Function Computeのインスタンスには、オンデマンドモードとプロビジョニングモードの2つの使用モードがあります。 どちらのモードでも、インスタンスの数とスケーリング速度に関する制限に基づいてオートスケーリングルールを設定できます。 プロビジョニングされたインスタンスでは、スケジュールされたスケーリングおよびメトリックベースのスケーリングルールを設定できます。
インスタンススケーリングの制限
オンデマンドインスタンスのスケーリング制限
Function Computeは既存のインスタンスを優先的に使用してリクエストを処理します。 既存のインスタンスがフルキャパシティになると、Function Computeはリクエストを処理するために新しいインスタンスを作成します。 リクエストの数が増えると、Function Computeは、着信リクエストを処理するのに十分なインスタンスが作成されるか、インスタンスの数が上限に達するまで、新しいインスタンスを作成し続けます。 オンデマンドインスタンスのスケーリングは、次の要因によって制約されます。
許可されるインスタンスの最大数: デフォルトでは、各Alibaba Cloudアカウントは、オンデマンドインスタンスとプロビジョニング済みインスタンスの両方を含め、リージョン内で最大100のインスタンスを実行できます。 クォータセンターコンソールの一般クォータページに表示される実際のクォータが優先されます。
実行中のインスタンスのスケーリング速度は、バースト可能なインスタンスの最大数とインスタンスが増加できる最大レートの両方によって制限されます。 異なるリージョンの制限の詳細については、「異なるリージョンのインスタンスのスケーリング速度の制限」をご参照ください。
バースト可能インスタンス: すぐに作成されたインスタンス。 バースト可能インスタンスのデフォルトの上限は、リージョンに応じて100または300です。
インスタンス成長率: バースト可能インスタンスの上限に達したときのインスタンス数の増加速度。 インスタンスの成長率のデフォルトの上限は、リージョンに応じて毎分100または毎分300です。
インスタンス数またはスケーリング速度が制限を超えた場合、Function ComputeはHTTP 429のステータスコードを返し、スロットリングエラーが発生したことを示します。 次の図は、呼び出しが急増したときにFunction Computeがスロットリングを適用する方法を示しています。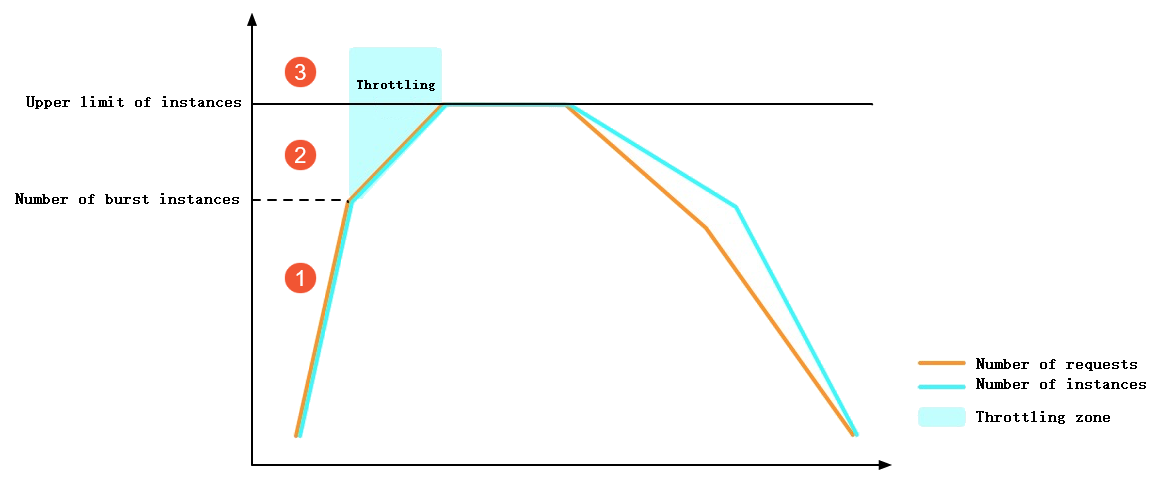
①: Function Computeは、リクエストの急増に対応するインスタンスを即座に作成します。 このプロセス中にコールドスタートが発生します。 バースト可能インスタンスの数が上限に達していないため、スロットリングエラーは報告されません。
②: インスタンス数の増加は、バースト可能なインスタンスの上限に達したため、インスタンスの増加率によって制限されるようになりました。 一部のリクエストでは、スロットルエラーが報告されます。
③: インスタンスの最大数に達したため、一部のリクエストでスロットリングエラーが発生しました。
デフォルトでは、同じリージョンのAlibaba Cloudアカウント内のすべての関数が同じスケーリング制限を共有します。 特定の機能のインスタンスの最大数を設定するには、「オンデマンドインスタンスの最大数の設定の概要」をご参照ください。 実行中のインスタンスの数が設定された最大値を超えると、Function Computeはスロットリングエラーを返します。
プロビジョニング済みインスタンスのスケーリング制限
