この Topic では、Deep Learning Containers (DLC) の計算リソースでハイパーパラメーターチューニングの AutoML 実験を送信する方法について説明します。このソリューションでは、PyTorch フレームワークを使用して、torchvision.datasets.MNIST モジュール経由で MNIST 手書きデータセットを自動的にダウンロードして読み込みます。その後、データセットでモデルをトレーニングし、最適なハイパーパラメーター構成を見つけます。さまざまなトレーニングニーズに対応するために、シングルノード、分散、ネストされたパラメーターの 3 つのトレーニングモードを提供します。
前提条件
AutoML 機能を初めて使用する前に、AutoML に必要な権限を付与する必要があります。詳細については、「クラウドプロダクトの依存関係と権限付与: AutoML」をご参照ください。
DLC に必要な権限を付与済みであること。詳細については、「クラウドプロダクトの依存関係と権限付与: DLC」をご参照ください。
ワークスペースを作成し、一般的なコンピューティングリソース用のパブリックリソースグループに関連付けていること。詳細については、「ワークスペースの作成と管理」をご参照ください。
OSS を有効化し、OSS バケットを作成済みであること。詳細については、「コンソールでのクイックスタート」をご参照ください。
ステップ 1: データセットの作成
ご利用の OSS バケットに mnist.py スクリプトファイルをアップロードします。詳細については、「コンソールでのクイックスタート」をご参照ください。
ハイパーパラメーターチューニング実験によって生成されたデータファイルを格納するために、OSS データセットを作成します。詳細については、「データセットの作成と管理」をご参照ください。
主要なパラメーターを以下に示します。その他のパラメーターはデフォルト構成を使用してください。
Dataset Name:カスタムのデータセット名を入力します。
Select Data Storage:スクリプトファイルを含む OSS フォルダを選択します。
Property:フォルダを選択します。
ステップ 2: 実験の作成
新しい実験 ページに移動し、主要なパラメーターを次のように設定します。 その他のパラメーター設定の詳細については、「実験を作成する」をご参照ください。 パラメーターを設定した後、Submit をクリックします。
実行設定の構成
このソリューションでは、シングルノードトレーニング、分散トレーニング、ネストされたパラメーターのトレーニングの 3 つのトレーニングモードを提供します。いずれかのトレーニングモードを選択してください。
シングルノードトレーニングのパラメーター設定
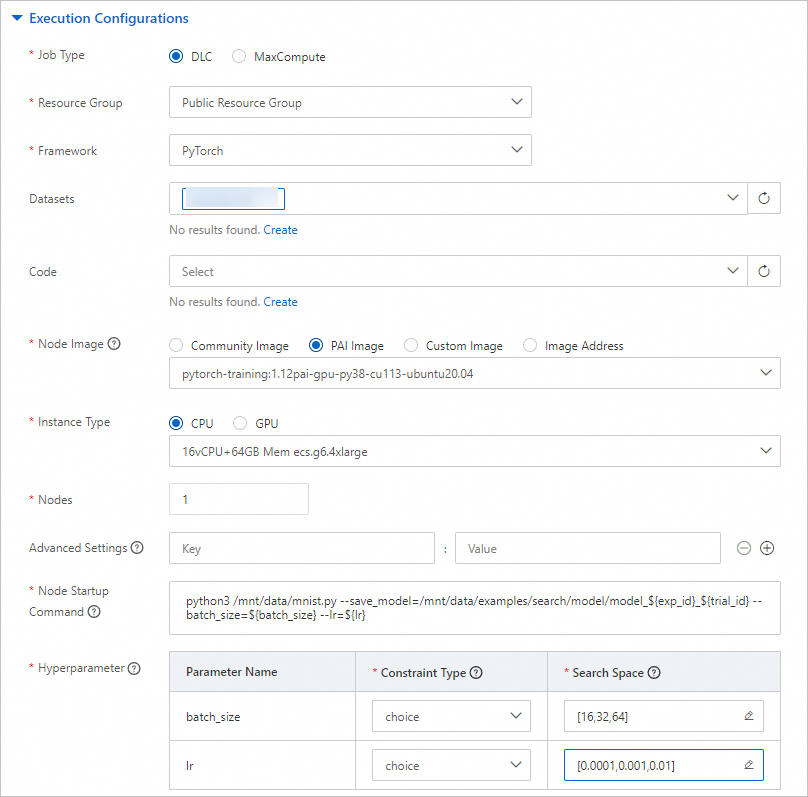
パラメーター
説明
Job Type
DLC を選択します。
Resource Group
Public Resource Groupを選択します。
Framework
PyTorch を選択します。
Datasets
ステップ 1 で作成したデータセットを選択します。
Node Image
PAI Image >
pytorch-training:1.12PAI-gpu-py38-cu113-ubuntu20.04を選択します。Instance Type
CPU >
ecs.g6.4xlargeを選択します。Nodes
1 に設定します。
Startup Command
python3 /mnt/data/mnist.py --save_model=/mnt/data/examples/search/model/model_${exp_id}_${trial_id} --batch_size=${batch_size} --lr=${lr}に設定します。ハイパーパラメーター
