デフォルトでは、Horizontal Pod Autoscaler (HPA) はCPUおよびメモリメトリックに基づく自動スケーリングをサポートしています。 しかしながら、これらのメトリックは、複雑な動作シナリオには十分でない。 Managed Service for Prometheusによって収集されたカスタムメトリックと外部メトリックをHPAでサポートされているスケーリングメトリックに変換するには、このトピックを参照して、モニタリングデータを取得し、対応するスケーリング設定を実装する方法について説明します。 このソリューションは、アプリケーションに柔軟で便利なスケーリングメカニズムを提供します。
前提条件
機能
デフォルトでは、HPAはCPUとメモリ使用量に基づくオートスケーリングのみをサポートします。 これはO&M要件を満たすことができません。 Managed Service for Prometheusは、オープンソースのPrometheusエコシステムと連動する完全マネージド型モニタリングサービスです。 Managed Service for Prometheusはさまざまなコンポーネントを監視し、すぐに使用できる複数のダッシュボードを提供します。 Prometheusメトリックに基づく水平ポッド自動スケーリングを有効にするには、次の手順を実行します。
ACKクラスターでManaged Service for Prometheusを使用して、メトリックを公開します。
ack-alibaba-cloud-metrics-adapterを使用して、PrometheusメトリクスをHPAでサポートされているKubernetesメトリクスに変換します。 詳細については、「Kubernetesオブジェクトに関連しないメトリクスの自動スケーリング」をご参照ください。
上記のメトリックに基づいて自動スケーリングを実行するようにHPAを設定してデプロイします。
メトリックは、シナリオに基づいて次のタイプに分類できます。
カスタムメトリック: ポッドなどのKubernetesオブジェクトを、オブジェクトに関連するメトリックに基づいてスケーリングします。 たとえば、ポッドのメトリックに基づいてポッドをスケーリングできます。 詳細については、「複数のメトリクスとカスタムメトリクスの自動スケーリング」をご参照ください。
外部メトリック: ポッドなどのKubernetesオブジェクトを、オブジェクトに関連しないメトリックに基づいてスケーリングします。 たとえば、業務QPSに基づいてワークロードのポッドをスケーリングできます。 詳細については、「Kubernetesオブジェクトに関連しないメトリクスの自動スケーリング」をご参照ください。
次のセクションでは、自動スケーリングのためにPrometheusメトリクスをHPAでサポートされているメトリクスに変換するalibaba-cloud-metrics-adapterを設定する方法について説明します。
ステップ1: プロメテウス指標の収集
例1: 定義済みのメトリックの使用
ACKクラスターにインストールされているManaged Service for Prometheusで使用可能な事前定義されたメトリックに基づいて、自動スケーリングを実行できます。 定義済みのメトリックには、コンテナモニタリング用のcadvisorメトリック、ノードモニタリング用のNode-ExporterおよびGPU-Exporterメトリック、およびManaged Service for Prometheusが提供するすべてのメトリックが含まれます。 Managed Service for Prometheusで定義済みのメトリックを表示するには、次の手順を実行します。
ACKコンソールにログインします。 左側のナビゲーションウィンドウで、[クラスター] をクリックします。
[クラスター] ページで、管理するクラスターの名前をクリックします。 左側のウィンドウで、 を選択します。
右上隅の [Go to ARMS Prometheus] をクリックします。
左側のナビゲーションウィンドウで、[設定] をクリックして、PrometheusのManaged Serviceでサポートされているすべてのメトリックを表示します。
例2: ポッドによって報告されたPrometheusメトリックの使用
テストアプリケーションをデプロイし、オープンソースのPrometheusのメトリック標準に基づいてアプリケーションのメトリックを公開します。 詳細については、「測定タイプ」をご参照ください。 次のセクションでは、sample-appという名前のアプリケーションをデプロイし、アプリケーションに送信されたリクエストの数を示すhttp_requests_totalメトリックを公開する方法について説明します。
アプリケーションのワークロードを展開します。
ACKコンソールにログインします。 左側のナビゲーションウィンドウで、[クラスター] をクリックします。
[クラスター] ページで、管理するクラスターの名前をクリックします。 左側のナビゲーションウィンドウで、 を選択します。
[デプロイメント] ページの上部で、[YAMLから作成] をクリックします。 [作成] ページで、[サンプルテンプレート] ドロップダウンリストから [カスタム] を選択し、次のコンテンツをテンプレートに追加し、[作成] をクリックします。
