このトピックでは、ノードの診断手順とノード例外のトラブルシューティング方法について説明します。また、ノードに関するよくある質問 (FAQ) への回答も提供します。
目次
カテゴリ | コンテンツ |
診断手順 | |
一般的なトラブルシューティング方法 | |
一般的な問題と解決策 |
|
診断手順
ノードに異常がないか確認します。詳細については、このトピックのノードの状態を確認するセクションをご参照ください。
ノードが [NotReady] 状態の場合、次の手順を実行して問題をトラブルシューティングします。
次のノード条件の値が [True] であるかどうかを確認します。PIDPressure、DiskPressure、MemoryPressure。ノード条件のいずれかが [True] の場合、ノード条件のキーワードに基づいて問題をトラブルシューティングします。詳細については、このトピックのdockerd の例外 - RuntimeOffline、メモリリソースが不足している - MemoryPressure、またはiノードが不足している - InodesPressure セクションをご参照ください。
ノードの主要コンポーネントとログを確認します。
kubelet
kubelet の状態、ログ、および構成を確認します。詳細については、このトピックのノードの主要コンポーネントを確認するセクションをご参照ください。
kubelet で例外が発生した場合、例外をトラブルシューティングします。詳細については、このトピックのkubelet の例外セクションをご参照ください。
dockerd
dockerd の状態、ログ、および構成を確認します。詳細については、このトピックのノードの主要コンポーネントを確認するセクションをご参照ください。
dockerd で例外が発生した場合、例外をトラブルシューティングします。詳細については、このトピックのdockerd の例外 - RuntimeOfflineセクションをご参照ください。
containerd
containerd の状態、ログ、および構成を確認します。詳細については、このトピックのノードの主要コンポーネントを確認するセクションをご参照ください。
containerd で例外が発生した場合、例外をトラブルシューティングします。詳細については、このトピックのcontainerd の例外 - RuntimeOfflineセクションをご参照ください。
NTP
Network Time Protocol (NTP) サービスの状態、ログ、および構成を確認します。詳細については、このトピックのノードの主要コンポーネントを確認するセクションをご参照ください。
NTP サービスで例外が発生した場合、例外をトラブルシューティングします。詳細については、このトピックのNTP の例外 - NTPProblemセクションをご参照ください。
ノードの診断ログを収集して確認します。詳細については、このトピックのノードの診断ログを収集するセクションをご参照ください。
CPU、メモリ、ネットワークリソースの使用状況など、ノードのモニタリングデータを確認します。詳細については、このトピックのノードのモニタリングデータを確認するセクションをご参照ください。リソース使用率が異常な場合は、例外をトラブルシューティングします。詳細については、このトピックのCPU リソースが不足しているまたはメモリリソースが不足している - MemoryPressureセクションをご参照ください。
ノードが [Unknown] 状態の場合、次の手順を実行して問題をトラブルシューティングします。
ノードをホストしている Elastic Compute Service (ECS) インスタンスが [Running] 状態であるかどうかを確認します。
ノードの主要コンポーネントを確認します。
kubelet
kubelet の状態、ログ、および構成を確認します。詳細については、このトピックのノードの主要コンポーネントを確認するセクションをご参照ください。
kubelet で例外が発生した場合、例外をトラブルシューティングします。詳細については、このトピックのkubelet の例外セクションをご参照ください。
dockerd
dockerd の状態、ログ、および構成を確認します。詳細については、このトピックのノードの主要コンポーネントを確認するセクションをご参照ください。
dockerd で例外が発生した場合、例外をトラブルシューティングします。詳細については、このトピックのdockerd の例外 - RuntimeOfflineセクションをご参照ください。
containerd
containerd の状態、ログ、および構成を確認します。詳細については、このトピックのノードの主要コンポーネントを確認するセクションをご参照ください。
containerd で例外が発生した場合、例外をトラブルシューティングします。詳細については、このトピックのcontainerd の例外 - RuntimeOfflineセクションをご参照ください。
NTP
NTP サービスの状態、ログ、および構成を確認します。詳細については、このトピックのノードの主要コンポーネントを確認するセクションをご参照ください。
NTP サービスで例外が発生した場合、例外をトラブルシューティングします。詳細については、このトピックのNTP の例外 - NTPProblemセクションをご参照ください。
ノードのネットワーク接続を確認します。詳細については、このトピックのノードのセキュリティグループを確認するセクションをご参照ください。ネットワーク例外が発生した場合、例外をトラブルシューティングします。詳細については、このトピックのネットワーク例外セクションをご参照ください。
