インスタンスの購入
詳細については、OpenSearch ベクトル検索版インスタンスの購入を参照してください。
インスタンスの設定
購入済みインスタンスの詳細ページで、インスタンスが設定保留中状態であることを確認できます。システムは、購入するクエリ結果検索(QRS)ワーカーと検索ワーカーの数と仕様に基づいて、空のインスタンスを自動的にデプロイします。インスタンスを検索に使用する前に、次の手順を実行します。テーブルの設定、データソースの追加、フィールドの設定、インデックススキーマの設定、そしてインスタンスの再インデックスを実行します。
1. テーブルの基本情報の構成
インスタンス詳細ページの左側のペインで、[テーブル管理] をクリックします。[テーブル管理] ページで、テーブルの追加をクリックします。作成ウィザードの [テーブルの基本情報] ステップで、テーブル名、データシャード、データ更新用リソース数、シナリオテンプレートパラメータを設定し、[次へ] をクリックします。
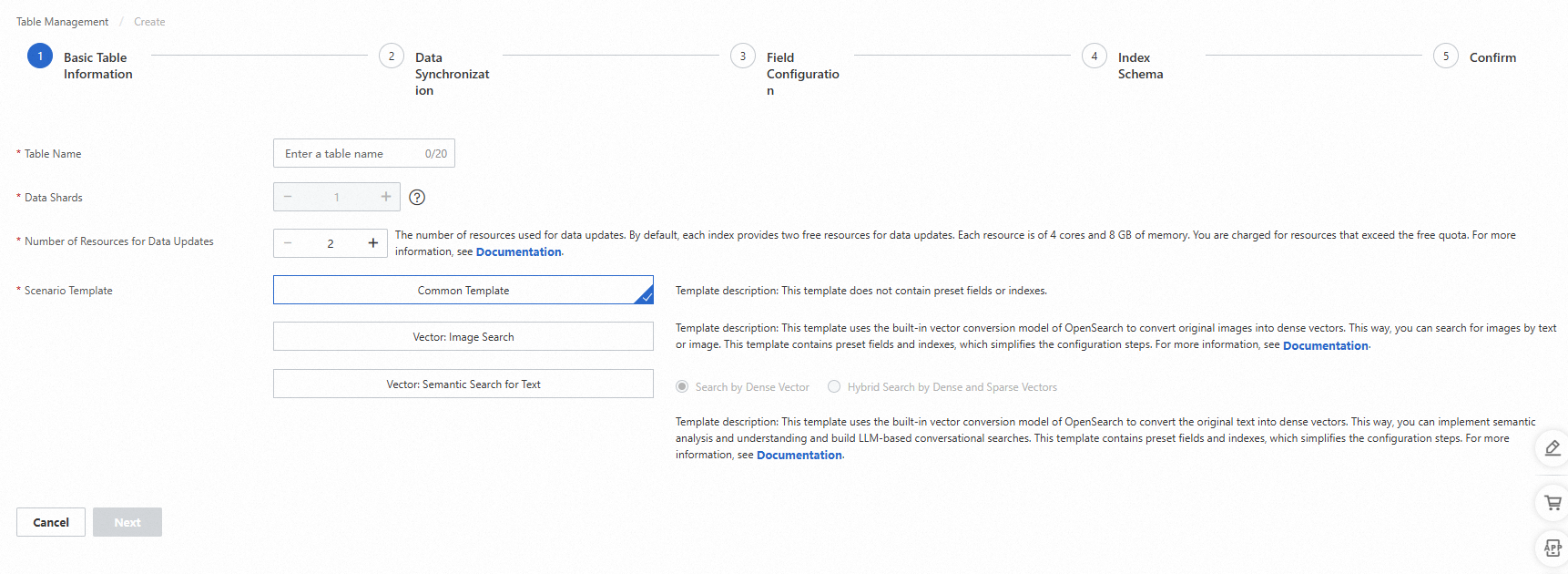
パラメータ:
テーブル名: テーブルの名前。テーブル名はカスタマイズできます。
データシャード: テーブル内のデータシャードの数。OpenSearch インスタンスに複数のインデックステーブルを作成する場合は、インデックステーブルに同じ数のシャードが含まれていることを確認してください。または、少なくとも1つのインデックステーブルに1つのシャードが含まれており、他のインデックステーブルに同じ数のシャードが含まれていることを確認してください。
