Platform for AI (PAI) では、ビジネス要件に基づいてカスタムアルゴリズムコンポーネントを作成できます。カスタムコンポーネントを Machine Learning Designer の組み込みコンポーネントと一緒に使用して、柔軟にパイプラインを構築できます。このトピックでは、カスタムコンポーネントの作成方法について説明します。
背景情報
カスタムコンポーネントは、Alibaba Cloud のオープンソース KubeDL を使用します。これは、ワークロードを管理するための Kubernetes ベースの AI フレームワークです。
カスタムコンポーネントを作成する際には、TensorFlow、PyTorch、XGBoost、ElasticBatch など、コンポーネントを使用するジョブのタイプを選択できます。また、入力パイプラインと出力パイプラインを作成し、ハイパーパラメータを構成することもできます。カスタムコンポーネントを作成したら、Machine Learning Designer でコンポーネントを構成できます。詳細については、「手順」をご参照ください。
KubeDL は、ジョブタイプに基づいて環境変数を割り当てます。環境変数を使用して、インスタンスの数とトポロジ情報を取得できます。詳細については、「付録 1: ジョブタイプ」をご参照ください。
環境変数を構成して入力パイプラインと出力パイプラインのデータとハイパーパラメータを取得する方法については、「パイプラインとハイパーパラメータのデータを取得する」をご参照ください。
コード内で環境変数を使用して、入力パイプラインと出力パイプラインのデータを取得できます。また、コンテナ内のマウントパスを使用してデータにアクセスすることもできます。詳細については、「入力ディレクトリと出力ディレクトリの構造」をご参照ください。
前提条件
ワークスペースが作成されていること。作成したカスタムコンポーネントはワークスペースに関連付けられています。詳細については、「ワークスペースの作成と管理」をご参照ください。
手順
カスタムコンポーネント ページに移動します。
PAI コンソール にログインします。
左側のナビゲーションウィンドウで、[ワークスペース] をクリックします。ワークスペース ページで、カスタムコンポーネントを作成するワークスペースの名前をクリックします。
左側のナビゲーションウィンドウで、[AI コンピューティングアセット管理] > [カスタムコンポーネント] を選択します。
[カスタムコンポーネント] ページで、[コンポーネントの作成] をクリックします。[コンポーネントの作成] ページで、次の表に示すパラメータを構成します。
基本情報
パラメータ
説明
コンポーネント名
カスタムコンポーネントの名前。名前は、同じリージョンの Alibaba Cloud アカウント内で一意である必要があります。
[コンポーネントの説明]
カスタムコンポーネントの説明。
コンポーネントバージョン
カスタムコンポーネントのバージョン番号。
説明コンポーネントバージョンは
x.y.z形式で管理することをお勧めします。たとえば、最初のメジャーバージョンが 1.0.0 の場合、マイナーな問題を修正する場合はバージョンを 1.0.1 に、マイナーな機能をアップグレードする場合は 1.1.0 にアップグレードできます。これは、コンポーネントバージョンを簡単かつ効果的に管理するのに役立ちます。[バージョンの説明]
カスタムコンポーネントの現在のバージョンの説明。例: 初期バージョン。
実行構成
パラメータ
説明
ジョブタイプ
カスタムコンポーネントを使用するジョブのタイプ。 有効な値: TFJob の場合は [Tensorflow]、PyTorchJob の場合は [PyTorch]、XGBoostJob の場合は [XGBoost]、および KubeDL の ElasticBatchJob の場合は [ElasticBatch]。 ジョブタイプの詳細については、「付録: ジョブタイプ」をご参照ください。
画像
使用するイメージ。有効な値: [コミュニティイメージ]、[Alibaba Cloud イメージ]、[カスタムイメージ]。ドロップダウンリストからイメージを選択するか、[イメージアドレス] を選択してイメージアドレスを指定できます。