ノードの診断ログを収集して確認します。詳細については、このトピックのノードの診断ログを収集するセクションをご参照ください。
CPU、メモリ、ネットワークリソースの使用状況など、ノードのモニタリングデータを確認します。詳細については、このトピックのノードのモニタリングデータを確認するセクションをご参照ください。リソース使用率が異常な場合は、例外をトラブルシューティングします。詳細については、このトピックのCPU リソースが不足しているまたはメモリリソースが不足している - MemoryPressureセクションをご参照ください。
上記の手順を実行した後も問題が解決しない場合は、Container Service for Kubernetes (ACK) が提供する診断機能を使用して問題をトラブルシューティングします。詳細については、このトピックのノード診断機能を使用する セクションをご参照ください。
一般的なトラブルシューティング方法
ノード診断機能を使用する
ノードで例外が発生した場合、ACK が提供する診断機能を使用して例外をトラブルシューティングできます。
ACK コンソール にログインします。左側のナビゲーションウィンドウで、[クラスタ] をクリックします。
[クラスタ] ページで、変更するクラスタの名前をクリックします。左側のナビゲーションウィンドウで、 を選択します。
[ノード] ページで、ターゲットノードを見つけ、[アクション] 列で を選択します。
表示されたパネルで、 [診断の作成] をクリックし、コンソールページで診断結果と対応する修復の提案を表示します。
ノードの詳細を確認する
ACK コンソール にログインします。左側のナビゲーションウィンドウで、[クラスタ] をクリックします。
[クラスタ] ページで、変更するクラスタの名前をクリックします。左側のナビゲーションウィンドウで、 を選択します。
[ノード] ページで、確認するノードを見つけて、ノードの名前をクリックするか、[アクション] 列の [詳細] をクリックします。
ノードの状態を確認する
ACK コンソール にログインします。左側のナビゲーションウィンドウで、[クラスタ] をクリックします。
[クラスタ] ページで、変更するクラスタの名前をクリックします。左側のナビゲーションウィンドウで、 を選択します。
[ノード] ページで、各ノードの状態を表示します。
ノードが [Ready] 状態の場合、ノードは正常に実行されています。
ノードが [Ready] 状態ではない場合、ノードの名前をクリックするか、ノードの [アクション] 列の [詳細] をクリックして、ノードの詳細を表示できます。
説明InodesPressure、DockerOffline、RuntimeOffline などのノード条件に関する情報を収集する場合は、クラスタに node-problem-detector をインストールし、イベントセンターを作成する必要があります。イベントセンター機能は、クラスタの作成時に自動的に有効になります。詳細については、イベントセンターを作成して使用する をご参照ください。
ノードイベントを確認する
ACK コンソール にログインします。左側のナビゲーションウィンドウで、[クラスタ] をクリックします。
[クラスタ] ページで、変更するクラスタの名前をクリックします。左側のナビゲーションウィンドウで、 を選択します。
[ノード] ページで、ターゲットノードを見つけ、ノード名をクリックするか、[アクション] 列の [詳細] をクリックします。
ノードの詳細ページの下部に、ノードに関連するイベントが表示されます。
ノードの診断ログを収集する
コンソールの Container Intelligence Service が提供するノード診断機能を使用して、診断ログを収集します。詳細については、ノード診断 をご参照ください。
スクリプトを使用して診断ログを収集します。詳細については、「クラスタ管理に関する FAQ」トピックの Kubernetes クラスタの診断情報を収集するにはどうすればよいですか? セクションをご参照ください。
ノードの主要コンポーネントを確認する
kubelet:
kubelet の状態を確認する
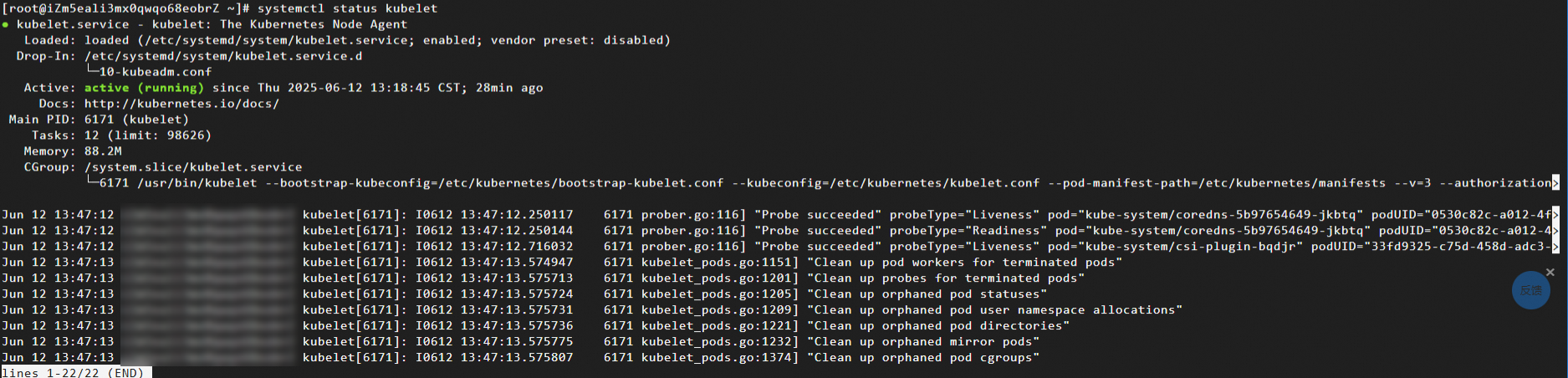
kubelet が実行されているノードにログインし、次のコマンドを実行して kubelet プロセスの状態をクエリします。
systemctl status kubelet期待される出力:
kubelet のログを確認する
kubelet が実行されているノードにログインし、次のコマンドを実行して kubelet のログを出力します。kubelet のログを確認する方法の詳細については、このトピックの ノードの診断ログを収集する セクションをご参照ください。
journalctl -u kubeletkubelet の構成を確認する
kubelet が実行されているノードにログインし、次のコマンドを実行して kubelet の構成を確認します。
cat /etc/systemd/system/kubelet.service.d/10-kubeadm.conf
ランタイム:
dockerd を確認する
dockerd の状態を確認する
dockerd が実行されているノードにログインし、次のコマンドを実行して dockerd プロセスの状態をクエリします。
systemctl status docker期待される出力:

dockerd のログを確認する
dockerd が実行されているノードにログインし、次のコマンドを実行して dockerd のログを出力します。dockerd のログを確認する方法の詳細については、このトピックの ノードの診断ログを収集する セクションをご参照ください。
