このトピックでは、NGINX Ingressコントローラーを診断する手順と、NGINX Ingressコントローラーに関連する問題のトラブルシューティング方法について説明します。 このトピックでは、一般的な診断方法についても説明し、NGINX Ingressコントローラーに関するよくある質問 (FAQ) に対する回答を提供します。
目次
カテゴリ | コンテンツ |
診断手順 | |
トラブルシューティング | |
一般的な診断方法 | |
よくある質問 |
|
背景情報
Container Service for Kubernetes (ACK) は、オープンソースバージョンに基づいて最適化されたNGINX Ingressコントローラーを提供します。 ACKによって提供されるNGINX Ingressコントローラは、オープンソースバージョンと互換性があり、オープンソースバージョンによって提供されるすべての注釈をサポートします。 ACKクラスターまたはACKサーバーレスクラスターを作成するときに、NGINX Ingressコントローラーをインストールできます。 NGINX Ingressコントローラーのインストール方法の詳細については、「NGINX Ingressコントローラーの管理」をご参照ください。
Ingressは、NGINX IngressコントローラーをクラスターにデプロイしてIngressのルーティングルールを解析する場合にのみ、通常どおり機能します。 NGINX Ingressコントローラがルーティングルールに一致する要求を受信した後、NGINX Ingressコントローラは、対応するバックエンドサービスに要求をルーティングします。 その後、バックエンドサービスは要求をポッドに転送します。 Kubernetesクラスターでは、Services、Ingress、およびNGINX Ingressコントローラーは次のプロセスで動作します。
サービスは、複製されたポッドのセットで実行されるバックエンドアプリケーションの抽象化です。
Ingressにはリバースプロキシルールが含まれています。 HTTPまたはHTTPSリクエストがルーティングされるサービスポッドを制御します。 たとえば、リクエストは、リクエスト内のホストとURLパスに基づいて、異なるServiceポッドにルーティングされます。
NGINX Ingressコントローラは、Ingressルールを解析するリバースプロキシプログラムです。 Ingressルールに変更が加えられた場合、NGINX Ingressコントローラはそれに応じてIngressルールを更新します。 NGINX Ingressコントローラーがリクエストを受信すると、Ingressルールに基づいてリクエストをServiceポッドにリダイレクトします。
NGINX Ingressコントローラーは、APIサーバーからIngressルールの変更を取得し、nginx.confなどの設定ファイルを動的に生成します。 これらの設定ファイルは、NGINXなどのロードバランサーで必要です。 次に、NGINX Ingressコントローラはロードバランサをリロードします。 たとえば、NGINX Ingressコントローラーはnginx -s reloadコマンドを実行してNGINXをリロードし、新しいIngressルールを生成します。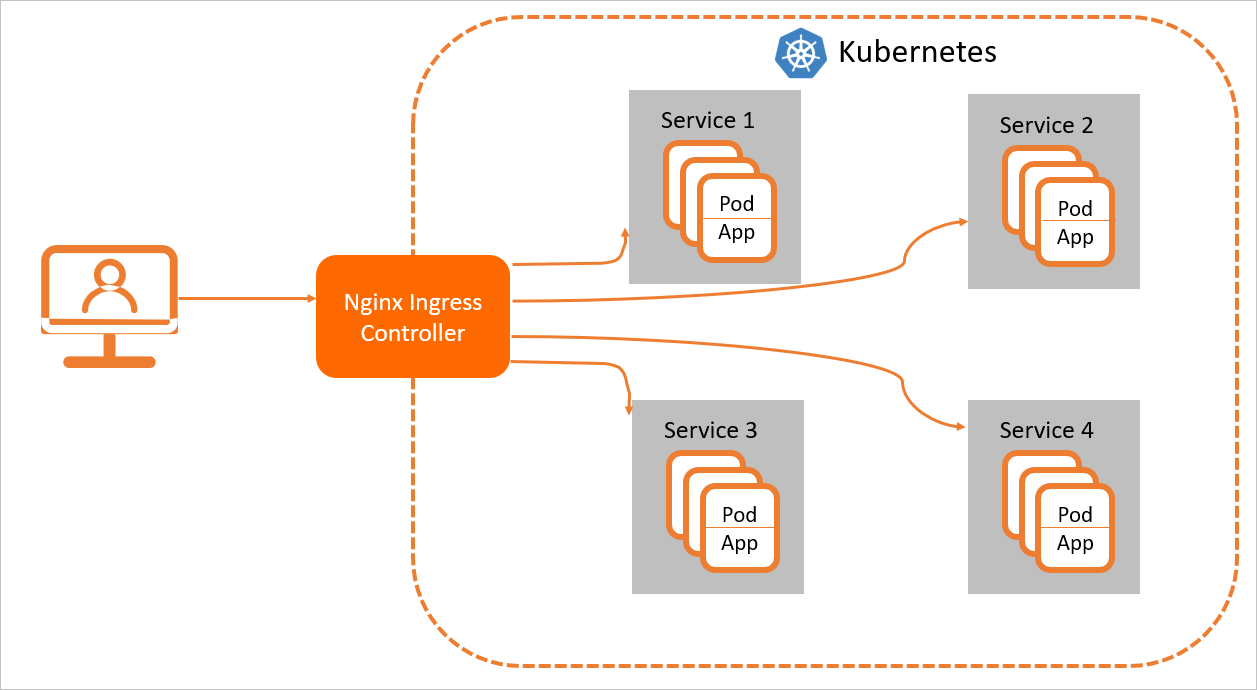
診断手順
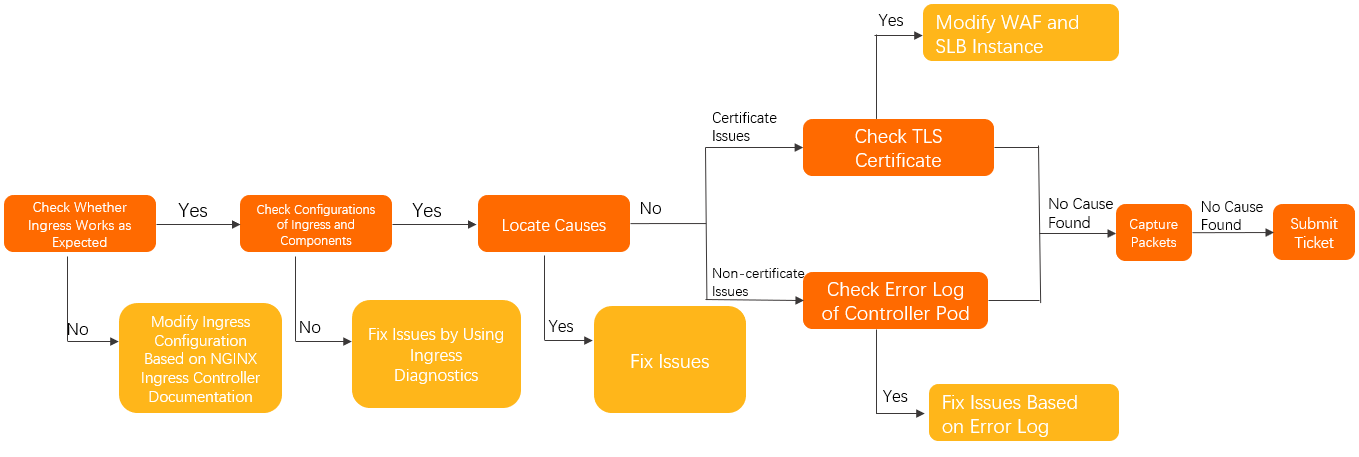
次の手順を実行して、Ingressによって問題が発生しているかどうかを確認できます。 Ingressコントローラーの設定が有効であることを確認してください。
コントローラポッドから特定のポッドにアクセスできるかどうかを確認します。 詳細については、このトピックの「Ingressコントローラポッドを使用してIngressポッドとバックエンドポッドに手動でアクセスする」をご参照ください。
NGINX Ingressコントローラーが正しく設定されているかどうかを確認します。 詳細については、「NGINX Ingressコントローラーのドキュメント」をご参照ください。
Ingress診断機能を使用して、Ingressとコンポーネントの設定を確認します。 次に、プロンプトに従って設定を変更します。 詳細については、このトピックの「Ingress診断機能の使用」をご参照ください。
問題の原因を特定し、に記載されている関連ソリューションを参照してください。トラブルシューティングこのトピックのセクション。
問題が解決しない場合は、次の手順を実行します。
TLS証明書に関連する問題:
ドメイン名がCNAMEレコードモードまたは透過プロキシモードでWeb Application Firewall (WAF) に追加されているかどうかを確認します。
ドメイン名がWAFに追加されている場合は、ドメイン名にTLS証明書があるかどうかを確認します。
ドメイン名がWAFに追加されていない場合は、次の手順に進みます。
Server Load Balancer (SLB) インスタンスにレイヤー7リスナーが設定されているかどうかを確認します。
SLBインスタンスにレイヤー7リスナーが設定されている場合は、そのリスナーにTLS証明書が関連付けられているかどうかを確認します。
SLBインスタンスにレイヤ7リスナーが設定されていない場合は、次の手順に進みます。
問題がTLS証明書に関連していない場合は、コントローラポッドのエラーログを確認してください。 詳細については、このトピックの「NGINX Ingressコントローラポッドのエラーログの診断」をご参照ください。
問題が解決しない場合は、コントローラポッドとバックエンドポッドでパケットをキャプチャして、問題の原因を特定します。 詳細については、このトピックの「パケットのキャプチャ」をご参照ください。
問題が解決しない場合は、
チケットの送信してサポートセンターにお問い合わせくださいしてサポートセンターにお問い合わせください。
トラブルシューティング
トラブルシューティング | 問題 | 解決策 |
接続に関連する問題 | クラスター内のポッドはIngressにアクセスできません。 | |
Ingressコントローラにアクセスできません。 | ||
TCPおよびUDPサービスにアクセスできません。 | ||
HTTPSリクエストに関連する問題 | 証明書が更新されないか、デフォルトの証明書が返されます。 | TLS証明書をクラスターに追加した後、またはTLS証明書を変更した後に、デフォルトのTLS証明書または以前のTLS証明書が使用されるのはなぜですか。 |
| HTTPSリクエストに対してエラー "SSL_ERROR_RX_RECORD_TOO_LONG" が返された場合はどうすればよいですか? | |
Ingressの作成時にエラーが発生する | Ingressを作成すると、「webhookの呼び出しに失敗しました... 」というエラーが発生します。 | Ingressを作成したときに「webhookの呼び出しに失敗しました」というエラーが発生した場合はどうすればよいですか? |