ServiceMonitorを作成します。
Application Real-Time Monitoring Service (ARMS) コンソールにログインします。
左側のナビゲーションウィンドウで、[統合管理] をクリックします。 ページの上部で、クラスターが存在するリージョンを選択します。
[統合管理] ページの [統合環境] タブで、[コンテナーサービス] タブをクリックします。 [環境名 /ID] 列で、クラスターと同じ名前のPrometheusインスタンスをクリックします。
Container Serviceページで、[メトリックスクレイピング] タブをクリックします。
現在のタブの左側のナビゲーションウィンドウで、[サービスモニター] をクリックします。 [作成] をクリックします。 [ServiceMonitor構成の追加] パネルで、[YAML] をクリックし、ServiceMonitorの次の構成を追加して、[作成] をクリックします。
apiVersion: monitoring.coreos.com/v1 kind: ServiceMonitor metadata: annotations: arms.prometheus.io/discovery: 'true' name: sample-app namespace: default spec: endpoints: - interval: 30s port: http path: /metrics namespaceSelector: any: true selector: matchLabels: app: sample-app
監視状況を確認してください。
インスタンス詳細ページの [セルフモニタリング] タブで、[ターゲット] タブをクリックします。 default/sample-app/0(1/1 up) が表示されている場合、Managed Service for Prometheusがアプリケーションを監視しています。
Prometheusダッシュボードで、一定期間内に
http_requests_totalの値を照会して、モニタリングデータがエラーなしで収集されていることを確認します。
手順2: ack-alibaba-cloud-metrics-adapterの設定を変更する
ACKコンソールにログインします。 左側のナビゲーションウィンドウで、[クラスター] をクリックします。
[クラスター] ページで、管理するクラスターの名前をクリックします。 左側のナビゲーションウィンドウで、 を選択します。
Helmページで、ack-alibaba-cloud-metrics-adapterを見つけ、[操作] 列の [更新] をクリックします。
[リリースの更新] パネルで、次のコンテンツをYAMLエディターに追加し、[OK] をクリックします。
次の表に、いくつかのフィールドを示します。 ack-alibaba-cloud-adapterの設定ファイルの詳細については、このトピックの「ack-alibaba-cloud-metrics-adapterの設定ファイル」をご参照ください。
フィールド
説明
listaCloudMetricsAdapterを使用します。 prometheus.adapter.ru les.customPrometheusメトリクスの変換に使用されるalibaba-cloud-metrics-adapterの設定。 このフィールドを上記のYAMLコンテンツの値に設定します。
alibabaCloudMetricsAdapter. prometheus.urlPrometheusのマネージドサービスのエンドポイント。 エンドポイントを取得する方法の詳細については、このトピックの「Prometheus APIのマネージドサービスのエンドポイントの取得」をご参照ください。
listaCloudMetricsAdapterを使用します。 prometheus.prometheusHeader[].Authorizationトークン。 トークンの取得方法の詳細については、このトピックの「Prometheus APIのマネージドサービスのエンドポイントの取得」をご参照ください。
listaCloudMetricsAdapterを使用します。 prometheus.adapter.rules.de障害事前定義されたメトリックを作成するかどうかを指定します。 デフォルトでは、定義済みのメトリックが作成されます。 デフォルト値
falseを使用することを推奨します。
ack-alibaba-cloud-metrics-adapterを設定します。 ack-alibaba-cloud-metrics-adapterのデプロイ後、次のコマンドを実行して、KubernetesアグリゲーションAPIがデータを収集したかどうかを確認します。
カスタム指標に基づいてポッドをスケーリングします。
次のコマンドを実行して、HPAでサポートされているカスタムメトリクスの詳細を照会します。
kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1/" | jq .次のコマンドを実行して、デフォルトの名前空間の
