このトピックでは、DNS解決失敗の診断手順とトラブルシューティングについて説明します。 このトピックでは、DNS解決の失敗に対するソリューションと診断方法も提供します。
目次
項目 | コンテンツ |
診断手順 | |
トラブルシューティング | |
診断方法 | |
よくある質問 |
診断手順
条件
internal domain name: サービスを公開するためにCoreDNSによって使用されるドメイン名。 内部ドメイン名は
. cluster.local. 内部ドメイン名のDNSクエリは、アップストリームDNSサーバーではなく、CoreDNSのDNSキャッシュに基づいて解決されます。外部ドメイン名: サードパーティDNSサービスプロバイダー、Alibaba Cloud DNS、またはAlibaba Cloud DNS PrivateZoneによって提供される権威DNSによって解決されるドメイン名。 クラスター外部ドメイン名は、CoreDNSのアップストリームDNSサーバーによって解決されます。 CoreDNSは、DNSクエリのみをアップストリームDNSサーバーに転送します。
application pod: Kubernetesクラスター内のシステムコンポーネントのポッド以外のポッド。
DNS解決にCoreDNSを使用するアプリケーションポッド: DNSクエリを処理するためにCoreDNSを使用するアプリケーションポッド。
DNS解決にNodeLocal DNSCacheを使用するアプリケーションポッド: DNSConfigが挿入されるアプリケーションポッド。 クラスターにNodeLocal DNSCacheをインストールした後、アプリケーションポッドにDNSConfigを挿入してDNS設定を構成できます。 このように、これらのポッドのDNSクエリは、最初にNodeLocal DNSCacheに送信されます。 NodeLocal DNSCacheがクエリの処理に失敗した場合、クエリはCoreDNSのkube-dns Serviceに送信されます。
トラブルシューティング手順

例外の原因を特定します。 詳細については、このトピックの「一般的なエラーメッセージ」をご参照ください。
ドメイン名が存在しないことを示すエラーメッセージが表示された場合は、[トラブルシューティング] セクションの [ドメイン名の確認] を参照してください。
DNSサーバーへの接続が確立できないことをエラーメッセージが示す場合は、[トラブルシューティング] セクションの [エラーの頻度の確認] を参照してください。
問題が解決しない場合は、次の手順を実行します。
アプリケーションポッドのDNS設定でCoreDNSが指定されているかどうかを確認します。 詳細については、このトピックの「アプリケーションポッドのDNS設定の診断」をご参照ください。
CoreDNSがDNS設定で指定されていない場合、クライアントはフルロードで実行されるか、conntrackテーブルがいっぱいになる可能性があります。 詳細については、「」をご参照ください。クライアントが過負荷になったためにDNS解決が失敗した場合はどうすればよいですか? またはconntrackテーブルがいっぱいの場合はどうすればよいですか? このトピックのセクション。
DNS設定でCoreDNSが指定されている場合は、次の手順を実行します。
CoreDNSポッドのステータスを確認します。 詳細については、「CoreDNSポッドのステータスを診断する」および「CoreDNSポッドが期待どおりに実行されない場合の対処方法」をご参照ください。 このトピックのセクション。
CoreDNSポッドの実行ログを確認します。 詳細については、「CoreDNSの実行ログの診断」と「クラスターの外部ドメイン名が解決できない場合はどうすればよいですか」をご参照ください。 このトピックのセクション。
問題が安定して再現できるかどうかを確認します。
問題が安定して再現できる場合は、このトピックの「CoreDNSのDNSクエリログの診断」および「アプリケーションポッドとCoreDNSポッド間のネットワーク接続の診断」を参照してください。
問題を安定して再現できない場合は、このトピックのCapture packetsセクションを参照してください。
DNS設定でNodeLocal DNSCacheが指定されている場合は、NodeLocal DNSCacheが機能しない場合はどうすればよいですか? とAlibaba Cloud DNS PrivateZoneに追加されたドメイン名が解決できない場合はどうすればよいですか。 このトピックのセクション。
問題が解決しない場合は、チケットの送信します。
一般的なエラーメッセージ
クライアント | エラーメッセージ | 考えられる原因 |
ping |
| ドメイン名が存在しないか、DNSサーバーにアクセスできません。 解決レイテンシが5秒を超える場合、DNSサーバーにアクセスできない可能性があります。 |
curl |
| |
PHP HTTPクライアント |
| |
Golang HTTPクライアント |
| ドメイン名が存在しません。 |
掘る |
| |
Golang HTTPクライアント |