Ingressは作成されますが、有効になりません。 | ||
アクセスが期待に応えられない | クライアントIPアドレスは保持できません。 | |
IPアドレスホワイトリストは有効にならないか、期待に応えられません。 | ||
Ingressによって公開されているgRPCサービスにアクセスできません。 | ||
カナリアリリースルールは有効になりません。 | ||
カナリアリリースルールが無効であるか、他のトラフィックがカナリアIngressに関連付けられているバックエンドポッドに配信されます。 | カナリアリリースルールに基づいてトラフィックが配信されない場合、または他のIngressからのトラフィックがカナリアサービスにルーティングされる場合はどうすればよいですか? | |
次のエラーが発生します。 | ||
502、503、413、または499のステータスコードが返されます。 | ||
一部のページは表示できません。 |
| リクエストがルートディレクトリにリダイレクトされたときに、一部のwebページリソースの読み込みに失敗したり、空白の白い画面が返されたりするのはなぜですか。 |
リソースにアクセスすると、 | "net::ERR_HTTP2_SERVER_REFUSED_STREAM" というエラーが発生した場合はどうすればよいですか? |
一般的に使用される診断方法
Ingress診断機能の使用
ACKコンソールにログインします。 左側のナビゲーションウィンドウで、[クラスター] をクリックします。
[クラスター] ページで、管理するクラスターの名前をクリックします。 左側のウィンドウで、 を選択します。
On the診断ページをクリックします。侵入診断.
[Ingressの診断] ページで、[診断] をクリックします。 [Ingressの選択] パネルで、https://www.example.com などのアクセスできないURLを入力します。 [知っていると同意する] を選択し、[診断の作成] をクリックします。
診断が完了したら、診断結果を表示して問題の修正を試みることができます。
Simple log ServiceでNGINX Ingressコントローラポッドのアクセスログを診断する
NGINX Ingressコントローラーのアクセスログ形式は、kube-system名前空間のnginx-configuration ConfigMapで確認できます。
次のサンプルコードは、NGINX Ingressコントローラのアクセスログの既定の形式を示しています。
$remote_addr - [$remote_addr] - $remote_user [$time_local]
"$request" $status $body_bytes_sent "$http_referer" "$http_user_agent" $request_length
$request_time [$proxy_upstream_name] $upstream_addr $upstream_response_length
$upstream_response_time $upstream_status $req_id $host [$proxy_alternative_upstream_name]ログ形式を変更した後、それに応じてSimple log Serviceのログ収集ルールを変更する必要があります。 それ以外の場合、NGINX IngressコントローラーのアクセスログをSimple log Serviceに収集できません。 ログ形式を変更するときは注意してください。
次の図は、Simple log ServiceコンソールにNGINX Ingressコントローラーのアクセスログが表示されるページを示しています。 詳細については、「手順3: ログの照会と分析」をご参照ください。
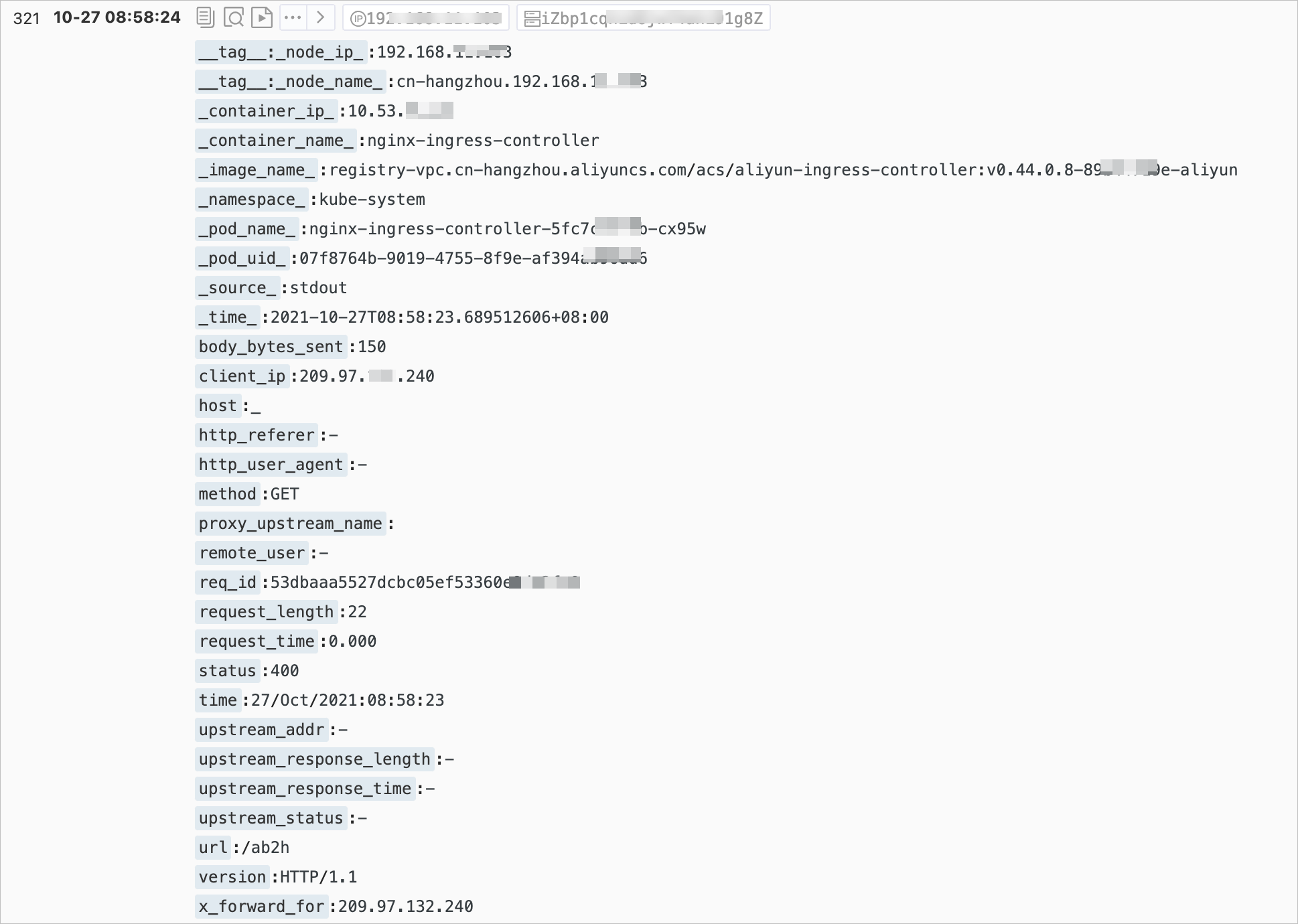
次の表に、Simple log Serviceコンソールに表示されるログフィールドを示します。 コンソールに表示される一部のログフィールドは、実際のログフィールドとは異なります。
フィールド | 説明 |
| クライアントの IP アドレスです。 |
| リクエストの詳細 (リクエストメソッド、URL、HTTPバージョンなど) 。 |
| リクエストの処理に消費される時間。 消費時間は、クライアント要求の最初のバイトが受信された時間から応答の最後のバイトが送信された時間まで計算されます。 このフィールドの値は、クライアントのネットワーク条件に基づいて変化するため、要求処理能力を反映しません。 |
| 上流サーバーのIPアドレス。 上流サーバーがリクエストを受信しない場合、戻り値は空です。 サーバー障害により複数の上流サーバーにリクエストが送信された場合、コンマ (,) で区切られた複数のIPアドレスが返されます。 |
| 上流サーバーからの応答に含まれるHTTPステータスコード。 HTTPステータスコードが成功した要求を示す場合、アップストリームサーバーにアクセスできます。 502ステータスコードが返された場合、上流サーバーにアクセスできません。 複数のステータスコードはコンマ (,) で区切ります。 |
| 上流サーバーの応答時間。 単位は秒です。 |
| 上流サーバーの名前。 名前の形式は |
| 代替上流サーバーの名前。 要求が代替上流サーバに転送される場合、代替上流サーバの名前が返される。 たとえば、カナリアリリースを実装します。 |
デフォルトでは、次のコマンドを実行して、NGINX Ingressコントローラの最近のアクセスログを照会できます。
kubectl logs <controller pod name> -n <namespace> | less想定される出力:
42.11.**.** - [42.11.**.**]--[25/Nov/2021:11:40:30 +0800]"GET / HTTP/1.1" 200 615 "_" "curl/7.64.1" 76 0.001 [default-nginx-svc-80] 172.16.254.208:80 615 0.000 200 46b79dkahflhakjhdhfkah**** 47.11.**.**[]
42.11.**.** - [42.11.**.**]--[25/Nov/2021:11:40:31 +0800]"GET / HTTP/1.1" 200 615 "_" "curl/7.64.1" 76 0.001 [default-nginx-svc-80] 172.16.254.208:80 615 0.000 200 fadgrerthflhakjhdhfkah**** 47.11.**.**[]NGINX Ingressコントローラポッドのエラーログの診断
NGINX Ingressコントローラポッドのエラーログを診断して、トラブルシューティングの範囲を絞り込むことができます。 Ingressコントローラポッドのエラーログには、次のタイプが含まれます。