突然の呼び出しの数が多すぎると、スロットリングエラーが避けられなくなります。 さらに、新しいインスタンスの作成によりコールドスタートが発生します。 どちらもリクエスト処理のレイテンシを増加させます。 遅延を軽減するために、事前にFunction Computeでインスタンスを予約できます。 これらのリザーブドインスタンスは、プロビジョニング済みインスタンスと呼ばれます。 プロビジョニングされたインスタンスのスケーリングは、オンデマンドインスタンスに課せられた制限の影響を受けません。 代わりに、それは以下の要因によって制約されます。
許可されるインスタンスの最大数: デフォルトでは、各Alibaba Cloudアカウントは、オンデマンドインスタンスとプロビジョニング済みインスタンスの両方を含め、リージョン内で最大100のインスタンスを実行できます。 クォータセンターコンソールの一般クォータページに表示される実際のクォータが優先されます。
最大スケーリング速度: プロビジョニングされたインスタンスのスケーリング速度のデフォルトの上限は、リージョンに応じて、1分あたり100または1分あたり300です。 異なるリージョンの制限の詳細については、「異なるリージョンのインスタンスのスケーリング速度の制限」をご参照ください。 次の図は、前の図と同じロードシナリオでプロビジョニングされたインスタンスが構成されている場合に、Function Computeがどのようにスロットリングを適用するかを示しています。
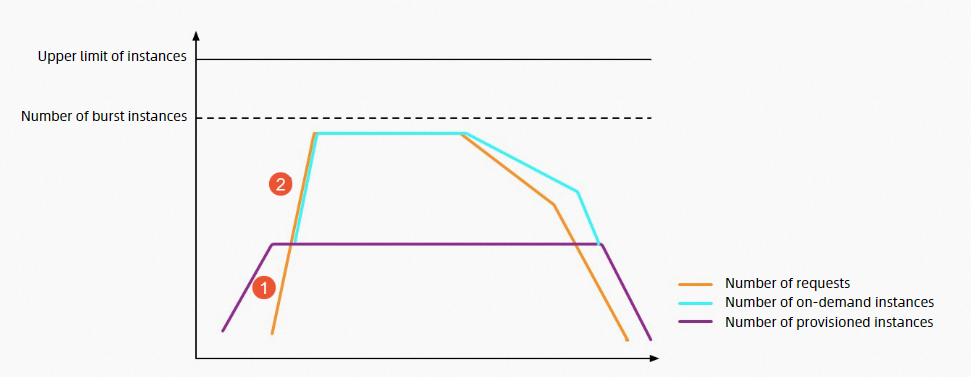
①: すべての受信リクエストは、プロビジョニングされたインスタンスが全容量に達するまですぐに処理されます。 このプロセス中、コールドスタートは発生せず、スロットリングエラーは報告されません。
②: プロビジョニングされたインスタンスが完全に活用されました。 Function Computeは、バースト可能なインスタンスの数が上限に達するまで、後続のリクエストを処理するオンデマンドインスタンスの作成を開始します。 このプロセス中、コールドスタートが発生しますが、スロットリングエラーは報告されません。
異なるリージョンのインスタンスのスケーリング速度の制限
リージョン | バースト可能インスタンスの最大数 | 最大インスタンス成長率 |
中国 (杭州) 、中国 (上海) 、中国 (北京) 、中国 (張家口) 、中国 (深セン) | 300 | 1分あたりの300 |
他のリージョン | 100 | 100/ 分 |
同じリージョンでは、プロビジョニングされたインスタンスとオンデマンドインスタンスのスケーリング速度の制限は同じです。
デフォルトでは、各Alibaba Cloudアカウントはリージョン内で最大100個のインスタンスを実行できます。 クォータセンターコンソールの一般クォータページに表示される実際のクォータが優先されます。 クォータセンターコンソールでクォータ調整を申請することもできます。
GPU高速化インスタンスは、CPUインスタンスと比較してスケーリング速度が遅くなります。 そのため、事前にプロビジョニングモードを使用してGPU高速化インスタンスを予約することを推奨します。
自動スケーリングルールの設定
自動スケーリングルールの作成
Function Computeコンソールにログインします。 左側のナビゲーションウィンドウで、[サービスと機能] をクリックします。
上部のナビゲーションバーで、リージョンを選択します。 [サービス] ページで、目的のサービスをクリックします。
関数ページで、変更する関数をクリックします。
