Function Computeコンソール、SDK、またはServerless Devsを使用して、GPU高速化インスタンスのベストプラクティスを体験できます。 このトピックでは、Serverless Devsと関数コードを使用してビデオをトランスコードする方法について説明します。mp4から. flv。 このトピックでは、Pythonを例として使用します。
シナリオと利点
ソーシャルライブストリーミング、オンライン教室、遠隔医療などの高度にインタラクティブなアプリケーションシナリオの出現により、リアルタイムおよび準リアルタイムのインターネットトラフィックがトレンドになりつつあります。 ほとんどの場合、ビデオプラットフォームは、ソースビデオコンテンツをトランスコードして、ビットレート、解像度、チャネルパッチ、および再生プラットフォームなどの要因に基づいて1:N方式で複数の配信ビデオフォーマットを出力し、異なる再生プラットフォーム上の視聴者に異なるネットワーク品質を提供する必要があります。 ビデオのトランスコーディングは、ビデオの制作と配信の重要なステップです。 理想的なビデオコード変換ソリューションは、コスト (RMB /ストリーム) と電力効率 (ワット /ストリーム) の点で費用対効果が高い必要があります。
このセクションでは、Function ComputeにGPUアクセラレーションがないインスタンスと比較した、GPUアクセラレーションインスタンスの利点について説明します。
リアルタイムおよび準リアルタイムのアプリケーションシナリオ
GPU高速化されたインスタンスは、ビデオを数倍高速にトランスコードし、プロダクションコンテンツをより効率的にユーザーにプッシュできます。
コスト優先GPUアプリケーションシナリオ
GPU高速化インスタンスは、ビジネス要件に基づいて柔軟にプロビジョニングでき、自己購入の仮想マシン (VM) よりも費用対効果が高くなります。
効率優先GPUアプリケーションシナリオ
ドライバーとCUDAのバージョン管理、マシンの運用管理、欠陥のあるGPU管理など、GPUクラスターでO&Mを実行することなく、コード開発とビジネス目標に焦点を当てます。
GPU高速化インスタンスの詳細については、「インスタンスタイプとインスタンスモード」をご参照ください。
性能比較
Function ComputeのGPU高速化インスタンスは、Turingアーキテクチャに基づいており、次のエンコードおよびデコード形式をサポートしています。
エンコード形式
H.264 (AVCHD) YUV 4:2:0
H.264 (AVCHD) YUV 4:4:4
H.264 (AVCHD) ロスレス
H.265 (HEVC) 4K YUV 4:2:0
H.265 (HEVC) 4K YUV 4:4:4
H.265 (HEVC) 4Kロスレス
H.265 (HEVC) 8k
HEVC10-bitsupport
HEVCBフレームサポート
デコード形式
MPEG-1
MPEG-2
VC-1
VP8
VP9
H.264 (AVCHD)
H.265 (HEVC) 4:2:0
* H.265 (HEVC) 4:4:4
8ビット
10ビット
12ビット
8ビット
10ビット
12ビット
8ビット
10ビット
12ビット
次の表に、ソースビデオに関する情報を示します。
項目 | 値 |
有効期間 | 2分5秒 |
ビットレート | 4085 Kb/s |
ビデオストリーム情報 | h264 (高) 、yuv420p (プログレッシブ) 、1920x1080 [SAR 1:1 DAR 16:9] 、25 fps、25 tbr、1k tbn、50 tbc |
オーディオおよびビデオ情報 | aac (LC) 、44100Hz、ステレオ、fltp |
次の表に、GPUアクセラレーションを使用するテストマシンとGPUアクセラレーションを使用しないマシンに関する情報を示します。
項目 | マシン、GPUアクセラレーションなし | マシンとGPUアクセラレーション |
CPU | CPU Xeon®プラチナ8163 4C | CPU Xeon®プラチナ8163 4C |
RAM | 16 GB | 16 GB |
GPU | 非該当 | T4 |
FFmpeg | git-2020-08-12-1201687 | git-2020-08-12-1201687 |
ビデオトランスコード (1:1)
パフォーマンステスト: 1入力steramと1出力ストリーム
解像度 | GPUアクセラレーションなしのトランスコード期間 | GPUアクセラレーションによるトランスコード期間 |
H264 ∶ 1920x1080 (1080p) (フルHD) | 3分19.331秒 | 9.399秒 |
H264 ∶ 1280x720 (720p) (ハーフHD) | 2分3.708秒 | 5.791秒 |
H264 ∶ 640x480 (480p) | 1分1.018秒 | 5.753秒 |
H264 ∶ 480x360 (360p) | 44.376秒 | 5.749秒 |
ビデオトランスコーディング (1: N)