http_requests_per_secondメトリックの現在の値を照会します。# Query the container_memory_working_set_bytes_per_second metric to view the size of the working memory of the pods in the kube-system namespace per second. kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1/namespaces/kube-system/pods/*/container_memory_working_set_bytes_per_second" # Query the container_cpu_usage_core_per_second metric to view the number of vCores of the pods in the kube-system namespace per second. kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1/namespaces/kube-system/pods/*/container_cpu_usage_core_per_second"サンプル出力:
{ "kind": "MetricValueList", "apiVersion": "custom.metrics.k8s.io/v1beta1", "metadata": { "selfLink": "/apis/custom.metrics.k8s.io/v1beta1/namespaces/kube-system/pods/%2A/container_memory_working_set_bytes_per_second" }, "items": [ { "describedObject": { "kind": "Pod", "namespace": "kube-system", "name": "ack-alibaba-cloud-metrics-adapter-7cf8dcb845-h****", "apiVersion": "/v1" }, "metricName": "container_memory_working_set_bytes_per_second", "timestamp": "2023-08-09T06:30:19Z", "value": "24576k", "selector": null } ] }
外部メトリックに基づいてポッドをスケーリングします。
次のコマンドを実行して、HPAでサポートされている外部メトリックの詳細を照会します。
kubectl get --raw "/apis/external.metrics.k8s.io/v1beta1/" | jq .次のコマンドを実行して、デフォルトの名前空間の
http_requests_per_secondメトリックの現在の値を照会します。kubectl get --raw "/apis/external.metrics.k8s.io/v1beta1/namespaces/default/http_requests_per_second"サンプル出力:
{ "kind": "ExternalMetricValueList", "apiVersion": "external.metrics.k8s.io/v1beta1", "metadata": {}, "items": [ { "metricName": "http_requests_per_second", "metricLabels": {}, "timestamp": "2022-01-28T08:40:20Z", "value": "33m" } ] }
手順3: 収集されたメトリックに基づいて自動スケーリングを実行するためのHPAの設定とデプロイ
HPAのデプロイ
Prometheusメトリクスを使用して、カスタムメトリクスと外部メトリクスを同時に公開できます。 次の表に、2つのタイプのメトリックを示します。
メートル法のタイプ | 説明 |
カスタムメトリック | オブジェクトに関連するメトリックに基づいて、ポッドなどのKubernetesオブジェクトをスケーリングします。 たとえば、ポッドのメトリックに基づいてポッドをスケーリングできます。 詳細については、「複数のメトリクスとカスタムメトリクスの自動スケーリング」をご参照ください。 |
外部メトリック | ポッドなどのKubernetesオブジェクトを、そのオブジェクトに関連しないメトリックに基づいてスケーリングします。 たとえば、業務QPSに基づいてワークロードのポッドをスケーリングできます。 詳細については、「Kubernetesオブジェクトに関連しないメトリクスの自動スケーリング」をご参照ください。 |
カスタムメトリクスに基づくポッドのスケーリング
hpa.yamlという名前のファイルを作成し、次の内容をファイルに追加します。