データ更新用リソース数: データ更新に使用されるリソースの数。デフォルトでは、OpenSearch は、OpenSearch ベクトル検索版インスタンスの各データソースに対して、データ更新用に2つのリソースの無料枠を提供します。各リソースは、4 個の CPU コアと 8 GB のメモリで構成されています。無料枠を超えるリソースについては課金されます。詳細については、OpenSearch ベクトル検索版の課金概要を参照してください。
シナリオテンプレート: テーブルの作成に使用されるテンプレート。有効な値: 共通テンプレート、ベクトル: 画像検索、ベクトル: テキストのセマンティック検索。
2. データソースの追加
データ同期ステップで、データソースを追加します。MaxCompute データソースまたは API データソースを追加できます。この例では、MaxCompute + API が完全データソースとして選択されています。プロジェクト、アクセスキー、アクセスキーのシークレット、テーブル、パーティションキーのパラメータを設定し、自動再インデックスパラメータを [はい] または [いいえ] に設定して、確認をクリックします。データソース情報がチェックに合格したら、[次へ] をクリックします。
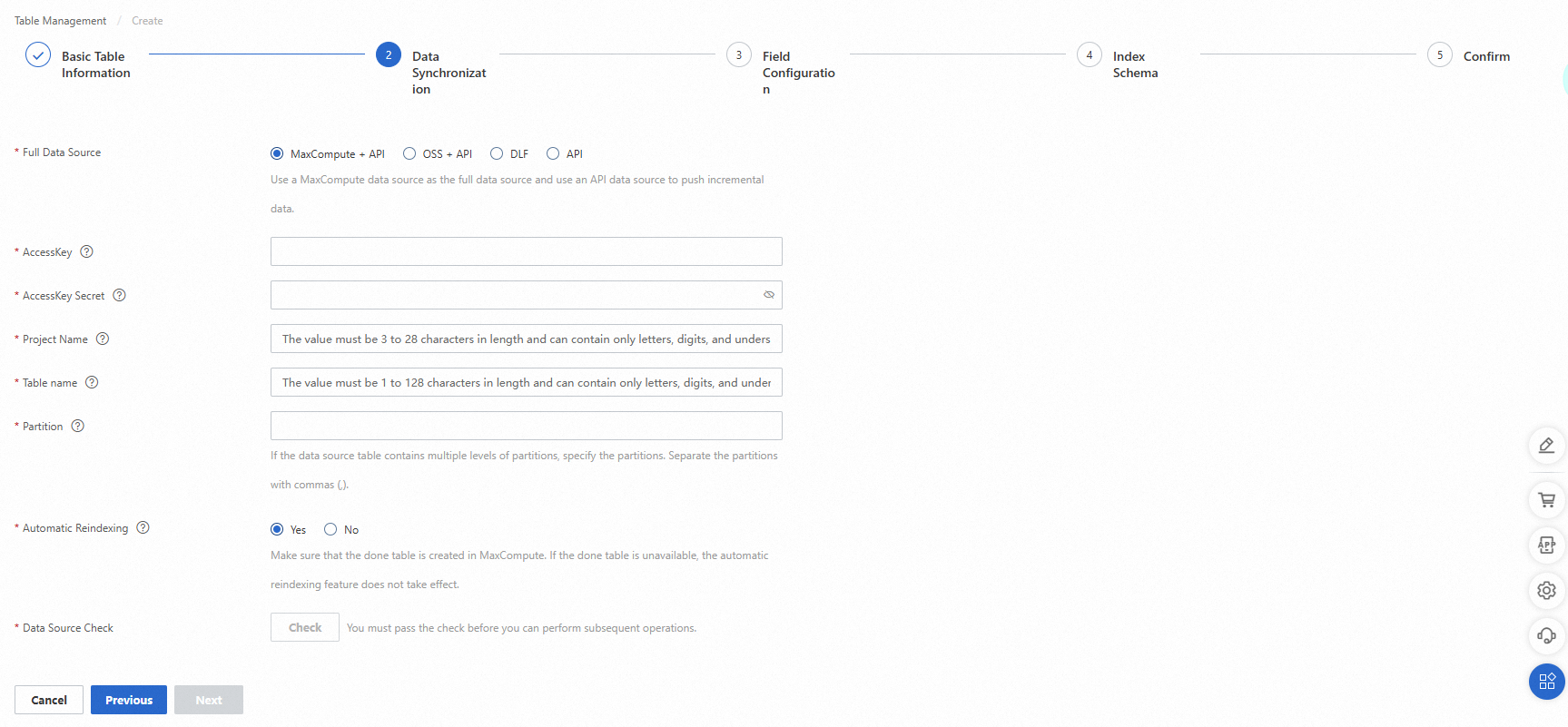
MaxCompute データソースの詳細については、MaxCompute データソースのテーブルの作成を参照してください。