journalctl -u dockerdockerd の構成を確認する
dockerd が実行されているノードにログインし、次のコマンドを実行して dockerd の構成をクエリします。
cat /etc/docker/daemon.json
containerd を確認する
containerd の状態を確認する
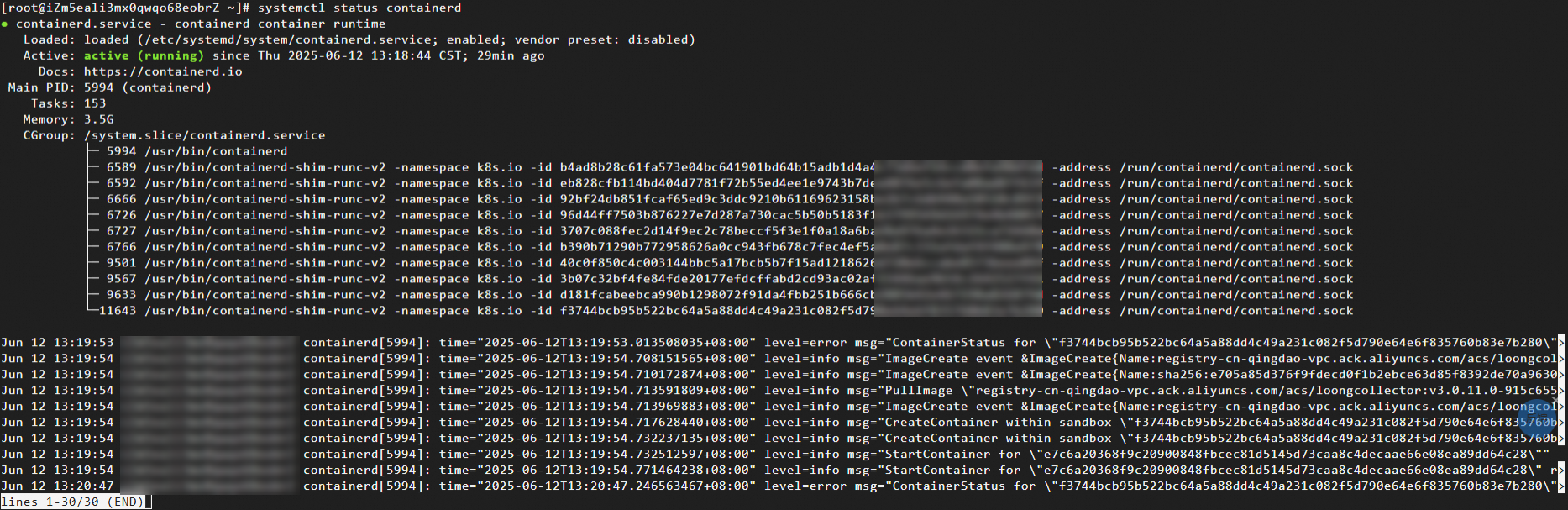
containerd が実行されているノードにログインし、次のコマンドを実行して containerd プロセスの状態をクエリします。
systemctl status containerd期待される出力:
containerd のログを確認する
containerd が実行されているノードにログインし、次のコマンドを実行して containerd のログを出力します。containerd のログを確認する方法の詳細については、このトピックの ノードの診断ログを収集する セクションをご参照ください。
journalctl -u containerd
NTP:
NTP サービスの状態を確認する
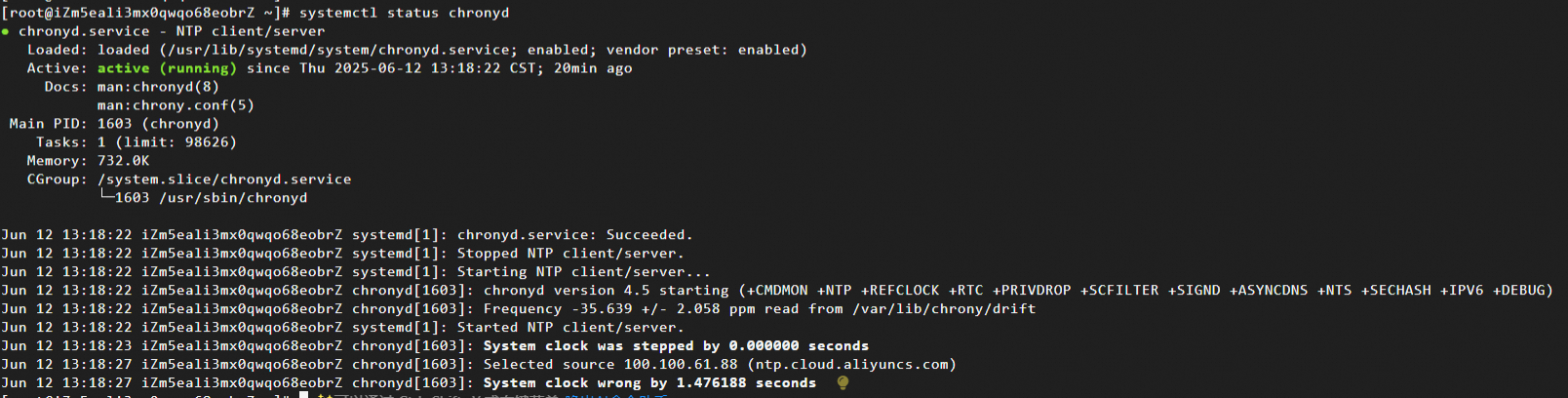
NTP サービスが実行されているノードにログインし、次のコマンドを実行して chronyd プロセスの状態をクエリします。
systemctl status chronyd期待される出力:
NTP サービスのログを確認する
NTP サービスが実行されているノードにログインし、次のコマンドを実行して NTP サービスのログを出力します。
journalctl -u chronyd
ノードのモニタリングデータを確認する
[CloudMonitor]
ACK は CloudMonitor と統合されています。 CloudMonitor コンソールにログインして、ACK クラスタにデプロイされている ECS インスタンスのモニタリングデータを表示できます。ノードを監視する方法の詳細については、ノードを監視する をご参照ください。
[Managed Service For Prometheus]
ACK コンソール にログインします。左側のナビゲーションウィンドウで、[クラスタ] をクリックします。
[クラスタ] ページで、目的のクラスタを見つけて名前をクリックします。左側のウィンドウで、 を選択します。
[Prometheus モニタリング] ページで、[ノードモニタリング] タブをクリックし、[ノード] タブをクリックします。
[ノード] タブで、ドロップダウンリストからノードを選択して、CPU、メモリ、ディスクリソースなどのノードのモニタリングデータを表示します。
ノードのセキュリティグループを確認する
詳細については、概要 および クラスタのセキュリティグループを構成する をご参照ください。
kubelet の例外
原因
kubelet の例外は、通常、kubelet プロセス自体、コンテナランタイム、または無効な kubelet 構成の問題が原因で発生します。
問題
kubelet の状態は [inactive] です。
解決策
次のコマンドを実行して kubelet を再起動します。再起動操作は、実行中のコンテナには影響しません。
systemctl restart kubeletkubelet の再起動後、kubelet が実行されているノードにログインし、次のコマンドを実行して kubelet の状態が正常かどうかを確認します。
systemctl status kubeletkubelet の状態が異常な場合は、ノードで次のコマンドを実行して kubelet のログを出力します。
journalctl -u kubeletkubelet ログに例外が見つかった場合は、キーワードに基づいて例外をトラブルシューティングします。
kubelet の構成が無効な場合は、次のコマンドを実行して構成を変更します。
vi /etc/systemd/system/kubelet.service.d/10-kubeadm.conf # kubelet の構成を変更します。 systemctl daemon-reload;systemctl restart kubelet # 構成をリロードして kubelet を再起動します。
dockerd の例外 - RuntimeOffline
原因
ほとんどの場合、dockerd の例外は、dockerd の構成が無効であるか、dockerd プロセスが過負荷になっているか、ノードが過負荷になっていることが原因で発生します。
問題
dockerd の状態は [inactive] です。
dockerd の状態は [active (running)] ですが、dockerd は予期したとおりに実行されていません。その結果、ノードで例外が発生します。この場合、
docker psまたはdocker execコマンドの実行に失敗する可能性があります。ノード条件 [RuntimeOffline] の値は [True] です。
クラスタノードのアラート機能を有効にしている場合、dockerd が実行されているノードで例外が発生したときにアラートを受信できます。アラートルールの構成方法の詳細については、アラート管理 をご参照ください。
解決策
次のコマンドを実行して dockerd を再起動します。
systemctl restart dockerdockerd の再起動後、ノードにログインし、次のコマンドを実行して dockerd の状態が正常かどうかを確認します。
systemctl status dockerdockerd の状態が異常な場合は、ノードで次のコマンドを実行して dockerd のログを出力します。
