レコメンデーションアルゴリズムによってトレーニングされたフィーチャエンジニアリング機能を使用して、元のデータセットを処理し、その後のベクトルの再呼び出しまたはランク付け操作で使用できる新しいフィーチャテーブルを生成できます。 元のデータセットには、ユーザーテーブル、アイテムテーブル、または動作テーブルなどのテーブルが含まれます。
前提条件
Platform for AI (PAI) のMachine Learning Designerがアクティブ化され、デフォルトのワークスペースが作成されます。 詳細については、「PAIの有効化とデフォルトワークスペースの作成」をご参照ください。
MaxComputeリソースはワークスペースに関連付けられています。 詳細については、「ワークスペースの管理」をご参照ください。
MaxComputeデータソースが作成され、ワークスペースのエンジンとして関連付けられます。 詳細については、「新しいバージョンのMaxComputeデータソースの追加」をご参照ください。
データセット
スクリプトによって生成されるユーザーテーブル、アイテムテーブル、および動作テーブルは、実際のデータセットではありません。 次のデモでは、テーブルを例として使用します。
ユーザーテーブル: pai_online_project.rec_sln_demo_user_table
フィールド | 種類 | 説明 |
user_id | bigint | 一意のユーザー ID です。 |
gender | String | ユーザーの性別。 |
age | bigint | ユーザーの年齢。 |
city | String | ユーザーが住んでいる都市。 |
item_cnt | bigint | ユーザーが作成するコンテンツの数。 |
follow_cnt | bigint | ユーザーがフォローしているユーザーの数。 |
follower_cnt | bigint | ユーザーのフォロワー数。 |
register_time | bigint | アカウントの登録時間。 |
tags | String | ユーザーのタグ。 |
ds | String | テーブル内のパーティション列の名前。 |
アイテムテーブル: pai_online_project.rec_sln_demo_item_table
フィールド | 種類 | 説明 |
item_id | bigint | アイテムのID。 |
期間 | double | ビデオの長さ。 |
タイトル | String | アイテムのタイトル。 |
カテゴリ | String | レベル1タグ。 |
著者 | bigint | アイテムの作成者。 |
click_count | bigint | アイテムの合計クリック数。 |
praise_count | bigint | アイテムのいいね! |
pub_time | bigint | アイテムがリリースされた日付。 |
ds | String | テーブル内のパーティション列の名前。 |
行動表: pai_online_project.rec_sln_demo_behavior_table
フィールド | 種類 | 説明 |
request_id | bigint | トラッキングポイントまたはリクエストのID。 |
user_id | bigint | 一意のユーザー ID です。 |
exp_id | String | 実験ID。 |
page | String | ページ。 |
net_type | String | ネットワークタイプ。 |
event_time | bigint | 動作が発生した時刻。 |
item_id | bigint | アイテムのID。 |
event | String | 動作のタイプ。 |
プレイタイム | double | 再生時間または読み取り時間 |
ds | String | テーブル内のパーティション列の名前。 |
手順
ステップ1:機械学習デザイナー
PAIコンソールにログインします。
左側のナビゲーションウィンドウで、[ワークスペース] をクリックします。 [ワークスペース] ページで、管理するワークスペースの名前をクリックします。
左側のナビゲーションウィンドウで、モデルの開発とトレーニング> 視覚化モデリング (デザイナー) を選択します。
ステップ2: パイプラインの構築
[可視化モデリング (デザイナー)] ページで、[プリセットテンプレート] タブをクリックします。
テンプレートリストページの [推奨ソリューション-機能エンジニアリング] セクションで、[作成] をクリックします。
[パイプラインの作成] ダイアログボックスで、パラメーターを設定します。 デフォルト値を使用できます。
Pipeline Data Pathパラメーターに指定された値は、パイプラインのランタイム中に生成された一時データとモデルを格納するために使用されるObject Storage Service (OSS) バケットパスです。
[OK] をクリックします。
パイプラインの作成には約10秒かかります。
パイプラインリストで、[推奨ソリューション-機能エンジニアリング] をダブルクリックしてパイプラインに入ります。
次の図に示すように、キャンバス上のパイプラインのコンポーネントを表示します。 システムは、プリセットテンプレートに基づいてパイプラインを自動的に作成します。
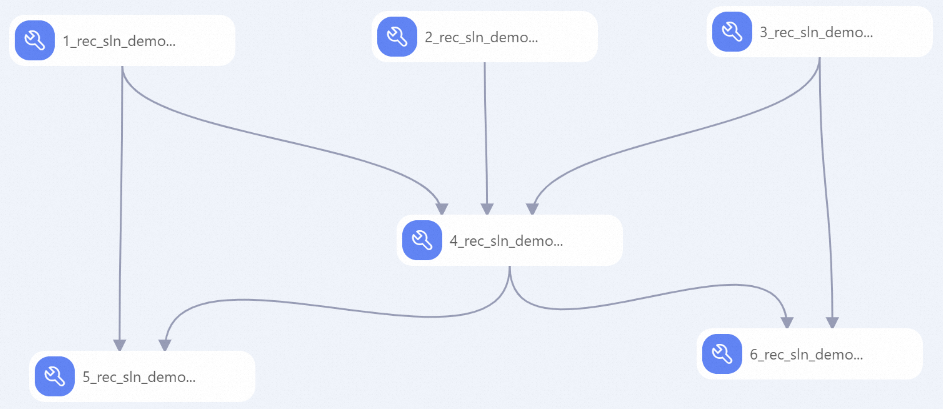
コンポーネント
説明
1
アイテムテーブルを前処理します。
次の特徴生成 (FG) のために、タグ特徴デリミタを
chr(29)に置き換える。アイテムが新しいかどうかを示すフィーチャーを生成します。
2
動作テーブルの前処理: day_hやweek_dayなど、動作時間の派生特徴を出力します。