説明ジョブの安定性を確保するために、同じリージョンの Alibaba Cloud Container Registry (ACR) を使用することをお勧めします。
Container Registry Personal Edition のみ使用できます。Container Registry Enterprise Edition はサポートされていません。イメージアドレスは
registry-vpc.${region}.aliyuncs.com形式で指定します。カスタムイメージを使用する場合は、カスタムコンポーネントの同じバージョンでイメージを頻繁に更新しないことをお勧めします。イメージを頻繁に更新すると、イメージキャッシュがすぐに更新されない可能性があり、ジョブの起動が遅れる可能性があります。
イメージが想定どおりに実行されるようにするには、イメージに
sh shellコマンドが含まれている必要があります。イメージは、sh -cメソッドを使用してコマンドを実行します。カスタムイメージを使用する場合は、イメージに必要な環境と Python 用の pip コマンドが含まれていることを確認してください。そうでない場合、ジョブが失敗する可能性があります。
コード
有効な値:
OSS パスのマウント: コンポーネントを実行すると、Object Storage Service (OSS) パスにあるすべてのファイルが
/ml/usercode/パスにダウンロードされます。コマンドを実行して、パス内のファイルを実行できます。説明コンポーネントの起動中に遅延やタイムアウトが発生するのを防ぐために、このパスには必要なアルゴリズムファイルのみを保存することをお勧めします。
requirements.txt ファイルがコードディレクトリに存在する場合、アルゴリズムは自動的に
pip install -r requirements.txtコマンドを実行して関連する依存関係をインストールします。
コード構成: Git コードリポジトリを構成します。
コマンド
イメージが実行するコマンド。コマンドは次の形式で指定します。
python main.py $PAI_USER_ARGS --{CHANNEL_NAME} $PAI_INPUT_{CHANNEL_NAME} --{CHANNEL_NAME} $PAI_OUTPUT_{CHANNEL_NAME} && sleep 150 && echo "job finished"ハイパーパラメータと入力パイプラインおよび出力パイプラインに関する情報を取得するには、次の環境変数を構成します。PAI_USER_ARGS、PAI_INPUT_{CHANNEL_NAME}、PAI_OUTPUT_{CHANNEL_NAME}。データの取得方法の詳細については、「パイプラインとハイパーパラメータのデータを取得する」をご参照ください。
たとえば、入力パイプラインの名前が test と train で、出力パイプラインの名前が model と checkpoints であるとします。コマンドの例:
python main.py $PAI_USER_ARGS --train $PAI_INPUT_TRAIN --test $PAI_INPUT_TEST --model $PAI_OUTPUT_MODEL --checkpoints $PAI_OUTPUT_CHECKPOINTS && sleep 150 && echo "job finished"main.py ファイルは、引数を解析するためのロジックの例を示しています。ビジネス要件に基づいてファイルを修正できます。ファイルの内容の例:
import os import argparse import json def parse_args(): """引数を解析します。""" // Parse the arguments. parser = argparse.ArgumentParser(description="PythonV2 コンポーネントスクリプトの例。") // PythonV2 component script example. # 入力チャンネルと出力チャンネル // input & output channels parser.add_argument("--train", type=str, default=None, help="入力チャンネル train。") // input