データ管理 (DMS) によって提供される分類およびグレーディング機能は、データベースの機密データを検出し、識別ルールの条件を満たすフィールドに対応するデータカテゴリを自動的にタグ付けし、識別結果に機密フィールドを表示できます。 この機能は、高感度レベルでフィールドを保護します。 このトピックでは、DMSの分類およびグレーディング機能の原理について説明します。
仕組み
DMSの分類およびグレーディング機能は、基本的な識別モデルベースのスキャンと、上位層の分類およびグレーディングベースのスキャンによって実装されます。 この機能を使用する場合、DMSはまず識別モデルを使用してテーブルのフィールドとデータをスキャンします。 次に、DMSは、分類およびグレーディングルールを使用してテーブルのフィールドをスキャンします。 識別モデルベースのスキャンは、名前または時間などのデータカテゴリを識別することができる。 分類およびグレーディングベースのスキャンは、識別モデルの識別結果に基づいて機能します。 インスタンスに関連付けられている分類テンプレートとグレーディングテンプレートを使用して、フィールドを分類およびグレーディングできます。 このプロセス中に、セキュリティレベルとデータマスキングアルゴリズムがフィールドに自動的に設定されます。
識別モデルに基づくスキャンと、分類及びグレーディングに基づくスキャンとは、互いに独立している。
識別モデルベースのスキャン
識別モデルベースのスキャンは、次の2つの識別方法をサポートします。
データコンテンツの識別 (正規表現一致)
この識別方法では、識別モデルは、フィールド内容に基づいてフィールドを分類する。 例えば、識別モデルがIDカードと名付けられ、フィールドがIDカードアルゴリズムの条件を満たす場合、フィールドは、この識別モデルによってIDカードのデータカテゴリでタグ付けされる。
データコンテンツ識別の間、DMSは識別のためにフィールドからいくつかのデータをランダムにサンプリングし、識別効率を保証する。 サンプリングされたデータ内の識別モデルの要件を満たすデータの量が指定されたしきい値よりも大きい場合、DMSはこのフィールドのデータカテゴリがIDカードであると判断します。
メタデータの識別
この識別方法では、識別モデルは、フィールド名に基づいてフィールドを分類する。 たとえば、DMSの組み込みIDカード識別モデルは、テーブル内のid_cardという名前のフィールドを識別し、フィールドはIDカードのデータカテゴリでタグ付けされます。
識別結果
各フィールドは、複数の識別結果に対応し得る。 例えば、携帯電話番号を含むフィールドは、携帯電話番号識別モデルと、識別規則が11桁であるカスタム識別モデルとによって識別することができる。 DMSは、フィールドの識別結果を最大3つ保存します。
DMSは、さまざまな組み込み識別モデルを提供します。 カスタム識別モデルを作成することもできます。 カスタム識別モデルは、データコンテンツ識別のみをサポートします。
識別モデルを有効または無効にできます。 デフォルトでは、識別モデルを作成すると、モデルが有効になります。 DMSは、有効になっている識別モデルのみを識別に使用できます。
分類とグレーディングベースのスキャン