Ingressコントローラのエラーを記録するログ。 通常、このタイプのエラーログは、無効なIngress設定が原因で生成されます。 次のコマンドを実行して、このタイプのエラーログを照会できます。
kubectl logs <controller pod name> -n <namespace> | grep -E ^[WE]説明イングレスコントローラの初期化中に、いくつかの警告イベントが生成され得る。 たとえば、kubeconfigファイルまたはIngressClassリソースを指定しない場合、警告イベントが生成されます。 これらのイベントはIngressコントローラーには影響せず、無視できます。
NGINXアプリケーションのエラーを記録するログ。 通常、このタイプのエラーログは、失敗した要求によって生成されます。 次のコマンドを実行して、このタイプのエラーログを照会できます。
kubectl logs <controller pod name> -n <namespace> | grep error
Ingressコントローラポッドを使用してIngressポッドとバックエンドポッドに手動でアクセスする
次のコマンドを実行して、Ingressコントローラポッドにログインします。
kubectl exec <controller pod name> -n <namespace> -it -- bashIngressコントローラポッドにはcurlとOpenSSLがプリインストールされており、ネットワーク接続のテストと証明書の検証が可能です。
次のコマンドを実行して、Ingressとバックエンドポッド間のネットワーク接続をテストします。
# Replace your.domain.com with the actual domain name of the Ingress. curl -H "Host: your.domain.com" http://127.0.**.**/ # for http curl --resolve your.domain.com:443:127.0.0.1 https://127.0.0.1/ # for https次のコマンドを実行して証明書を確認します。
openssl s_client -servername your.domain.com -connect 127.0.0.1:443バックエンドポッドへのアクセスをテストします。
説明Ingressコントローラーは、ClusterIPサービスを使用する代わりに、バックエンドポッドのIPアドレスに直接接続します。
次のkubectlコマンドを実行して、バックエンドポッドのIPアドレスを照会します。
kubectl get pod -n <namespace> <pod name> -o wide想定される出力:
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES nginx-dp-7f5fcc7f-**** 1/1 Running 0 23h 10.71.0.146 cn-beijing.192.168.**.** <none> <none>出力は、バックエンドポッドのIPアドレスが10.71.0.146であることを示しています。
Ingressコントローラポッドとバックエンドポッド間のネットワーク接続をテストするには、次のコマンドを実行してIngressコントローラポッドを使用してIPアドレスに接続します。
curl http://<your pod ip>:<port>/path
コマンドを実行してNGINX Ingressコントローラーのトラブルシューティング
kubectl-plugin
Kubernetes用Ingressコントローラーは、もともとNGINXを使用していました。 バージョン0.25.0以降のIngressコントローラはOpenRestyを使用します。 Ingressコントローラーは、APIサーバー上のIngressの設定の変更を自動的にリッスンし、対応するNGINX設定を生成してから、設定を再ロードして有効にします。 詳細については、「NGINX Ingressコントローラーのドキュメント」をご参照ください。
Ingressの数が増加し、すべての構成が単一の構成ファイルに集約されると、構成ファイルは過度に大きくなり、デバッグが困難になります。 特に、バージョン0.14.0以降のIngressコントローラーでは、lua-resty-balancerを使用してアップストリームサーバーの設定を動的に生成するため、設定ファイルのデバッグが難しくなります。 したがって、コミュニティは、nginx ingressの設定のデバッグを簡素化するためにkubectlプラグインingress-NGINXを提供しています。 詳細については、「ingress-nginx kubectl plugin」をご参照ください。
次のコマンドを実行して、NGINX Ingressコントローラが認識しているバックエンドを取得します。
kubectl ingress-nginx backends -n ingress-nginxdbgコマンド
ingress-nginx kubectlプラグインの使用に加えて、
dbgコマンドを実行して関連情報を表示および診断できます。次のコマンドを実行して、NGINX Ingressコントローラポッドにアクセスします。
kubectl exec -itn kube-system <nginx-ingress-pod-name> bash/dbgコマンドを実行します。 次の出力が返されます。nginx-ingress-controller-69f46d8b7-qmt25:/$ /dbg dbg is a tool for quickly inspecting the state of the nginx instance Usage: dbg [command] Available Commands: backends Inspect the dynamically-loaded backends information certs Inspect dynamic SSL certificates completion Generate the autocompletion script for the specified shell conf Dump the contents of /etc/nginx/nginx.conf general Output the general dynamic lua state help Help about any command Flags: -h, --help help for dbg --status-port int Port to use for the lua HTTP endpoint configuration. (default 10246) Use "dbg [command] --help" for more information about a command.