kind: HorizontalPodAutoscaler apiVersion: autoscaling/v2 metadata: name: sample-app-memory-high spec: # Describe the object that you want the HPA to scale. The HPA can dynamically change the number of pods that are deployed for the object. scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: sample-app # Specify the maximum and minimum number of pods. minReplicas: 1 maxReplicas: 10 # Specify the metrics based on which the HPA performs auto scaling. You can specify different types of metrics at the same time. metrics: - type: Pods pods: # Use the pods/container_memory_working_set_bytes_per_second metric. metric: name: container_memory_working_set_bytes_per_second # Specify an AverageValue type threshold. You can specify only AverageValue type thresholds for Pods metrics. target: type: AverageValue averageValue: 1024000m # 1024000m indicates a memory threshold of 1 KB. Unit: bytes per second. m is a precision unit used by Kubernetes. If the value contains decimal places and ACK requires high precision, the m or k unit is used. For example, 1001m is equal to 1.001 and 1k is equal to 1000.次のコマンドを実行してHPAを作成します。
kubectl apply -f hpa.yaml次のコマンドを実行して、HPAが期待どおりに実行されるかどうかを確認します。
kubectl get hpa sample-app-memory-high想定される出力:
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE sample-app-memory-high Deployment/sample-app 24576k/1024000m 3 10 1 7m
外部メトリックに基づくポッドのスケーリング
hpa.yamlという名前のファイルを作成し、次の内容をファイルに追加します。
apiVersion: autoscaling/v2 kind: HorizontalPodAutoscaler metadata: name: sample-app spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: sample-app minReplicas: 1 maxReplicas: 10 metrics: - type: External external: metric: name: http_requests_per_second selector: matchLabels: job: "sample-app" # You can specify only thresholds of the Value or AverageValue type for external metrics. target: type: AverageValue averageValue: 500m次のコマンドを実行してHPAを作成します。
kubectl apply -f hpa.yamlLoadBalancerサービスの作成後、次のコマンドを実行してストレステストを実行します。
ab -c 50 -n 2000 LoadBalancer(sample-app):8080/次のコマンドを実行して、HPAの詳細を照会します。
kubectl get hpa sample-app想定される出力:
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE sample-app Deployment/sample-app 33m/500m 1 10 1 7m
ack-alibaba-cloud-metrics-adapterの設定ファイル
ack-alibaba-cloud-metrics-adapterは、以下の手順を実行して、PrometheusメトリクスをHPAでサポートされているメトリクスに変換します。
発見: HPAで使用できるプロメテウス指標を発見します。
