Feature Database(FeatureDB)は、Platform for AI(PAI)の FeatureStore が提供するデータベースサービスです。 FeatureStore のオンラインデータストアとして機能し、検索、レコメンデーション、広告シナリオ向けにオンライン特徴量ストレージと高パフォーマンスの読み取り/書き込み最適化を提供します。 このトピックでは、FeatureDB の概要、その特徴と利点について説明します。
FeatureDB とは
FeatureDB は、FeatureStore が提供する高パフォーマンスの分散データベースです。 KV および KKV 形式のデータをサポートし、配列を Array タイプ、KV を Map タイプとして保存します。 保存された Array タイプと Map タイプの構造化データは、後続の読み取り、書き込み、および推論サービスのパフォーマンスを向上させます。 FeatureDB は、オフライン特徴量とリアルタイム特徴量、およびユーザー行動シーケンス特徴量の生成、更新、および消費リンクを完全にサポートします。
アクティブ化方法
FeatureDB データストアを作成する際に、インターフェースの指示に従ってサービスをアクティブ化できます。
特徴
FeatureDB は、FeatureStore の特徴量読み取りのために、以下の機能と最適化を実装しています。
KV および KKV タイプの特徴量の読み取りと書き込み。
MaxCompute 複合型の特徴量(Array、Map)の読み取りと書き込み。
FeatureView 配下のすべての特徴量データのプル。
リアルタイム特徴量データを更新するためのミリ秒レベルのポーリング。
秒単位の TTL、期限切れデータの自動クリーンアップ。
実際の読み取りと書き込みに基づく従量課金制。
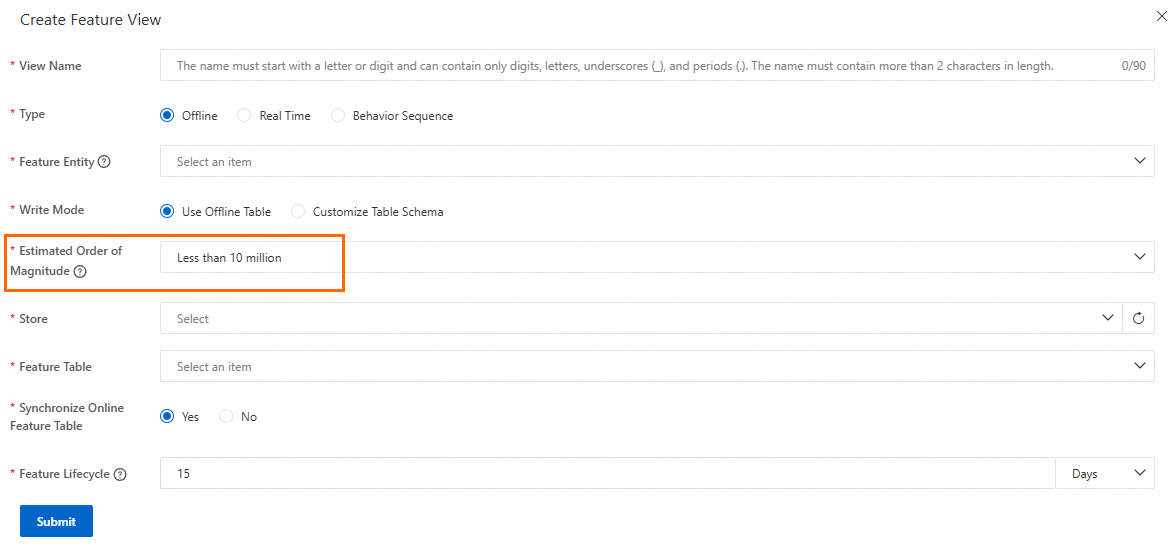
FeatureDB は、FeatureView のデータをシャーディングし、シャーディング数を調整して、さまざまなシナリオでの読み取りおよび書き込みパフォーマンス要件を満たすことができます。 また、レプリカをサポートして、データの安定性とセキュリティを確保します。 シャードの数は、指定された [推定規模] に基づきます。
[1,000 万未満](デフォルト): 5 シャード。
[1,000 万~1 億]: 10 シャード。
[1 億超]: 20 シャード。
利点
費用対効果が高い
特徴量ストレージ要件が少ないお客様の場合、FeatureDB を使用することでコストを削減できます。
高頻度の更新要件に対応
リアルタイムの統計特徴量を使用する場合、リアルタイム特徴量は数秒ごとに複数の EasyRec Processor(モデル推論サービス)インスタンスのストレージに更新する必要があります。 FeatureDB は、高頻度の更新に対するこれらの高い要件を満たすことができます。
複合型の特徴量をサポート
検索およびプロモーションビジネスでは、Array タイプと Map タイプの特徴量、ユーザー行動の長いシーケンス特徴量、およびそれらの SideInfo が広く使用されています。 複合型の特徴量が文字列として保存されている場合、使用時に Map タイプにシリアル化する必要があり、パフォーマンスが低下します。
FeatureDB は、複合型のデータの保存と、MaxCompute 2.0 複合型のデータを FeatureDB に同期して高パフォーマンスの読み取り操作を行うことをサポートしています。
柔軟なスケーリングをサポート
大規模なお客様の場合、特徴量ビューに応じてシャード数を柔軟に増やすことで、読み取りおよび書き込みパフォーマンスを向上させることができます。
監視の盲点を解消