API データソースの詳細については、API データソースのテーブルの作成を参照してください。
オブジェクトストレージサービス (OSS) データソースの詳細については、OSS データソースのテーブルの作成を参照してください。
3. フィールドの設定
OpenSearch は、選択したシナリオテンプレートに基づいて関連するプリセットフィールドを提供し、データソースからフィールドリストにすべてのフィールドを自動的にインポートします。
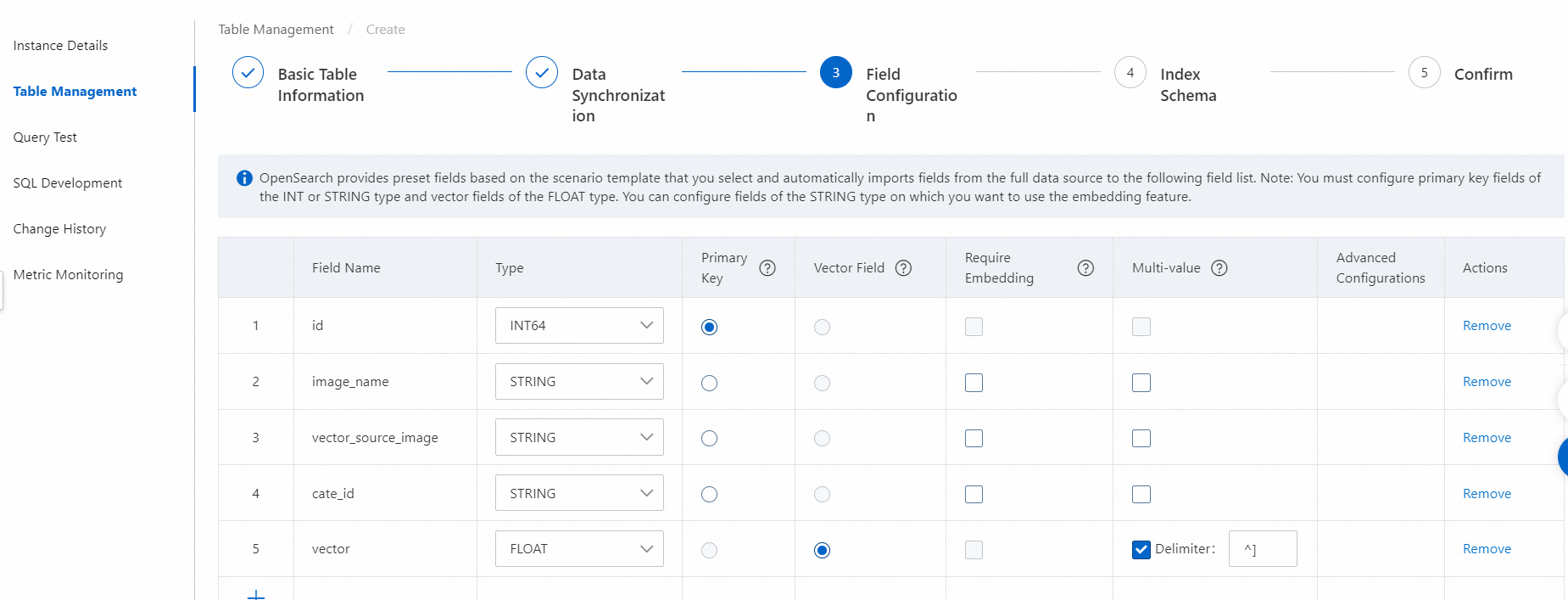
フィールド設定ステップで、フィールドを設定します。少なくとも2つのフィールドを設定する必要があります。主キーフィールドとベクトルフィールドです。ベクトルフィールドは、FLOAT 型の複数値フィールドとして定義する必要があります。
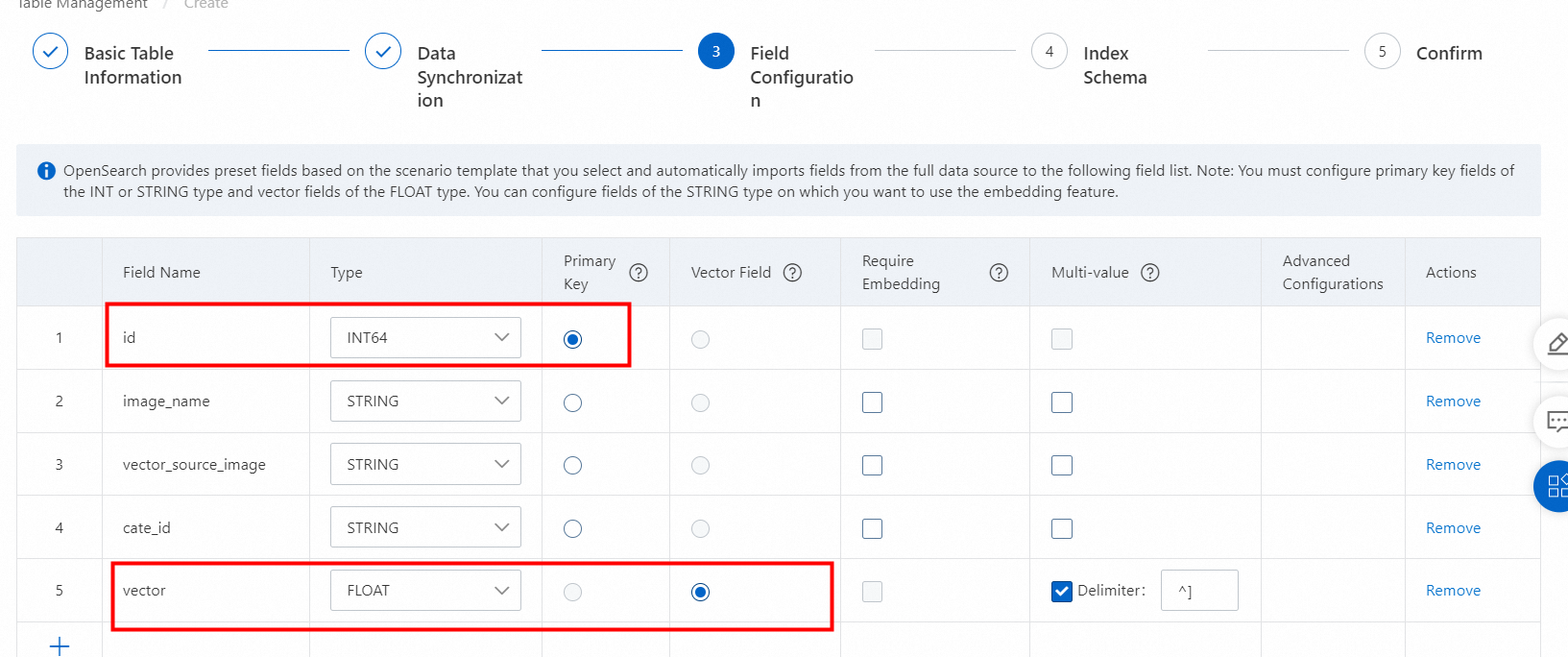
カテゴリに基づいてベクトルインデックスを作成する必要がある場合は、主キーフィールドとベクトルフィールドの間にカテゴリフィールドを追加できます。
注:
主キーフィールドとベクトルフィールドは必須です。主キーフィールドの場合は、[タイプ] パラメータを INT または STRING に設定し、[主キー] 列のオプションを選択する必要があります。ベクトルフィールドの場合は、[タイプ] パラメータを FLOAT に設定し、[ベクトルフィールド] 列のチェックボックスを選択する必要があります。
