この Topic では、Realtime Compute for Apache Flink のワークスペース、名前空間、デプロイメントの管理方法、および関連機能の使用方法について説明します。たとえば、リソースの構成の変更、ワークスペース ID の表示、デプロイメントのエンジンバージョンの表示、デプロイメントのパラメーターの構成が可能です。
ワークスペースと名前空間の管理
Realtime Compute for Apache Flink 計算リソースの構成をスペックアップした後に構成が有効にならない場合はどうすればよいですか?
Realtime Compute for Apache Flink デプロイメントで使用するために OSS コンソールでファイルをアップロードするにはどうすればよいですか?
アクティブ化したワークスペースが Realtime Compute for Apache Flink コンソールに表示されない場合はどうすればよいですか?
「Has not enough ip address: abnormal event detected from kubernetes」というエラーメッセージが表示された場合はどうすればよいですか?
アーティファクトのアップロード中に「Unknown Error: Http failure response for xxxxx」というエラーを修正するにはどうすればよいですか?
デプロイメント管理
ワークスペースの名前は変更できますか?
ワークスペースの名前は変更できません。
インスタンスの VPC と vSwitch は変更できますか?
インスタンスの VPC は変更できませんが、インスタンスの vSwitch を変更することはできます。
ワークスペース ID などのワークスペースに関する情報を表示するにはどうすればよいですか?
Realtime Compute for Apache Flink の管理コンソールにログインし、管理するワークスペースを見つけ、[操作] 列で を選択して、ワークスペース ID などのワークスペースに関する情報を表示します。

名前空間のスケールダウン中にリソース割り当てが失敗した場合はどうすればよいですか?
問題の説明
名前空間をスケールダウンすると、リソース割り当てが失敗します。

原因
すべてのリソースが割り当てられているか、使用されています。
解決策
名前空間のキューに割り当てられているリソースの量を減らしてから、名前空間をスケールダウンします。リソースの変更方法の詳細については、「キューで使用できる CU 数を再構成する」をご参照ください。

Realtime Compute for Apache Flink 計算リソースの構成をスペックアップした後に構成が有効にならない場合はどうすればよいですか?
サブスクリプション
Realtime Compute for Apache Flink のスケールアップにはトップダウンアプローチを使用します。ワークスペースのリソースクォータを増やし、ワークスペース内の名前空間にリソースを割り当て、次に名前空間内のキューにリソースを割り当てます。詳細については、「リソースの再構成」をご参照ください。