サードパーティのデータソースを統合する場合、データリンク全体の監視が難しくなります。特にリアルタイム特徴量の場合は困難です。 FeatureDB は、ビューの粒度レベルで、読み取りおよび書き込み QPS、RT、データ更新レイテンシ、ストレージ使用量などの主要なパフォーマンス指標を監視できます。
機能
VPC 直接接続
FeatureDB は、PrivateLink に基づく VPC 直接接続を提供します。 構成が完了すると、VPC 内の FeatureStore SDK を使用して、PrivateLink に基づくプライベート接続を介して FeatureDB にアクセスできるようになり、データの読み取りと書き込みのパフォーマンスが向上し、アクセスレイテンシが短縮されます。
次のいずれかの方法で VPC 直接接続を構成できます。
方法 1: FeatureDB データストアがない場合は、[ストア] タブの [ソースの作成] をクリックします。 FeatureDB データソースを作成する際に、[VPC 直接接続の構成] セクションで [VPC]、[ゾーンと VSwitch]、および [セキュリティグループ名] を構成します。具体的な手順については、「オンラインデータストア: FeatureDB」をご参照ください。
方法 2: FeatureDB データソースをすでに作成している場合は、[ストア] タブの [feature_db] をクリックします。表示されたページで、[VPC 直接接続の構成] をクリックします。 [VPC]、[ゾーンと VSwitch]、および [セキュリティグループ名] を指定し、[OK] をクリックします。
注意事項
[VPC] 設定は、設定後は変更できません。構成する VPC が、FeatureStore を使用するオンラインサービスが存在する VPC であることを確認してください。
ネットワークレイテンシを回避し、パフォーマンスを向上させるために、以下のゾーンにサービスをデプロイすることをお勧めします。
エリア
リージョン
推奨ゾーン
アジア太平洋
中国 (杭州)
ゾーン G
中国 (上海)
ゾーン L
中国 (北京)
ゾーン F
中国 (深圳)
ゾーン F
中国 (香港)
ゾーン B
シンガポール
ゾーン C
ヨーロッパおよびアメリカ
ドイツ (フランクフルト)
ゾーン A
米国 (シリコンバレー)
ゾーン B
[ゾーンと VSwitch]: オンラインサービスインスタンスが存在するゾーンの vSwitch を選択してください。高可用性と安定性のために、少なくとも 2 つのゾーンの vSwitch を選択することをお勧めします。
確認後、構成を変更または削除することはできません。他のゾーンの vSwitch を追加することのみ可能です。
特徴量の書き込み
オフライン特徴量の場合、FeatureStore Python SDK を使用して、DataWorks を介してスケジュールされたタスクを実行し、MaxCompute から FeatureDB にデータを同期できます。
リアルタイム特徴量の場合、Java SDK を使用して特徴量データを直接書き込むことができます。
// regionId、Alibaba Cloud アカウント、FeatureStore プロジェクトを構成する
Configuration configuration = new Configuration("cn-beijing",
Constants.accessId, Constants.accessKey,"fs_demo_featuredb" );
// FeatureDB のユーザー名とパスワードを構成する
configuration.setUsername(Constants.username);
configuration.setPassword(Constants.password);
// パブリックネットワークを使用して FeatureStore に接続する場合は、上記のドメイン情報を参照してください