channel train. parser.add_argument("--test", type=str, default=None, help="入力チャンネル test。") // input channel test. parser.add_argument("--model", type=str, default=None, help="出力チャンネル model。") // output channel model. parser.add_argument("--checkpoints", type=str, default=None, help="出力チャンネル checkpoints。") // output channel checkpoints. # パラメータ // parameters parser.add_argument("--param1", type=int, default=None, help="param1") parser.add_argument("--param2", type=float, default=None, help="param2") parser.add_argument("--param3", type=str, default=None, help="param3") parser.add_argument("--param4", type=bool, default=None, help="param4") parser.add_argument("--param5", type=int, default=None, help="param5") args, _ = parser.parse_known_args() return args if __name__ == "__main__": args = parse_args() print("入力チャンネル train={}".format(args.train)) // Input channel train={} print("入力チャンネル test={}".format(args.test)) // Input channel test={} print("出力チャンネル model={}".format(args.model)) // Output channel model={} print("出力チャンネル checkpoints={}".format(args.checkpoints)) // Output channel checkpoints={} print("パラメータ param1={}".format(args.param1)) // Parameters param1={} print("パラメータ param2={}".format(args.param2)) // Parameters param2={} print("パラメータ param3={}".format(args.param3)) // Parameters param3={} print("パラメータ param4={}".format(args.param4)) // Parameters param4={} print("パラメータ param5={}".format(args.param5)) // Parameters param5={}コマンド実行のログで、入力パイプラインと出力パイプライン、およびパラメータに関する情報を取得できます。ログの例:
Input channel train=/ml/input/data/train Input channel test=/ml/input/data/test/easyrec_config.config Output channel model=/ml/output/model/ Output channel checkpoints=/ml/output/checkpoints/ Parameters param1=6 Parameters param2=0.3 Parameters param3=test1 Parameters param4=True Parameters param5=2 job finishedパイプラインとパラメータ