| DNSサーバにアクセスできません。 |
掘る |
|
トラブルシューティング
API 操作 | 症状 | 原因と解決策 |
ドメイン名の確認 | 内部ドメイン名と外部ドメイン名で解決エラーが発生します。 | |
解決エラーは外部ドメイン名でのみ発生します。 | ||
解決エラーは、Alibaba Cloud DNS PrivateZoneに追加されたドメイン名とvpc-proxyを含むドメイン名でのみ発生します。 | Alibaba Cloud DNS PrivateZoneに追加されたドメイン名が解決できない場合はどうすればよいですか。 | |
解決エラーは、ヘッドレスサービスのドメイン名でのみ発生します。 | ||
エラーの頻度を確認する | 解決エラーは毎回発生します。 | |
解決エラーはピーク時にのみ発生します。 | ||
分解能エラーは高い頻度で発生する。 | ||
分解能エラーは低い周波数で発生する。 | ||
解決エラーは、ノードスケーリングまたはCoreDNSスケーリング中にのみ発生します。 |
診断方法
アプリケーションポッドのDNS設定の診断
コマンド
# Run the following command to query the YAML file of the foo pod. Then, check whether the dnsPolicy field in the YAML file is set to a proper value. kubectl get pod foo -o yaml # If the dnsPolicy field is set to a proper value, check the DNS configuration file of the pod. # Run the following command to log on to the containers of the foo pod by using bash. If bash does not exist, use sh. kubectl exec -it foo bash # Run the following command to query the DNS configuration file. Then, check the DNS server addresses in the nameserver field. cat /etc/resolv.confDNSポリシー設定
次のサンプルコードは、DNSポリシー設定で構成されたポッドテンプレートを提供します。
apiVersion: v1 kind: Pod metadata: name: <pod-name> namespace: <pod-namespace> spec: containers: - image: <container-image> name: <container-name> # The default value of the dnsPolicy field is ClusterFirst. dnsPolicy: ClusterFirst # The following code shows the DNS policy settings that are applied when NodeLocal DNSCache is used. dnsPolicy: None dnsConfig: nameservers: - 169.254.20.10 - 172.21.0.10 options: - name: ndots value: "3" - name: timeout value: "1" - name: attempts value: "2" searches: - default.svc.cluster.local - svc.cluster.local - cluster.local securityContext: {} serviceAccount: default serviceAccountName: default terminationGracePeriodSeconds: 30dnsPolicyの値
説明
デフォルト
この値は、クラスター内からの内部アクセスが不要な場合に使用できます。 ポッドは、Elastic Compute Service (ECS) インスタンスの /etc/resolv.confファイルで指定されているDNSサーバーを使用します。
ClusterFirst
デフォルト値です。 kube-dns ServiceのIPアドレスは、ポッドで使用されるDNSサーバーのアドレスとして使用されます。 ホストネットワークを使用するポッドの場合、ClusterFirstの値はDefaultの値と同じ効果があります。
ClusterFirstWithHostNet
ホストネットワークを使用するポッドの場合、ClusterFirstWithHostNetの値はClusterFirstの値と同じ効果を持ちます。
なし