デフォルトでは、ベクトルフィールドは FLOAT 型の複数値フィールドであり、ベクトルフィールドの複数の値は HA3 デリミタ (^]) で区切られます。このデリミタは、UTF 形式で \x1D としてエンコードされます。カスタムの複数値デリミタを入力することもできます。
ベクトルインデックスを設定する場合は、主キーフィールド、名前空間フィールド、ベクトルフィールドの順にフィールドを指定する必要があります。名前空間フィールドはオプションです。前の図は例を示しています。
4. インデックススキーマの設定
ベクトルインデックス
OpenSearch は、主キーフィールドとベクトルフィールドのインデックスを自動的に作成します。インデックス名はフィールド名と同じです。OpenSearch コンソールでベクトルインデックスのみを設定する必要があります。
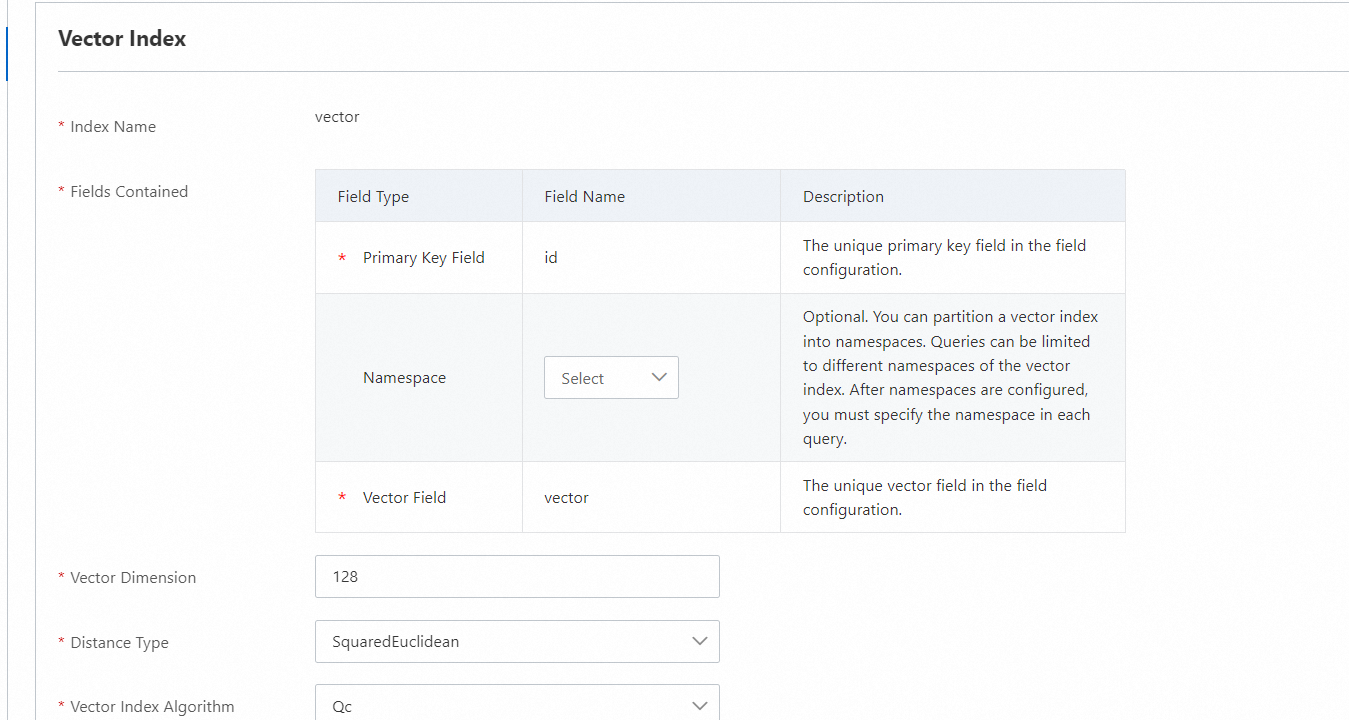
ベクトルインデックスの詳細設定のパラメータを個別に設定する必要があります。詳細については、ベクトルインデックスの共通設定を参照してください。
主キーフィールドとベクトルフィールドは必須です。名前空間フィールドはオプションで、空のままにすることができます。
[含まれるフィールド] パラメータには、3つの固定フィールドのみを設定でき、フィールドを追加することはできません。
システムはベクトルインデックスのパラメータを自動的に設定します。特別な要件がない場合は、次へをクリックして設定を完了します。