パフォーマンステスト: 1つの入力ストリームと3つの出力ストリーム
解像度 | GPUアクセラレーションなしのトランスコード期間 | GPUアクセラレーションによるトランスコード期間 |
H264 ∶ 1920x1080 (1080p) (フルHD) | 5分58.696秒 | 45.268秒 |
H264 ∶ 1280x720 (720p) (ハーフHD) | ||
H264 ∶ 640x480 (480p) |
コード変換コマンド
GPU高速化なしのトランスコードのコマンド
シングルストリームのトランスコード (1:1)
docker run --rm -it --volume $PWD:/workspace --runtime=nvidia willprice/nvidia-ffmpeg -y -i input.mp4 -c:v h264 -vf scale=1920:1080 -b:v 5M output.mp4複数ストリームのトランスコーディング (1:N)
docker run --rm -it --volume $PWD:/workspace --runtime=nvidia willprice/nvidia-ffmpeg \ -y -i input.mp4 \ -c:a copy -c:v h264 -vf scale=1920:1080 -b:v 5M output_1080.mp4 \ -c:a copy -c:v h264 -vf scale=1280:720 -b:v 5M output_720.mp4 \ -c:a copy -c:v h264 -vf scale=640:480 -b:v 5M output_480.mp4
表 1. パラメーターの説明
パラメーター
説明
-c: コピー
オーディオストリームは、記録せずにコピーすることができる。
-c:v h264
出力ストリーム用のソフトウェアH.264エンコーダを選択します。
-b:v 5M
出力ビットレートを5メガバイト/秒に設定します。
GPUアクセラレーションによるトランスコードのコマンド
シングルストリームのトランスコード (1:1)
docker run --rm -it --volume $PWD:/workspace --runtime=nvidia willprice/nvidia-ffmpeg -y -hwaccel cuda -hwaccel_output_format cuda -i input.mp4 -c:v h264_nvenc -vf scale_cuda=1920:1080:1:4 -b:v 5M output.mp4複数ストリームのトランスコーディング (1:N)
docker run --rm -it --volume $PWD:/workspace --runtime=nvidia willprice/nvidia-ffmpeg \ -y -hwaccel cuda -hwaccel_output_format cuda -i input.mp4 \ -c:a copy -c:v h264_nvenc -vf scale_npp=1920:1080 -b:v 5M output_1080.mp4 \ -c:a copy -c:v h264_nvenc -vf scale_npp=1280:720 -b:v 5M output_720.mp4 \ -c:a copy -c:v h264_nvenc -vf scale_npp=640:480 -b:v 5M output_480.mp4
表 2. パラメーターの説明
パラメーター
説明
-hwaccel cuda
適切なハードウェアアクセラレータを選択します。
-hwaccel_output_format cuda
デコードされたフレームをGPUメモリに保存します。
-c:v h264_nvenc
NVIDIAハードウェアを使用してH.264エンコーダを高速化します。
準備
ユーザーエクスペリエンスを最適にするには、DingTalkグループ (ID 11721331) に参加し、次の情報を提供します。
組織名 (会社の名前など) 。
Alibaba CloudアカウントのID。
GPUアクセラレーションインスタンスを使用するリージョン (中国 (深セン) など) 。
携帯電話番号、メールアドレス、DingTalkアカウントなどの連絡先情報。
GPUアクセラレーションインスタンスが存在するリージョンで、次の操作を実行します。
Container Registry Enterprise EditionインスタンスまたはPersonal Editionインスタンスを作成します。 Enterprise Editionインスタンスを作成することを推奨します。 詳細については、「手順1: Container Registry Enterprise Editionインスタンスの作成」をご参照ください。
名前空間とイメージリポジトリを作成します。 詳細については、「手順2: 名前空間の作成」および「手順3: イメージリポジトリの作成」をご参照ください。
FFmpegをコンパイルします。