この値を使用すると、dnsConfigセクションで自己管理DNSサーバーとカスタムパラメーターを設定できます。 dnsConfig for NodeLocal DNSCacheの自動注入を有効にすると、ローカルDNSキャッシュのIPアドレスとkube-dns ServiceのIPアドレスがDNSサーバーのアドレスとして指定されます。
CoreDNSポッドのステータスの診断
コマンド
次のコマンドを実行して、CoreDNSポッドに関する情報を照会します。
kubectl -n kube-system get pod -o wide -l k8s-app=kube-dns期待される出力:
NAME READY STATUS RESTARTS AGE IP NODE coredns-xxxxxxxxx-xxxxx 1/1 Running 0 25h 172.20.6.53 cn-hangzhou.192.168.0.198次のコマンドを実行して、CoreDNSポッドのリアルタイムリソース使用状況を照会します。
kubectl -n kube-system top pod -l k8s-app=kube-dns期待される出力:
NAME CPU(cores) MEMORY(bytes) coredns-xxxxxxxxx-xxxxx 3m 18MiCoreDNSポッドが [実行中] 状態でない場合は、
kubectl -n kube-system describe pod <CoreDNS pod name>コマンドを実行して原因を特定します。
CoreDNSの実行ログの診断
コマンド
次のコマンドを実行して、CoreDNSの実行ログを照会します。
kubectl -n kube-system logs -f --tail=500 --timestamps coredns-xxxxxxxxx-xxxxxパラメーター | 説明 |
| ログがストリーミングされます。 |
| ログの最後の500行が印刷されます。 |
| タイムスタンプは、ログ出力の各行に含まれます。 |
| CoreDNSポッドの名前。 |
CoreDNSのDNSクエリログを診断する
コマンド
CoreDNSのDNSクエリログは、CoreDNSのログプラグインが有効になっている場合にのみ生成されます。 ログプラグインを有効にする方法の詳細については、「CoreDNSの設定」をご参照ください。
CoreDNSの実行ログのクエリに使用するコマンドを実行します。 詳細については、このトピックの「CoreDNSの実行ログの診断」をご参照ください。
CoreDNSポッドのネットワーク接続を診断する
コンソールまたはCLIを使用して、CoreDNSポッドのネットワーク接続を診断できます。
コンソールの使用
クラスターが提供するネットワーク診断機能を使用できます。
ACKコンソールにログインします。 左側のナビゲーションウィンドウで、[クラスター] をクリックします。
[クラスター] ページで、診断するクラスターの名前をクリックします。 左側のナビゲーションウィンドウで、[検査と診断]> [診断] を選択します。
[診断] ページで、[ネットワーク診断] をクリックします。
[ネットワーク診断] ページで、[診断] をクリックします。 [ネットワーク] パネルで、次のパラメーターを設定します。
ソースアドレス: CoreDNSポッドのIPアドレスを入力します。
宛先アドレス: アップストリームDNSサーバーのIPアドレスを入力します。 デフォルトでは、100.100.2.136または100.100.2.138を選択できます。
宛先ポート:
53プロトコル:
udp
警告を読み、[知っていると同意する] を選択し、[診断の作成] をクリックします。
[診断結果] ページで、診断結果を表示できます。 [パケットパス] セクションには、診断されたすべてのノードが表示されます。
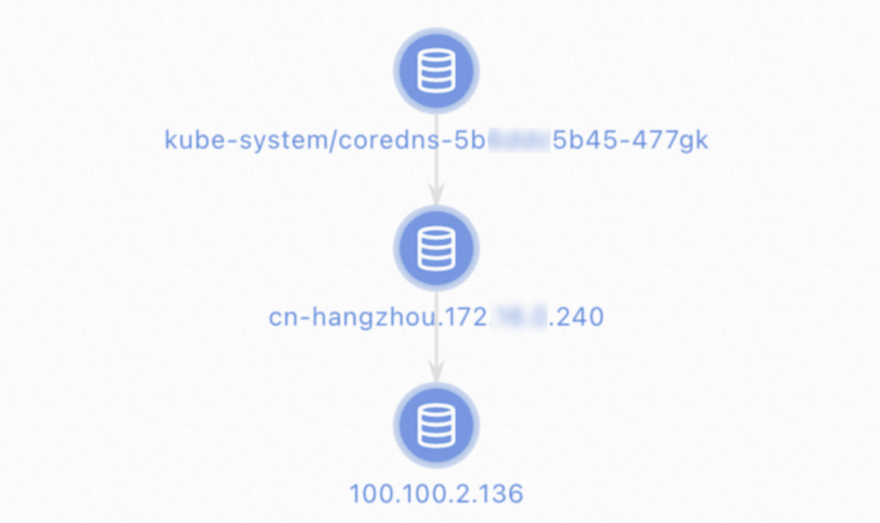
CLIの使用
手順
CoreDNSポッドが実行されているノードにログインします。
を実行します。Run the
ps aux | grep corednsコマンドを実行して、CoreDNSプロセスのIDを照会します。nsenter -t <pid> -n -- <related commands>コマンドを実行して、CoreDNSが属するネットワーク名前空間を入力します。pidを、前の手順で取得したcorednsのプロセスIDに置き換えます。ネットワーク接続をテストします。
を実行します。Run the
telnet <apiserver_clusterip> 6443コマンドを実行して、クラスターのKubernetes APIサーバーへの接続をテストします。apiserver_clusteripを、クラスターのKubernetes APIサーバーを公開するために使用されるサービスのIPアドレスに置き換えます。を実行します。Run the
dig <domain> @<upstream_dns_server_ip>コマンドを実行して、CoreDNSポッドとアップストリームDNSサーバー間の接続をテストします。domainをテストドメイン名に置き換え、upstream_dns_server_ipをアップストリームDNSサーバーのIPアドレス (デフォルトでは100.100.2.136および100.100.2.138) に置き換えます。