// VPC 環境を使用する場合は、設定する必要はありません
//configuration.setDomain(Constants.host);
ApiClient client = new ApiClient(configuration);
// パブリックネットワーク接続を使用する場合は、usePublicAddress = true を設定します。VPC 環境では設定する必要はありません
// FeatureStoreClient featureStoreClient = new FeatureStoreClient(client, Constants.usePublicAddress);
FeatureStoreClient featureStoreClient = new FeatureStoreClient(client );
Project project = featureStoreClient.getProject("fs_demo_featuredb");
if (null == project) {
throw new RuntimeException("project not found"); // プロジェクトが見つかりません
}
FeatureView featureView = project.getFeatureView("user_test_2");
if (null == featureView) {
throw new RuntimeException("featureview not found"); // 特徴量ビューが見つかりません
}
List<Map<String, Object>> writeData = new ArrayList<>();
// 書き込むデータの構築をシミュレートする
for (int i = 0; i < 10; i++) {
Map<String, Object> data = new HashMap<>();
data.put("user_id", i);
data.put("string_field", String.format("test_%d", i));
data.put("int32_field", i);
data.put("int64_field", Long.valueOf(i));
data.put("float_field", Float.valueOf(i));
data.put("double_field", Double.valueOf(i));
data.put("boolean_field", i % 2 == 0);
writeData.add(data);
}
for (int i = 0; i < 100;i++) {
featureView.writeFeatures(writeData);
}
// これは一度だけ呼び出す必要があります。すべてのデータが書き込まれた場合は、すべての書き込みが完了していることを確認してください。このインターフェースを呼び出した後、writeFeatures を再度呼び出すことはできません。
featureView.writeFlush();
リアルタイム特徴量の書き込みでは、データ行全体がデフォルトで更新されます。書き込まれたデータに一部のフィールドのみが含まれている場合、書き込まれていないフィールドは空に設定されます。書き込まれたフィールドのみを更新し、元のデータとマージする場合は、次の設定を行うことができます。
Java SDK を使用する: InsertMode.PartialFieldWrite を指定する。
for (int i = 0; i < 100;i++) { featureView.writeFeatures(writeData, InsertMode.PartialFieldWrite); }Flink Connector を使用する: insert_mode を partial_field_write に設定する。