GPUアクセラレーションを使用する前に、FFmpegをコンパイルする必要があります。 次の項目は、FFmpegをコンパイルする方法を説明します。
(推奨) Dockerからコンパイル済みFFmpegを使用します。 ダウンロードアドレス: nvidia-ffmpegまたはffmpeg。
FFmpegを手動でコンパイルします。 詳細については、「コンパイルガイド」をご参照ください。
処理するオーディオおよびビデオリソースを、GPUアクセラレーションインスタンスが配置されているリージョンのObject Storage Service (OSS) バケットにアップロードします。 バケット内のオブジェクトに対する読み取りおよび書き込み権限があることを確認してください。 オーディオおよびビデオリソースをアップロードする方法の詳細については、「オブジェクトのアップロード」をご参照ください。 権限の詳細については、「バケットのACLの変更」をご参照ください。
Serverless Devsを使用してGPUアプリケーションをデプロイする
あなたが始める前に
手順
プロジェクトを作成します。
s init devsapp/start-fc-custom-container-event-python3.9 -d fc-gpu-prj次のサンプルコードは、作成されたプロジェクトのディレクトリを示しています。
fc-gpu-prj ├── code │ ├── app.py # Function code. │ └── Dockerfile # Dockerfile: The image Dockerfile that contains the code. ├── README.md └── s.yaml # Project configurations, which specify how the image is deployed in Function Computeでのイメージのデプロイ方法を指定するプロジェクト設定
プロジェクトディレクトリに移動します。
cd fc-gpu-prjビジネス要件に基づいて、次のファイルのパラメーター設定を変更します。
を編集します。Edit thes.yamlファイルを作成します。
YAMLファイルのパラメーターの詳細については、「YAML仕様」をご参照ください。
edition: 1.0.0 name: container-demo access: default vars: region: cn-shenzhen services: customContainer-demo: component: devsapp/fc props: region: ${vars.region} service: name: tgpu_ffmpeg_service internetAccess: true function: name: tgpu_ffmpeg_func description: test gpu for ffmpeg handler: not-used timeout: 600 caPort: 9000 instanceType: fc.gpu.tesla.1 gpuMemorySize: 8192 cpu: 4 memorySize: 16384 diskSize: 512 runtime: custom-container customContainerConfig: #1. Make sure that the namespace:demo namespace and the repo:gpu-transcoding_s repository are created in advance in Alibaba Cloud Container Registry. #2. Modify the tag from v0.1 to v0.2 when you update the function later and run s build && s deploy again. image: registry.cn-shanghai.aliyuncs.com/demo/gpu-transcoding_s:v0.1 codeUri: ./codeを編集します。Edit theapp.pyファイルを作成します。
例:
# -*- coding: utf-8 -*- # python2 and python3 from __future__ import print_function from http.server import HTTPServer, BaseHTTPRequestHandler import json import sys import logging import os import time import urllib.request import subprocess class Resquest(BaseHTTPRequestHandler): def download(self, url, path): print("enter download:", url) f = urllib.request.urlopen(url) with