このトピックでは、DLC 計算リソースを使用してハイパーパラメーター調整実験を送信し、最適なハイパーパラメーター構成を特定する方法で LoRA モデルをトレーニングする手順について説明します。
前提条件
ご利用のアカウントに AutoML を使用するために必要な権限が付与されています。この前提条件は、初めて AutoML を使用する場合に必須です。詳細については、「クラウドプロダクトの依存関係と権限付与:AutoML」をご参照ください。
ご利用のアカウントに DLC を使用するために必要な権限が付与されています。詳細については、「クラウドプロダクトの依存関係と権限付与:DLC」をご参照ください。
ワークスペースが作成され、汎用計算リソース用のパブリックリソースグループに関連付けられています。詳細については、「ワークスペースの作成と管理」をご参照ください。
Object Storage Service (OSS) が有効化され、OSS バケットが作成されています。詳細については、「OSS コンソール入門」をご参照ください。
ステップ 1:データセットの作成
OSS データセットを作成します。このデータセットは、ハイパーパラメーター調整実験によって生成されたデータファイルを格納するための OSS ストレージディレクトリを DLC のパスにマウントします。以下の主要なパラメーターを設定してください。その他のパラメーターはすべてデフォルト構成を使用します。詳細については、「データセットの作成と管理」をご参照ください。
Dataset Name:データセットの任意の名前を入力します。
Select Data Storage:スクリプトファイルを含む OSS ストレージディレクトリを選択します。
Property:[フォルダー] を選択します。
ステップ 2:実験の作成
New Experimentページに移動し、以下のように主要なパラメーターを構成します。その他のパラメーター設定の詳細については、「新規実験」をご参照ください。構成が完了したら、Submit をクリックします。
実行設定を構成します。
パラメーター
説明
Job type
DLC を選択します。
Resource Group
Public Resource Group を選択します。
Framework
Tensorflow を選択します。
Datasets
ステップ 1 で作成したデータセットを選択します。
Node Image
Image Address を選択し、テキストボックスに
registry.cn-shanghai.aliyuncs.com/mybigpai/nni:diffusersを入力します。ランタイムイメージには以下のデータが事前設定されています。
事前学習済み基盤モデル:Stable-Diffusion-V1-5 モデルがイメージパス
/workspace/diffusers_model_data/modelに事前設定されています。LoRa トレーニングデータ:ポケモンデータがイメージパス
/workspace/diffusers_model_data/dataに事前設定されています。トレーニングコード:diffusers コードがイメージパス
/workspace/diffusersに事前設定されています。
Instace Type
GPU >
12vCPU+92GB Mem+1*NVIDIA V100 ecs.gn6e-c12g1.3xlargeを選択します。Nodes
1 に設定します。
Startup Command