 アイコンをクリックして、カスタムコンポーネントの入力パイプラインと出力パイプライン、およびパラメータを構成します。パイプラインとパラメータの名前は、次の形式で指定します。
アイコンをクリックして、カスタムコンポーネントの入力パイプラインと出力パイプライン、およびパラメータを構成します。パイプラインとパラメータの名前は、次の形式で指定します。名前はグローバルに一意である必要があります。
名前に数字、文字、アンダースコア (_)、ハイフン (-) を使用できますが、アンダースコア (_) で始めることはできません。
説明名前にサポートされていない文字が含まれている場合、システムが環境変数を生成するときに、その文字はアンダースコア (_) に置き換えられます。ハイフン (-) もアンダースコア (_) に置き換えられることに注意してください。名前の小文字は大文字に自動的に変換されます。たとえば、パラメータ名を test_model と test-model として指定すると、名前は PAI_HPS_TEST_MODEL に変換され、競合が発生する可能性があります。
次の図は、パイプラインとパラメータの構成と、Machine Learning Designer のコンポーネントパラメータとの間のマッピングを示しています。
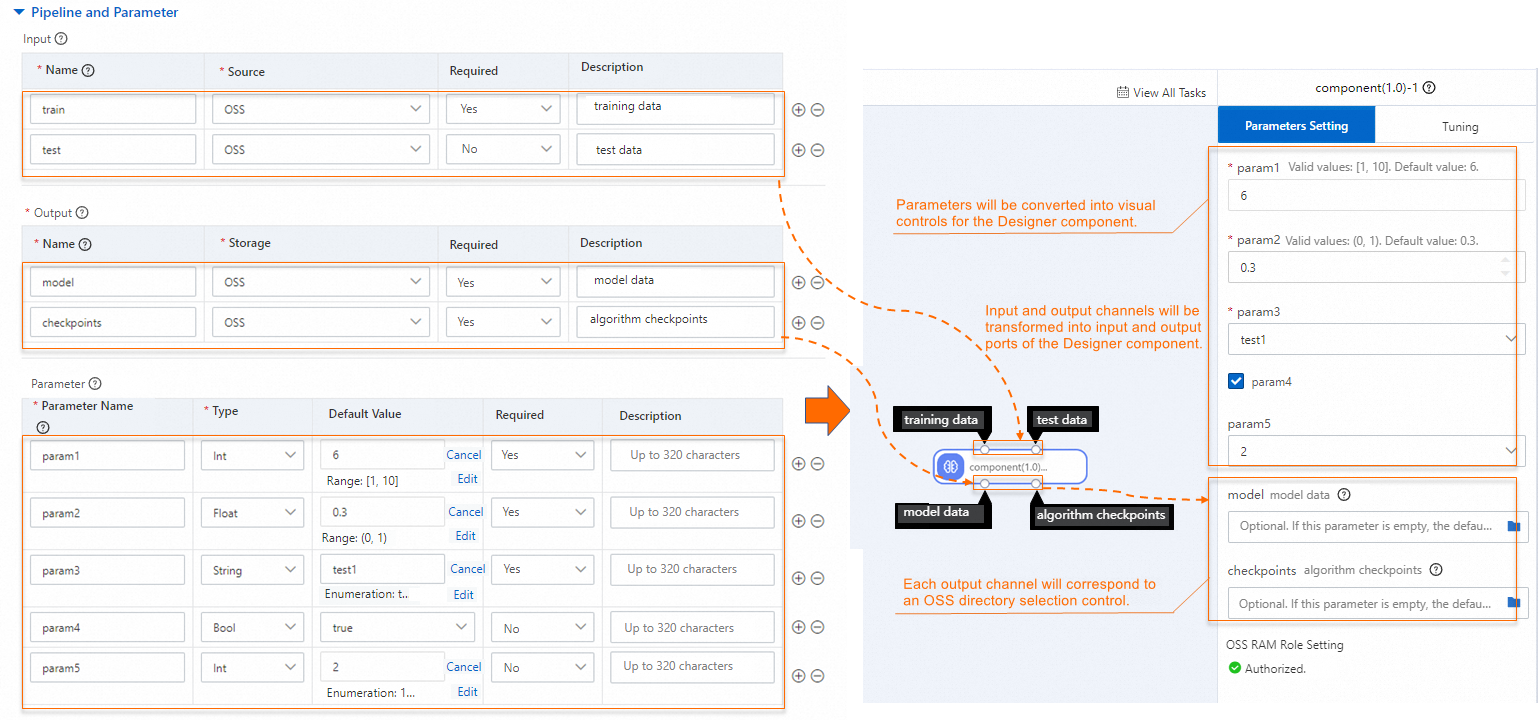
次の表にパラメータを示します。
パラメータ
説明
入力
カスタムコンポーネントが入力データまたはモデルを取得するソース。次のパラメータを構成します。
[名前]: 入力パイプラインの名前を指定します。
[ソース]: 入力パイプラインがデータを取得する OSS、File Storage NAS (NAS)、または MaxCompute のパスを指定します。入力データは、トレーニングコンテナの
/ml/input/data/{channel_name}/ディレクトリにマウントされます。コンポーネントは、オンプレミスファイルを読み取ることで、OSS、NAS、または MaxCompute からデータを読み取ることができます。
出力
出力パイプラインは、トレーニング済みモデルやチェックポイントなどの結果を保存するために使用されます。次のパラメータを構成します。
[名前]: 出力パイプラインの名前。
[ストレージ]: 各出力パイプラインの OSS または MaxCompute ディレクトリを指定します。指定したディレクトリは、トレーニングコンテナの
/ml/output/{channel_name}/ディレクトリにマウントされます。
パラメーター
ハイパーパラメータに関する情報。次のパラメータを構成します。
パラメーター名: パラメーターの名前です。
[タイプ]: パラメータのタイプ。有効な値: Int、Float、String、Bool。
制約: Bool 以外のタイプ (Int、Float、または String) を選択した後、[デフォルト値] 列で [制約] をクリックして、パラメータの制約を構成します。制約タイプの有効な値:
[範囲]: 最大値と最小値を指定して値の範囲を指定します。
[列挙]: パラメータの列挙値を構成します。
制約
トレーニングジョブに必要な計算リソースを指定するために使用されるトレーニング制約。[制約を有効にする] をオンにして、トレーニング制約を構成します。
次の図は、トレーニング制約と、Machine Learning Designer のコンポーネントの調整パラメータとの間のマッピングを示しています。
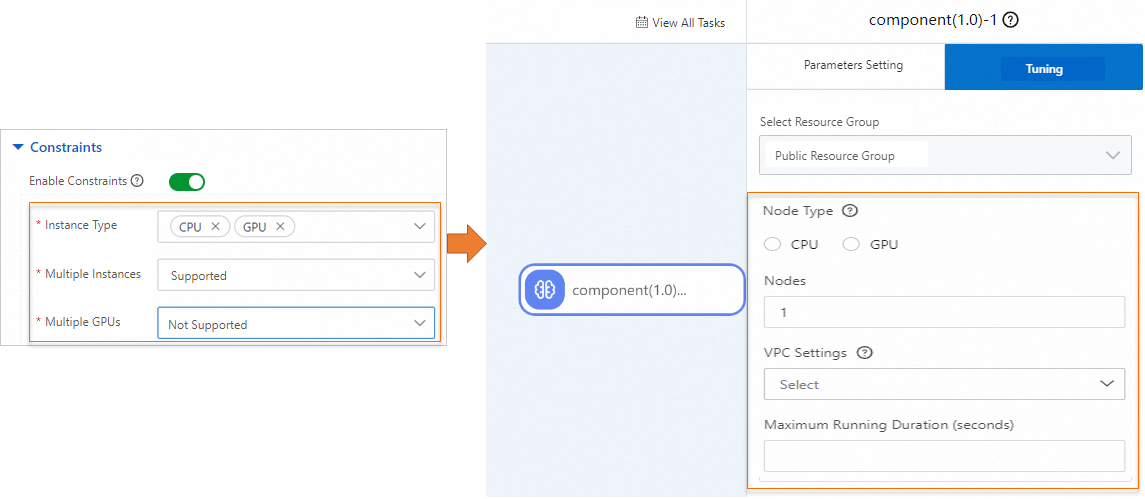
次の表にパラメータを示します。
パラメータ
説明
インスタンスタイプ
有効な値: CPU と GPU。
[複数インスタンス]
コンポーネントが複数インスタンスでの分散トレーニングをサポートするかどうかを指定します。有効な値:
[サポート]: コンポーネントの実行時にインスタンスの数を構成できます。
[サポートなし]: コンポーネントの実行時のインスタンスの数は 1 のみで、変更できません。
複数の GPU
このパラメータは、[インスタンスタイプ] パラメータを GPU に設定した場合にのみ使用できます。
カスタムコンポーネントが複数 GPU をサポートするかどうかを指定します。
このパラメータを [サポート] に設定すると、単一 GPU または複数 GPU のインスタンスタイプを選択してコンポーネントを実行できます。