関数の詳細ページで、自動スケーリングタブをクリックし、ルールの作成をクリックします。
表示されるページで、次のパラメーターを設定し、作成をクリックします。
オンデマンドインスタンスの場合
[最小インスタンス数] パラメーターを0に設定し、[最大インスタンス数] パラメーターをビジネス要件に最適な値に設定します。 [最大インスタンス数] パラメーターの設定を解除したままにした場合、許可される最大値は、Alibaba Cloudアカウントと現在のリージョンに適用される制限に基づきます。
説明プロビジョニングされたインスタンスでは、[アイドルモード] 、[スケジュール設定変更] 、および [メトリックベースの設定変更] パラメーターが有効になります。
プロビジョニング済みインスタンスの場合
パラメーター
説明
基本設定
バージョンまたはエイリアス
プロビジョニングされたインスタンスを作成するバージョンまたはエイリアスを選択します。
説明プロビジョニング済みインスタンスは、LATESTバージョンに対してのみ作成できます。
最小インスタンス数
作成するプロビジョニング済みインスタンスの数を入力します。 インスタンスの最小数は、作成されるプロビジョニング済みインスタンスの数と同じです。
説明関数インスタンスの最小数を設定することで、関数呼び出し要求のコールドスタートと応答時間を短縮できます。 これにより、オンラインサービス、特に応答遅延に敏感なサービスのパフォーマンスが向上します。
アイドルモード
ビジネス要件に基づいて、アイドルモード機能を有効または無効にします。 デフォルトでは無効になっています。 以下の点にご注意ください。
この機能を有効にすると、プロビジョニングされたインスタンスには、リクエストを処理している間だけvCPUリソースが割り当てられます。 リクエストの処理を停止すると、vCPUリソースは凍結されます。
Function Computeは、インスタンスが容量に達するまで、インスタンスの同時実行設定に基づいて同じインスタンスに着信リクエストを送信し続けます。 たとえば、インスタンスの同時実行性を50に設定し、10個のアイドルプロビジョニング済みインスタンスがある場合、40個のリクエストが到着すると、それらは同じインスタンスに送信され、そのインスタンスのみがアクティブ状態に遷移します。
この機能を無効にすると、プロビジョニングされたインスタンスは常にアクティブなままになります。つまり、リクエストを処理しているかどうかに関係なく、vCPUリソースが割り当てられます。
最大インスタンス数
ビジネス要件に最適なインスタンスの最大数を設定します。 プロビジョニング済みインスタンスとオンデマンドインスタンスの両方をカウントする必要があります。 インスタンスの最大数は、作成されるプロビジョニング済みインスタンスの数に、許可されるオンデマンドインスタンスの最大数を加えたものに等しくなります。
説明インスタンスの最大数を設定することで、1つの関数が過度の呼び出しによって多くのインスタンスを占有することを防ぐことができます。 これにより、バックエンドリソースを保護し、予期しない料金を回避できます。
このパラメーターを設定しない場合、許可されるインスタンスの最大数は、Alibaba Cloudアカウントと現在のリージョンに適用される制限に基づいています。
(オプション) スケジュール設定の変更: スケジュールされたスケーリングルールを作成して、プロビジョニングされたインスタンスをより柔軟に設定できます。 スケジュールされたスケーリングポリシーは、指定された時間にプロビジョニングされたインスタンスの数を指定された値に自動的に調整し、サービスの特定の同時実行要件を満たします。 設定の原則と例の詳細については、「スケジュール設定の変更」をご参照ください。
