッチまたはストリームタイプのものです。
LinkまたはLinkFrom構文を使用して、演算子を接続できます。 例: 各演算子にはパラメータのセットが付属しています。 たとえば、ロジスティック回帰演算子には次のパラメーターが付属します。
パラメータを設定するには、パラメータ名と一緒にセットを使用します。 例: ソースおよびシンク関連の演算子は、最初に定義する必要がある特別な演算子です。 次に、LinkまたはLinkForm構文を使用して、それらを他のアルゴリズムコンポーネントと接続できます。 次の図は、これらの演算子の使用方法を示しています。  Alinkコンポーネントは、一般的に使用されるストリームおよびバッチデータソースを提供します。 例: |
パイプライン | パイプラインは、Alinkアルゴリズムを使用する別の方法です。 データ処理、フィーチャ生成、およびモデルトレーニングを単一のパイプラインに統合して、オンライントレーニングおよび予測サービスを提供できます。 次のコードは、パイプラインの使用例を示しています。 |
ベクトル | VECTORはAlinkのカスタムデータ型です。 次のVECTORタイプを使用できます。
説明 Alinkでは、列がVECTOR型の場合、vectorColNameパラメーターを使用して列名を指定します。 |
PyAlinkスクリプトでサポートされているAlinkコンポーネント
PyAlink Scriptは、データ処理、機能エンジニアリング、モデルトレーニングなどの分野をカバーする何百ものAlinkコンポーネントを提供します。
PyAlink Scriptはパイプラインおよびバッチコンポーネントをサポートしますが、ストリームコンポーネントはサポートしません。
方法1: PyAlinkスクリプトコンポーネントを単独で使用する
このセクションでは、Alibaba Cloudリソースに基づいて、Machine Learning DesignerでPyAlinkスクリプトコンポーネントを使用する方法について説明します。 この例では、アイテムベースの協調フィルタリング (ItemCF) モデルを使用してMovieLensデータセットをスコアリングします。 以下の手順を実行します。
[Visualized Modeling (Designer)] ページに移動し、空のパイプラインを作成します。 詳細については、「手順」をご参照ください。
[パイプライン] タブで、作成したパイプラインを見つけてクリックします。 次に、[開く] をクリックします。
左側のコンポーネントリストの上にある検索ボックスで、PyAlink Scriptを検索します。 次に、PyAlink Scriptを右側のキャンバスにドラッグします。 PyAlink Script-1という名前のパイプラインノードがキャンバスに自動的に生成されます。
キャンバスで、PyAlink Script-1ノードをクリックします。 右側のウィンドウで、[パラメーター設定] タブと [チューニング] タブでパラメーターを設定します。
[パラメーター設定] タブに次のコードを記述します。