次のコマンドを実行して、ドメイン名に関連付けられた証明書が存在するかどうかを確認します。
/dbg certs get <hostname>次のコマンドを実行して、すべてのバックエンドに関する情報を表示します。
/dbg backends all
NGINX Ingressコントローラのステータスを確認する
NGINXには、オペレーション統計を生成できるセルフチェックモジュールが含まれています。 NGINX Ingressコントローラポッドで、curlコマンドを実行して、ポート10246を使用するNGINX Ingressコントローラにアクセスできます。 このようにして、NGINX Ingressコントローラーのリクエストと接続に関する統計を表示できます。
次のコマンドを実行して、NGINX Ingressコントローラポッドにアクセスします。
kubectl exec -itn kube-system <nginx-ingress-pod-name> bash次のコマンドを実行して、NGINX Ingressコントローラーのリクエストと接続に関する統計を表示します。
nginx-ingress-controller-79c5b4d87f-xxx:/etc/nginx$ curl localhost:10246/nginx_status Active connections: 12818 server accepts handled requests 22717127 22717127 823821421 Reading: 0 Writing: 382 Waiting: 12483上記の出力は、NGINX Ingressコントローラーが起動した後、22,717,127の接続を受信して処理し、各接続がすぐにシャットダウンすることなく成功したことを示しています。 22,717,127接続中、823,821,421の要求が処理されます。これは、平均して各接続中に約36.2の要求が処理されることを示します。
アクティブ接続: NGINX Ingressコントローラーがデプロイされているサーバーのアクティブ接続の総数。 上記の出力では、アクティブな接続の数は12,818です。
読み取り: NGINX Ingressコントローラーがデプロイされているサーバーがリクエストヘッダーを読み取っている間の接続数。 前の出力では、そのような接続の数は0です。
書き込み: NGINX Ingressコントローラーがデプロイされているサーバーが応答を送信している間の接続数。 前の出力では、そのような接続の数は382です。
待機中: キープアライブ状態の接続数。 前の出力では、そのような接続の数は12,483です。
キャプチャパケット
問題を特定できない場合は、パケットをキャプチャして診断します。
問題がIngressコントローラポッドに関連しているか、アプリケーションポッドに関連しているかを確認します。 問題を特定できない場合は、Ingressコントローラポッドとアプリケーションポッドの両方のパケットをキャプチャします。
アプリケーションポッドとIngressコントローラポッドが実行されているノードにログインします。
Elastic Compute Service (ECS) インスタンスで次のコマンドを実行して、Ingressによって受信されたすべての最近のパケットをキャプチャします。
tcpdump -i any host <IP address of the application pod or Ingress controller pod> -C 20 -W 200 -w /tmp/ingress.pcapログデータにエラーが確認された場合は、パケットのキャプチャを停止します。
エラーが発生した期間に転送されるパケットを診断します。
説明パケットキャプチャはサービスに影響を与えず、CPU使用率とディスクI/Oのわずかな増加のみを引き起こします。
上記のコマンドは、キャプチャされたパケットをローテーションし、最大200を生成できます. pcapファイルのサイズはそれぞれ20 MBです。
Kubernetesクラスター内のLoadBalancerサービスのIPアドレスにアクセスできないのはなぜですか。
問題
Kubernetesクラスターでは、LoadBalancerサービスのexternalTrafficPolicyパラメーターがLocalに設定されている場合、特定のノードのみがLoadBalancerサービスのIPアドレスにアクセスできます。
原因
externalTrafficPolicy: LocalはLoadBalancerサービスに設定されます。 ローカルモードでは、LoadBalancerサービスのIPアドレスには、LoadBalancerサービスを実行するローカルノードでプロビジョニングされているポッドからのみアクセスできます。 LoadBalancerサービスのIPアドレスは、クラスター内の他のノードのポッドからアクセスできません。 SLBインスタンスのIPアドレスがACKクラスターの外部にあること。 ACKクラスター内のノードまたはポッドがセカンドホップを使用せずにIPアドレスにアクセスできない場合、要求はSLBインスタンスに到達できません。 その結果、SLBインスタンスのIPアドレスは、SLBインスタンスを使用するサービスの拡張IPアドレスと見なされます。 リクエストは、iptablesまたはIP仮想サーバー (IPVS) に基づくkube-proxyによって転送されます。
このシナリオでは、要求されたポッドがローカルノードでプロビジョニングされていない場合、接続の問題が発生します。 SLBインスタンスのIPアドレスには、要求されたポッドがローカルノードでプロビジョニングされている場合にのみアクセスできます。 external-lbの詳細については、「kube-proxyがexternal-lbのIPアドレスをノードのローカルiptablesルールに追加」をご参照ください。
解決策
ClusterIPサービスまたはIngress名を使用して、Kubernetesクラスター内からLoadBalancerのIPアドレスにアクセスすることを推奨します。
Ingressは、kube-system名前空間で
nginx-ingress-lbという名前です。kubectl edit svc nginx-ingress-lb -n kube-systemコマンドを実行して、Ingressを変更します。 LoadBalancerサービスのexternalTrafficPolicyパラメーターをClusterに設定します。 設定を変更した後、クライアントのIPアドレスは保持できません。クラスターがTerwayネットワークプラグインを使用し、クラスターに対して排他的または包括的なelastic network interface (ENI) モードが有効になっている場合、LoadBalancer Serviceの
externalTrafficPolicyパラメーターをclusterに設定し、ENIアノテーションを追加できます。 アノテーションにより、LoadBalancerサービスのバックエンドサーバーとしてENIが割り当てられたポッドが追加されます。 これにより、クライアントIPアドレスを保持し、LoadBalancerサービスのIPアドレスにクラスター内でアクセスできます。サンプルコード:
apiVersion: v1 kind: Service metadata: annotations: service.beta.kubernetes.io/backend-type: eni # Specify pods that are assigned ENIs as backend servers. labels: app: nginx-ingress-lb name: nginx-ingress-lb namespace: kube-system spec: externalTrafficPolicy: Clusterサービス注釈の詳細については、「CLBインスタンスを構成するためのサービスのYAMLファイルへの注釈の追加」をご参照ください。
IngressコントローラポッドがIngressコントローラへのアクセスに失敗するのはなぜですか。
問題
Flannelが使用されているクラスターでは、Ingressコントローラーポッドがドメイン名、SLB IPアドレス、またはクラスターIPアドレスを使用してIngressコントローラーにアクセスすると、Ingressコントローラーポッドから送信されたリクエストの一部またはすべてがドロップされます。
原因
デフォルトでは、Flannelはループバック要求を許可しません。
解決策
Terwayネットワークプラグインを使用する新しいクラスターを作成し、ワークロードを新しいクラスターに移行することを推奨します。
新しいクラスターを作成しない場合は、Flannelの設定で
hairpinModeを有効にできます。 設定を変更した後、Flannelポッドを再作成して変更を有効にします。次のコマンドを実行して、Flannelの設定を変更します。
kubectl edit cm kube-flannel-cfg -n kube-system返されるcni-conf.jsonファイルで、
delegateフィールドに"hairpinMode": trueを追加します。サンプルコード:
cni-conf.json: | { "name": "cb0", "cniVersion":"0.3.1", "type": "flannel", "delegate": { "isDefaultGateway": true, "hairpinMode": true } }次のコマンドを実行して、以前のFlannelポッドを削除し、Flannelポッドを再作成します。
kubectl delete pod -n kube-system -l app=flannel
TLS証明書をクラスターに追加した後、またはTLS証明書を変更した後に、デフォルトのTLS証明書または以前のTLS証明書が使用されるのはなぜですか。
問題
クラスターにシークレットを追加するか、クラスター内のシークレットを変更し、IngressのsecretNameフィールドのシークレット名を更新しました。 クラスターにアクセスすると、デフォルトの証明書 (Kubernetes Ingress Controller Fake certificate) または以前の証明書が使用されます。
原因
証明書は、クラスターのIngressコントローラーによって返されません。
証明書が無効で、Ingressコントローラは証明書をロードできません。
証明書は、Server Name Indication (SNI) フィールドに基づいてIngressコントローラによって返されます。 SNIフィールドは、TLSハンドシェイクの一部として送信されなくてもよい。
解決策
次のいずれかの方法を使用して、SNIフィールドがTLSハンドシェイクの一部として送信されているかどうかを確認します。
ブラウザをSNIをサポートするバージョンに更新します。
openssl s_clientコマンドを実行して証明書が使用中かどうかを確認するときは、-servernameパラメーターを指定します。curlコマンドを実行するときは、IPアドレスとホストリクエストヘッダーを使用する代わりに、hostsを追加するか、-- resolveパラメーターを使用してドメイン名をマップします。
CNAMEレコードモードまたは透過プロキシモードでWebサイトをWAFに接続する場合、TLS証明書が指定されていないこと、またはTLS証明書がSLBインスタンスのレイヤー7リスナーに関連付けられていないことを確認します。 TLS証明書は、クラスターのIngressコントローラーによって返される必要があります。
Container Intelligence Serviceコンソールに移動し、Ingressを診断します。 診断レポートで、Ingressの設定が有効かどうか、およびログデータにエラーが表示されているかどうかを確認します。 詳細については、このトピックの「Ingress診断機能の使用」をご参照ください。
次のコマンドを実行して、Ingressコントローラポッドのエラーログを表示し、ログデータに基づいて問題をトラブルシューティングします。
kubectl logs <ingress pod name> -n <pod namespace> | grep -E ^[EW]
Ingressによって公開されているgRPCサービスにアクセスできないのはなぜですか?