ポリシー名
ポリシー名を入力してください。
最小インスタンス数
指定された時間範囲に必要なプロビジョニング済みインスタンスの数を入力します。
スケジュール式 (UTC)
スケジュールの式を入力します。 例: cron(0 0 20 * * *) 。 詳細については、「パラメーターの説明」をご参照ください。
有効時間 (UTC)
スケジュールされたスケーリングルールが有効になる開始時間と終了時間を指定します。
(オプション) メトリックベースの設定の変更: メトリックベースのスケーリングポリシーは、インスタンスの同時実行性とさまざまな機能リソースの使用率に基づいて、プロビジョニングされたインスタンスの数を1分ごとに自動的に調整します。 設定の原則と例の詳細については、「メトリックベースの設定の変更」をご参照ください。
ポリシー名
ポリシー名を入力してください。
インスタンスの最小範囲
プロビジョニングされたインスタンスの最小数の範囲を指定します。
利用タイプ
このパラメーターは、GPU高速化インスタンスでのみ使用できます。 スケーリングポリシーの動作を決定するメトリックタイプを選択します。 GPUアクセラレーションインスタンスの自動スケーリングポリシーの詳細については、「プロビジョニングされたGPUアクセラレーションインスタンスの自動スケーリングポリシーの作成」をご参照ください。
同時実行使用のしきい値
スケーリングをトリガーするしきい値を設定します。 インスタンスの同時実行性または指定された関数リソースの使用率が設定したしきい値を下回ると、function Computeはプロビジョニングされたインスタンスの数を減らします。 逆に、使用率がしきい値を超えると、Function Computeはインスタンスをスケールアウトします。
有効時間 (UTC)
有効にするメトリックベースのスケーリングルールの開始時間と終了時間を指定します。
関数の [Auto Scaling] タブに移動して、関数用に作成したオートスケーリングルールを表示します。
自動スケーリングルールの変更または削除
[Auto Scaling] タブで、管理するルールを見つけ、[操作] 列の [変更] または [削除] をクリックして、ルールを変更または削除します。
プロビジョニングされたインスタンスが不要になった場合は、[最小インスタンス数] パラメーターを0に設定します。
プロビジョニング済みインスタンスの自動スケーリング
プロビジョニングされたインスタンスの固定数の設定に加えて、スケジュール設定の変更およびメトリックベースの設定の変更パラメーターを設定することで、柔軟な調整を行うことができます。 このアプローチは、インスタンス使用率の向上に役立ちます。
スケジュール設定の変更
定義: スケジュールされたスケーリングポリシーは、指定された時間にプロビジョニングされたインスタンスの数を指定された値に自動的に調整し、サービスの特定の同時実行要件を満たします。
適用可能なシナリオ: サービスに明確な周期パターンまたは予測可能なトラフィックピークがある場合は、スケジュールされたスケーリングを選択します。 同時呼び出しの数がスケジュールされたスケーリングポリシーで定義された容量を超えると、すべての過剰なリクエストは処理のためにオンデマンドインスタンスに送信されます。 詳細については、「インスタンスタイプと使用モード」をご参照ください。
例: 次の図は、インスタンスのスケーリングの2つのスケジュールアクションを示しています。 最初のスケジュールされたアクションは、トラフィックピークの前にプロビジョニングされたインスタンスをスケールアウトし、2番目のスケジュールされたアクションは、トラフィックピークの後にプロビジョニングされたインスタンスをスケールアウトします。