from pyalink.alink import * def main(sources, sinks, parameter): PATH = "http://alink-test.oss-cn-beijing.aliyuncs.com/yuhe/movielens/" RATING_FILE = "ratings.csv" PREDICT_FILE = "predict.csv" RATING_SCHEMA_STRING = "user_id long, item_id long, rating int, ts long" ratingsData = CsvSourceBatchOp() \ .setFilePath(PATH + RATING_FILE) \ .setFieldDelimiter("\t") \ .setSchemaStr(RATING_SCHEMA_STRING) predictData = CsvSourceBatchOp() \ .setFilePath(PATH + PREDICT_FILE) \ .setFieldDelimiter("\t") \ .setSchemaStr(RATING_SCHEMA_STRING) itemCFModel = ItemCfTrainBatchOp() \ .setUserCol("user_id").setItemCol("item_id") \ .setRateCol("rating").linkFrom(ratingsData); itemCF = ItemCfRateRecommender() \ .setModelData(itemCFModel) \ .setItemCol("item_id") \ .setUserCol("user_id") \ .setReservedCols(["user_id", "item_id"]) \ .setRecommCol("prediction_score") result = itemCF.transform(predictData) result.link(sinks[0]) BatchOperator.execute()PyAlink Scriptコンポーネントは、最大4つの出力ポートをサポートします。 このスクリプトでは、出力データをPyAlink scriptコンポーネントの最初の出力ポートに書き込むために、
result.link (シンク [0])が使用されます。 下流ノードは、出力データを読み取るために第1の出力ポートに接続することができる。 PyAlink Scriptコンポーネントがさまざまな種類のデータを読み書きする方法の詳細については、「PyAlink Scriptコンポーネントがさまざまな種類のデータを読み書きする方法」をご参照ください。[チューニング] タブで、実行中のモデルとノードの仕様に関連するパラメーターを設定します。 下表に、各パラメーターを説明します。
パラメーター
説明
[実行モードの選択]
有効な値:
DLC (マルチスレッド): デバッグフェーズで少量のデータを含むタスクを実行する場合は、この値を選択することを推奨します。
MaxCompute (分散): 大量のデータを含むタスクを実行する場合、または本番タスクを実行する場合は、この値を選択することを推奨します。
Flink (分散): この値は、現在のワークスペースに関連付けられているFlinkクラスターのリソースが分散モードで実行されることを示します。
労働者の数
このパラメーターは、[実行モードの選択] を [MaxCompute (分散)] または [Flink (分散)] に設定した場合にのみ使用できます。 このパラメータは、ワーカーの数を指定します。 デフォルトでは、このパラメータは空のままです。 この場合、システムはタスクデータに基づいてこのパラメーターの値を自動的に指定します。
各ワーカーのメモリ (MB単位)
このパラメーターは、[実行モードの選択] を [MaxCompute (分散)] または [Flink (分散)] に設定した場合にのみ使用できます。 各ワーカーのメモリサイズを指定します。 単位:MB。 値は正の整数でなければなりません。 デフォルト値は 8192 です。