open(path, "wb") as local_file: local_file.write(f.read()) def upload(self, url, path): print("enter upload:", url) headers = { 'Content-Type': 'application/octet-stream', 'Content-Length': os.stat(path).st_size, } req = urllib.request.Request(url, open(path, 'rb'), headers=headers, method='PUT') urllib.request.urlopen(req) def trans(self, input_path, output_path, enable_gpu): print("enter trans input:", input_path, " output:", output_path, " enable_gpu:", enable_gpu) cmd = ['ffmpeg', '-y', '-i', input_path, "-c:a", "copy", "-c:v", "h264", "-b:v", "5M", output_path] if enable_gpu: cmd = ["ffmpeg", "-y", "-hwaccel", "cuda", "-hwaccel_output_format", "cuda", "-i", input_path, "-c:v", "h264_nvenc", "-b:v", "5M", output_path] try: subprocess.run(cmd, stdout=subprocess.PIPE, stderr=subprocess.PIPE, check=True) except subprocess.CalledProcessError as exc: print('\nreturncode:{}'.format(exc.returncode)) print('\ncmd:{}'.format(exc.cmd)) print('\noutput:{}'.format(exc.output)) print('\nstderr:{}'.format(exc.stderr)) print('\nstdout:{}'.format(exc.stdout)) def trans_wrapper(self, enable_gpu): src_url = "https://your.domain/input.mp4" # Use the path of the OSS object under your Alibaba Cloud account. You must have the read and write permissions on the object. dst_url = "https://your.domain/output.flv" # Use the path of the OSS object under your Alibaba Cloud account. You must have the read and write permissions on the object. src_path = "/tmp/input_c.flv" dst_path = "/tmp/output_c.mp4" if enable_gpu: src_url = "https://your.domain/input.mp4" # Use the path of the OSS object under your Alibaba Cloud account. You must have the read and write permissions on the object. dst_url = "https://your.domain/output.flv" # Use the path of the OSS object under your Alibaba Cloud account. You must have the read and write permissions on the object. src_path = "/tmp/input_g.flv" dst_path = "/tmp/output_g.mp4" local_time = time.time() self.download(src_url, src_path) download_time = time.time() - local_time local_time = time.time() self.trans(src_path, dst_path, enable_gpu) trans_time = time.time() - local_time local_time = time.time() self.upload(dst_url, dst_path) upload_time = time.time() - local_time data = {'result':'ok', 