問題
Ingressによって公開されるgRPCサービスにはアクセスできません。
原因
バックエンドプロトコルを指定するためにIngressにアノテーションを設定しないでください。
gRPCサービスには、トランスポート層セキュリティ (TLS) 経由でのみアクセスできます。
解決策
Ingressに次のアノテーションを設定します。
nginx.ingress.kubernetes.io/backend-protocol:"GRPC"クライアントがHTTPSポートを使用してリクエストを送信し、トラフィックがTLSを使用して暗号化されていることを確認します。
バックエンドHTTPSサービスにアクセスできないのはなぜですか?
問題
Ingressに基づいてバックエンドHTTPSサービスにアクセスできません。
400のエラーコードが返され、次のエラーメッセージが報告されます。
the plain HTTP request was sent to HTTPS port。
原因
Ingressコントローラーは、HTTPリクエストをバックエンドポッドに送信します。 デフォルト設定です。
解決策
Ingressに次のアノテーションを設定します。nginx.ingress.kubernetes.io/backend-protocol:"HTTPS"
IngressコントローラポッドがクライアントIPアドレスを保持できないのはなぜですか。
問題
Ingressコントローラポッドは、クライアントIPアドレスを保持できません。 ノードIPアドレス100.XX. XX.XXまたはその他のアドレスが表示されます。
原因
externalTrafficPolicyパラメーターは、Ingressに関連付けられているサービスのクラスターに設定されます。SLBインスタンスはレイヤ7プロキシを使用します。
WebサイトがCNAMEレコードモードまたは透過プロキシモードでWAFに接続されています。
解決策
externalTrafficPolicyパラメーターがサービスのクラスターに設定されており、レイヤー4 SLBインスタンスが使用されている場合は、次の手順を実行します。externalTrafficPolicyパラメーターをLocalに設定します。 ただし、クラスター内のLoadBalancerサービスのIPアドレスにアクセスできない場合があります。 詳細については、「」をご参照ください。Kubernetesクラスター内のLoadBalancerサービスのIPアドレスにアクセスできないのはなぜですか。レイヤー7プロキシを使用する場合は、次の手順を実行します。 たとえば、レイヤー7 SLBインスタンスが使用されている場合、またはWebサイトがCNAMEレコードモードまたは透過プロキシモードでWAFに接続されている場合、
レイヤー7プロキシでX-Forwarded-Forヘッダーが有効になっていることを確認します。
IngressコントローラーのConfigMapに
enable-real-ip: "true"を追加します。 デフォルトでは、ConfigMapはnginx-configurationという名前で、kube-system名前空間に属します。ログデータを分析して、クライアントIPアドレスが保存できるかどうかを確認します。
クライアント要求がIngressコントローラポッドに到達する前にリバースプロキシを通過する必要がある場合など、クライアント要求がIngressコントローラポッドに到達する前に複数のホップを通過する場合は、
enable-real-ipをtrueに設定した後、remote_addrの値を確認できます。 値がクライアントIPアドレスの場合、X-Forwarded-Forヘッダーが有効になり、クライアントIPアドレスをIngressコントローラーポッドに渡します。 X-Forwarded-Forヘッダーが無効になっている場合は、リクエストがIngressコントローラポッドに到達する前に、X-Forwarded-Forヘッダーを有効にするか、他の方法を使用してリクエストにクライアントIPアドレスを追加します。
カナリアリリースルールが有効にならないのはなぜですか?
問題
クラスターにカナリアリリースルールを設定しますが、ルールは有効になりません。
原因
考えられる原因:
canary-*アノテーションを追加する場合、nginx.ingress.kubernetes.io/canary: "true"は設定しません。NGINX Ingressコントローラーのバージョンが0.47.0より前です。
canary-*アノテーションを追加するときは、Ingressルールのホストフィールドでアプリケーションのドメイン名を指定しません。
解決策
上記の理由で問題が発生した場合は、
nginx.ingress.kubernetes.io/canary: "true"を設定するか、Ingressルールのhostフィールドでアプリケーションのドメイン名を指定します。 詳細については、「NGINX Ingressコントローラーを使用したカナリアリリースとブルーグリーンリリースの実装」をご参照ください。上記のいずれの理由でも問題が発生しない場合は、カナリアリリースルールに基づいてトラフィックが配信されない場合、または他のIngressからのトラフィックがカナリアサービスにルーティングされる場合はどうすればよいですか? このトピックのセクション。
カナリアリリースルールに基づいてトラフィックが配信されない場合、または他のIngressからのトラフィックがカナリアサービスにルーティングされる場合はどうすればよいですか?
問題
カナリアリリースルールを設定しましたが、トラフィックはカナリアリリースルールに基づいて配信されません。または、他のIngressからのトラフィックはカナリアサービスにルーティングされます。
原因
NGINX Ingressコントローラーのカナリアリリースルールは、カナリアリリースルールが作成されたサービスに関連付けられているすべてのIngressに対して有効になります。
この問題の詳細については、「カナリアのあるIngressは、同じサービスのすべてのIngressに影響を与えます」をご参照ください。
解決策
Canary Ingressには、service-matchアノテーションまたはcanary-* アノテーションが割り当てられたIngressが含まれます。 カナリアIngressを作成する前に、カナリアリリースに使用される同じサービスを2つ作成し、アクセスするバックエンドポッドにサービスをマップします。 詳細については、「NGINX Ingressコントローラーを使用したカナリアリリースとブルーグリーンリリースの実装」をご参照ください。
Ingressを作成したときに「webhookの呼び出しに失敗しました」というエラーが発生した場合はどうすればよいですか?