アソシエーション: メトリックをポッド、ノード、名前空間などのKubernetesリソースに関連付けます。
Naming: 変換後にHPAで使用できるメトリックの名前を定義します。
クエリ: Managed Service for Prometheus APIからメトリクスデータをクエリする方法を定義します。
上記の例では、sample-appポッドによって公開されるhttp_requests_totalメトリックは、HPAのhttp_requests_per_secondメトリックに変換されます。 次のコードブロックは、ack-alibaba-cloud-metrics-adapterの設定を示しています。
- seriesQuery: http_requests_total{namespace!="",pod!=""}
resources:
overrides:
namespace: {resource: "namespace"}
pod: {resource: "pod"}
name:
matches: ^(.*)_total
as: ${1}_per_second
metricsQuery: sum(rate(<<.Series>>{<<.LabelMatchers>>}[2m])) by (<<.GroupBy>>)パラメータ | 説明 |
| Prometheus Query Language (PromQL) クエリデータ。 |
| PromQLクエリデータをseriesQueryに集約します。 説明
|
| PromQLクエリデータのラベル。 |
| 正規表現を使用して、Prometheusメトリックの名前を読みやすいメトリック名に変換します。 この例では、 |
ディスカバリー
変換するプロメテウス指標を指定します。
seriesFiltersパラメーターを指定して、メトリックをフィルタリングできます。seriesQueryパラメーターは、指定されたラベルに基づいてデータと一致します。 次のコードブロックに例を示します。seriesQuery: http_requests_total{namespace!="",pod!=""} seriesFilters: - isNot: "^container_.*_seconds_total"seriesFilters: オプション。 このフィールドはメトリクスをフィルタリングします。is:<regex>: この正規表現を名前に含むメトリックに一致します。isNot:<regex>: 名前にこの正規表現が含まれていないメトリックに一致します。
アソシエーション
PrometheusメトリクスのラベルをKubernetesリソースにマッピングします。
http_requests_totalメトリックのラベルは、namespace!=""とpod!=""です。- seriesQuery: http_requests_total{namespace!="",pod!=""} resources: overrides: namespace: {resource: "namespace"} pod: {resource: "pod"}名前付け
Prometheusメトリクスから変換されるHPAメトリクスに名前を付けます。 Prometheusメトリックの名前は変更されません。 Prometheusメトリックを直接使用する場合は、命名設定を構成する必要はありません。
kubectl get -- raw "/apis/custom.metrics.k8s.io/v1beta1"コマンドを実行して、HPAでサポートされているメトリクスを照会できます。- seriesQuery: http_requests_total{namespace!="",pod!=""} resources: overrides: namespace: {resource: "namespace"} pod: {resource: "pod"} name: matches: "^(.*)_total" as: "${1}_per_second"クエリ
Managed Service for Prometheus APIに送信されるリクエストのテンプレート。 ack-alibaba-cloud-adapterは、HPAのパラメーターをリクエストテンプレートに渡し、テンプレートに基づいてManaged Service for Prometheus APIにリクエストを送信し、返されたパラメーター値を自動スケーリングのためにHPAに送信します。
- seriesQuery: http_requests_total{namespace!="",pod!=""} resources: overrides: namespace: {resource: "namespace"} pod: {resource: "pod"} name: matches: ^(.*)_total as: ${1}_per_second metricsQuery: sum(rate(<<.Series>>{<<.LabelMatchers>>}[2m])) by (<<.GroupBy>>)
Prometheus APIのマネージドサービスのエンドポイントの取得
シナリオ1: Prometheusのマネージドサービス