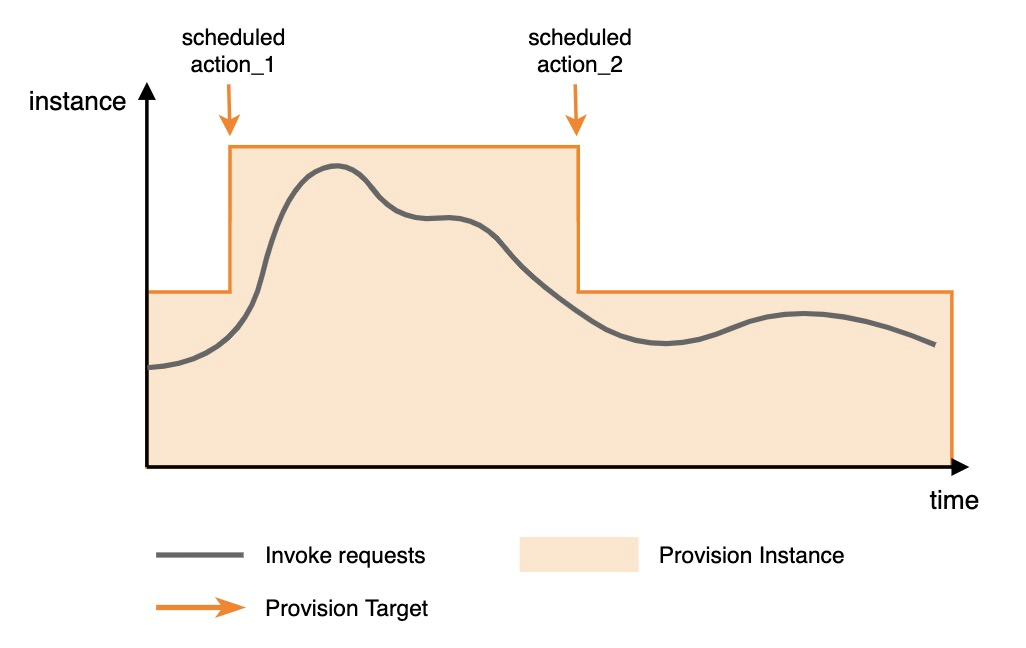
次のサンプルコードは、設定の詳細を示しています。 この例では、service_1という名前のサービスのfunction_1という名前の関数は、自動的にスケールインおよびスケールアウトするように構成されています。 設定は、2022年11月1日の10:00:00から2022年11月30日の10:00:00まで有効になります。 プロビジョニングされたインスタンスの数は、毎日20:00に50、22:00に10に調整されます。 PutProvisionConfig操作を使用してスケジュールされたスケーリングを構成する方法の詳細については、次のサンプルコードを参照してください。
{
"ServiceName": "service_1",
"FunctionName": "function_1",
"Qualifier": "alias_1",
"ScheduledActions": [
{
"Name": "action_1",
"StartTime": "2022-11-01T10:00:00Z",
"EndTime": "2022-11-30T10:00:00Z",
"TargetValue": 50,
"ScheduleExpression": "cron(0 0 20 * * *)"
},
{
"Name": "action_2",
"StartTime": "2022-11-01T10:00:00Z",
"EndTime": "2022-11-30T10:00:00Z",
"TargetValue": 10,
"ScheduleExpression": "cron(0 0 22 * * *)"
}
]
}サンプルコードのパラメーターを次の表に示します。
パラメーター | 説明 |
Name | スケジュールされた自動スケーリングタスクの名前。 |
StartTime | スケーリングポリシーが有効になり始める時刻 (UTC) 。 |
EndTime | スケーリングポリシーの有効期限 (UTC) 。 |
ターゲット値 | インスタンスのターゲット数。 |
ScheduleExpression | スケジュールされたスケーリングタスクをいつ実行するかを指定する式。 次の形式がサポートされています。
|
次の表に、cron式のフィールドをSeconds Minutes Hours Day-of-month Day-of-weekの形式で示します。
表 1. フィールドの説明
フィールド | 有効値 | 許可された特殊文字 |
秒 | 0から59 | なし |
分 | 0から59 | , - * / |
時間 | 0から23 | , - * / |
月の日 | 1から31 | , - * ? / |
1 か月 | 1〜12またはJAN〜DEC | , - * / |
曜日 | 1〜7またはMON〜SUN | , - * ? |
表 2. 特殊文字の説明
キャラクター | 説明 | 例 |
* | anyまたはそれぞれを示します。 |
|
, | 値のリストを指定します。 |
|
- | 範囲を指定します。 |
|
? | 不確定な値を示します。 | この文字は指定された値と共に使用されます。 たとえば、特定の曜日に関連付けずに日付を指定した場合、 |
/ | 増分を指定します。 n/mは、nの位置から始まるmの増分を示す。 |
|
メトリックベースの設定の変更