このパラメータを [サポートなし] に設定すると、単一 GPU のインスタンスタイプのみを選択してコンポーネントを実行できます。
[送信] をクリックします。
作成したカスタムコンポーネントが カスタムコンポーネント ページに表示されます。
カスタムコンポーネントを作成したら、Machine Learning Designer でコンポーネントを使用できます。詳細については、「カスタムコンポーネントを使用する」をご参照ください。
付録 1: ジョブタイプ
TensorFlow (TFJob)
ジョブタイプ パラメータを TensorFlow に設定すると、システムは TF_CONFIG 環境変数を使用して、ジョブが実行されるインスタンストポロジ情報を挿入します。次の例は、環境変数の形式を示しています。
{
"cluster": {
"chief": [
"dlc17****iui3e94-chief-0.t104140334615****.svc:2222"
],
"evaluator": [
"dlc17****iui3e94-evaluator-0.t104140334615****.svc:2222"
],
"ps": [
"dlc17****iui3e94-ps-0.t104140334615****.svc:2222"
],
"worker": [
"dlc17****iui3e94-worker-0.t104140334615****.svc:2222",
"dlc17****iui3e94-worker-1.t104140334615****.svc:2222",
"dlc17****iui3e94-worker-2.t104140334615****.svc:2222",
"dlc17****iui3e94-worker-3.t104140334615****.svc:2222"
]
},
"task": {
"type": "chief",
"index": 0
}
}次の表に、上記のコードのパラメータを示します。
パラメータ | 説明 |
cluster | TensorFlow クラスタの説明。
|
task |
|
PyTorch (PyTorchJob)
ジョブタイプ パラメータを PyTorch に設定すると、システムは次の環境変数を挿入します。
RANK: インスタンスのロール。値 0 は、インスタンスがマスターノードであることを指定します。0 以外の値は、インスタンスがワーカーノードであることを指定します。
WORLD_SIZE: ジョブ内のインスタンスの数。
MASTER_ADDR: マスターノードのアドレス。
MASTER_PORT: マスターノードのポート。
XGBoost (XGBoostJob)
ジョブタイプ パラメータを XGBoost に設定すると、システムは次の環境変数を挿入します。
RANK: インスタンスのロール。値 0 は、インスタンスがマスターノードであることを指定します。0 以外の値は、インスタンスがワーカーノードであることを指定します。
WORLD_SIZE: ジョブ内のインスタンスの数。
MASTER_ADDR: マスターノードのアドレス。
MASTER_PORT: マスターノードのポート。
WORKER_ADDRS: ワーカーノードのアドレス (RANK でソート)。
WORKER_PORT: ワーカーノードのポート。
例:
分散ジョブ (複数インスタンス)
WORLD_SIZE=6 WORKER_ADDRS=train1pt84cj****-worker-0,train1pt84cj****-worker-1,train1pt84cj****-worker-2,train1pt84cj****-worker-3,train1pt84cj****-worker-4 MASTER_PORT=9999 MASTER_ADDR=train1pt84cj****-master-0 RANK=0 WORKER_PORT=9999単一インスタンスジョブ
説明ジョブにインスタンスが 1 つしかない場合、そのインスタンスはマスターノードであり、WORKER_ADDRS 環境変数と WORKER_PORT 環境変数は使用できません。
WORLD_SIZE=1 MASTER_PORT=9999 MASTER_ADDR=train1pt84cj****-master-0 RANK=0