各ワーカーのcpuコア
このパラメーターは、[実行モードの選択] を [MaxCompute (分散)] または [Flink (分散)] に設定した場合にのみ使用できます。 このパラメーターは、各ワーカーのCPUコアの数を指定します。 値は正の整数でなければなりません。 デフォルトでは、このパラメータは空のままです。
スクリプトを実行するノード仕様の選択
このパラメータは、ディープラーニングコンテナ (DLC) ノードの仕様を指定します。 デフォルト値: 2vCPU + 8GB Mem-ecs.g6.large。
キャンバスの上の [保存] をクリックし、
 ボタンをクリックしてPyAlinkスクリプトを実行します。
ボタンをクリックしてPyAlinkスクリプトを実行します。 タスクの実行が完了したら、右クリックします。PyAlinkスクリプト-1キャンバス上で選択します結果を表示します。
列名
説明
ユーザー_id
ユーザーの ID。
iteme_id
ムービーのID。
prediction_score
ユーザーが映画をどれだけ好きかを示します。 この値は、映画のレコメンデーションの参照として使用されます。
方法2: PyAlinkスクリプトコンポーネントをMachine Learning Designerの他のアルゴリズムコンポーネントと一緒に使用する
PyAlinkスクリプトコンポーネントの入出力ポートは、Machine Learning Designerの他のアルゴリズムコンポーネントの入出力ポートと同じです。 PyAlinkスクリプトコンポーネントを他のアルゴリズムコンポーネントに接続して、それらを一緒に使用できます。 次の図は、PyAlinkスクリプトコンポーネントをMachine Learning Designerの他のアルゴリズムコンポーネントと一緒に使用する方法の例を示しています。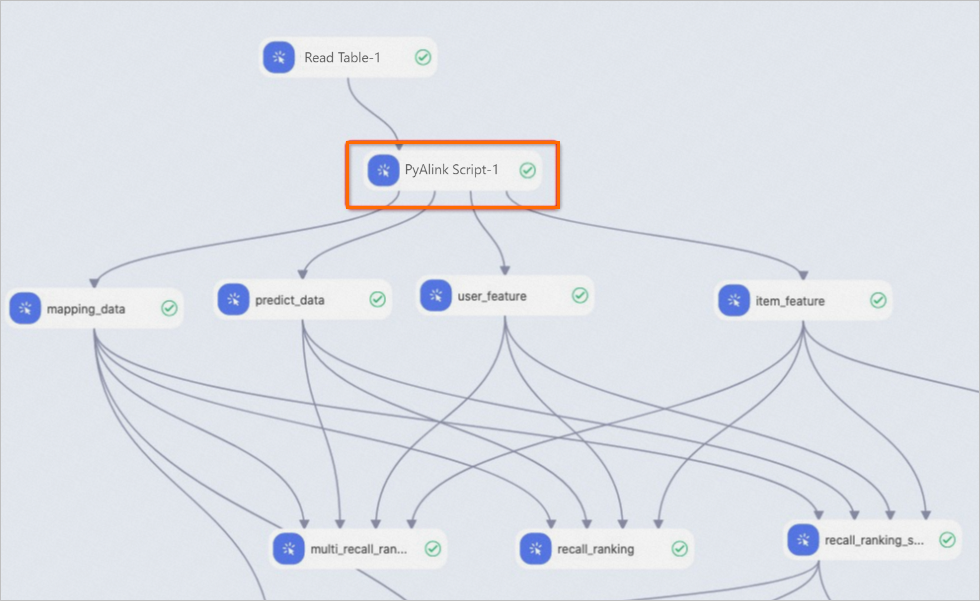
PyAlink Scriptコンポーネントが異なるタイプのデータを読み書きするメソッド
データの読み取り
MaxComputeテーブルからのデータの読み取り: PyAlink Scriptコンポーネントは、入力ポートを使用して上流ノードからデータを読み取ります。 次のサンプルコードに例を示します。
train_data = sources[0] test_data = sources[1]コードでは、sources[0] は最初の入力ポートに対応するMaxComputeテーブルを示し、sources[1] は2番目の入力ポートに対応するMaxComputeテーブルを示します。 PyAlink Scriptコンポーネントは、最大4つの入力ポートをサポートします。
ネットワークファイルシステムからデータを読み取る: PyAlink Scriptコンポーネントは、コード内のAlinkのソースコンポーネントCsvSourceBatchOpおよびAkSourceBatchOPを使用してデータを読み取ります。 PyAlinkスクリプトコンポーネントは、次の種類のファイルからデータを読み取ることができます。
HTTP形式のネットワーク共有ファイル。 次のサンプルコードに例を示します。
ratingsData = CsvSourceBatchOp() \ .setFilePath(PATH + RATING_FILE) \ .setFieldDelimiter("\t") \ .setSchemaStr(RATING_SCHEMA_STRING)Object Storage Service (OSS) に保存されているファイル。 次の図に示す手順に基づいて、データを読み取るOSSパスを指定します。
