GPUアクセラレーションLinuxインスタンスでPyTorchを使用すると、インスタンスにインストールされているCompute Unified Device Architecture (CUDA) のバージョンがPyTorchのバージョンと互換性がないため、エラーが発生する場合があります。 このトピックでは、この問題の原因と解決策について説明します。
問題の説明
Alibaba Cloud Linux 3を実行するGPUアクセラレーションLinuxインスタンスでPyTorchを使用すると、次のエラーメッセージが表示されます。
>>> import torch
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/local/lib/python3.8/dist-packages/torch/__init__.py", line 235, in <module>
from torch._C import * # noqa: F403
ImportError: /usr/local/lib/python3.8/dist-packages/torch/lib/../../nvidia/cusparse/lib/libcusparse.so.12: undefined symbol: __nvJitLinkAddData_12_1, version libnvJitLink.so.12原因
上記のエラーは、GPUアクセラレーションインスタンスにインストールされているCUDAのバージョンとPyTorchバージョンの間の非互換性が原因で発生する可能性があります。 CUDAバージョンとPyTorchバージョン間のマッピングの詳細については、「以前のPyTorchバージョン」をご参照ください。
sudo pip3 install torchコマンドでインストールされたPyTorchのバージョンは2.1.2で、互換性のあるCUDAバージョンは12.1です。 ただし、購入したGPUアクセラレーションインスタンスに自動的にインストールされるCUDAバージョンは12.0です。 このバージョンは、インストールされているPyTorchバージョンと互換性のあるCUDAバージョンと一致しません。
解決策
ECS (Elastic Compute Service) コンソールでGPU高速化インスタンスを購入したときに、イメージセクションの [パブリックイメージ] タブで [GPUドライバーの自動インストール] を選択した場合、次のいずれかの方法でCUDAバージョンを12.1に変更できます。
GPU高速化インスタンスを停止します。
詳細は、「インスタンスの停止」をご参照ください。
[インスタンス] ページで、停止したGPUアクセラレーションインスタンスを見つけ、[操作] 列の
 アイコンをクリックします。 [インスタンス設定] セクションで、[ユーザーデータの設定] をクリックします。
アイコンをクリックします。 [インスタンス設定] セクションで、[ユーザーデータの設定] をクリックします。 ユーザーデータを変更し、[OK] をクリックします。
DRIVER_VERSION、CUDA_VERSION、およびCUDNN_VERSIONパラメーターの値を次のバージョンに変更します。... DRIVER_VERSION="535.154.05" CUDA_VERSION="12.1.1" CUDNN_VERSION="8.9.7.29" ...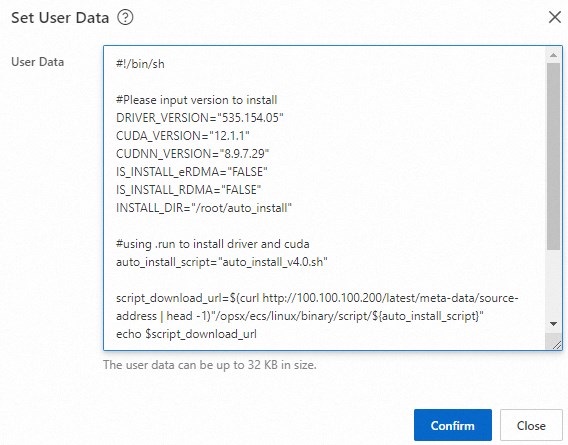
GPU高速化インスタンスのOSを変更します。
詳細については、「インスタンスのオペレーティングシステム (システムディスク) の交換」をご参照ください。
GPU高速化インスタンスが再起動された後、システムは新しいバージョンのNVIDIA Teslaドライバー、CUDA、およびCUDA Deep Neural Networkライブラリ (cuDNN) を再インストールします。