定義: メトリックベースの自動スケーリングポリシーは、追跡するメトリックに基づいて、プロビジョニングされたインスタンスの数を動的に調整します。
機能: メトリックベースのスケーリングポリシーを設定すると、Function Computeは、プロビジョニングされたインスタンスの同時実行使用率メトリックまたはリソース使用率メトリックを定期的に収集します。 これらのメトリックを、インスタンスのスケーリングを制御するために指定したスケーリングトリガー値と組み合わせて使用し、インスタンスの数が実際のリソース使用量に一致するようにします。
原則: プロビジョニングされたインスタンスの数は、メトリック値に基づいて1分ごとに調整されます。
メトリック値がトリガー値またはしきい値を超えると、スケールアウトを指定します。Function Computeは、プロビジョニングされたインスタンスの数をスケールアウトの事前設定されたターゲットまで急速に増やします。
逆に、メトリック値がスケールイン用に設定したしきい値を下回ると、Function Computeはプロビジョニングされたインスタンスの数をスケールイン用にプリセットされたターゲットに向けて徐々に調整します。
プロビジョニングされたインスタンスの最大数と最小数が設定されている場合、Function Computeはその範囲内でインスタンスをスケーリングします。 インスタンス数が最大または最小に達すると、スケーリングは停止します。
例: 次の図は、インスタンス同時実行の使用率に基づく自動スケーリングの例を示しています。
トラフィック量が増加すると、スケールアウトしきい値がトリガーされ、Function Computeはプロビジョニングされたインスタンスの数を増やし始めます。 スケールアウトは、数が上限に達すると停止する。 過剰なリクエストは、処理のためにオンデマンドインスタンスに送信されます。
トラフィック量が減少すると、スケールインしきい値がトリガーされ、Function Computeはプロビジョニングされたインスタンスの数を減らし始めます。
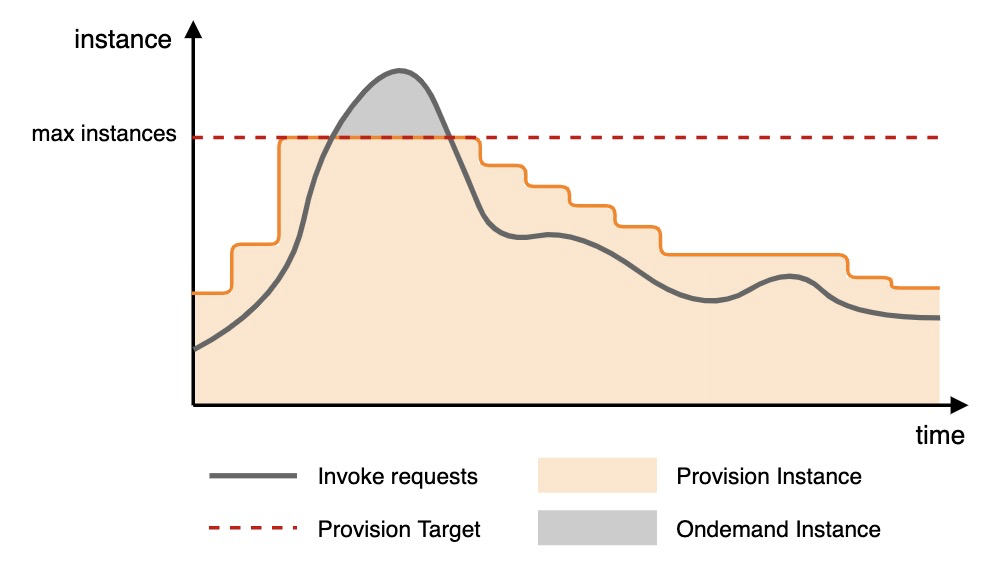
同時実行利用率メトリックには、プロビジョニングされたインスタンスの同時実行のみが含まれ、オンデマンドインスタンスの同時実行は含まれません。
メトリックは、次の式を使用して計算されます。プロビジョニングされたインスタンスによって処理される同時リクエストの数 /すべてのプロビジョニングされたインスタンスが処理できる同時リクエストの最大数。 メトリック値の範囲は0から1です。
プロビジョニングされたすべてのインスタンスが処理できる同時リクエストの最大数、または最大同時実行性は、インスタンスの同時実行設定によって決まります。 詳細については、「インスタンス同時実行の設定」をご参照ください。
各インスタンスは一度に1つのリクエストを処理します。最大同時実行数=インスタンス数。
各インスタンスは複数のリクエストを同時に処理します。最大同時実行数=インスタンス数 × 1つのインスタンスによって同時に処理されるリクエスト数。
スケーリングのターゲット値:
値は、現在のメトリック値、メトリックターゲット、プロビジョニングされたインスタンスの現在の数、およびスケールイン係数によって決定されます。
計算の原則: Function Computeは、0 (除外) から1までのスケールイン係数に基づいて、プロビジョニングされたインスタンスでスケールします。 スケールイン係数は、スケールイン速度を遅くするために使用されるシステムパラメータである。 手動設定は必要ありません。 スケーリングタスクのターゲット値は、次の計算結果以上の最小の整数です。