journalctl -u docker
containerd の例外 - RuntimeOffline
原因
ほとんどの場合、containerd の例外は、containerd の構成が無効であるか、containerd プロセスが過負荷になっているか、ノードが過負荷になっていることが原因で発生します。
containerd の状態は [inactive] です。
ノード条件 [RuntimeOffline] の値は [True] です。
クラスタノードのアラート機能を有効にしている場合、containerd が実行されているノードで例外が発生したときにアラートを受信できます。アラートルールの構成方法の詳細については、アラート管理 をご参照ください。
解決策
次のコマンドを実行して containerd を再起動します。
systemctl restart containerdcontainerd の再起動後、ノードにログインし、次のコマンドを実行して containerd の状態が正常かどうかを確認します。
systemctl status containerdcontainerd の状態が異常な場合は、ノードで次のコマンドを実行して containerd のログを出力します。
journalctl -u containerd
NTP の例外 - NTPProblem
原因
ほとんどの場合、NTP の例外は、NTP プロセスの状態が異常であることが原因で発生します。
問題
chronyd の状態は [inactive] です。
ノード条件 [NTPProblem] の値は [True] です。
クラスタノードのアラート機能を有効にしている場合、NTP サービスが実行されているノードで例外が発生したときにアラートを受信できます。アラートルールの構成方法の詳細については、アラート管理 をご参照ください。
解決策
次のコマンドを実行して chronyd を再起動します。
systemctl restart chronydchronyd の再起動後、ノードにログインし、次のコマンドを実行して chronyd の状態が正常かどうかを確認します。
systemctl status chronydchronyd の状態が異常な場合は、ノードで次のコマンドを実行して chronyd のログを出力します。
journalctl -u chronyd
PLEG の例外 - PLEG が正常でない
原因
Pod Lifecycle Event Generator (PLEG) は、コンテナの起動や終了に関連するイベントなど、ポッドのライフサイクル全体で発生するすべてのイベントを記録します。ほとんどの場合、PLEG is not healthy 例外は、ノードのコンテナランタイムが異常であるか、ノードが以前の systemd バージョンを使用していることが原因で発生します。
問題
ノードの状態は [NotReady] です。
kubelet のログに次のコンテンツが存在します。
I0729 11:20:59.245243 9575 kubelet.go:1823] skipping pod synchronization - PLEG is not healthy: pleg was last seen active 3m57.138893648s ago; threshold is 3m0s.クラスタノードのアラート機能を有効にしている場合、PLEG 例外が発生したときにアラートを受信できます。アラートルールの構成方法の詳細については、アラート管理 をご参照ください。
解決策
ノードの次の主要コンポーネントを順番に再起動します。dockerd/containerd および kubelet。次に、ノードの状態が正常かどうかを確認します。
主要コンポーネントを再起動した後もノードの状態が異常な場合は、ノードを再起動します。詳細については、インスタンスを再起動する をご参照ください。
警告再起動操作では、ノード上のポッドも再起動されます。注意して進めてください。
異常なノードが CentOS 7.6 を実行している場合は、What Can I Do if the Logs of the kubelet Contain the "Reason:KubeletNotReady Message:PLEG is not healthy:" error When CentOS 7.6 Is Used を参照して例外をトラブルシューティングします。
スケジューリングに十分なノードリソースがない
原因
この問題は、通常、クラスタ内のノードに、新しいポッドのスケジューリング要求を満たすのに十分なリソースがない場合に発生します。
問題
クラスタ内のノードによって提供されるリソースが不足している場合、ポッドのスケジューリングは失敗し、次のいずれかのエラーが返されます。
CPU リソースが不足している: [0/2 Nodes Are Available: 2 Insufficient Cpu]
メモリリソースが不足している: [0/2 Nodes Are Available: 2 Insufficient Memory]
一時ストレージリソースが不足している: [0/2 Nodes Are Available: 2 Insufficient Ephemeral-storage]
スケジューラは、次のルールに基づいて、ノードによって提供されるリソースが不足しているかどうかを判断します。
CPU が不足している:ポッドの要求 CPU > (ノードの割り当て可能 CPU - ノードのすでに割り当てられた CPU)
メモリが不足している:ポッドの要求メモリ > (ノードの割り当て可能メモリ - ノードのすでに割り当てられたメモリ)