トラブルシューティング
問題 | 原因 | 解決策 |
CoreDNSは、クラスターのKubernetes APIサーバーに接続できません。 | クラスターのKubernetes APIサーバーでエラーが発生したり、ノードが過負荷になったり、kube-proxyが期待どおりに実行されなかったりします。 | |
CoreDNSはアップストリームDNSサーバーに接続できません。 | ノードが過負荷になっているか、CoreDNS設定が間違っているか、Express Connect回路のルーティング設定が正しくありません。 |
アプリケーションポッドとCoreDNSポッド間のネットワーク接続の診断
コンソールまたはCLIを使用して、アプリケーションポッドとCoreDNSポッド間のネットワーク接続を診断できます。
コンソールの使用
ACKコンソールにログインします。 左側のナビゲーションウィンドウで、[クラスター] をクリックします。
[クラスター] ページで、診断するクラスターの名前をクリックします。 左側のナビゲーションウィンドウで、[検査と診断]> [診断] を選択します。
[診断] ページで、[ネットワーク診断] をクリックします。
[ネットワーク診断] ページで、[診断] をクリックします。 [ネットワーク] パネルで、次のパラメーターを設定します。
送信元アドレス: アプリケーションポッドのIPアドレスを入力します。
宛先アドレス: CoreDNSポッドまたはクラスターのIPアドレスを入力します。
宛先ポート:
53プロトコル:
udp
警告を読み、[知っていると同意する] を選択し、[診断の作成] をクリックします。
[診断結果] ページで、診断結果を表示できます。 [パケットパス] セクションには、診断されたすべてのノードが表示されます。
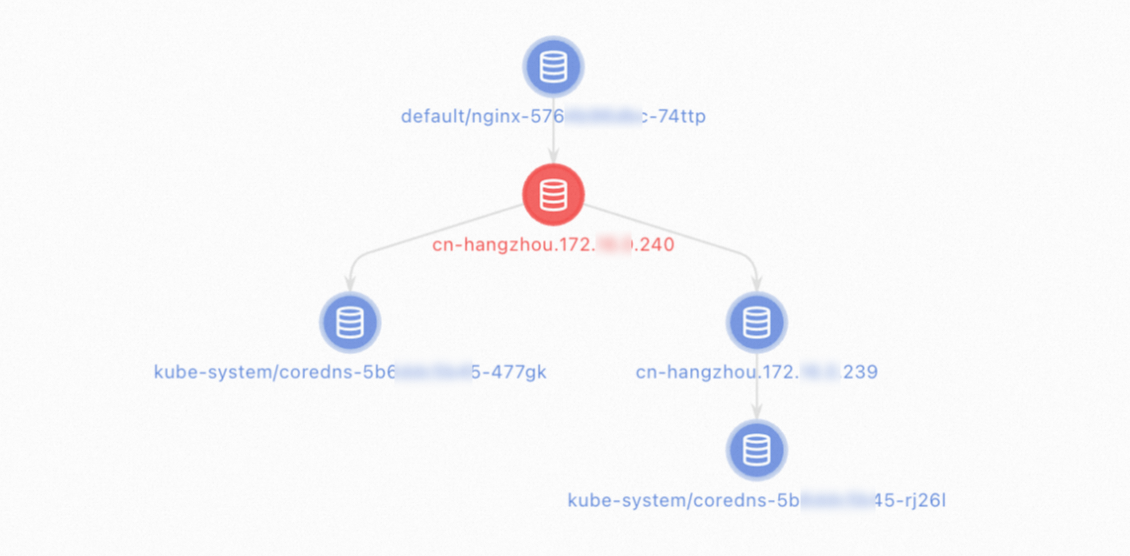
CLIの使用
手順
次のいずれかの方法を使用して、アプリケーションポッドのコンテナネットワークに接続します。
方法1:
kubectl execコマンドを実行します。方法 2
アプリケーションポッドが実行されているノードにログインします。
ps aux | grep <Application process name>コマンドを実行して、アプリケーションプロセスのIDを照会します。nsenter -t <pid> -n bashコマンドを実行し、アプリケーションポッドが属する名前空間を入力します。pidを前の手順で取得したプロセスIDに置き換えます。
方法3: アプリケーションポッドが頻繁に再起動する場合は、次の手順を実行します。
アプリケーションポッドが実行されているノードにログインします。
docker ps -a | grep <Application container names>コマンドを実行して、名前がk8s_POD_で始まるコンテナを照会します。 返されるサンドボックス化されたコンテナIDを記録します。docker inspect <Sandboxed container ID> | grep netnsコマンドを実行して、/var /Run /docker/netns/xxxxファイル内のコンテナが属するネットワーク名前空間のパスを照会します。nsenter -n<netns path> -n bashコマンドを実行し、ネットワーク名前空間を入力します。netns pathを前の手順で取得したパスに置き換えます。説明-nと<netns path>の間にスペースを追加しないでください。
ネットワーク接続をテストします。
dig <domain> @<kube_dns_svc_ip>コマンドを実行して、アプリケーションポッドとkube-dns Service間の接続をテストします。<domain>をテストドメイン名に、<kube_dns_svc_ip>をkube-system名前空間のkube-dnsサービスのIPアドレスに置き換えます。を実行します。Run the
ping <coredns_pod_ip>コマンドを実行して、アプリケーションポッドとCoreDNSポッド間の接続をテストします。<coredns_pod_ip>をkube-system名前空間のCoreDNSポッドのIPアドレスに置き換えます。を実行します。Run the
dig <domain> @<coredns_pod_ip>コマンドを実行して、アプリケーションポッドとCoreDNSポッド間の接続をテストします。<domain>をテストドメイン名に、<coredns_pod_ip>をkube-system名前空間のCoreDNSポッドのIPアドレスに置き換えます。
トラブルシューティング
問題 | 原因 | 解決策 |
アプリケーションポッドはkube-dnsサービスに接続できません。 | ノードが過負荷になっているか、kube-proxyが期待どおりに実行されないか、セキュリティグループルールがUDPポート53をブロックします。 | セキュリティグループルールがUDPポート53を開いているかどうかを確認します。 セキュリティグループルールがUDPポート53を開くと、チケットの送信します。 |