batch_size
制約タイプ:選択肢を選択します。
検索空間:
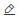 をクリックし、16、32、64 の 3 つの列挙値を追加します。
をクリックし、16、32、64 の 3 つの列挙値を追加します。
lr
制約タイプ:選択肢を選択します。
検索空間:
をクリックし、0.0001、0.001、0.01 の 3 つの列挙値を追加します。
これらの設定により、9 つのハイパーパラメーターの組み合わせが生成されます。実験では、組み合わせごとにトライアルを作成し、その組み合わせでスクリプトを実行します。
分散トレーニングのパラメーター設定
パラメーター
説明
Job Type
DLC を選択します。
Resource Group
Public Resource Group を選択します。
Framework
PyTorch を選択します。
Datasets
ステップ 1 で作成したデータセットを選択します。
Node Image
PAI Image >
pytorch-training:1.12PAI-gpu-py38-cu113-ubuntu20.04を選択します。Instance Type
CPU >
ecs.g6.4xlargeを選択します。Nodes
3 に設定します。
Startup Command
python -m torch.distributed.launch --master_addr=$MASTER_ADDR --master_port=$MASTER_PORT --nproc_per_node=1 --nnodes=$WORLD_SIZE --node_rank=$RANK /mnt/data/mnist.py --data_dir=/mnt/data/examples/search/data --save_model=/mnt/data/examples/search/pai/model/model_${exp_id}_${trial_id} --batch_size=${batch_size} --lr=${lr}に設定します。ハイパーパラメーター
batch_size
制約タイプ:選択肢を選択します。
検索空間:
をクリックし、16、32、64 の 3 つの列挙値を追加します。
lr
制約タイプ:選択肢を選択します。
検索空間:
をクリックし、0.0001、0.001、0.01 の 3 つの列挙値を追加します。
これらの設定により、9 つのハイパーパラメーターの組み合わせが生成されます。実験では、組み合わせごとにトライアルを作成し、その組み合わせでスクリプトを実行します。
ネストされたパラメーターのトレーニング設定
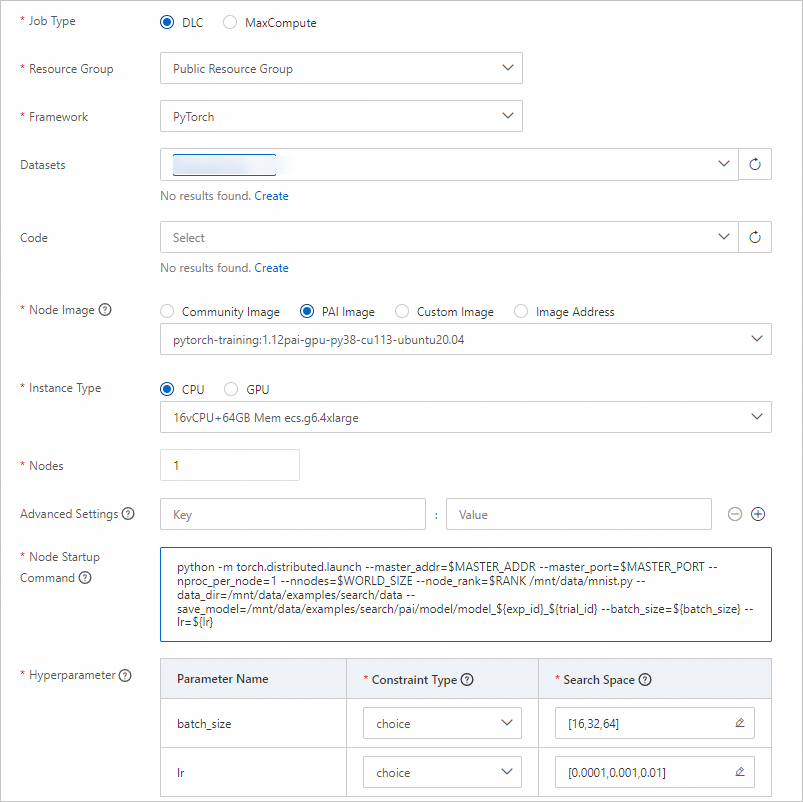
パラメーター
説明
Job Type
DLC を選択します。
Resource Group
Public Resource Group を選択します。
Framework
PyTorch を選択します。
Datasets
ステップ 1 で作成したデータセットを選択します。
Node Image
PAI Image >
pytorch-training:1.12PAI-gpu-py38-cu113-ubuntu20.04を選択します。Instance Type
CPU >
ecs.g6.4xlargeを選択します。Nodes
1 に設定します。
Startup Command