問題
Ingressを作成すると、「内部エラーが発生しました: webhookの呼び出しに失敗しました... 」というエラーが発生します。

原因
Ingressリソースを作成すると、Ingressが有効かどうかを確認するためにサービスが使用されます。 デフォルトでは、ingress-nginx-controller-admissionという名前のサービスが使用されます。 サービスやIngressコントローラーが削除されるなど、webhookリンクエラーが発生した場合、Ingressは作成できません。
解決策
次のwebhookリンクに基づいて、リソースが存在し、期待どおりに動作するかどうかを確認します。ValidatingWebhookConfiguration > Service > Pod。
Ingressコントローラポッドで承認機能が有効になっていること、およびクラスターの外部に外部要求を送信することでポッドにアクセスできることを確認します。
Ingressコントローラーが削除されている場合、またはwebhook機能を使用しない場合は、ValidatingWebhookConfigurationリソースを削除できます。
HTTPSリクエストに対してエラー "SSL_ERROR_RX_RECORD_TOO_LONG" が返された場合はどうすればよいですか?
問題
HTTPSリクエストに対して次のエラーのいずれかが返されます。SSL_ERROR_RX_RECORD_TOO_LONGまたはルーチン: CONNECT_CR_SRVR_HELLO: 間違ったバージョン番号。
原因
HTTPSリクエストは、HTTPポートなどの非HTTPSポートに配信されます。
一般的な原因:
SLBインスタンスのポート443は、Ingressコントローラポッドのポート80にマップされます。
Ingressコントローラポッドに関連付けられているサービスのポート443は、Ingressコントローラポッドのポート80にマップされます。
解決策
HTTPSリクエストが適切なポートに配信されるように、SLBインスタンスまたはサービスの設定を変更します。
共通のHTTPステータスコードが返された場合はどうすればよいですか?
問題
2xx、3xx以外のHTTPステータスコード (502、503、413、499など) が返されます。
原因と解決策
ログを表示し、Ingressコントローラーからエラーが返されたかどうかを確認します。 詳細については、このトピックの「Simple log ServiceのNGINX Ingressコントローラポッドのアクセスログの診断」をご参照ください。 Ingressコントローラーからエラーが返された場合は、次のソリューションを使用します。
413エラー
原因: リクエストサイズが上限を超えています。
解決策: IngressコントローラーのConfigMapでproxy-body-sizeの値を大きくします。 proxy-body-sizeのデフォルト値は、オープンソースKubernetesのNGINX Ingressコントローラーの場合1 MBであり、proxy-body-sizeのデフォルト値は、ACKのNGINX Ingressコントローラーの場合20 MBです。
499エラー
原因: クライアントは事前に接続を終了します。 このエラーは、Ingressコントローラーまたはバックエンドサービスが原因ではない可能性があります。
解決策:
499エラーが頻繁に発生せず、ワークロードに影響がない場合は、エラーを無視できます。
499エラーが頻繁に発生する場合は、バックエンドポッドがリクエストを処理するのにかかる時間が、クライアントで設定されているリクエストタイムアウト期間を超えているかどうかを確認する必要があります。
502エラー
原因: Ingressコントローラーがバックエンドポッドに接続できません。
解決策:
問題は時々発生します:
バックエンドポッドが期待どおりに機能するかどうかを確認します。 バックエンドポッドがオーバーロードされている場合は、バックエンドポッドを追加します。
デフォルトでは、IngressコントローラーはHTTP永続接続を使用してHTTP/1.1リクエストをバックエンドサービスに送信します。 バックエンドポッドに設定されたアイドル永続接続のタイムアウト期間が、Ingressコントローラーに設定されたタイムアウト期間よりも長いことを確認します。 デフォルトでは、タイムアウト時間は900秒に設定されています。
問題は毎回発生します。
サービスポートが有効かどうか、およびIngressコントローラポッドからサービスにアクセスできるかどうかを確認します。
問題が解決しない場合は、パケットをキャプチャして分析し、
チケットを起票してサポートセンターにお問い合わせくださいしてサポートセンターにお問い合わせください。
503エラー
原因: Ingressコントローラーがバックエンドポッドを検出できないか、Ingressコントローラーがすべてのバックエンドポッドにアクセスできません。
解決策:
問題は時々発生します:
502エラーを解決するためのソリューションを参照してください。
バックエンドポッドのステータスを確認し、ヘルスチェックを設定します。
問題は毎回発生します。
サービス設定が有効かどうか、およびエンドポイントが存在するかどうかを確認します。
上記の方法を使用して原因を特定できない場合は、
チケットを起票してサポートセンターにお問い合わせくださいしてサポートセンターにお問い合わせください。
"net::ERR_HTTP2_SERVER_REFUSED_STREAM" というエラーが発生した場合はどうすればよいですか?
問題
Webサイトにアクセスすると、一部のリソースをロードできず、コンソールに次のエラーのいずれかが報告されます。net::ERR_HTTP2_SERVER_REFUSED_STREAMおよびnet::ERR_FAILED。
原因
リソースへの同時HTTP/2ストリームの数が上限に達しました。
解決策
ConfigMapの
http2-max-concurrentストリームの値をより大きな値に変更することを推奨します。 デフォルト値は 128 です。 詳細は、「http2-max-concurrentストリーム」をご参照ください。ConfigMapで
use-http2をfalseに設定して、HTTP/2を無効にします。 詳細は、「use-http2」をご参照ください。
エラー "The param of ServerGroupName is illegal" が発生した場合、Idは何をしますか?
原因
ServerGroupNameは、namespace + svcName + portの形式で生成されます。 サーバーグループ名は2 ~ 128文字で、英数字、ピリオド (.) 、アンダースコア (_) 、ハイフン (-) を使用できます。 先頭は英字とする必要があります。
解決策
サーバーグループ名を必要な形式で変更します。
Ingressの作成時に "certificate signed by unknown authority" エラーが発生した場合はどうすればよいですか?
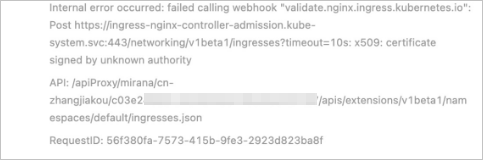
原因
複数のIngressがクラスターにデプロイされ、IngressがSecrets、Services、webhook設定などの同じリソースを使用している場合、webhookがトリガーされたときにバックエンドサーバーとの通信に異なるSSL証明書が使用されるため、上記のエラーが発生します。
解決策
2つのIngressをデプロイし、Ingressが異なるリソースを使用するようにします。 Ingressで使用されるリソースの詳細については、ACKコンソールの [アドオン] ページでNGINX Ingressコントローラーを更新した後、システムで何が更新されますか?
ヘルスチェックに失敗した後、Ingressコントローラポッドが再起動するのはなぜですか?
問題
Ingressコントローラポッドは、ヘルスチェックに失敗すると再起動します。
原因
Ingressコントローラポッドまたはポッドがデプロイされているノードがオーバーロードされています。 その結果、ポッドはヘルスチェックに合格しませんでした。
tcp_tw_reuseやtcp_tw_timestampなどのカーネルパラメーターは、Ingressコントローラポッドがデプロイされているクラスターノードに設定できます。 これにより、ヘルスチェックが失敗する可能性があります。
解決策
Ingressコントローラポッドを追加し、問題が解決しないか確認します。 詳細については、「高信頼性NGINX Ingressコントローラーのデプロイ」をご参照ください。
tcp_tw_reuseを無効にするか、パラメーターの値を2に設定し、tcp_tw_timestampsを無効にして、問題が解決するかどうかを確認します。
TCPまたはUDPを使用するサービスを追加する方法?
tcp-servicesおよびudp-services ConfigMapsに特定のエントリを追加します。 デフォルトでは、ConfigMapsはkube-system名前空間に属します。
次のサンプルコードでは、既定の名前空間のexample-goのポート8080をポート9000にマップする方法の例を示します。
apiVersion: v1 kind: ConfigMap metadata: name: tcp-services namespace: ingress-nginx data: 9000: "default/example-go:8080" # Map port 8080 to port 9000.NGINX Ingressコントローラーの展開にポート9000を追加します。 デフォルトでは、Deploymentはnginx-ingress-controllerという名前で、kube-system名前空間に属します。
Ingressに関連付けられているサービスにポート9000を追加します。
TCPまたはUDPを使用するサービスを追加する方法の詳細については、「TCPまたはUDPサービスの公開」をご参照ください。
Ingressルールが有効にならないのはなぜですか?