従量課金
従量課金方式では、リソースの支払い前にリソースを使用できます。システムは、ワークスペースの実際のリソース使用量に基づいて料金を計算します。リソースを再構成する必要はありません。管理するワークスペースを見つけ、[操作] 列で を選択します。[ワークスペースクォータ制限の編集] ダイアログボックスで、リソースの隔離と管理を必要とするバッチデプロイメントシナリオの要件をより満たすように、名前空間のキューのリソースを構成します。詳細については、「キューの管理」をご参照ください。
アカウントの AccessKey ペアを表示するにはどうすればよいですか?
AccessKey ID
Alibaba Cloud アカウントの AccessKey ID を表示するには、Alibaba Cloud アカウントを使用して Alibaba Cloud 管理コンソールにログインします。表示されるページの右上隅にあるプロファイル画像にポインターを合わせ、[AccessKey] をクリックします。
RAM ユーザーの AccessKey ID を表示するには、「RAM ユーザーの AccessKey ペアに関する情報を表示する」に記載されている手順に従ってください。
AccessKey Secret
AccessKey Secret は、Alibaba Cloud アカウントまたは RAM ユーザーの AccessKey ペアを作成するときにのみ表示されます。その後の操作で AccessKey Secret を表示することはできません。これにより、AccessKey ペアの漏洩リスクが軽減されます。AccessKey ペアを作成する際に、AccessKey Secret を記録し、機密に保管してください。
AccessKey ペアを忘れた場合は、別のペアを作成する必要があります。詳細については、「AccessKey ペアの作成」をご参照ください。
Realtime Compute for Apache Flink デプロイメントで使用するために OSS コンソールでファイルをアップロードするにはどうすればよいですか?
Realtime Compute for Apache Flink ワークスペースをアクティブ化するときにストレージタイプとして OSS バケットを選択した場合、ワークスペースに関連付けられている Object Storage Service (OSS) バケットにファイルをアップロードし、Realtime Compute for Apache Flink デプロイメントでオブジェクトを使用できます。Realtime Compute for Apache Flink 開発コンソールの [アーティファクト] ページでファイルをアップロードすることもできます。詳細については、「アーティファクトの管理」をご参照ください。
Realtime Compute for Apache Flink の管理コンソールにログインし、ワークスペースを見つけ、[操作] 列で を選択して、ワークスペースに関連付けられている OSS バケットに関する情報を表示します。
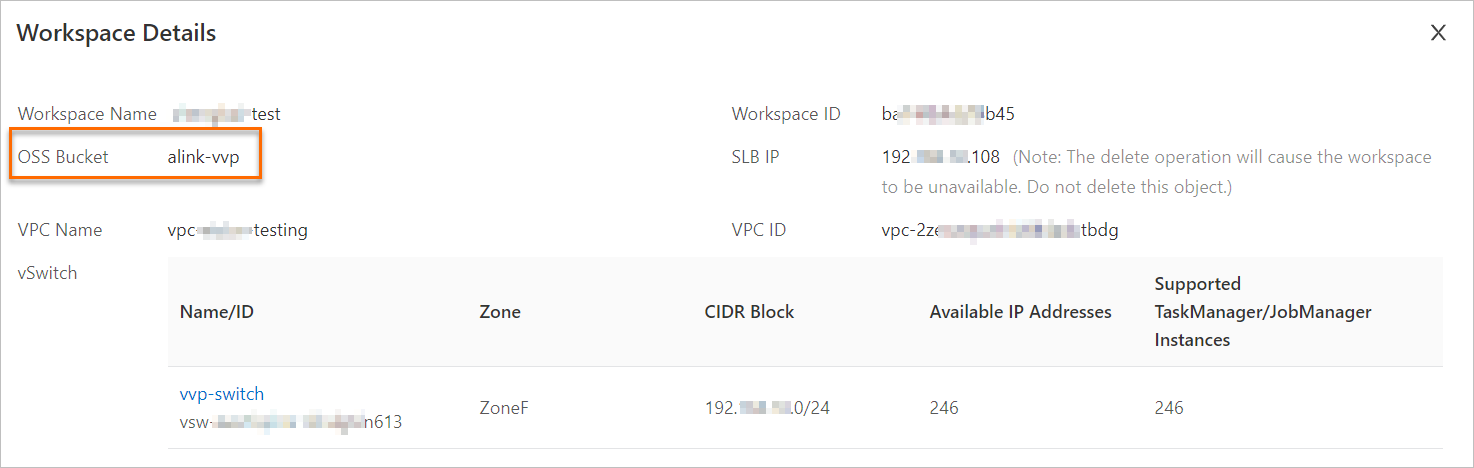
次のいずれかの方法で、リソースファイルを OSS バケットにアップロードします。
Realtime Compute for Apache Flink 開発コンソールの左側のナビゲーションウィンドウで、[アーティファクト] をクリックして、OSS コンソールでアップロードしたリソースファイルを表示します。