スケールアウト目標値=現在のプロビジョニング済みインスタンス × (現在のメトリック値 /メトリック目標)
スケールイン目標値=現在のプロビジョニング済みインスタンス × スケールイン係数 × (1-現在のメトリック値 /メトリック目標)
例: 現在のメトリック値が80% 、メトリックターゲットが40% 、現在のプロビジョニング済みインスタンス数が100の場合、ターゲット値は次の式に基づいて計算されます。100 × (80%/40%) = 200。 プロビジョニングされたインスタンスの数を200に増やして、メトリックターゲットが40% の近くに留まるようにします。
次のサンプルコードは、設定の詳細を示しています。 この例では、service_1という名前のサービスのfunction_1という名前の関数は、ProvisionedConcurrencyUtilizationメトリックに基づいて自動的にスケールインおよびスケールアウトするように構成されています。 設定は、2022年11月1日の10:00:00から2022年11月30日の10:00:00まで有効になります。 同時実行使用率が60% を超えると、プロビジョニングされたインスタンスの数が増加し、上限は100になります。 同時実行使用率が60% を下回ると、プロビジョニングされたインスタンスの数が減り、下限は10になります。 PutProvisionConfig操作を使用してスケジュールされたスケーリングを構成する方法の詳細については、次のサンプルコードを参照してください。
{
"ServiceName": "service_1",
"FunctionName": "function_1",
"Qualifier": "alias_1",
"TargetTrackingPolicies": [
{
"Name": "action_1",
"StartTime": "2022-11-01T10:00:00Z",
"EndTime": "2022-11-30T10:00:00Z",
"MetricType": "ProvisionedConcurrencyUtilization",
"MetricTarget": 0.6,
"MinCapacity": 10,
"MaxCapacity": 100,
}
]
}サンプルコードのパラメーターを次の表に示します。
パラメーター | 説明 |
Name | 設定されたメトリックベースの自動スケーリングタスクの名前。 |
StartTime | スケーリングポリシーが有効になり始める時刻 (UTC) 。 |
EndTime | スケーリングポリシーの有効期限 (UTC) 。 |
MetricType | 追跡されるメトリック。 この例では、値はProvisionedConcurrencyUtilizationに設定されています。 |
MetricTarget | メトリックベースの自動スケーリングのしきい値。 |
MinCapacity | スケールアウト用にプロビジョニングされたインスタンスの最大数。 |
MaxCapacity | スケールイン用にプロビジョニングされたインスタンスの最小数。 |
関連ドキュメント
オンデマンドおよびプロビジョニングされたインスタンスの基本概念と課金方法の詳細については、インスタンスタイプと使用モードをご参照ください。
プロビジョニングされたインスタンスの自動スケーリングポリシーを設定した後、FunctionProvisionedCurrentInstanceメトリックをチェックして、関数の実行で占有されているプロビジョニングされたインスタンスの数を確認できます。 詳細については、「関数固有のメトリック」をご参照ください。