特徴量の読み取り
FeatureStore SDK(Go/Java)または EasyRec Processor を使用して特徴量を読み取ることができます。
FeatureStore SDK(Go/Java)は、オフライン/リアルタイム特徴量の KV ポイントクエリをサポートしています。 JoinID(プライマリキー)値と特徴量名を指定することで、ミリ秒単位でキーバリュー(KV)クエリを完了し、ターゲットの特徴量データを取得できます。 FeatureStore SDK(Go/Java)は、行動シーケンス特徴量の KKV クエリもサポートしています。 UserID 値を指定することで、アセンブルされたシーケンス特徴量のクエリ結果を取得できます。
EasyRec Processor は FeatureStore Cpp SDK を統合しており、FeatureDB からすべての特徴データをメモリにプルすることをサポートし、リアルタイム特徴データをメモリに更新するためのミリ秒レベルのポーリングをサポートすることで、より高いパフォーマンスの読み取りを実現します。
メトリクス
FeatureDB をオンラインデータソースとして使用する場合、特徴量ビューを作成した後、ターゲットビューの右側にある [データ監視] をクリックすると、そのビューの読み取りおよび書き込み QPS や RT などのメトリクスを表示できます。
リアルタイム特徴量リンク
FeatureStore が提供するストレージサービスは、主に Feature Service(アクセスレイヤー)、MSMQ(DataHub)、および FeatureDB の 3 つの部分で構成されています。
リアルタイム特徴量では、ユーザーは FeatureStore Java SDK または Flink Connector を介して特徴量サービスを呼び出し、特徴量データを FeatureDB に書き込むことができます。 特徴量サービスを介して書き込まれたデータは、ユーザーの MaxCompute テーブルにも同期され、リアルタイム特徴量サンプルのエクスポートやさらなるモデルトレーニングに使用できます。
FeatureDB に保存されている特徴量データは、FeatureStore の Java/Go SDK を介して読み取るか、EasyRec Processor を介してすべての特徴量をプルしてローカルキャッシュに保存することで、より高パフォーマンスの読み取りを実現できます。 リアルタイム特徴量の場合、ミリ秒レベルで最新の特徴量情報を取得できます。
リアルタイム特徴量のライフサイクル
リアルタイム特徴量ビューを作成する際に、FeatureDB テーブルの [特徴量のライフサイクル] を指定できます。行の生存時間がライフサイクルに達すると、数秒以内に自動的にクリーンアップされます。
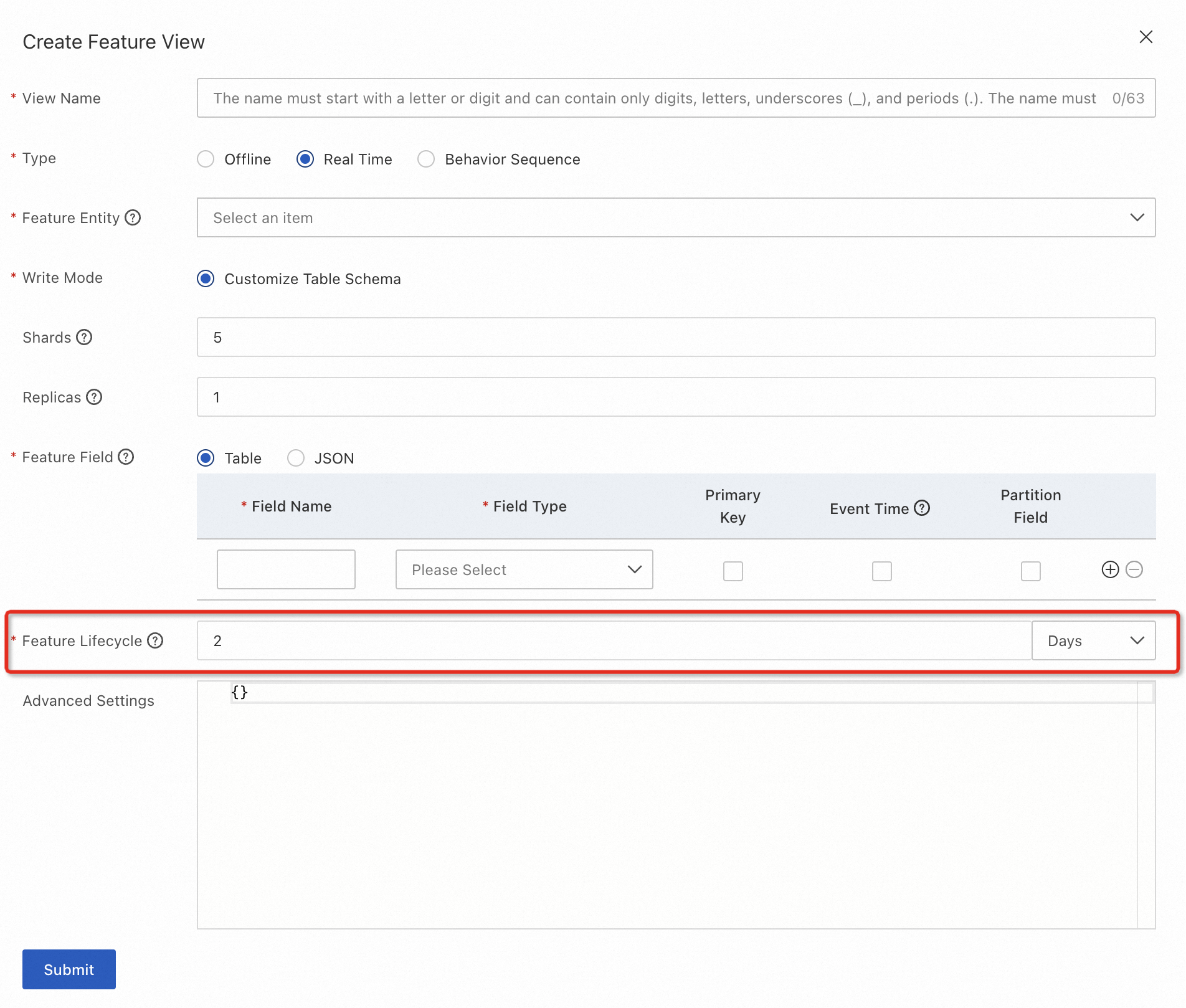
次の方法で生存時間を指定できます。
方法 1: [イベント時間] フィールドを設定しない。この場合、生存時間はデータの書き込み時間に基づいて計算されます。
方法 2: 特徴量フィールドの [イベント時間] をオンにする。単位はミリ秒です。 event_time が [イベント時間] の値、time_now が現在の時刻、time_ttl = time_now - ttl がデータの有効期限が切れ始める event_time であると仮定します。書き込まれた特徴量データの具体的な処理方法は次のとおりです。
PartialFieldWrite モードを使用して部分フィールド更新書き込みを行う場合、生存時間は実際のデータ書き込み時間に基づきます。
event_time > time_now + 15 分: データは書き込まれません。(これは、異なるシステム間のタイムスタンプの差異を防ぎ、15 分のバッファを許容します)