分類およびグレーディングベースのスキャンでは、DMSはスキャンするフィールドを分類ルールと1つずつ照合します。 フィールドが分類ルールの条件を満たす場合、フィールドには対応するデータカテゴリがタグ付けされます。
原理
DMSは、分類およびグレーディングテンプレートで有効になっているすべての分類ルールをフィルタリングし、各分類ルールを使用して次の3つの手順で識別します。
識別モデルのスキャン結果に基づいて、分類ルールにフィールドに対応する識別モデルが含まれているかどうかを判断します。
例えば、フィールドに対応する識別モデルが識別モデルaおよび識別モデルBであり、分類ルールに対して指定された識別モデルが識別モデルBおよび識別モデルCである場合、DMSは、識別モデルの共通部分、すなわち識別モデルBを識別する。この場合、DMSはまた、この分類規則がフィールドの識別モデルを含むと判定し、識別のために次の分類規則を使用し続ける。 分類ルールがフィールドの識別モデルを含まない場合、識別は失敗し、DMSは識別のために次の分類ルールを使用し続ける。
データベース名、テーブル名、フィールド名、フィールドの説明など、フィールドのメタデータに基づいて識別範囲を決定します。
このステップでは、DMSは、フィールドのデータが分類ルールに指定された識別範囲内にあるかどうかを判断します。 フィールドのデータが分類ルールに対して指定された識別範囲内にある場合、対応するデータカテゴリがフィールドの分類結果に格納され、DMSは識別のために次の分類ルールを使用し続ける。
フィールドにデータカテゴリのタグを付けます。
すべての分類ルールが識別に使用された後、フィールドが1つの分類ルールのみの条件を満たす場合、フィールドには対応するデータカテゴリがタグ付けされます。 フィールドが複数の分類ルールの条件を満たす場合、DMSは、セキュリティレベルに基づいて分類ルールを昇順でソートし、セキュリティレベルが最も高い分類ルールに対応するデータカテゴリをフィールドにタグ付けします。
次の図は、分類およびグレーディングフィーチャが1つのフィールドをスキャンする方法を示しています。

識別ルールに関連するパラメータ
分類およびグレーディングベースのスキャンを実行する前に、分類およびグレーディングテンプレートのカスタム識別ルールを作成できます。 次のセクションでは、識別ルールを作成するときに設定できるパラメーターについて説明します。
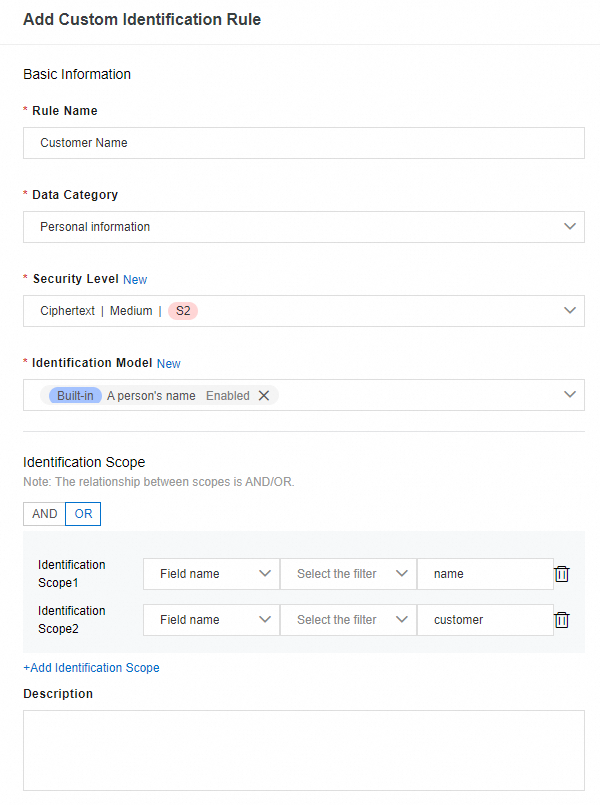
セキュリティレベル: フィールドのセキュリティレベル。 このパラメーターは、ビジネス要件に基づいて設定できます。 セキュリティレベルが高いほど、フィールドの機密性が高く重要であることを示します。 詳細については、「フィールドセキュリティレベル」をご参照ください。
識別モデル: この識別ルールに使用する基本的な識別モデル。 複数の識別モデルを選択できます。 選択したモデル間の論理関係はORです。 例えば、フィールドが選択された識別モデルの1つにヒットした場合、フィールドはこの識別規則によって検出される。
識別範囲: このパラメーターを設定して、メタデータをフィルタリングできます。 有効な値はANDとORです。 ANDを選択すると、メタデータが指定されたすべてのスコープの条件を満たすフィールドが検出されます。 ORを選択すると、メタデータが指定されたスコープのいずれかの条件を満たすフィールドが検出されます。