cd /workspace/diffusers/examples/text_to_image && accelerate launch --mixed_precision="fp16" train_text_to_image_lora_eval.py \ --pretrained_model_name_or_path="/workspace/diffusers_model_data/model" \ --dataset_name="/workspace/diffusers_model_data/data" \ --caption_column="text" \ --resolution=512 --random_flip \ --train_batch_size=8 \ --val_batch_size=8 \ --num_train_epochs=100 --checkpointing_steps=100 \ --learning_rate=${lr} --lr_scheduler=${lr_scheduler} --lr_warmup_steps=0 \ --rank=${rank} --adam_beta1=${adam_beta1} --adam_beta2=${adam_beta2} --adam_weight_decay=${adam_weight_decay} \ --max_grad_norm=${max_grad_norm} \ --seed=42 \ --output_dir="/mnt/data/diffusers/pokemon/sd-pokemon_${exp_id}_${trial_id}" \ --validation_prompts "a cartoon pikachu pokemon with big eyes and big ears" \ --validation_metrics ImageRewardPatched \ --save_by_metric val_lossハイパーパラメーター
各ハイパーパラメーターの制約タイプと探索空間は、以下のように構成されます。
lr:
制約タイプ:選択肢。
探索空間:
 をクリックし、列挙値として 1e-4、1e-5、および 2e-5 の 3 つを追加します。
をクリックし、列挙値として 1e-4、1e-5、および 2e-5 の 3 つを追加します。
lr_scheduler:
制約タイプ:選択肢。
探索空間:
 をクリックし、列挙値として constant、cosine、および polynomial の 3 つを追加します。
をクリックし、列挙値として constant、cosine、および polynomial の 3 つを追加します。
rank:
制約タイプ:選択肢。
探索空間:
 をクリックし、列挙値として 4、32、および 64 の 3 つを追加します。
をクリックし、列挙値として 4、32、および 64 の 3 つを追加します。
adam_beta1:
制約タイプ:選択肢。
探索空間:
 をクリックし、列挙値として 0.9 および 0.95 の 2 つを追加します。
をクリックし、列挙値として 0.9 および 0.95 の 2 つを追加します。
adam_beta2:
制約タイプ:選択肢。
探索空間:
 をクリックし、列挙値として 0.99 および 0.999 の 2 つを追加します。
をクリックし、列挙値として 0.99 および 0.999 の 2 つを追加します。
adam_weight_decay:
制約タイプ:選択肢。
探索空間:
 をクリックし、列挙値として 1e-2 および 1e-3 の 2 つを追加します。