time_ttl < event_time <= time_now + 15 分: データは正常に書き込まれ、生存時間は event_time から計算され、データの行はライフサイクルに達すると自動的にクリーンアップされます。
0 < event_time < time_ttl: データは書き込まれた後に自動的にクリーンアップされます。 event_time の単位はミリ秒であることに注意してください。 [イベント時間] フィールドの値が秒単位の場合、このケースに該当し、データが正常に書き込まれません。
event_time <= 0: 生存時間は実際のデータ書き込み時間に基づいて計算されます。
無効な値(整数に変換できない): データは書き込まれません。
[イベント時間] フィールドを登録したが、[イベント時間] フィールドの値を渡さなかった: データは正常に書き込まれ、生存時間は実際のデータ書き込み時間に基づいて計算されます。
[イベント時間] フィールドがない: データは正常に書き込まれ、生存時間は実際のデータ書き込み時間に基づいて計算されます。
さらに、FeatureDB では、event_time の値はこのデータ行の ts として使用されます。つまり、キーに対応するデータを更新する必要がある場合、[イベント時間] フィールドの値は、このデータ行が更新される前の値以上である必要があります。新しい event_time < 元の event_time 値の場合、このキーに対応するデータは更新されません。
パフォーマンステスト
FeatureStore Go SDK を使用した FeatureDB データの読み取りに関するパフォーマンステスト結果の例を以下に示します。選択した特徴量テーブルデータは、レコメンデーションシナリオのユーザー側データで、特徴量テーブルには合計 17,689,586 行あります。テストマシンのコア数は 4、メモリは 8GiB です。テスト結果は参考値です。
VPC 直接接続 が構成されており、オンラインサービスが 推奨ゾーン にある場合:
特徴量フィールドの数(列)
読み取られたキーの数(行)
平均レイテンシ
TP95
TP99
260
1
0.89 ミリ秒
1.20 ミリ秒
1.45 ミリ秒
260
10
1.17 ミリ秒
1.52 ミリ秒
1.87 ミリ秒
260
50
1.91 ミリ秒
2.56 ミリ秒
2.92 ミリ秒
260
100
2.87 ミリ秒
3.58 ミリ秒
3.93 ミリ秒
260
200
4.43 ミリ秒
5.25 ミリ秒
5.80 ミリ秒
VPC 直接接続は構成されているが、オンラインサービスが推奨されていないゾーンにある場合:
特徴量フィールドの数(列)
読み取られたキーの数(行)
平均レイテンシ
TP95
TP99
260
1
2.54 ミリ秒
2.86 ミリ秒
3.15 ミリ秒
260
10
2.75 ミリ秒
3.12 ミリ秒
3.56 ミリ秒
260
50
3.95 ミリ秒
4.75 ミリ秒
5.19 ミリ秒
260
100
4.82 ミリ秒
5.66 ミリ秒
6.21 ミリ秒
260
200
6.84 ミリ秒
7.75 ミリ秒
8.25 ミリ秒
VPC 直接接続が構成されていない場合:
特徴量フィールドの数(列)
読み取られたキーの数(行)
平均レイテンシ
TP95
TP99
260
1
3.62 ミリ秒
3.83 ミリ秒
4.27 ミリ秒
260
10
3.82 ミリ秒
4.11 ミリ秒
4.61 ミリ秒
260
50
4.54 ミリ秒
5.19 ミリ秒
5.60 ミリ秒
260
100
5.40 ミリ秒
6.13 ミリ秒
6.56 ミリ秒
260
200
7.15 ミリ秒
7.93 ミリ秒
8.47 ミリ秒
課金
詳細については、「FeatureStore の課金」をご参照ください。