アプリケーションポッドはCoreDNSポッドに接続できません。 | コンテナネットワークに関連するエラーが発生するか、セキュリティグループルールがインターネット制御メッセージプロトコル (ICMP) トラフィックをブロックします。 | セキュリティグループルールがICMPを開いているかどうかを確認します。 セキュリティグループのルールがICMPを開くと、チケットの送信します。 |
アプリケーションポッドはCoreDNSポッドに接続できません。 | ノードが過負荷になるか、セキュリティグループルールがUDPポート53をブロックします。 | セキュリティグループルールがUDPポート53を開いているかどうかを確認します。 セキュリティグループルールがUDPポート53を開くと、チケットの送信します。 |
パケットのキャプチャ
問題を特定できない場合は、パケットをキャプチャして診断します。
アプリケーションポッドとCoreDNSポッドが実行されているノードにログインします。
各ECSインスタンスで次のコマンドを実行して、ポート53で受信した最近のパケットをすべてキャプチャします。
tcpdump -i any port 53 -C 20 -W 200 -w /tmp/client_dns.pcapエラーが発生した期間に転送されるパケットを診断します。
説明パケットキャプチャはサービスに影響を与えず、CPU使用率とディスクI/Oのわずかな増加のみを引き起こします。
前述のコマンドは、キャプチャされたパケットをローテーションし、最大で200を生成できます。pcapファイルのサイズはそれぞれ20 MBです。
クラスターの外部ドメイン名を解決できない場合はどうすればよいですか。
問題の説明
クラスターの内部ドメイン名は解決できますが、クラスターの外部ドメイン名は解決できません。
原因
外部ドメイン名が解決されたときのアップストリームDNSサーバーのエラー。
解決策
CoreDNSのDNSクエリログを確認します。
共通DNSクエリログ
CoreDNSがクライアントのDNSクエリに応答した後、CoreDNSはDNSクエリを記録するログエントリを生成します。
# If the response code is NOERROR, the domain name is resolved without errors.
[INFO] 172.20.2.25:44525 - 36259 "A IN redis-master.default.svc.cluster.local. udp 56 false 512" NOERROR qr,aa,rd 110 0.000116946s一般的な応答コード
DNSレスポンスコードの詳細については、「ドメイン名-IMPLEMENTATION AND SPECIFICATION」をご参照ください。
応答コード | 説明 | 原因 |
NXDOMAIN | ドメイン名がアップストリームDNSサーバーに存在しません。 | ポッド要求のドメイン名には、検索ドメインサフィックスが追加されます。 DNSサーバーにサフィックス付きドメイン名が存在しない場合、この応答コードが返されます。 DNSクエリログでこの応答コードが見つかった場合、ドメイン名解決エラーが発生しました。 |
サービス | 上流DNSサーバでエラーが発生しました。 | 上流DNSサーバでエラーが発生しました。 たとえば、アップストリームDNSサーバーへの接続は確立できません。 |
払い戻し | DNSクエリは、アップストリームDNSサーバーによって拒否されます。 | CoreDNS設定またはノードの /etc/resolv.confファイルで指定されているアップストリームDNSサーバーがドメイン名を解決できません。 CoreDNSの設定ファイルを確認できます。 |
CoreDNSのDNSクエリログに、クラスターの外部ドメイン名のNXDOMAIN、SERVFAIL、またはREFUSEDが表示された場合、CoreDNのアップストリームDNSサーバーはエラーを返します。
デフォルトでは、Virtual Private Cloud (VPC) が提供するDNSサーバー100.100.2.136および100.100.2.138は、CoreDNSのアップストリームDNSサーバーとして使用されます。 前述のエラーを解決するには、 ECSチームにチケットを起票してください。 次の表に記載されている情報をチケットに含める必要があります。
項目 | 説明 | 例 |
ドメイン名 | DNSクエリログのDNS応答コードに対応するクラスター外部ドメイン名。 | www.aliyun.com |
DNS応答コード | 返されるDNS応答コード。NXDOMAIN、SERVFAIL、またはREFUSEDのいずれかです。 | NXDOMAIN |
時間 | ログエントリが生成された時刻 (秒単位) 。 | 2022-12-22 20:00:03 |
ECS インスタンス | CoreDNSポッドをホストするECSインスタンスのID。 | i-xxxxx i-yyyyy |
ヘッドレスサービスのドメイン名を解決できない場合はどうすればよいですか?