ElasticBatch (ElasticBatchJob)
ElasticBatch は、分散オフライン推論ジョブの一種です。ElasticBatch ジョブには次の利点があります。
二重スループットをサポートする高い並列性を実現します。
ジョブの待ち時間を短縮します。ワーカーノードは、リソースが割り当てられた直後に実行できます。
インスタンスの起動を監視し、起動が遅延しているインスタンスをバックアップワーカーノードに自動的に置き換えます。これにより、ロングテールやジョブのハングを防ぎます。
リソースをより効率的に使用するグローバルなデータシャードの動的配布をサポートします。
ジョブの早期停止をサポートします。すべてのデータが処理された後、システムは起動されていないワーカーノードを起動せず、ジョブの稼働時間の増加を防ぎます。
フォールトトレランスをサポートします。単一のワーカーノードに障害が発生した場合、システムは自動的にインスタンスを再起動します。
ElasticBatch ジョブは、AIMaster と Worker という 2 つのタイプのノードで構成されます。
AIMaster ノードは、データシャードの動的配布、各ワーカーノードのデータスループットパフォーマンスの監視、フォールトトレランスなど、ジョブのグローバル制御に使用されます。
ワーカーノードは AIMaster からシャードを取得し、データの読み取り、処理、書き戻しを行います。データシャードの動的配布により、効率的なインスタンスは低速なインスタンスよりも多くのデータを処理できます。
ElasticBatch ジョブを開始すると、AIMaster ノードとワーカーノードが起動されます。コードはワーカーノードで実行されます。システムは ELASTICBATCH_CONFIG 環境変数をワーカーノードに挿入します。次の例は、環境変数値の形式を示しています。
{
"task": {
"type": "worker",
"index": 0
},
"environment": "cloud"
}次のパラメータに注意してください。
task.type: 現在のインスタンスのジョブタイプ。
task.index: ロールのネットワークアドレスのリストにおけるインスタンスのインデックス。
付録 2: カスタムコンポーネントの原則
パイプラインとハイパーパラメータのデータを取得する
入力パイプラインデータを取得する
入力パイプラインのデータは、PAI_INPUT_{CHANNEL_NAME} 環境変数を使用してジョブコンテナに挿入されます。
たとえば、カスタムコンポーネントに train と test という名前の 2 つの入力パイプラインがあり、値が oss://<YourOssBucket>.<OssEndpoint>/path-to-data/ と oss://<YourOssBucket>.<OssEndpoint>/path-to-data/test.csv の場合、次の環境変数が挿入されます。
PAI_INPUT_TRAIN=/ml/input/data/train/
PAI_INPUT_TEST=/ml/input/data/test/test.csv出力パイプラインデータを取得する
システムは、PAI_OUTPUT_{CHANNEL_NAME} 環境変数を使用してデータを取得します。
たとえば、カスタムコンポーネントに model と checkpoints という名前の 2 つの出力パイプラインがある場合、次の環境変数が挿入されます。
PAI_OUTPUT_MODEL=/ml/output/model/
PAI_OUTPUT_CHECKPOINTS=/ml/output/checkpoints/ハイパーパラメータデータを取得する
システムは、次の環境変数を使用してハイパーパラメータデータを取得します。
PAI_USER_ARGS
コンポーネントの実行時、ジョブのすべてのハイパーパラメータ情報は、
--{hyperparameter_name} {hyperparameter_value}形式の PAI_USER_ARGS 環境変数を使用してジョブコンテナに挿入されます。たとえば、ジョブに