アクティブ化したワークスペースが Realtime Compute for Apache Flink コンソールに表示されない場合はどうすればよいですか?
次の観点から問題をトラブルシューティングします。問題が解決しない場合は、チケットを送信してください。
Realtime Compute for Apache Flink ワークスペースが初期化されているかどうかを確認します。ほとんどの場合、初期化には 5〜10 分かかります。
Realtime Compute for Apache Flink コンソールの上部ナビゲーションバーで選択したリージョンが、ワークスペースをアクティブ化したときに選択したリージョンであることを確認してください。
RAM ユーザーとしてコンソールにログインする場合は、その RAM ユーザーが Realtime Compute for Apache Flink の管理コンソールで必要な権限を持っていることを確認してください。権限構成の詳細については、「権限管理」をご参照ください。
「Has not enough ip address: abnormal event detected from kubernetes」というエラーメッセージが表示された場合はどうすればよいですか?
エラーメッセージ
Has not enough ip address:abnormal event detected from kubernetes (type:[Warning], reason:[CniError_CodeUnKnownErr], message:[CniAllocateError: allocateIP failed: ipamCreate failed: failed to create ENI: all vSwitches ([*****]) cannot be used: CreateNetworkInterface: RequestId: 67959AE5-EA20-5CB4-8560-5BD6752472FD, ErrorCode: InvalidVSwitchId.IpNotEnough, Message: The specified VSwitch "*****" has not enough IpAddress., elapsedTime: 245.03232ms])原因
vSwitch の CIDR ブロックで使用可能な IP アドレスがありません。
解決策
使用可能な IP アドレスを持つ vSwitch を作成します。詳細については、「vSwitch の変更」をご参照ください。
アーティファクトのアップロード中に「Unknown Error: Http failure response for xxxxx」というエラーを修正するにはどうすればよいですか?
説明
アーティファクトのアップロードが次のエラーで失敗しました:
Unknown Error: Http failure response for https://<bucketName>.oss-ap-southeast-1.aliyuncs.com: 0 Unknown Error。原因
Alibaba Cloud の国際サイトのドメイン名が alibabacloud.com に変更された後、Flink リクエストを成功させるには、OSS バケットにオリジン間リソース共有 (CORS) 設定が必要です。
解決策
Flink ワークスペースの OSS バケットに対して、OSS コンソールで CORS ルールを設定します。「アーティファクトの管理」の手順に従ってください。
ジョブのエンジンバージョンを表示するにはどうすればよいですか?
次のいずれかの方法を使用して、デプロイメントで使用される Realtime Compute for Apache Flink のエンジンバージョンを表示できます。
デプロイメントの [ETL] または [データ取り込み] ページに移動します。表示されるページの右側のナビゲーションウィンドウで [構成] タブをクリックします。[構成] パネルで、[エンジンバージョン] フィールドでデプロイメントで使用される Realtime Compute for Apache Flink のエンジンバージョンを表示します。

ページで、管理するデプロイメントを見つけて、その名前をクリックします。[構成] タブで、[基本] セクションの [エンジンバージョン] フィールドでデプロイメントで使用される Realtime Compute for Apache Flink のエンジンバージョンを表示します。