'download_time':download_time, 'trans_time':trans_time, 'upload_time':upload_time} self.send_response(200) self.send_header('Content-type', 'application/json') self.end_headers() self.wfile.write(json.dumps(data).encode()) def pong(self): data = {"function":"trans_gpu"} self.send_response(200) self.send_header('Content-type', 'application/json') self.end_headers() self.wfile.write(json.dumps(data).encode()) def dispatch(self): mode = self.headers.get('TRANS-MODE') if mode == "ping": self.pong() elif mode == "gpu": self.trans_wrapper(True) elif mode == "cpu": self.trans_wrapper(False) else: self.pong() def do_GET(self): self.dispatch() def do_POST(self): self.dispatch() if __name__ == '__main__': host = ('0.0.0.0', 9000) server = HTTPServer(host, Resquest) print("Starting server, listen at: %s:%s" % host) server.serve_forever()Dockerfileファイルを編集します。
例:
FROM registry.cn-shanghai.aliyuncs.com/serverless_devs/nvidia-ffmpeg:latest WORKDIR /usr/src/app RUN apt-get update --fix-missing RUN apt-get install -y python3 RUN apt-get install -y python3-pip COPY . . ENTRYPOINT [ "python3", "-u", "/usr/src/app/app.py" ] EXPOSE 9000
イメージを作成します。
s build --dockerfile ./code/DockerfileコードをFunction Computeにデプロイします。
s deploy説明上記のコマンドを繰り返し実行し、サービス名と関数名を変更しない場合は、
use localコマンドを実行してローカル設定を使用します。プロビジョニング済みインスタンスの設定
s provision put --target 1 --qualifier LATESTプロビジョニング済みインスタンスの準備ができているかどうかを確認します。
s provision get --qualifier LATESTcurrentの値が1の場合、GPUアクセラレーションインスタンスのプロビジョニングモードは準備完了です。 例:[2021-12-14 08:45:24] [INFO] [S-CLI] - Start ... [2021-12-14 08:45:24] [INFO] [FC] - Getting provision: tgpu_ffmpeg_service.LATEST/tgpu_ffmpeg_func customContainer-demo: serviceName: tgpu_ffmpeg_service functionName: tgpu_ffmpeg_func qualifier: LATEST resource: 188077086902****#tgpu_ffmpeg_service#LATEST#tgpu_ffmpeg_func target: 1 current: 1 scheduledActions: (empty array) targetTrackingPolicies: (empty array) currentError:関数を呼び出します。
オンライン機能のバージョンを表示する
s invokeトランスコードにCPUを使用する
s invoke -e '{"method":"GET","headers":{"TRANS-MODE":"cpu"}}'GPUを使用したトランスコード
s invoke -e '{"method":"GET","headers":{"TRANS-MODE":"gpu"}}'
GPU高速化インスタンスをリリースします。
s provision put --target 0 --qualifier LATEST
Function Computeコンソールを使用してGPUアプリケーションをデプロイする