をクリックし、列挙値として 1e-2 および 1e-3 の 2 つを追加します。
max_grad_norm:
制約タイプ:選択肢。
探索空間:
 をクリックし、列挙値として 1、5、および 10 の 3 つを追加します。
をクリックし、列挙値として 1、5、および 10 の 3 つを追加します。
これらの構成により、648 通りのハイパーパラメーター組み合わせが生成されます。実験では、各組み合わせごとに 1 つのトライアルが作成されます。各トライアルは、1 つのハイパーパラメーター組み合わせを使用してスクリプトを実行します。
トライアル設定を構成します。
パラメーター
説明
メトリックタイプ
stdout を選択します。
計算方法
best を選択します。
メトリックの重み
キー:val_loss=([0-9\\.]+)。
値:1。
メトリックソース
cmd1 に設定します。
最適化方向
大きいほど良い を選択します。
探索設定を構成します。
パラメーター
説明
探索アルゴリズム
TPE を選択します。
最大探索回数
5 に設定します。
最大並列度
2 に設定します。
earlystop を有効化
スイッチをオンにします。
開始ステップ
5
ステップ 3:実装の詳細と実行結果の確認
実験リストページで、実験名をクリックして実験の詳細ページに移動します。
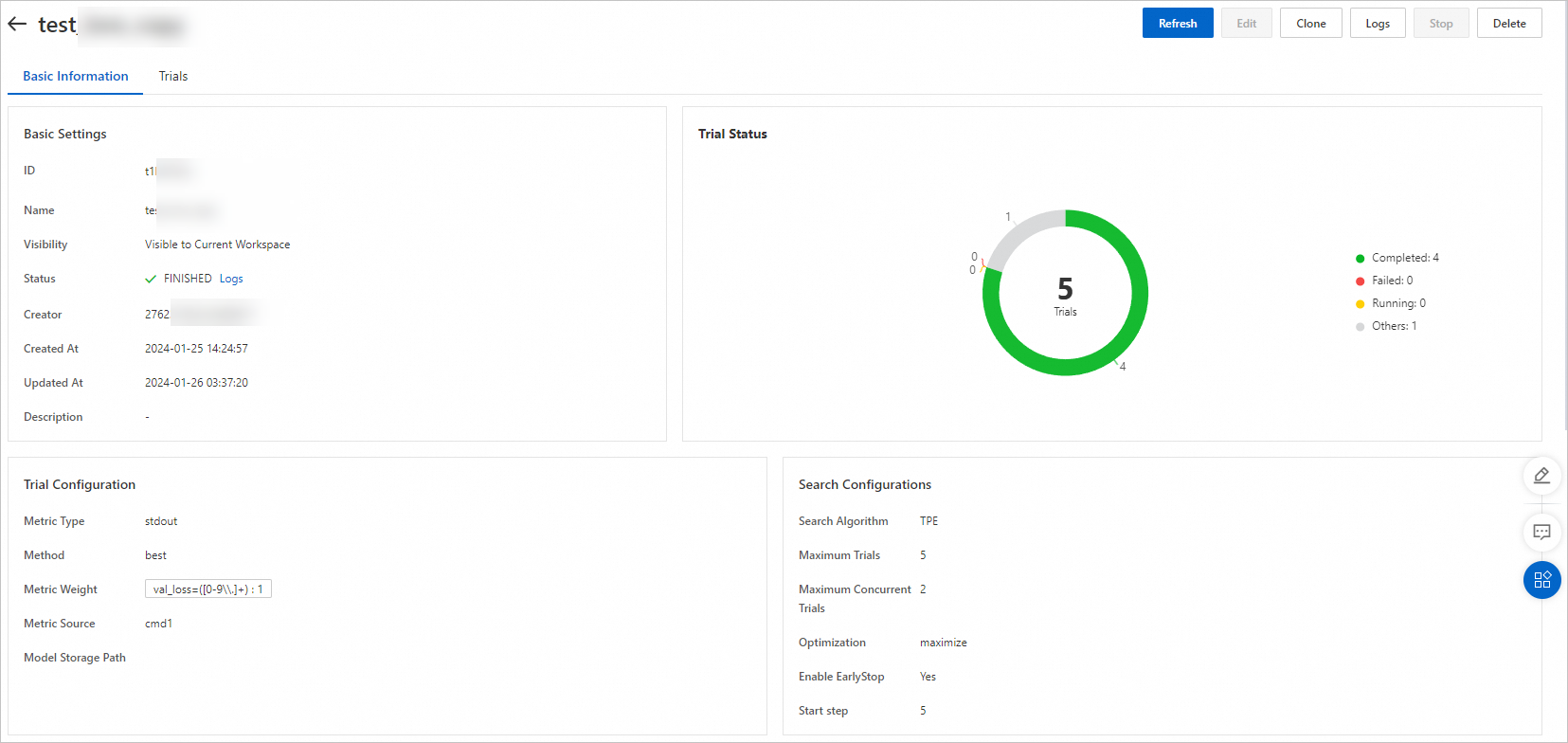
このページでは、トライアルの実行進捗とステータス統計を確認できます。実験では、構成された探索アルゴリズムと最大探索回数に基づき、自動的に 5 つのトライアルが作成されます。
[トライアルリスト] タブをクリックします。このページでは、実験のために自動生成されたすべてのトライアルと、それらの実行ステータス、最終メトリック、ハイパーパラメーター組み合わせを確認できます。
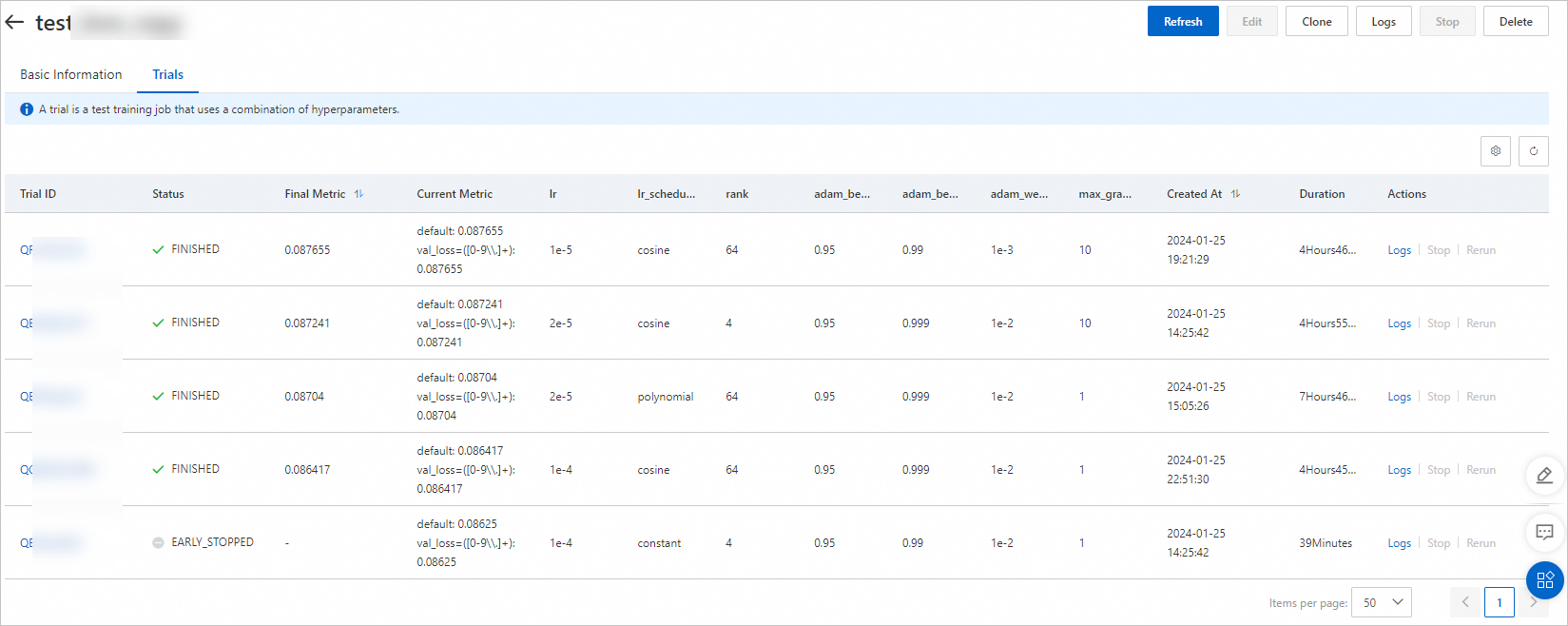
各トライアルの実行時間は約 5 時間です。構成された最適化方向(大きいほど良い)に基づき、最終メトリックが 0.087655 となるハイパーパラメーター組み合わせが最適です。
ステップ 4:モデルサービスのデプロイメントと推論の実行
LoRA モデルをダウンロードし、モデルファイル形式を変換します。
実験が正常に完了すると、起動コマンドで指定された
output_dirディレクトリにモデルファイルが生成されます。この実験のデータセットがマウントされている OSS パス内のcheckpoint-bestディレクトリに移動し、モデルファイルを表示・ダウンロードします。詳細については、「コンソール入門」をご参照ください。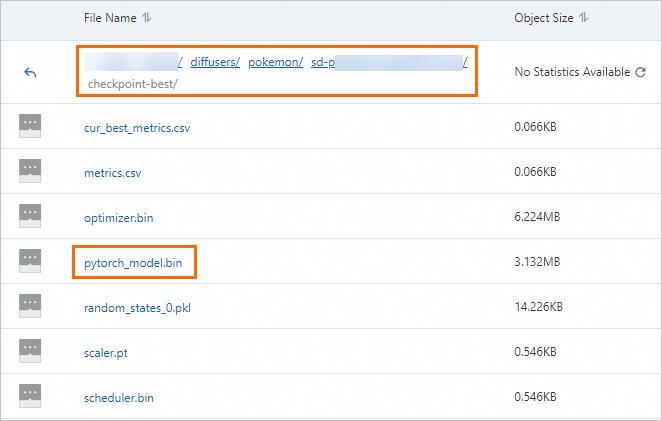
次のコマンドを実行して、pytorch_model.bin を pytorch_model_converted.safetensors に変換します。
wget http://automl-nni.oss-cn-beijing.aliyuncs.com/aigc/convert.py python convert.py --file pytorch_model.bin
Stable Diffusion WebUI サービスをデプロイします。
Elastic Algorithm Service (EAS) ページに移動します。詳細については、「カスタムデプロイメント」をご参照ください。
Elastic Algorithm Service (EAS) ページで、Deploy Service をクリックします。Custom Model Deploymentエリアで、Custom Deployment をクリックします。