一時ストレージが不足している:ポッドの要求一時ストレージ > (ノードの割り当て可能一時ストレージ - ノードのすでに割り当てられた一時ストレージ)
ポッドによって要求されるリソース量が、ノードによって提供される割り当て可能リソースの総量とノードから割り当てられたリソース量の差よりも大きい場合、ポッドはそのノードにスケジュールされません。
次のコマンドを実行して、ノードのリソース割り当てに関する情報をクエリします。
kubectl describe node [$nodeName]期待される出力:
Allocatable:
cpu: 3900m
ephemeral-storage: 114022843818
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 12601Mi
pods: 60
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
Resource Requests Limits
-------- -------- ------
cpu 725m (18%) 6600m (169%)
memory 977Mi (7%) 16640Mi (132%)
ephemeral-storage 0 (0%) 0 (0%)
hugepages-1Gi 0 (0%) 0 (0%)
hugepages-2Mi 0 (0%) 0 (0%)パラメータ:
割り当て可能: ノードによって提供される割り当て可能な CPU、メモリ、または一時ストレージリソースの量。
割り当て済みリソース: ノードから割り当てられた CPU、メモリ、または一時ストレージリソースの量。
解決策
ノードによって提供されるリソースが不足している場合は、次のいずれかの方法を使用してノードの負荷を軽減できます。
不要になったポッドを削除します。詳細については、ポッドを管理する をご参照ください。
ビジネス要件に基づいて、ポッドのリソース構成を変更します。詳細については、「ポッドを管理する」トピックの ポッドの CPU とメモリリソースの上限と下限を変更する セクションをご参照ください。
リソースプロファイリング機能は、リソース使用量の既存データに基づいて、コンテナのリソース仕様の推奨事項を提供できます。これにより、コンテナのリソース要求と制限の構成が大幅に簡素化されます。詳細については、リソースプロファイリング をご参照ください。
クラスタにノードを追加します。詳細については、ノードプールを作成および管理する をご参照ください。
クラスタ内のノードをアップグレードします。詳細については、ワーカーノードの構成をアップグレードまたはダウングレードする をご参照ください。
詳細については、このトピックの CPU リソースが不足している、メモリリソースが不足している - MemoryPressure、および ディスク容量が不足している - DiskPressure セクションをご参照ください。
CPU リソースが不足している
原因
ほとんどの場合、ノードによって提供される CPU リソースが不足するのは、ノード上のコンテナが過剰な量の CPU リソースを占有していることが原因です。
問題
ノードに十分な CPU リソースがない場合、ノードの状態が異常になる可能性があります。
クラスタノードのアラート機能を有効にしている場合、ノードの CPU 使用率が 85% 以上に達したときにアラートを受信できます。アラートルールの構成方法の詳細については、アラート管理 をご参照ください。
解決策
コンソールの [ノードモニタリング] タブで CPU 使用率曲線を確認し、CPU 使用率が急上昇した時点を特定します。次に、ノードで実行されているプロセスが過剰な量の CPU リソースを占有しているかどうかを確認します。詳細については、このトピックの ノードのモニタリングデータを確認する セクションをご参照ください。
ノードの負荷を軽減する方法の詳細については、このトピックの スケジューリングに十分なノードリソースがない セクションをご参照ください。
ノードを再起動します。詳細については、インスタンスを再起動する をご参照ください。
警告再起動操作では、ノード上のポッドも再起動されます。注意して進めてください。
メモリリソースが不足している - MemoryPressure
原因
ほとんどの場合、ノードによって提供されるメモリリソースが不足するのは、ノード上のコンテナが過剰な量のメモリリソースを占有していることが原因です。
問題
ノード上の使用可能なメモリリソースの量が
memory.availableしきい値を下回ると、ノード条件 [MemoryPressure] の値が [True] に変わります。コンテナはノードからエビクトされます。コンテナエビクションの詳細については、Node-pressure Eviction をご参照ください。ノードに十分なメモリリソースがない場合、次の問題が発生します。
ノード条件 [MemoryPressure] の値が [True] に変わります。
コンテナはノードからエビクトされます。
エビクトされたコンテナのイベントで [The Node Was Low On Resource: Memory] 情報を見つけることができます。
ノードのイベントで [attempting To Reclaim Memory] 情報を見つけることができます。
メモリ不足 (OOM) エラーが発生する可能性があります。OOM エラーが発生した場合、ノードのイベントで [System OOM] 情報を見つけることができます。
クラスタノードのアラート機能を有効にしている場合、ノードのメモリ使用率が 85% 以上に達したときにアラートを受信できます。アラートルールの構成方法の詳細については、アラート管理 をご参照ください。
解決策