問題の説明
CoreDNSは、ヘッドレスサービスのドメイン名を解決できません。
原因
1.7.0より前のCoreDNSバージョンが使用されている場合、クラスターのKubernetes APIサーバーでネットワークジッターが発生すると、CoreDNSが予期せず終了することがあります。 その結果、CoreDNSがダウンしてもヘッドレスサービスのドメイン名は更新されません。
解決策
CoreDNSを1.7.0以降に更新します。 詳細については、「 [コンポーネントの更新] Update CoreDNS」をご参照ください。
ヘッドレスサービスのドメイン名の解決に失敗した場合はどうすればよいですか?
問題の内容
CoreDNSポッドは、ヘッドレスサービスのドメイン名を解決できません。 digコマンドを使用すると、レスポンスにtcフラグが表示されます。これは、レスポンスが大きすぎることを示します。
原因
ヘッドレスドメインネームに対応するIPアドレスの数が大きすぎる場合、UDPを介してクライアントによって送信されるDNSクエリは、UDP DNSパケットのサイズ制限を超える可能性があります。 この結果、解決の失敗が生じる。
解決策
解決の失敗を回避するには、TCP経由でDNSクエリを送信するようにクライアントアプリケーションを設定します。 CoreDNSはTCPとUDPの両方をサポートします。 さまざまなビジネスシナリオに基づいてプロトコルを変更できます。
glibc関連のリゾルバーを使用します。
クライアントアプリケーションがglibc関連のリゾルバーを使用している場合は、
use-vc設定をdnsConfigに追加できます。このように、クライアントアプリケーションはTCPを介してDNSクエリを送信します。 これらの設定は、/etc/resolv.confファイルの対応するoptions設定にマッピングされます。オプションの詳細については、「Linuxマニュアルページ」をご参照ください。dnsConfig: options: - name: use-vcGolangによって実装されたビジネスコードロジック
開発にGolangを使用する場合は、次のコードを参照してTCP経由でDNSクエリを送信できます。
package main import ( "fmt" "net" "context" ) func main() { resolver := &net.Resolver{ PreferGo: true, Dial: func(ctx context.Context, network, address string) (net.Conn, error) { return net.Dial("tcp", address) }, } addrs, err := resolver.LookupHost(context.TODO(), "example.com") if err != nil { fmt.Println("Error:", err) return } fmt.Println("Addresses:", addrs) }
CoreDNSの更新後にヘッドレスサービスのドメイン名を解決できない場合はどうすればよいですか?
問題の説明
etcd、Nacos、Kafkaなどの以前のバージョンのオープンソースコンポーネントは、Kubernetes 1.20以降およびCoreDNS 1.8.4以降が使用されている場合、期待どおりに機能しません。
原因
CoreDNS 1.8.4以降は、EndpointSlice APIを使用して、クラスター内のサービスのIPアドレスを同期します。 一部のオープンソースコンポーネントでは、準備ができていないサービスを公開するために、初期化フェーズ中にEndpoint APIによって提供されたservice.alpha.kubernetes.io /relenate-unready-endpointsアノテーションを使用します。 このアノテーションはEndpointSlice APIで廃止され、publishNotReadyAddressesに置き換えられました。 したがって、CoreDNSの更新後に準備ができていないサービスをリリースすることはできません。 その結果、オープンソースコンポーネントは、サービス発見を実行することができない。
解決策
オープンソースコンポーネントのYAMLファイルまたはHelm Chartファイルにservice.alpha.kubernetes.io /tolerance-unready-endpointsアノテーションが含まれているかどうかを確認します。 オープンソースコンポーネントにアノテーションが含まれている場合、オープンソースコンポーネントは期待どおりに機能しない可能性があります。 この場合、オープンソースコンポーネントをアップグレードするか、オープンソースコンポーネントコミュニティを参照する必要があります。
StatefulSetポッドのドメイン名を解決できない場合はどうすればよいですか?