デプロイメントで使用される Realtime Compute for Apache Flink のエンジンバージョンを変更するにはどうすればよいですか?
SQL または YAML デプロイメント
デプロイメントの [ETL] または [データ取り込み] ページに移動します。表示されるページの右側のナビゲーションウィンドウで [構成] タブをクリックします。[構成] パネルで、[エンジンバージョン] ドロップダウンリストからターゲットのエンジンバージョンを選択します。デプロイメントのエンジンバージョンが変更された場合、バージョンの変更を有効にするには、ドラフトを再デプロイしてデプロイメントを開始する必要があります。
JAR または Python デプロイメント
[デプロイメント] ページで、管理するデプロイメントを見つけて、その名前をクリックします。[構成] タブで、[基本] セクションの右上隅にある [編集] をクリックします。[エンジンバージョン] ドロップダウンリストからターゲットのエンジンバージョンを選択し、[保存] をクリックしてから [開始] をクリックします。
デプロイメント実行用のカスタムパラメーターを構成するにはどうすればよいですか?
管理するワークスペースを見つけ、[操作] 列の [コンソール] をクリックします。
左側のナビゲーションウィンドウで、[デプロイメント] をクリックします。[デプロイメント] ページで、管理するデプロイメントを見つけて、その名前をクリックします。
[構成] タブで、[パラメーター] セクションの右上隅にある [編集] をクリックします。
[パラメーター] セクションで、[その他の構成] フィールドにパラメーター構成を追加します。
各キーと値のペアの間のコロン (:) の後にスペースがあることを確認してください。サンプルコード:
task.cancellation.timeout: 180s[保存] をクリックします。
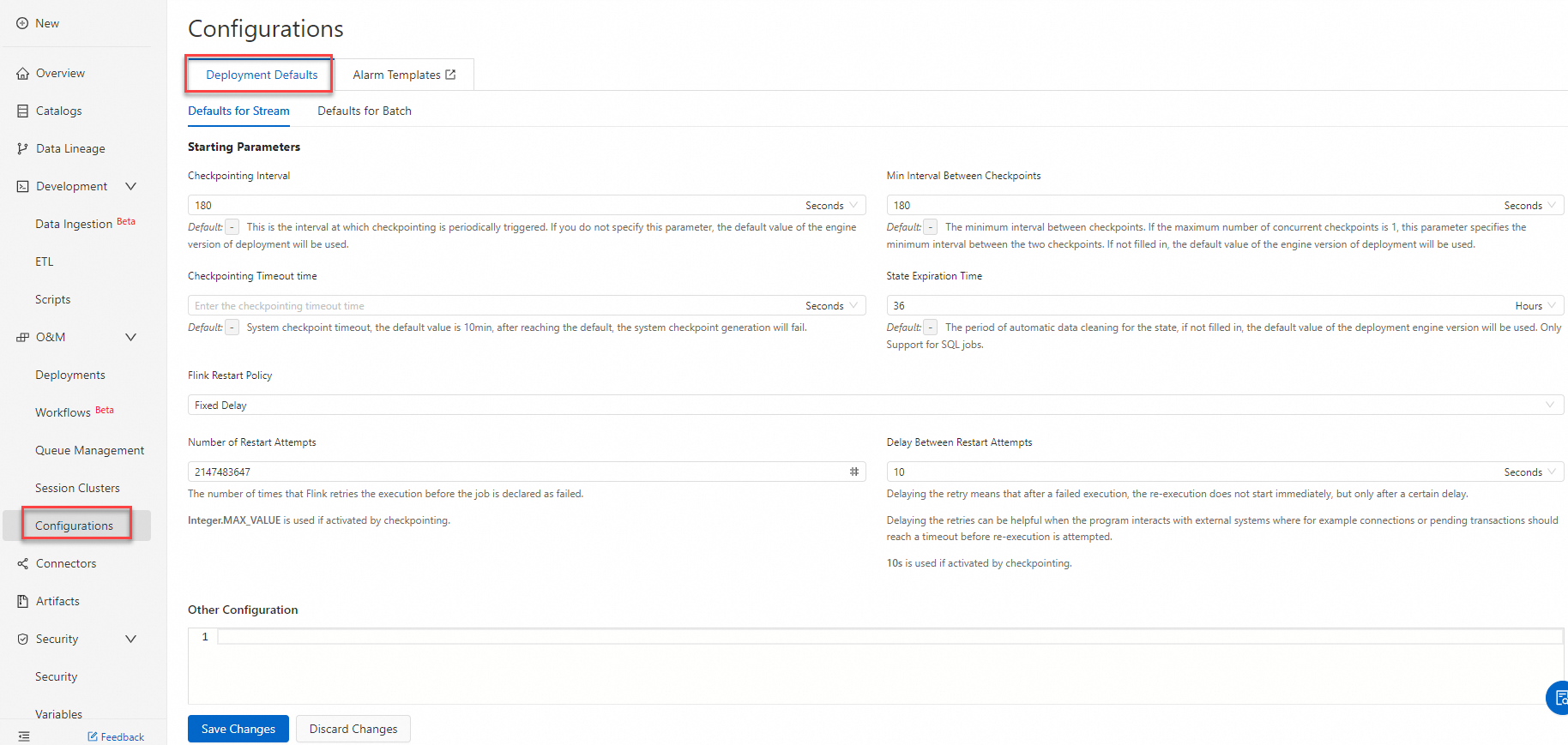
構成効率を向上させるために、Realtime Compute for Apache Flink の共通構成を永続化するにはどうすればよいですか?
Realtime Compute for Apache Flink は [ドラフトテンプレート] 機能を提供します。この機能を使用すると、共通のパラメーター構成をデフォルトとして保存できます。これにより、ドラフトを作成するときにパラメーターを手動で構成する必要がなくなります。
AccessKey ペアやパスワードなどの機密情報の漏洩を防ぐにはどうすればよいですか?
変数を使用して、プレーンテキストの AccessKey ペアやパスワードなどの情報によって引き起こされるセキュリティリスクを防ぎます。変数を使用することで、同じコードや値を繰り返し記述する必要がなくなります。これにより、構成管理が簡素化されます。SQL ドラフトや JAR または Python デプロイメントの開発、ログ出力構成、UI ベースのパラメーター構成など、さまざまなシナリオで変数を参照できます。詳細については、「変数の管理」をご参照ください。
Realtime Compute for Apache Flink デプロイメントの計算リソースを利用するにはどうすればよいですか?
次の方法を使用します。
手動調整: デプロイメントの [診断] タブで [診断] をクリックしてリソース分析結果を表示し、プロンプトに従って手動でリソースを調整します。
自動調整: 自動チューニング機能を有効にします。この機能により、システムはリソースを自動的に調整できます。アプリケーションシナリオと構成の詳細については、「自動チューニングの構成」をご参照ください。