Create Serviceページで、以下の主要なパラメーターを構成し、Deploy をクリックします。
パラメーター
説明
Service Name
任意のサービス名を入力します。本例では、サービス名は sdwebui_demo です。
Deployment Method
Deploy Web App by Using Image を選択します。
Select Image
PAI Imageリストで stable-diffusion-webui を選択します。イメージバージョンには 4.2-standard を選択します。
説明バージョンは頻繁に更新されるため、デプロイメント時には最新のイメージバージョンを選択してください。
Model Settings
Specify Model Settings をクリックしてモデルを構成します。
Model Settingsでは、OSS を選択します。OSS パスを、ステップ 1 で作成した OSS バケットのパスに設定します。例:
oss://bucket-test/data-oss/。Mount Path:構成した OSS ファイルディレクトリを、イメージ内の
/code/stable-diffusion-webuiパスにマウントします。例:/code/stable-diffusion-webui/data-ossにパスを設定します。Enable Read-Only:スイッチをオフにします。
Command to Run
イメージの構成後、システムが自動的に実行コマンドを構成します。Model Settingsセクションの Mount Path の最後の階層ディレクトリと同じになるように、実行コマンドの末尾に
--data-dir <mount_directory>を追加する必要があります。本例では、実行コマンドの末尾に--data-dir data-ossを追加します。Resource Configuration Mode
General を選択します。
Resource Configuration
GPU タイプを選択します。コストパフォーマンスを最適化するには、Instance Typeを ml.gu7i.c16m60.1-gu30 に設定します。
Extra System Storage
追加システムディスクを 100 GB に設定します。
[デプロイ] をクリックします。
PAI は、構成した空の OSS ファイルディレクトリ内に以下のディレクトリ構造を自動的に作成し、必要なデータをディレクトリにコピーします。
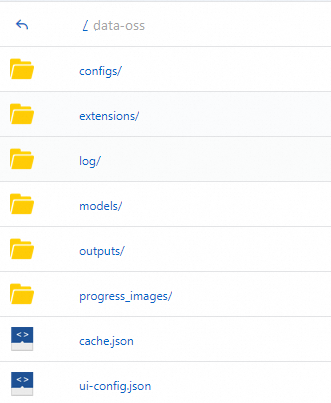
モデルファイルを指定パスにアップロードします。その後、対象サービスの Actions 列で
 Restart Service をクリックします。サービスが再起動すると、変更が反映されます。
Restart Service をクリックします。サービスが再起動すると、変更が反映されます。前のステップで生成された pytorch_model_converted.safetensors モデルファイルを、OSS 内の
models/lora/ディレクトリにアップロードします。revAnimated_v122 基盤モデルを、OSS 内の
models/Stable-diffusion/ディレクトリにアップロードします。
対象サービスの Service Type 列で、View Web App をクリックして、WebUI ページでモデル推論と検証を実行します。