コンソールの [ノードモニタリング] タブでメモリ使用率曲線を確認し、メモリ使用率が急上昇した時点を特定します。次に、ノードで実行されているプロセスでメモリリークが発生しているかどうかを確認します。詳細については、このトピックの ノードのモニタリングデータを確認する セクションをご参照ください。
ノードの負荷を軽減する方法の詳細については、このトピックの スケジューリングに十分なノードリソースがない セクションをご参照ください。
ノードを再起動します。詳細については、インスタンスを再起動する をご参照ください。
警告再起動操作では、ノード上のポッドも再起動されます。注意して進めてください。
iノードが不足している - InodesPressure
原因
ほとんどの場合、ノードによって提供される iノードが不足するのは、ノード上のコンテナが過剰な数の iノードを占有していることが原因です。
問題
ノード上の使用可能な iノードの数が
inodesFreeしきい値を下回ると、ノード条件 [InodesPressure] の値が [True] に変わります。コンテナはノードからエビクトされます。コンテナエビクションの詳細については、Node-pressure Eviction をご参照ください。ノードによって提供される iノードが不足すると、次の問題が発生します。
ノード条件 [InodesPressure] の値が [True] に変わります。
コンテナはノードからエビクトされます。
エビクトされたコンテナのイベントで [The Node Was Low On Resource: Inodes] 情報を見つけることができます。
ノードのイベントで [attempting To Reclaim Inodes] 情報を見つけることができます。
クラスタノードのアラート機能を有効にしている場合、ノードに十分な iノードがないときにアラートを受信できます。アラートルールの構成方法の詳細については、アラート管理 をご参照ください。
解決策
コンソールの [ノードモニタリング] タブで iノード使用率曲線を確認し、iノード使用率が急上昇した時点を特定します。次に、ノードで実行されているプロセスが過剰な数の iノードを占有しているかどうかを確認します。詳細については、このトピックの ノードのモニタリングデータを確認する セクションをご参照ください。
その他の問題のトラブルシューティング方法の詳細については、Linux インスタンスのディスク容量不足の問題を解決する をご参照ください。
PID が不足している - NodePIDPressure
原因
ほとんどの場合、ノードによって提供されるプロセス ID (PID) が不足するのは、ノード上のコンテナが過剰な数の PID を占有していることが原因です。
問題
ノード上の使用可能な PID の数が
pid.availableしきい値を下回ると、ノード条件 [NodePIDPressure] の値が [True] に変わります。コンテナはノードからエビクトされます。コンテナエビクションの詳細については、Node-pressure Eviction をご参照ください。クラスタノードのアラート機能を有効にしている場合、ノードに十分な PID がないときにアラートを受信できます。アラートルールの構成方法の詳細については、アラート管理 をご参照ください。
解決策
次のコマンドを実行して、ノードの PID の最大数と最大の PID 値をクエリします。
sysctl kernel.pid_max # PID の最大数をクエリします。 ps -eLf|awk '{print $2}' | sort -rn| head -n 1 # 最大の PID 値をクエリします。次のコマンドを実行して、最も多くの PID を占有している上位 5 つのプロセスをクエリします。
ps -elT | awk '{print $4}' | sort | uniq -c | sort -k1 -g | tail -5期待される出力:
# 最初の列には、プロセスによって占有されている PID の数が表示されます。2 番目の列には、プロセスの ID が表示されます。 73 9743 75 9316 76 2812 77 5726 93 5691プロセス ID を使用して、対応するプロセスとポッドを見つけ、問題を診断し、コードを最適化できます。
ノードの負荷を軽減します。詳細については、このトピックの スケジューリングに十分なノードリソースがない セクションをご参照ください。
ノードを再起動します。詳細については、インスタンスを再起動する をご参照ください。
警告再起動操作では、ノード上のポッドも再起動されます。注意して進めてください。
ディスク容量が不足している - DiskPressure
原因
ほとんどの場合、ノードによって提供されるディスク容量が不足するのは、ノード上のコンテナが過剰な量のディスク容量を占有しているか、コンテナイメージのサイズが過度に大きいことが原因です。
問題
ノード上の使用可能なディスク容量が
imagefs.availableしきい値を下回ると、ノード条件 [DiskPressure] の値が [True] に変わります。使用可能なディスク容量が
nodefs.availableしきい値を下回ると、ノード上のすべてのコンテナがエビクトされます。コンテナエビクションの詳細については、Node-pressure Eviction をご参照ください。ノードのディスク容量が不足すると、次の問題が発生します。
ノード条件 [DiskPressure] の値が [True] に変わります。