3
ユーザーテーブルを前処理します。
ユーザーが新しいかどうかを示す機能を生成します。
次の特徴生成 (FG) のために、タグ特徴デリミタを
chr(29)に置き換える。
4
行動テーブル、ユーザーテーブル、およびアイテムテーブルを関連付けて、統計的プロパティを持つ幅広い行動ログテーブルを生成します。
5
期間中のアイテムの統計的特徴を含むアイテム特徴テーブルを生成します。
item __{ event}_cnt_{N}d:N日間にアイテムで発生した特定の行動の数。アイテムの人気を示します。item __{ event }_{ itemid}_dcnt_{N}d:N日以内にアイテムに対して特定の行動を行ったユニークユーザーの数。アイテムの人気を示します。item __{ min | max | avg | sum }_{ field }_{ N}d:N日以内にアイテムに対してポジティブな行動を実行するユーザーの特定の数値プロパティの統計的分布。これは、アイテムを好むユーザーの数値プロパティを示します。item__kv_{cate }_{ event }_{ N}d:N日以内にアイテムに対して特定の行動を実行するユーザーの特定のカテゴリプロパティの統計。これは、アイテムを好むユーザーのカテゴリプロパティを示します。
6
期間中のユーザーの統計的特徴を含むユーザー特徴テーブルを生成します。
ステップ3: 関数の追加
ワークフローの作成 詳細については、「ワークフローの作成」をご参照ください。
作成するワークフローの下にある [MaxCompute] を右クリックし、 を選択して、count_cates_kvs.pyという名前のPythonスクリプトを作成します。 詳細は、「MaxComputeリソースの作成と使用」をご参照ください。
作成するワークフローの下にある [MaxCompute] を右クリックし、[関数の作成] を選択して、COUNT_CATES_KVSという名前のMaxCompute関数を作成します。 クラス名を
count_cates_kvsに設定します。 CountCatesKVS、および [リソース] をcount_cates_kvs.pyに設定します。 詳細については、「MaxCompute関数の作成と使用」をご参照ください。
ステップ4: ワークフローを実行して結果を表示
この例で使用されるデータセットは、45日のデータを使用し、実行に時間がかかります。 ワークフローをより短い期間実行するには、次の操作を実行します。
実行時間ウィンドウのパラメーターを変更して、より短い時間のデータを使用します。
次のコンポーネントをクリックし、[パラメーター設定] タブの [実行時間ウィンドウ] パラメーターを
(-45,0)から(-9,0)に変更します。1_rec_sln_demo_item_table_preprocess_v22_rec_sln_demo_behavior_table_preprocess_ v23_rec_sln_demo_user_table_preprocess_v24_rec_sln_demo_behavior_table_preprocess_wide_v2
次のコンポーネントをクリックし、[パラメーター設定] タブの [実行時間ウィンドウ] パラメーターを
(-31,0)から(-8,0)に変更します。5_rec_sln_demo_item_table_preprocess_all_feature_v26_rec_sln_demo_user_table_preprocess_all_feature_v2
より小さなサンプルサイズのユーザーを使用するようにSQLスクリプトを変更します。
コンポーネント
2_rec_sln_demo_behavior_table_preprocess_ v2をクリックします。 [パラメーターの設定] タブで、SQL Scriptパラメーターの32行目をWHERE ds = '${pai.system.cycledate}'からWHERE ds = '${pai.system.cycledate}' およびuser_id % 10=1に変更します。コンポーネント
3_rec_sln_demo_user_table_preprocess_v2をクリックします。 [パラメーターの設定] タブで、SQL Scriptパラメーターの38行目をWHERE ds = '${pai.system.cycledate}'からWHERE ds = '${pai.system.cycledate}' およびuser_id % 10=1に変更します。
パイプラインキャンバスの上部ツールバーの [実行] ボタン
 をクリックします。
をクリックします。 パイプラインの実行後、次のMaxComputeテーブルに30日間のデータがあるかどうかを確認します。
アイテム機能テーブル:
rec_sln_demo_item_table_preprocess_all_feature_v2行動ログ全体のテーブル:
rec_sln_demo_behavior_table_preprocess_v2ユーザー機能テーブル:
rec_sln_demo_user_table_preprocess_all_feature_v2
SQL文を使用して、上記のテーブルのデータをクエリできます。 詳細は、「DataWorks」をご参照ください。
説明テーブルが属するプロジェクトのパーティションテーブルでは、テーブル全体のスキャンが無効になっています。 スキャンするパーティションを指定する必要があります。 SQL文を使用してテーブル全体をスキャンする場合は、
set odps.sql.allow.fullscan=trueをSQL文に追加し、SQL文と一緒にコマンドをコミットできます。 フルテーブルスキャンは、データ入力とコストを増加させます。