ACKコンソールにログインします。 左側のナビゲーションウィンドウで、[クラスター] をクリックします。
[クラスター] ページで、管理するクラスターの名前をクリックします。 左側のウィンドウで、 を選択します。
右上隅の [Go to ARMS Prometheus] をクリックします。
左側のナビゲーションウィンドウで、[設定] をクリックします。 次に、[設定] タブをクリックし、[HTTP API URL (Grafana読み取りURL)] を表示します。
マネージドサービスfor Prometheus APIを内部ネットワーク経由で呼び出すことを推奨します。 内部ネットワークが利用できない場合は、インターネット経由でAPIを呼び出すことができます。

シナリオ2: オープンソースのPrometheus
オープンソースの自己管理型Prometheusソリューションの場合は、サービスを使用して標準のPrometheus APIを公開する必要があります。 次に、メトリクスアダプタコンポーネントでPrometheusデータソースURLの相対パラメーターを設定し、オープンソースのPrometheusからのデータに基づいてHPAデータソースの設定を完了します。
次の例では、ackコンソールのMarketplaceページからHelm ChartコミュニティアプリケーションACK-prometheus-operatorを使用します。 詳細については、「オープンソースのPrometheusを使用したACKクラスターのモニタリング」をご参照ください。
Prometheusのマネージドサービスをデプロイし、Prometheusの標準APIを公開します。
ACKコンソールにログインします。 左側のナビゲーションウィンドウで、 を選択します。
[アプリカタログ] ページで、[ack-prometheus-operator] を見つけてクリックします。 表示されるページで、[デプロイ] をクリックします。
表示されるパネルで、[クラスター] パラメーターと [名前空間] パラメーターを設定し、ビジネス要件に基づいて [リリース名] パラメーターを変更し、[次へ] をクリックします。 ビジネス要件に基づいて [パラメーター] セクションを変更し、[OK] をクリックします。
デプロイの結果を表示します。
サービスを使用して標準のPrometheus APIを公開します。 例として、
ack-prometheus-operator-prometheusからServiceを取ります。ブラウザのアドレスバーに
ServiceIP:9090と入力し、PrometheusコンソールにアクセスするためにServer Load Balancer (SLB) インスタンスにアクセスするためのインターネットアクセスを有効にします。ブラウザのアドレスバーに入力し、インターネット経由でのアクセスを有効にして、Server Load Balancer (SLB) インスタンスにアクセスしてPrometheusコンソールにアクセスします。
上部のナビゲーションバーで、 を選択して、すべての収集タスクを表示します。
UP状態のタスクは期待どおりに実行されています。
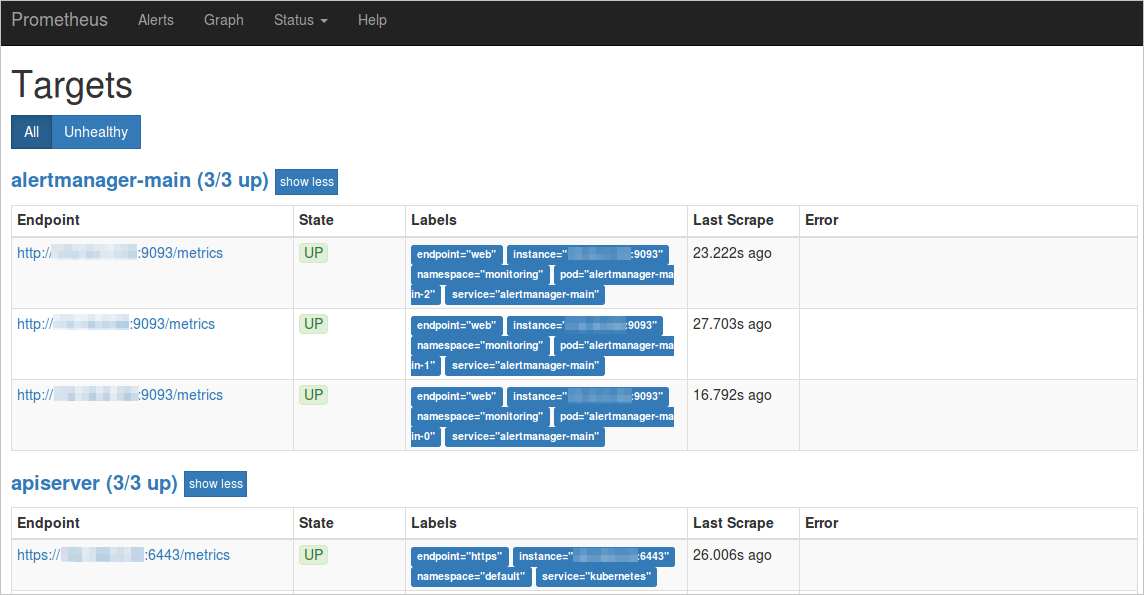
[ラベル] 列の [サービス] と [名前空間] を確認します。
次のコードブロックは、エンドポイントを示しています。 この例では、ServiceNameはack-prometheus-operator-prometheusであり、ServiceNamespaceは監視しています。
http://ack-prometheus-operator-prometheus.monitoring.svc.cluster.local:9090
コンポーネントの設定で、PrometheusデータソースのURLパラメーターを設定して、コンポーネントとPrometheus間の適切な通信を確保します。
インターネット経由でPrometheus APIにアクセスする場合は、次の設定例を参照してください。
AlibabaCloudMetricsAdapter: ...... prometheus: enabled: true url: http://your_domain.com:9090 # Replace your_domain.com with your public IP address.例としてack-prometheus-operatorを使用すると、
url値はhttp:// ack-prometheus-operator-prometheus.monitoring.svc.cluster.local:9090です。
関連ドキュメント
HTTPリクエストレートや1秒あたりの入力クエリ (QPS) などの外部メトリックを使用してHPAを実装する方法の詳細については、「Alibaba Cloudメトリックに基づく水平自動スケーリングの実装」をご参照ください。
NGINX Ingressを使用してHPAを実装し、ワークロードに基づいて複数のアプリケーションのポッド数を動的に調整する方法の詳細については、「NGINX Ingressトラフィック指標に基づいて複数のアプリケーションの水平ポッド自動スケーリングを構成する」をご参照ください。