python3 /mnt/data/mnist.py --save_model=/mnt/data/examples/search/pai/model/model_${exp_id}_${trial_id} --batch_size=${nested_params}.{batch_size} --lr=${nested_params}.{lr} --gamma=${gamma}に設定します。ハイパーパラメーター
nested_params
制約タイプ:選択肢を選択します。
検索空間:
をクリックし、{"_name":"large","{lr}":{"_type":"choice","_value":[0.02,0.2]},"{batch_size}":{"_type":"choice","_value":[256,128]}}と{"_name":"small","{lr}":{"_type":"choice","_value":[0.01,0.1]},"{batch_size}":{"_type":"choice","_value":[64,32]}}の 2 つの列挙値を追加します。
gamma
制約タイプ:選択肢を選択します。
検索空間:
をクリックし、0.8、0.7、0.9 の 3 つの列挙値を追加します。
これらの設定により、9 つのハイパーパラメーターの組み合わせが生成されます。実験では、組み合わせごとにトライアルを作成し、その組み合わせでスクリプトを実行します。
トライアル設定の構成
パラメーター
説明
最適化メトリック
メトリックタイプ
stdout を選択します。これは、実行中に最終メトリックが stdout からフェッチされることを示します。
計算方法
best を選択します。
メトリックの重み
以下のパラメーターを設定します:
キー:validation: accuracy=([0-9\\.]+).
値:1.
メトリックソース
コマンドキーワードを cmd1 に設定します。
最適化の方向
[大きいほど良い] を選択します。
モデルストレージパス
モデルが保存される OSS パスに設定します。この例では、パスは
oss://examplebucket/examples/model/model_${exp_id}_${trial_id}です。検索設定の構成
パラメーター
説明
検索アルゴリズム
TPE を選択します。アルゴリズムの詳細については、「サポートされている検索アルゴリズム」をご参照ください。
最大検索数
3 に設定します。これは、実験が最大 3 つのトライアルを実行できることを示します。
最大同時実行数
2 に設定します。これは、実験が最大 2 つのトライアルを並行して実行できることを示します。
早期停止の有効化
このスイッチをオンにします。特定のハイパーパラメーターの組み合わせを評価する際にトライアルのパフォーマンスが低い場合、そのトライアルの評価プロセスは早期に停止されます。
開始ステップ
5 に設定します。これは、トライアルが少なくとも 5 回の評価を完了した後に早期停止できることを示します。
ステップ 3: 実験の詳細と結果の表示
実験リストで、実験の名前をクリックして 実験詳細 ページに移動します。
このページでは、トライアルの実行進捗とステータスを確認できます。実験は、設定された検索アルゴリズムと最大検索数に基づいて、自動的に 3 つのトライアルを作成します。
[トライアル] タブをクリックします。このページでは、実験用に自動生成されたすべてのトライアルのリストと、各トライアルの実行ステータス、最終メトリック、ハイパーパラメーターの組み合わせを確認できます。
参考資料
MaxCompute 計算リソースのハイパーパラメーターチューニング実験を送信することもできます。詳細については、「MaxCompute k-means クラスタリングのベストプラクティス」をご参照ください。
AutoML の使用方法とその仕組みの詳細については、「AutoML」をご参照ください。