名前空間フィールド: インスタンスのエンジンバージョンが vector_service_1.0.2 以前の場合、名前空間フィールドを STRING 型にすることはできません。インスタンスのエンジンバージョンが vector_service_1.0.2 以降の場合、フィールドタイプに制限はありません。
5. 作成の確認
[確認] ステップで、[確認] をクリックします。

6. 変更履歴の表示
インスタンス詳細ページの左側のペインで、[変更履歴] をクリックします。表示されるページの [データソースの変更] タブで、テーブルの作成、インデックスの作成、完全データの再インデックスの実行のプロセスに関連するすべての有限状態マシン (FSM) を表示できます。検索エンジンが構築された後、インスタンスでクエリテストを実行できます。
7. クエリテストの実行
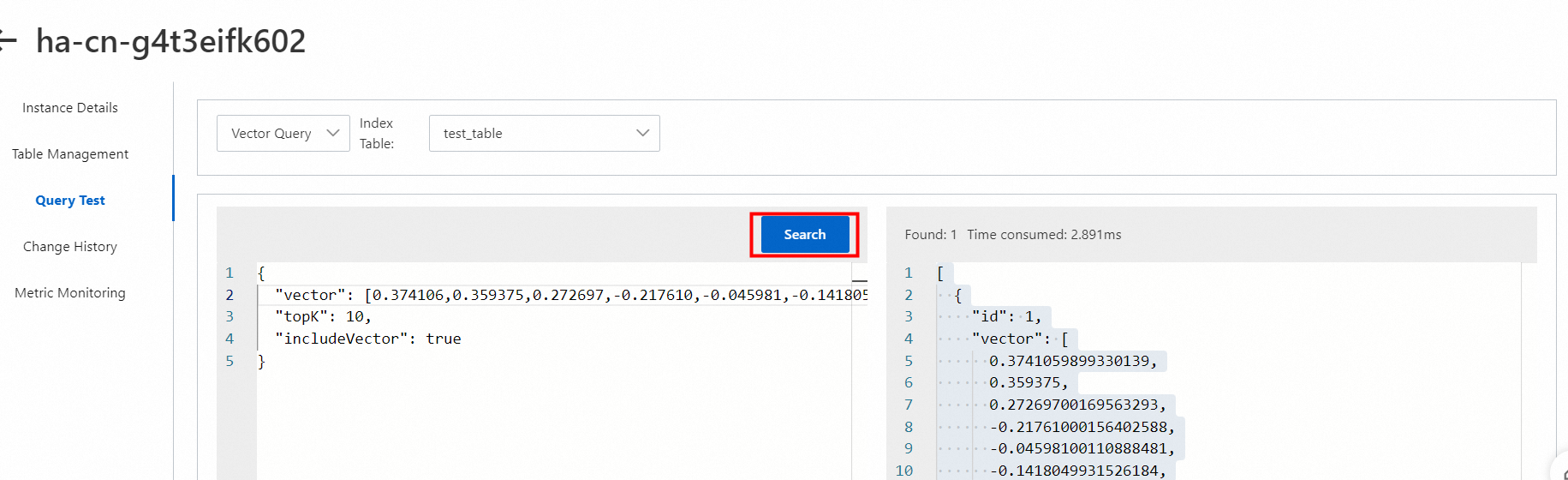
サンプルクエリ
{
"vector": [0.0019676427,0.005902928,0.021644069,0.21644068,0.12199384,0.043288138,0.007870571,0.0,0.08460863,0.041320495,0.043288138,0.035417568,0.011805856,0.055093993,0.12592913,0.017708784,0.021644069,0.0019676427,0.0,0.0,0.0019676427,0.078705706,0.1987319,0.041320495,0.039352853,0.0039352854,0.007870571,0.0039352854,0.0039