イメージ再利用ポリシーがトリガーされた後も、使用可能なディスク容量が正常なしきい値よりも低いままの場合、ノードのイベントで [failed To Garbage Collect Required Amount Of Images] 情報を見つけることができます。正常なしきい値のデフォルト値は 80% です。
コンテナはノードからエビクトされます。
エビクトされたコンテナのイベントで [The Node Was Low On Resource: [DiskPressure]] 情報を見つけることができます。
ノードのイベントで [attempting To Reclaim Ephemeral-storage] または [attempting To Reclaim Nodefs] 情報を見つけることができます。
クラスタノードのアラート機能を有効にしている場合、ノードのディスク使用率が 85% 以上に達したときにアラートを受信できます。アラートルールの構成方法の詳細については、アラート管理 をご参照ください。
解決策
コンソールの [ノードモニタリング] タブでディスク使用率曲線を確認し、ディスク使用率が急上昇した時点を特定します。次に、ノードで実行されているプロセスが過剰な量のディスク容量を占有しているかどうかを確認します。詳細については、このトピックの ノードのモニタリングデータを確認する セクションをご参照ください。
多数のファイルがディスク容量を占有している場合は、不要になったファイルを削除します。詳細については、Linux インスタンスのディスク容量不足の問題を解決する をご参照ください。
ノード上のポッドに割り当てられる
一時ストレージを制限します。詳細については、「ポッドを管理する」トピックの ポッドの CPU とメモリリソースの上限と下限を変更する セクションをご参照ください。Alibaba Cloud が提供するストレージサービスを使用し、hostPath ボリュームを使用しないことをお勧めします。詳細については、ストレージ をご参照ください。
ノードのディスクのサイズを変更します。
ノードの負荷を軽減します。詳細については、このトピックの スケジューリングに十分なノードリソースがない セクションをご参照ください。
IP アドレスが不足している - InvalidVSwitchId.IpNotEnough
原因
ほとんどの場合、ノードによって提供される IP アドレスが不足するのは、ノード上のコンテナが過剰な数の IP アドレスを占有していることが原因です。
問題
ポッドを起動できません。これらのポッドの状態は [ContainerCreating] です。ポッドのログで [InvalidVSwitchId.IpNotEnough] 情報を見つけることができます。ポッドのログを確認する方法の詳細については、「ポッドのトラブルシューティング」トピックの ポッドの問題をトラブルシューティングする セクションをご参照ください。
time="2020-03-17T07:03:40Z" level=warning msg="Assign private ip address failed: Aliyun API Error: RequestId: 2095E971-E473-4BA0-853F-0C41CF52651D Status Code: 403 Code: InvalidVSwitchId.IpNotEnough Message: The specified VSwitch \"vsw-AAA\" has not enough IpAddress., retrying"クラスタノードのアラート機能を有効にしている場合、ノードが十分な IP アドレスを提供できないときにアラートを受信できます。アラートルールの構成方法の詳細については、アラート管理 をご参照ください。
解決策
ノード上のコンテナの数を減らします。詳細については、このトピックの スケジューリングに十分なノードリソースがない セクションをご参照ください。その他の関連操作の詳細については、What Can I Do if Insufficient IP Addresses are Provided by a vSwitch in a Cluster that Uses Terway? および vSwitch をスケールアウトした後も Terway ネットワークモードでポッド IP を割り当てることができない場合はどうすればよいですか? をご参照ください。
ネットワーク例外
原因
ほとんどの場合、ネットワーク例外は、ノードの状態が異常であるか、ノードのセキュリティグループの構成が無効であるか、ネットワークが過負荷になっていることが原因で発生します。
問題
ノードにログインできませんでした。
ノードの状態は [Unknown] です。
クラスタノードのアラート機能を有効にしている場合、ノードのアウトバウンドインターネット帯域幅の使用率が 85% 以上に達したときにアラートを受信できます。アラートルールの構成方法の詳細については、アラート管理 をご参照ください。
解決策
ノードにログインできなかった場合は、次の手順を実行して問題をトラブルシューティングします。
ノードが [Running] 状態であるかどうかを確認します。
ノードのセキュリティグループの構成を確認します。詳細については、このトピックの ノードのセキュリティグループを確認する セクションをご参照ください。
ノードのネットワークが過負荷になっている場合は、次の手順を実行して問題をトラブルシューティングします。
コンソールの [ノードモニタリング] タブでノードのネットワークパフォーマンス曲線を確認し、帯域幅使用率の急上昇を探します。詳細については、このトピックの ノードのモニタリングデータを確認する セクションをご参照ください。
ネットワークポリシーを使用して、ポッドトラフィックを調整します。詳細については、ACK クラスタでネットワークポリシーを使用する をご参照ください。
