「おすすめソリューション - ランク」を使用して、特徴エンジニアリングによって処理されたユーザー特徴テーブル、アイテム特徴テーブル、およびユーザー行動テーブルに基づいてランキングモデルをトレーニングし、そのランキングモデルをオンラインサービスとしてデプロイできます。このトピックでは、ランク付けの実装方法について説明します。
前提条件
特徴エンジニアリングワークフローが実行され、ランキング用のデータセットが生成されていること。 詳細については、「特徴エンジニアリング」をご参照ください。
rec_sln_demo_user_table_preprocess_all_feature_v2
rec_sln_demo_item_table_preprocess_all_feature_v2
rec_sln_demo_behavior_table_preprocess_v2
手順
可視化モデリング (Designer) ページに移動します。
Machine Learning Platform for AI (PAI) コンソールにログインします。
左側のナビゲーションウィンドウで [Workspaces] をクリックします。 [Workspaces] ページで、管理するワークスペースの名前をクリックします。
左側のナビゲーションウィンドウで、[Model Training > Visualized Modeling (Designer)] を選択します。 [Visualized Modeling (Machine Learning Designer)] ページが表示されます。
パイプラインを作成します。
[Visualized Modeling (Designer)] ページで、[プリセットテンプレート] タブをクリックします。
テンプレートリストで、[Recommended Solutions - Rank] セクションの [作成] をクリックします。
[パイプラインの作成] ダイアログボックスで、次のパラメーターを設定します。 デフォルト値を使用できます。
[データストレージ] は、特徴エンジニアリングと同じ OSS バケットパスを使用して、ワークフローの実行中に生成された一時データとモデルファイルを保存します。
[OK] をクリックします。 パイプラインの作成には約 10 秒かかります。
次の図に示すように、キャンバスでパイプラインのコンポーネントを表示します。 プリセットテンプレートに基づいて、システムがパイプラインを自動的に作成します。
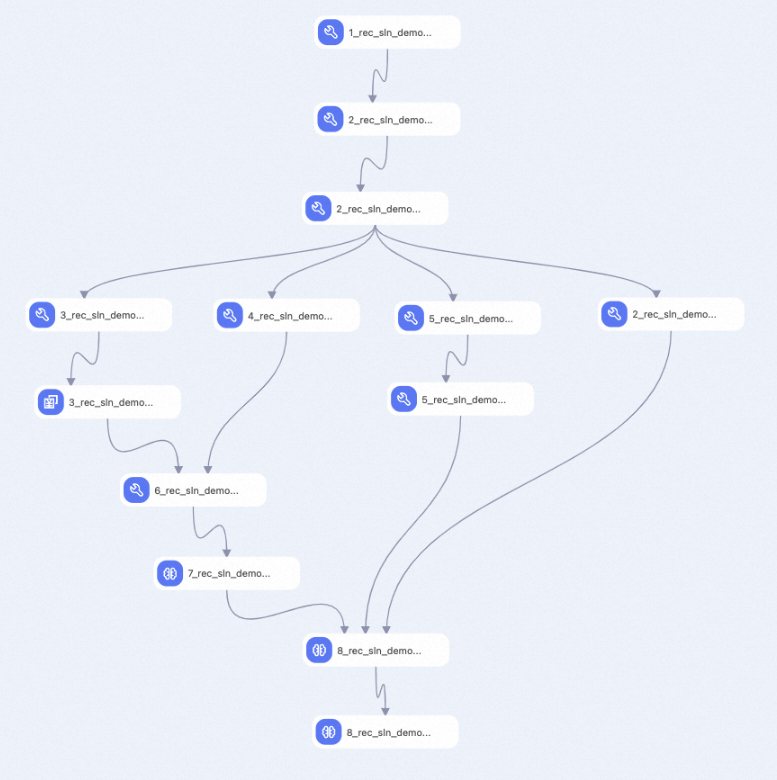
コンポーネント番号
説明
1
サンプルモデル。
2
fg.json ファイルに基づいて、特徴生成 (FG) を使用してサンプルモデルを処理します。
3
数値特徴の等頻度ビニングを使用して、モデルの boundaries を設定します。
4
列挙特徴の一意な値の数を使用して、モデルの embedding_dim と hash_bucket_size を設定します。
5
rec_sln_demo_sorting モデルの 30 日間のサンプルデータを離散化して、トレーニングサンプルを生成します。
6
rec_sln_demo_rec_sln_demo_sorting_30d_binning_v2 テーブルと rec_sln_demo_rec_sln_demo_sorting_30d_count_v2 テーブルの結果を要約して、特徴構成情報とステップ構成情報を計算します。
7
コンポーネント 6 の計算結果に基づいて EasyRec 構成ファイルを指定します。
説明このコンポーネントは 1 回だけ実行する必要があります。
8
モデルトレーニングの前に、コンポーネント 7 を実行して EasyRec 構成ファイルを生成する必要があります。