352854,0.017708784,0.035417568,0.06886749,0.0019676427,0.0019676427,0.013773498,0.049191065,0.2125054,0.22824654,0.123961486,0.0039352854,0.0,0.0,0.021644069,0.14560555,0.078705706,0.1987319,0.22824654,0.005902928,0.064932205,0.0019676427,0.0019676427,0.021644069,0.027546996,0.035417568,0.22824654,0.22824654,0.1337997,0.023611711,0.009838213,0.007870571,0.0039352854,0.0039352854,0.017708784,0.20069954,0.033449925,0.005902928,0.019676426,0.035417568,0.015741142,0.029514639,0.13183205,0.123961486,0.029514639,0.0,0.027546996,0.22824654,0.15741141,0.0,0.0039352854,0.043288138,0.18889369,0.072802775,0.055093993,0.17315255,0.08460863,0.0019676427,0.007870571,0.035417568,0.22824654,0.10034977,0.009838213,0.021644069,0.062964566,0.027546996,0.015741142,0.04525578,0.086576276,0.033449925,0.023611711,0.017708784,0.0,0.0,0.03738521,0.072802775,0.16724962,0.035417568,0.031482283,0.20463483,0.043288138,0.011805856,0.0039352854,0.051158708,0.023611711,0.11412327,0.13183205,0.16134669,0.049191065,0.023611711,0.0039352854,0.0039352854,0.049191065,0.035417568,0.015741142,0.0039352854,0.03738521,0.08264099,0.094446845,0.021644069],
"topK": 10,
"includeVector": true
}vector: クエリ対象のベクトル。
topK: クエリ対象の上位 K 件のドキュメント。
includeVector: ドキュメントにベクトル情報を返すかどうかを指定します。
サンプル結果
クエリ構文の詳細については、このトピックの「構文」セクションを参照してください。
構文
ベクトルベースのクエリの構文: ベクトルベースのクエリ
主キーベースのクエリの構文: 主キーベースのクエリ
フィルタ式の構文: フィルタ式