問題
Ingressルールを追加または変更した後、ルールは有効になりません。
原因
Ingressの設定にエラーが含まれています。 その結果、IngressはIngressルールをロードできませんでした。
Ingressリソースの設定にエラーが含まれています。
Ingressコントローラーに必要な権限がありません。 その結果、IngressコントローラーはIngressリソースに加えられた変更を監視できません。
以前のIngressは、
server-aliasフィールドで指定されたドメイン名を使用します。 ドメイン名が新しいIngressのドメイン名と競合しています。 その結果、Ingressルールは無視されます。
解決策
Container Intelligence Serviceコンソールに移動し、Ingressを診断し、プロンプトに従って問題を解決します。 詳細については、このトピックの「Ingress診断機能の使用」をご参照ください。
以前のIngressの設定にエラーが含まれているか、または設定の競合が存在するかどうかを確認します。
rewrite-targetが使用されず、パスが正規表現で指定されている場合は、nginx.ingress.kubernetes.io/use-regex: "trueアノテーションが追加されていることを確認してください。PathTypeが期待値に設定されているかどうかを確認します。 デフォルトでは、
ImplementationSpecificはPrefixと同じ効果があります。
Ingressコントローラーに関連付けられているClusterRole、ClusterRoleBinding、Role、RoleBinding、およびServiceAccountが存在することを確認します。 デフォルトの名前はingress-nginxです。
Ingressコントローラポッドに接続し、nginx.confファイルに追加されたルールを表示します。
次のコマンドを実行して、ポッドログを表示し、原因を特定します。
kubectl logs <ingress pod name> -n <pod namespace> | grep -E ^[EW]
リクエストがルートディレクトリにリダイレクトされたときに、一部のwebページリソースの読み込みに失敗したり、空白の白い画面が返されたりするのはなぜですか。
問題
Ingressでrewrite-targetアノテーションを設定してリクエストを書き換えると、一部のwebページリソースを読み込むことができないか、バックエンドサービスにアクセスすると空白の白い画面が表示されます。
原因
正規表現では
rewrite-targetを設定しません。リクエストされたリソースのパスは、ルートディレクトリに設定されます。
解決策
rewrite-targetが正規表現で使用されているかどうか、およびキャプチャグループが使用されているかどうかを確認します。 詳細については、「書き換え」をご参照ください。リクエストが期待されるパスにリダイレクトされるかどうかを確認します。
ingress-nginx-controllerの更新後にSimple Log Serviceがログを期待どおりに解析できない問題を修正するにはどうすればよいですか?
問題
ingress-nginx-controllerコンポーネントには、0.20と0.30の2つの一般的なバージョンがあります。 ACKコンソールの [アドオン] ページでingress-nginx-controllerを0.20から0.30に更新した後、Ingressを使用してカナリアリリースまたは青緑色リリースを実行すると、Ingressダッシュボードにはバックエンドサーバーへのリクエストの実際の統計が表示されません。
原因
ingress-nginx-controller 0.20のデフォルトのログ形式は、ingress-nginx-controller 0.30のそれとは異なります。 したがって、ingress-nginx-controllerを0.20から0.30に更新した後、Ingressダッシュボードには、Ingressを使用してカナリアリリースまたは青緑色リリースを実行すると、バックエンドサーバーへのリクエストの実際の統計が表示されない場合があります。
解決策
この問題を修正するには、次の手順を実行してnginx-configuration ConfigMapとk8s-nginx-ingressの設定を更新します。
nginx-configurationConfigMapを更新します。nginx-configurationConfigMapを変更していない場合は、次の内容をnginx-configuration.yamlという名前のファイルにコピーし、kubectl apply -f nginx-configuration.yamlコマンドを実行してファイルをデプロイします。apiVersion: v1 kind: ConfigMap data: allow-backend-server-header: "true" enable-underscores-in-headers: "true" generate-request-id: "true" ignore-invalid-headers: "true" log-format-upstream: $remote_addr - [$remote_addr] - $remote_user [$time_local] "$request" $status $body_bytes_sent "$http_referer" "$http_user_agent" $request_length $request_time [$proxy_upstream_name] $upstream_addr $upstream_response_length $upstream_response_time $upstream_status $req_id $host [$proxy_alternative_upstream_name] max-worker-connections: "65536" proxy-body-size: 20m proxy-connect-timeout: "10" reuse-port: "true" server-tokens: "false" ssl-redirect: "false" upstream-keepalive-timeout: "900" worker-cpu-affinity: auto metadata: labels: app: ingress-nginx name: nginx-configuration namespace: kube-systemnginx-configurationConfigMapを変更した場合は、次のコマンドを実行して設定を更新します。 これにより、以前の変更は上書きされません。kubectl edit configmap nginx-configuration -n kube-system
log-format-upstreamフィールドに[$proxy_alternative_upstream_name]を追加し、変更を保存して終了します。変更します。Modify the
k8s-nginx-ingress設定します。次のコンテンツを
k8s-nginx-ingress.yamlという名前のファイルにコピーし、kubectl apply -f k8s-nginx-ingress.yamlコマンドを実行して、ingress-nginx-controllerコンポーネントをデプロイします。
NGINX Ingressコントローラの一般的なエラーが発生した場合はどうすればよいですか?
発行
このトピックの「NGINX Ingressコントローラポッドのアクセスログの診断」セクションで説明されている手順に基づいてアクセスログを診断すると、コントローラエラーが見つかります。 例:
User "system:serviceaccount:kube-system:ingress-nginx" cannot list/get/update resource "xxx" in API group "xxx" at the cluster scope/ in the namespace "kube-system"原因
NGINX Ingressコントローラーには、リソースを更新する権限がありません。
解決策
ログデータに基づいて、問題がClusterRoleまたはRoleによって発生しているかどうかを確認します。
ログデータに
クラスタースコープが含まれている場合、問題はClusterRole (ingress-nginx) によって発生します。ログデータに
名前空間 "kube-system"が含まれている場合、問題はロール (kube-system/ingrerss-nginx) によって発生します。
必要な権限が付与され、ロールバインディングが正しいことを確認してください。
問題がClusterRoleによって発生した場合:
ClusterRole