イメージを展開します。
Container Registry Enterprise EditionインスタンスまたはContainer Registry Personal Editionインスタンスを作成します。
Enterprise Editionインスタンスを作成することを推奨します。 詳細については、「Container Registry Enterprise Editionインスタンスの作成」をご参照ください。
名前空間とイメージリポジトリを作成します。
詳細については、「Container Registry Enterprise Editionインスタンスを使用してイメージを構築する」トピックの「手順2: 名前空間の作成」および手順3: イメージリポジトリの作成」をご参照ください。
Container Registryコンソールのプロンプトに従って、Dockerで操作を実行します。 次に、前述のサンプルapp.pyとDockerfileをインスタンスイメージリポジトリにプッシュします。 ファイルの詳細については、Serverless Devsを使用してGPUアプリケーションをデプロイする場合、/codeディレクトリのapp.pyおよびDockerfileをご参照ください。
サービスを作成します。 詳細については、「サービスの管理」セクションの「サービスの作成」セクションをご参照ください。
関数を作成します。 詳細については、「カスタムコンテナー関数の作成」をご参照ください。
説明[インスタンスタイプ] に [GPUインスタンス] 、[リクエストハンドラタイプ] に [HTTPリクエストの処理] を選択します。
関数の実行タイムアウト時間を変更します。
管理する機能を見つけて、[操作] 列の [設定] をクリックします。
[環境情報] セクションで、[実行タイムアウト期間] の値を変更し、[保存] をクリックします。
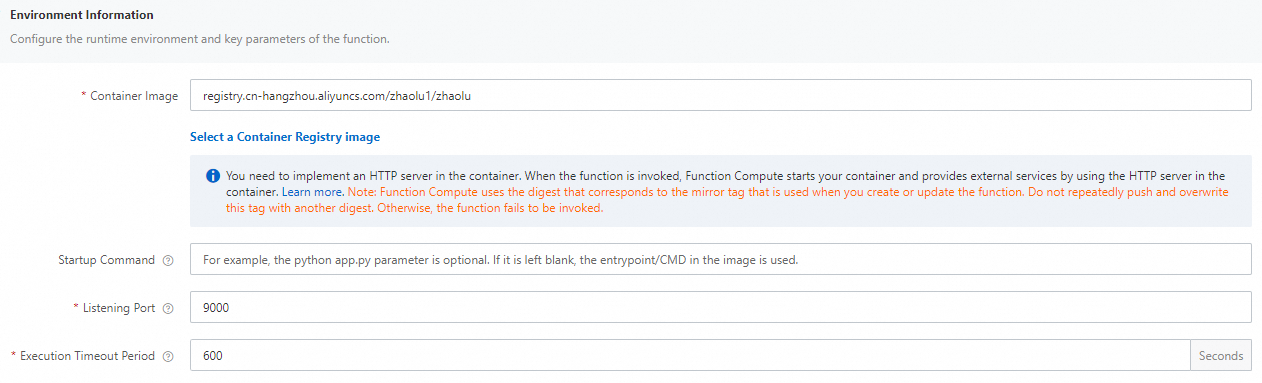
説明CPUを使用したトランスコード時間は、デフォルト値の60秒を超えています。 したがって、[実行タイムアウト期間] の値をより大きな値に設定することを推奨します。
プロビジョニングされたGPU高速化インスタンスを設定します。
[機能の詳細] ページで、[自動スケーリング] タブをクリックし、[ルールの作成] をクリックします。
表示されるページで、次のパラメーターを設定してGPUアクセラレーションインスタンスをプロビジョニングし、[作成] をクリックします。
プロビジョニング済みインスタンスの設定方法の詳細については、「自動スケーリングルールの設定」をご参照ください。
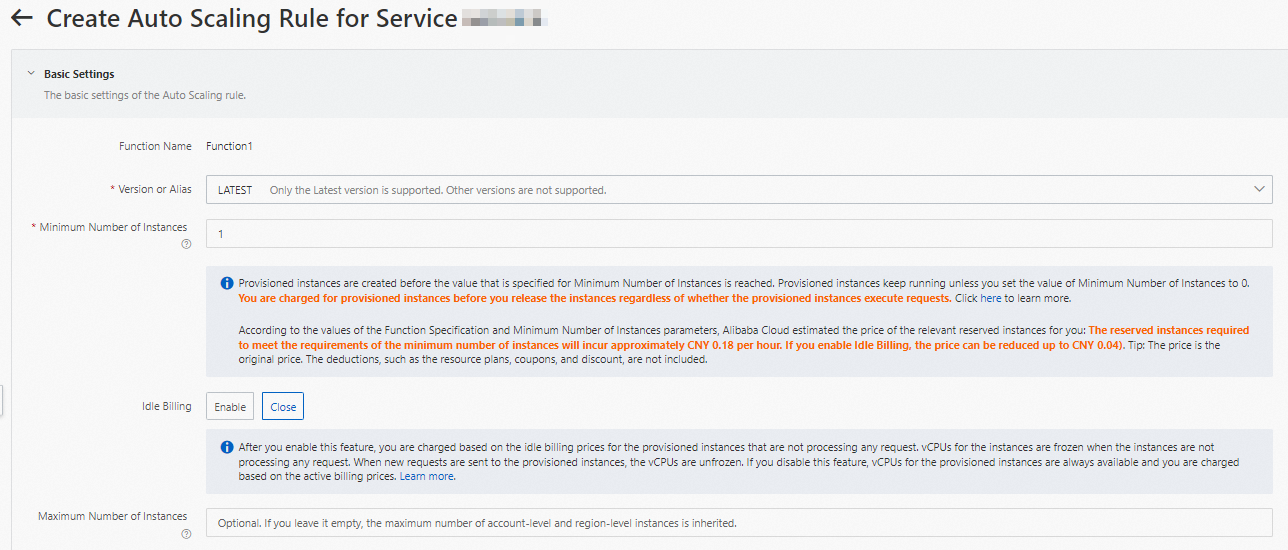
設定が完了したら、プロビジョニングされたGPUアクセラレーションインスタンスの準備ができているかどうかをルールリストで確認できます。 具体的には、Current Reserved Instancesの値が指定されたプロビジョニング済みインスタンスの数であるかどうかを確認します。
cURLを使用して関数をテスト
関数の詳細ページで、[トリガー] タブをクリックしてトリガーの設定を表示し、トリガーのエンドポイントを取得します。
コマンドラインインターフェイス (CLI) で次のコマンドを実行して、GPU関数を呼び出します。
オンライン機能のバージョンを表示する
curl -v "https://tgpu-ff-console-tgpu-ff-console-ajezot****.cn-shenzhen.fcapp.run" {"function": "trans_gpu"}トランスコードにCPUを使用する
curl "https://tgpu-ff-console-tgpu-ff-console-ajezot****.cn-shenzhen.fcapp.run" -H 'TRANS-MODE: cpu' {"result": "ok", "upload_time": 8.75510573387146, "download_time": 4.910430669784546, "trans_time": 105.37688875198364}GPUを使用したトランスコード
curl "https://tgpu-ff-console-tgpu-ff-console-ajezotchpx.cn-shenzhen.fcapp.run" -H 'TRANS-MODE: gpu' {"result": "ok", "upload_time": 8.313958644866943, "download_time": 5.096682548522949, "trans_time": 8.72346019744873}
結果
ブラウザで次のドメイン名にアクセスすると、トランスコード後にビデオを表示できます。
https://cri-zbtsehbrr8******-registry.oss-cn-shenzhen.aliyuncs.com/output.flvこのドメイン名は例として使用されます。 実際のドメイン名が優先されます。