予期しないノードの再起動
原因
ほとんどの場合、ノードが予期せず再起動するのは、ノードが過負荷になっていることが原因です。
問題
ノードの再起動プロセス中、ノードの状態は [NotReady] です。
クラスタノードのアラート機能を有効にしている場合、ノードが予期せず再起動したときにアラートを受信できます。アラートルールの構成方法の詳細については、アラート管理 をご参照ください。
解決策
次のコマンドを実行して、ノードが再起動した時点をクエリします。
last reboot期待される出力:

ノードのモニタリングデータを確認し、ノードが再起動した時点に基づいて異常なリソース使用状況をトラブルシューティングします。詳細については、このトピックの ノードのモニタリングデータを確認する セクションをご参照ください。
ノードのカーネルログを確認し、ノードが再起動した時点に基づいて例外をトラブルシューティングします。詳細については、このトピックの ノードの診断ログを収集する セクションをご参照ください。
auditd による高ディスク I/O またはシステムログに次のエラーメッセージが表示される問題を解決するにはどうすればよいですか?: audit: backlog limit exceeded?
原因
クラスタ内の一部の既存ノードは、デフォルトで Docker の auditd の監査ルールで構成されています。ノードが Docker を実行している場合、システムは auditd の監査ルールに基づいて Docker の監査ログを生成します。多数のコンテナが同時に繰り返し再起動したり、大量のデータがコンテナに書き込まれたり、カーネルバグが発生したりすると、多数の監査ログが生成される可能性があります。このような場合、auditd プロセスのディスク I/O 使用率が高くなり、システムログに次のエラーメッセージが表示されることがあります。 [audit: Backlog Limit Exceeded]。
問題
この問題は、Docker を実行しているノードにのみ影響します。ノードで特定のコマンドを実行した後に、次の状況が発生します。
iotop -o -d 1 コマンドを実行した後、結果は
DISK WRITEの値が 1MB/s 以上を維持していることを示しています。dmesg -d コマンドを実行した後、結果には次のキーワードを含むログが含まれています。
audit_printk_skb。例:audit_printk_skb: 100 callbacks suppressed。dmesg -d コマンドを実行した後、結果には次のキーワードが含まれています。
audit: backlog limit exceeded。
解決策
次の操作を実行して、前述の問題が auditd の監査ルールによって引き起こされているかどうかを確認します。
ノードにログインします。
次のコマンドを実行して、auditd ルールをクエリします。
sudo auditctl -l | grep -- ' -k docker'次の出力が返された場合、前述の問題は auditd の監査ルールによって引き起こされています。
-w /var/lib/docker -k docker
この問題を解決するには、次のいずれかの解決策を使用します。
クラスタをアップグレードする
クラスタの Kubernetes バージョンをアップグレードします。詳細については、クラスタを手動でアップグレードする をご参照ください。
コンテナランタイムを containerd に変更する
クラスタの Kubernetes バージョンを更新できない場合は、コンテナランタイムを containerd に変更して、この問題を防ぐことができます。Docker をコンテナランタイムとして使用するノードプールで次の操作を実行します。
Docker を実行しているノードプールを複製して、新しいノードプールを作成します。新しいノードプールは、containerd をコンテナランタイムとして使用します。コンテナランタイムを除いて、新しいノードプールの構成が複製されたノードプールの構成と同じであることを確認してください。
オフピーク時に、Docker を実行しているノードプールからノードを 1 つずつドレインし、すべてのアプリケーションポッドがノードプールからエビクトされるまで続けます。
auditd の構成を更新する
前述の解決策が適用できない場合は、ノードの auditd の構成を手動で更新して、この問題を解決できます。Docker をコンテナランタイムとして使用するノードで次の操作を実行します。
ノードにログインします。
次のコマンドを実行して、Docker の auditd ルールを削除します。
sudo test -f /etc/audit/rules.d/audit.rules && sudo sed -i.bak '/ -k docker/d' /etc/audit/rules.d/audit.rules sudo test -f /etc/audit/audit.rules && sudo sed -i.bak '/ -k docker/d' /etc/audit/audit.rules次のコマンドを実行して、新しい auditd ルールを適用します。
if service auditd status |grep running || systemctl status auditd |grep running; then sudo service auditd restart || sudo systemctl restart auditd sudo service auditd status || sudo systemctl status auditd fi