チケットを起票し、テクニカルサポートを受けます。ingress-nginxおよびClusterRoleBindingingress-nginxが存在することを確認します。 ClusterRoleとClusterRoleBinding ingress-nginxが存在しない場合は、手動で作成するか、関連するコンポーネントを再インストールするか、またはすることができます。ClusterRole
ingress-nginxがログデータに示されている権限を提供できることを確認します。 次の図では、networking.k8s.io/ingressesに対するLIST権限が必要です。 ClusterRoleが対応する権限を提供できない場合は、権限を追加します。
問題がロールに起因する場合:
Role
チケットを起票し、テクニカルサポートを受けます。kube-system/ingress-nginxおよびRoleBindingkube-system/ingress-nginxが存在することを確認してください。 ClusterRoleとClusterRoleBinding ingress-nginxが存在しない場合は、手動で作成するか、関連するコンポーネントを再インストールするか、またはすることができます。ロール
ingress-nginxがログデータに示された権限を提供できることを確認します。 次の図では、ingress-controller-leader-nginxConfigMapに対するUPDATE権限が必要です。 ロールに対応する権限がない場合は、ロールに権限を付与します。
問題
このトピックの「NGINX Ingressコントローラポッドのアクセスログの診断」セクションで説明されている手順に基づいてアクセスログを診断すると、コントローラエラーが見つかります。 例:
requeuing……nginx: configuration file xxx test failed (multiple lines)原因
IngressルールまたはConfigMapの構文エラーにより、NGINX設定のリロードに失敗しました。
解決策
ログのエラーメッセージを確認し、構文エラーを見つけます。 警告メッセージは無視できます。 エラーメッセージが構文エラーの特定に役立たない場合は、エラーメッセージに基づいてポッド内の対応するファイルとコード行を見つけることができます。 たとえば、/tmp/nginx/nginx-cfg2825306115ファイルの449行目を探します。 次の図に例を示します。
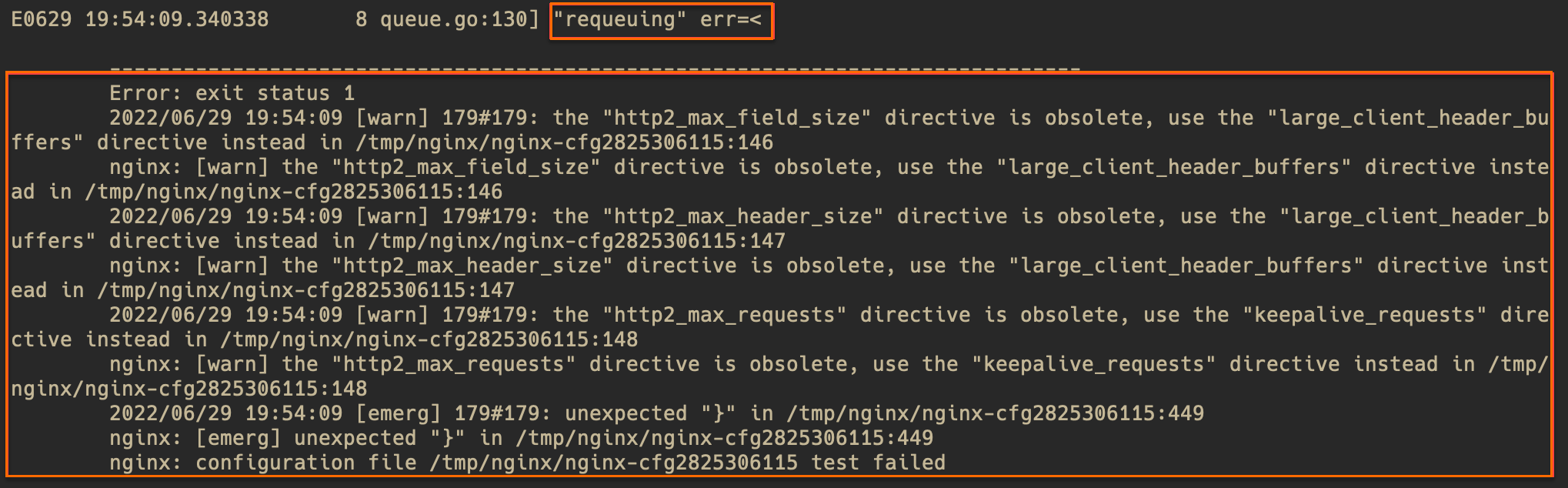
次のコマンドを実行して、構文エラーを確認します。
# Access the pod and run the command. kubectl exec -n <namespace> <controller pod name> -it -- bash # Export the file that contains syntax errors and display line numbers. Then, check for syntax errors in the corresponding lines. cat -n /tmp/nginx/nginx-cfg2825306115構文エラーを見つけて修正します。
問題
このトピックの「NGINX Ingressコントローラポッドのアクセスログの診断」セクションで説明されている手順に基づいてアクセスログを診断すると、コントローラエラーが見つかります。 例:
Unexpected error validating SSL certificate "xxx" for server "xxx"
原因
証明書に関連付けられているドメイン名がIngressで指定されているドメイン名と異なるため、証明書構成エラーが発生します。 警告レベルでいくつかの証明書エラーが発生した場合、期待どおりに証明書を使用し続けることができます。 たとえば、証明書にSAN属性がないことをシステムが要求した場合でも、証明書を引き続き使用できます。
解決策
証明書が次の要件を満たしていることを確認します。
の形式と内容。The format and content of the. certファイルと。キーファイルが有効です。
証明書に関連付けられているドメイン名は、Ingressで指定されているものと同じです。
証明書の有効期限が切れていない。
NGINX Ingressコントローラーに未クリーニングの構成ファイルが多数存在する場合はどうすればよいですか?
問題
1.10より前のバージョンのNginx Ingressコントローラーに既知のバグが存在します。通常の状況では、生成されたnginx-cfgファイルは時間内にクリーンアップされます。 Ingressが正しく構成されておらず、nginx.confファイルに問題が発生した場合、正しくない構成ファイルを期待どおりにクリアすることはできません。 その結果、nginx-cfgxxxファイルは徐々に蓄積され、大量のディスク容量を消費します。

原因
問題の原因は、クリーンアップロジックの欠陥です。 正しく生成された構成ファイルはクリーンアップされますが、無効な構成ファイルが生成されるシナリオではクリーンアップメカニズムは機能しません。 詳細については、「clean nginx temp configs function does not work #11568」をご参照ください。
解決策
この問題を解決するには、次のソリューションを使用します。
Nginx Ingressコントローラーの更新: Nginx Ingressコントローラーのバージョンを1.10以降に更新することを推奨します。 詳細については、「NGINX Ingressコントローラーの更新」をご参照ください。
古いファイルを手動でクリーンアップする: クリーンアップされていない
nginx-cfgxxxファイルを定期的に手動で削除できます。 手動操作の負担を軽減するために、プロセスを自動化するスクリプトを作成できます。構成エラーの確認: 新しいIngress構成を適用する前に、無効な構成ファイルが生成されないように、構成の正確性を慎重に確認してください。
NGINX Ingressコントローラーの更新後にポッドが継続保留状態になった場合はどうすればよいですか。
問題
Nginx Ingressコントローラーを更新すると、ポッドがスケジュールされない場合があります。 ポッドは長期間保留状態のままです。
原因
Nginx Ingressコントローラーを更新すると、ノードのアフィニティとポッドのアンチアフィニティのルールがデフォルトで設定されます。 その結果、新しいバージョンのポッドがスケジュールされない場合があります。 クラスターに十分なリソースがあることを確認してください。
次のコマンドを実行して、特定の原因を表示できます。
kubectl -n kube-system describe pod <pending-pod-name>kubectl -n kube-system get events解決策
この問題を解決するには、次のソリューションを使用できます。
クラスターリソースのスケールアウト: アフィニティルールの要件を満たす新しいノードを追加します。 詳細については、「ノードプールの手動スケーリング」をご参照ください。
アフィニティの調整: リソースが厳しい場合は、
kubectl edit deploy nginx-ingress-controller -n kube-systemコマンドを実行して、ポッドを同じノードにスケジュールできるように、アフィニティ対策要件を調整できます。 この方法は、コンポーネントの高可用性を低下させ得る。
FlannelとIPVSで構築されたクラスターで使用されるNGINX Ingressコントローラーが、複数のCLBインスタンス間でTCPトラフィックの問題を引き起こす場合はどうすればよいですか。
問題
FlannelとIPVSを使用するACKクラスターでは、Nginx Ingressコントローラーが複数のClassic Load Balancer (CLB) インスタンスにバインドされている場合、同時実行時にTCPトラフィックの問題が発生する可能性があります。 以下の異常は、パケットキャプチャによって観察することができる。
パケットの再送信
異常なTCP接続リセット

原因
Flannelを使用するACKクラスターでは、CLBはNginx Ingressコントローラーが存在するノードのNodePortにトラフィックを転送します。 ただし、複数のサービスが異なるNodePortsを使用する場合、IPVSセッションは高同時性シナリオで競合する可能性があります。
解決策
単一Server Load Balancerポリシー: Load Balancerサービス用にNginx Ingressコントローラーを1つだけ作成します。 競合の可能性を減らすために、他のCLBインスタンスをノードのNodePortに手動でバインドします。
複数のNodePortsが同時に有効になるのを防ぐ: IPVSセッションの競合のリスクを減らすために、同じノードで複数のNodePortsが同時に有効になるのを防ぐようにしてください。