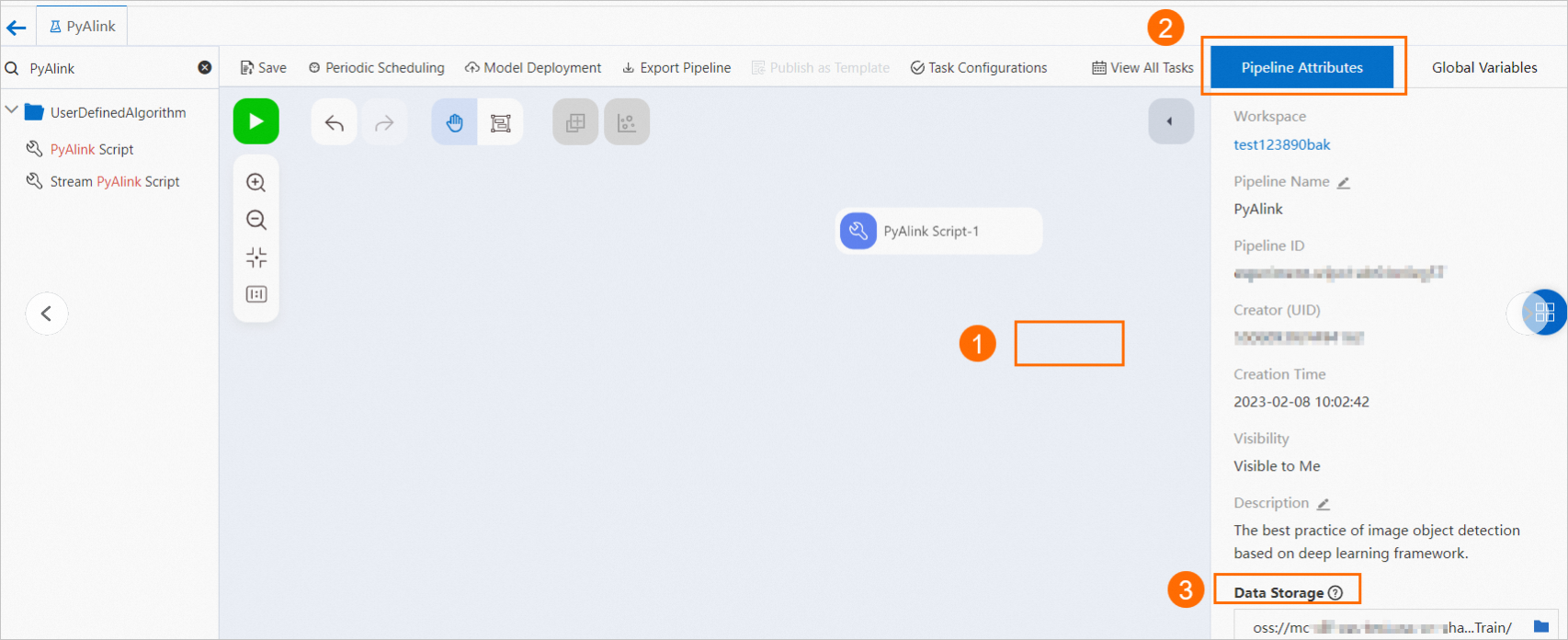 次のサンプルコードは、例を示します。
次のサンプルコードは、例を示します。 model_data = AkSourceBatchOp().setFilePath("oss:// xxxxxxxx/model_20220323.ak")
データを書き込み
MaxComputeテーブルへのデータの書き込み: PyAlink Scriptコンポーネントは、出力ポートを使用してダウンストリームノードにデータを書き込みます。 次のサンプルコードに例を示します。
result0.link(sinks[0]) result1.link(sinks[1]) BatchOperator.execute()このコードでは、result0.link (シンク [0]) は、最初の出力ポートに対応する結果テーブルにデータが書き込まれることを示します。 書き込まれたデータは、第1の出力ポートを使用してアクセスできる。 PyAlink Scriptコンポーネントは、最大4つの結果テーブルにデータを書き込むことができます。
OSSオブジェクトにデータを書き込む: 次の図に示す手順に基づいて、データを書き込むOSSパスを指定します。
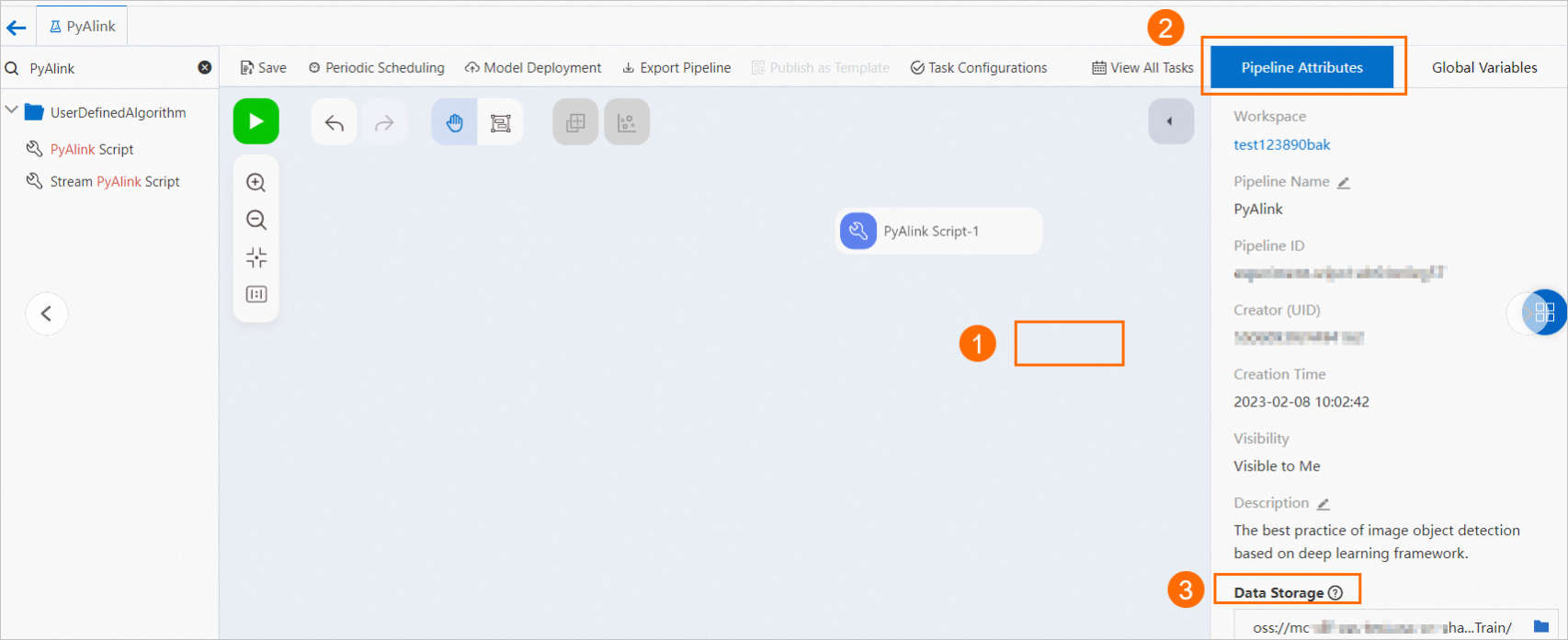 次のサンプルコードは、例を示します。
次のサンプルコードは、例を示します。 result.link(AkSinkBatchOp() \ .setFilePath("oss://xxxxxxxx/model_20220323.ak") \ .setOverwriteSink(True)) BatchOperator.execute()
例: PyAlinkスクリプトコンポーネントによって生成されたモデルをEASのサービスとしてデプロイする
デプロイするモデルを生成します。
PyAlinkスクリプトコンポーネントによって生成されたPipelineModelのみが、EASのサービスとしてデプロイできます。 次のサンプルコードを実行して、PipelineModelファイルを生成します。 詳細については、「方法1: PyAlinkスクリプトコンポーネントのみを使用する」をご参照ください。
from pyalink.alink import * def main(sources, sinks, parameter): PATH = "http://alink-test.oss-cn-beijing.aliyuncs.com/yuhe/movielens/" RATING_FILE = "ratings.csv" PREDICT_FILE = "predict.csv" RATING_SCHEMA_STRING = "user_id long, item_id long, rating int, ts long" ratingsData = CsvSourceBatchOp() \ .setFilePath(PATH + RATING_FILE) \ .setFieldDelimiter("\t") \ .setSchemaStr(RATING_SCHEMA_STRING) predictData = CsvSourceBatchOp() \ .setFilePath(PATH + PREDICT_FILE) \ .setFieldDelimiter("\t") \ .setSchemaStr(RATING_SCHEMA_STRING) itemCFModel = ItemCfTrainBatchOp() \ .setUserCol("user_id").setItemCol("item_id") \ .setRateCol("rating").linkFrom(ratingsData); itemCF = ItemCfRateRecommender() \ .setModelData(itemCFModel) \ .setItemCol("item_id") \ .setUserCol("user_id") \ .setReservedCols(["user_id", "item_id"]) \ .setRecommCol("prediction_score") model = PipelineModel(itemCF) model.save().link(AkSinkBatchOp() \ .setFilePath("oss://<your_bucket_name>/model.ak") \ .setOverwriteSink(True)) BatchOperator.execute()コード内の
<your_bucket_name>をOSSバケットの名前に置き換えます。重要pathパラメーターで指定されたデータセットパスからデータを読み取ることができます。 それ以外の場合、このコンポーネントは実行できません。
EAS構成ファイルを生成します。
次のコードを実行して、出力データをconfig.jsonファイルに書き込みます。
# Generate an EAS configuration file. import json # Generate EAS model configurations. model_config = {} # Specify the schema of the input data in EAS. model_config['inputDataSchema'] = "id long, movieid long" model_config['modelVersion'] = "v0.2" eas_config = { "name": "recomm_demo", "model_path": "http://xxxxxxxx/model.ak", "processor": "alink_outer_processor", "metadata": { "instance": 1, "memory": 2048, "region":"cn-beijing" }, "model_config": model_config } print(json.dumps(eas_config, indent=4))config.jsonファイルの重要なパラメーター:
name: デプロイするモデルの名前。
model_path: PipelineModelファイルが保存されているOSSパス。 コード内のmodel_pathパラメーターの値を実際のOSSパスに置き換えます。
config.jsonファイルのその他のパラメーターの詳細については、「EASCMDクライアントを使用するコマンドの実行」をご参照ください。
EASのサービスとしてモデルを展開します。
EASCMDクライアントにログインして使用し、モデルをデプロイできます。 EASCMDクライアントにログオンする方法の詳細については、「EASCMDクライアントのダウンロードとユーザー認証の完了」をご参照ください。 たとえば、64ビットWindowsでEASCMDクライアントを使用する場合は、次のコマンドを実行して、EASでモデルをサービスとして展開します。
eascmdwin64.exe create config.json