{"epochs": 10, "batch-size": 32, "learning-rate": 0.001}などのハイパーパラメータを指定した場合、PAI_USER_ARGS 環境変数の値は次のようになります。PAI_USER_ARGS="--epochs 10 --batch-size 32 --learning-rate 0.001"PAI_HPS_{HYPERPARAMETER_NAME}
単一のハイパーパラメータの値は、PAI_HPS_{HYPERPARAMETER_NAME} 環境変数を使用してジョブコンテナに挿入されます。ハイパーパラメータ名では、サポートされていない文字はアンダースコア (_) に置き換えられます。
たとえば、ジョブに
{"epochs": 10, "batch-size": 32, "train.learning_rate": 0.001}などのハイパーパラメータを指定した場合、環境変数の値は次のようになります。PAI_HPS_EPOCHS=10 PAI_HPS_BATCH_SIZE=32 PAI_HPS_TRAIN_LEARNING_RATE=0.001PAI_HPS
トレーニングジョブのハイパーパラメータ情報は、JSON 形式の PAI_HPS 環境変数を使用してコンテナに挿入されます。
たとえば、ジョブに
{"epochs": 10, "batch-size": 32}などのハイパーパラメータを指定した場合、PAI_HPS 環境変数の値は次のようになります。PAI_HPS={"epochs": 10, "batch-size": 32}
入出力ディレクトリ構造
コード内の環境変数を使用して入出力パイプライン情報を取得できます。また、コンテナー内のマウントパスを使用してデータにアクセスすることもできます。コンポーネントによって送信されたジョブがコンテナーで実行されると、次のルールに基づいてパスが作成されます:
コードパス:
/ml/usercode/。ハイパーパラメータの構成ファイル:
/ml/input/config/hyperparameters.json。トレーニングジョブの構成ファイル:
/ml/input/config/training_job.json。入力パイプラインのディレクトリ:
/ml/input/data/{channel_name}/。出力パイプラインのディレクトリ:
/ml/output/{channel_name}/。
次のコードは、カスタムコンポーネントによって送信されたジョブの入出力ディレクトリ構造の例です:
/ml
|-- usercode # ユーザーコードは /ml/usercode ディレクトリにロードされます。これはユーザーコードの作業ディレクトリでもあります。PAI_WORKING_DIR 環境変数を使用して値を取得できます。
| |-- requirements.txt
| |-- main.py
|-- input # ジョブの入力データと構成情報。
| |-- config # config ディレクトリには、ジョブの構成情報が含まれています。PAI_CONFIG_DIR 環境変数を使用して構成情報を取得できます。
| |-- training_job.json # ジョブの構成。
| |-- hyperparameters.json # ジョブのハイパーパラメータ。
| |-- data # ジョブの入力パイプライン。この例では、ディレクトリには train_data と test_data という名前のパイプラインが含まれています。
| |-- test_data
| | |-- test.csv
| |-- train_data
| |-- train.csv
|-- output # ジョブの出力パイプライン。この例では、ディレクトリには model と checkpoints という名前のパイプラインが含まれています。
|-- model # PAI_OUTPUT_{OUTPUT_CHANNEL_NAME} 環境変数を使用して出力パスを取得できます。
|-- checkpointsインスタンスが GPU インスタンスであるか、またその GPU 数を判断する方法
ジョブを開始した後、NVIDIA_VISIBLE_DEVICES 環境変数を使用して GPU の数を確認できます。たとえば、NVIDIA_VISIBLE_DEVICES=0,1,2,3 は、インスタンスに 4 つの GPU があることを示します。