問題の説明
StatefulSetポッドのドメイン名は解決できません。
原因
headless Serviceを使用してStatefulSetを公開する場合は、ポッドYAMLテンプレートのServiceNameパラメーターをheadless Serviceの名前に設定する必要があります。 それ以外の場合は、ポッド. headless-svc.ns.svc.cluster.localなどのStatefulSetポッドのドメイン名にアクセスできません。 ただし、headless-svc.ns.svc.cluster.localなどのヘッドレスサービスのドメイン名にアクセスできます。
解決策
ポッドYAMLテンプレートのServiceNameパラメーターを、StatefulSetポッドを公開するために使用されるヘッドレスサービスの名前に設定します。
DNSクエリがセキュリティグループルールまたはvSwitchに関連付けられているネットワークACLによってブロックされている場合はどうすればよいですか?
問題の説明
CoreDNSのDNS解決の失敗は、一部またはすべてのノードで持続します。
原因
ECSインスタンスブロックUDPポート53のネットワーク通信を制御するセキュリティグループルールまたはネットワークアクセス制御リスト (ACL) 。
解決策
セキュリティグループルールまたはネットワークACLを変更して、UDPポート53を開きます。
コンテナネットワーク接続エラーが発生した場合はどうすればよいですか。
問題の説明
CoreDNSのDNS解決の失敗は、一部またはすべてのノードで持続します。
原因
UDPポート53は、コンテナネットワーク接続エラーまたはその他の原因によりブロックされています。
解決策
ネットワーク診断機能を使用して、アプリケーションポッドとCoreDNSポッド間のネットワーク接続を診断できます。 問題が解決しない場合は、チケットの送信します。
CoreDNSポッドがオーバーロードされた場合はどうすればよいですか?
問題の説明
CoreDNSのDNS解決レイテンシが高いか、またはCoreDNSのDNS解決失敗が一部またはすべてのノードで持続するか、時折発生します。
CoreDNSポッドのステータスを確認し、CPUとメモリの使用率が上限に近づいているかどうかを確認します。
原因
CoreDNS用に設定されているレプリケートされたポッドの数は、DNSクエリを処理するには不十分です。
解決策
NodeLocal DNSCacheを使用してDNS解決効率を向上させ、CoreDNSの負荷を軽減します。 詳細については、「NodeLocal DNSCacheの設定」をご参照ください。
CoreDNSポッドをスケールアウトして、各ポッドのピークCPU使用率がノードのアイドルCPUリソースの量よりも少なくなるようにします。
DNSクエリの負荷がCoreDNSポッド間でバランスが取れていない場合はどうすればよいですか?
問題の説明
CoreDNSのDNS解決レイテンシが高いか、またはCoreDNSのDNS解決失敗が一部のノードで持続するか、時折発生します。
CoreDNSポッドのステータスは、CPU使用率がポッド間で異なることを示しています。
CoreDNS用に設定されているレプリケートされたポッドの数が2つ未満であるか、同じノードに複数のCoreDNSポッドがデプロイされています。
原因
DNSクエリは、ポッドスケジューリングの不均衡またはkube-dns Serviceの不適切なSessionAffinity設定により、CoreDNSポッド間で均等に分散されません。
解決策
CoreDNSポッドをスケールアウトし、ポッドを異なるノードにスケジュールします。
kube-dns Serviceの設定からSessionAffinityパラメーターを削除できます。 詳細については、「CoreDNSを自動的に更新するためのACKの設定」トピックの「kube-dnsサービスの設定」をご参照ください。
CoreDNSポッドが期待どおりに実行されない場合はどうすればよいですか?
問題の説明
CoreDNSのDNS解決レイテンシが高いか、またはCoreDNSのDNS解決失敗が一部のノードで持続するか、時折発生します。
CoreDNSポッドが [実行中] 状態でないか、ポッドの再起動回数が継続的に増加します。
CoreDNSログデータは、エラーが発生したことを示します。
原因
YAMLファイルまたはCoreDNS ConfigMapの設定が不適切なため、CoreDNSポッドは期待どおりに実行されません。
解決策
CoreDNSポッドのステータスと実行ログを確認します。
一般的なエラーログとソリューション
エラー | 原因 | 解決策 |
| CoreDNS ConfigMapの設定は、現在のCoreDNSバージョンと互換性がありません。 エラーレコードの | kube-system名前空間のCoreDNS ConfigMapから準備完了プラグインを削除します。 エラーログに他のプラグインが表示されている場合は、ConfigMapからプラグインを削除します。 |
| Kubernetes APIサーバーへの接続は、ログが生成された期間中に中断されます。 | この期間にDNS解決エラーが発生しない場合、ネットワーク接続の問題が原因ではありません。 それ以外の場合は、CoreDNSポッドのネットワーク接続を確認します。 詳細については、このトピックの「CoreDNSポッドのネットワーク接続の診断」をご参照ください。 |
| ログが生成された期間中は、上流DNSサーバへの接続を確立できません。 |
クライアントが過負荷になったためにDNS解決が失敗した場合はどうすればよいですか?
問題の説明
DNS解決エラーは、時折またはピーク時に発生します。 ECSインスタンスに関するモニタリング情報は、ネットワークインターフェイスコントローラー (NIC) の異常な再送信率と異常なCPU使用率を示しています。
原因
DNSクエリをCoreDNSに送信するポッドをホストするECSインスタンスが完全にロードされているため、UDPパケットが失われます。
解決策
お勧めします チケットの送信して問題のトラブルシューティングを行います。
NodeLocal DNSCacheを使用してDNS解決効率を向上させ、CoreDNSの負荷を軽減します。 詳細については、「NodeLocal DNSCacheの設定」をご参照ください。
conntrackテーブルがいっぱいの場合はどうすればよいですか?
問題の説明
CoreDNSは、ピーク時に一部またはすべてのノードのドメイン名の解決に失敗することがよくありますが、オフピーク時には予想どおりにドメイン名を解決できます。
インスタンスで
dmesg -Hコマンドを実行し、解決が失敗した期間中に生成されたログを確認します。 ログには、キーワードconntrack fullが含まれています。
原因
Linuxカーネルのconntrackテーブルがいっぱいです。 その結果、UDPまたはTCPを介して送信されたリクエストは処理できません。
解決策
Linuxカーネルのconntrackテーブルのエントリの最大数を増やします。 詳細については、「」をご参照ください。Linuxカーネルのconntrackテーブルで追跡される接続の最大数を増やすにはどうすればよいですか? 「コンテナネットワークに関するFAQ」トピックのセクション。
オートパスプラグインが期待どおりに機能しない場合はどうすればよいですか?
問題の説明
外部ドメイン名の解決に失敗するか、誤ったIPアドレスに解決されることがあります。 ただし、内部ドメイン名は期待どおりに解決されます。
クラスターが高い頻度でコンテナを作成すると、内部ドメイン名が間違ったIPアドレスに解決されます。
原因
CoreDNSの欠陥のため、オートパスプラグインは期待どおりに機能しません。
解決策
次の操作を実行して、autopathプラグインを無効にします。
kubectl -n kube-system edit configmap corednsコマンドを実行して、coredns ConfigMapを変更します。autopath @ kubernetesを削除し、変更を保存して終了します。CoreDNSポッドのステータスと実行ログを確認します。 ログデータに
reloadキーワードが含まれている場合、新しい設定が読み込まれます。
AレコードとAAAAレコードの同時クエリによりDNS解決が失敗した場合はどうすればよいですか。
問題の説明
CoreDNSのDNS解決が失敗することがあります。
キャプチャされたパケットまたはCoreDNSへのDNSクエリのログは、AレコードとAAAAレコードのクエリが同じポートで同時に開始されることを示しています。
原因
AレコードとAAAAレコードの同時DNSクエリにより、Linuxカーネルのconntrackテーブルにエラーが発生し、UDPパケットが失われます。
バージョンが2.33より前のGNU Cライブラリ (libc) は、ARMマシンでAレコードとAAAAレコードのクエリを同時に開始します。 その結果、クエリはタイムアウトし、再開されます。 詳細については、「GLIBC#26600」をご参照ください。
解決策
NodeLocal DNSCacheを使用してDNS解決効率を向上させ、CoreDNSの負荷を軽減します。 詳細については、「NodeLocal DNSCacheの設定」をご参照ください。
CentOSやUbuntuイメージなど、libcを使用するイメージの場合は、AレコードとAAAAレコードのクエリが同時に開始される問題を防ぐために、libcのバージョンを2.33以降に更新します。
options timeout:2試行: 3 rotate single-request-reopenなどのパラメータを設定することで、CentOSとUbuntuのイメージを最適化できます。使用するイメージがAlpine Linuxに基づいている場合は、そのイメージを別のオペレーティングシステムに基づいているイメージに置き換えることをお勧めします。 詳細については、「Alpine」をご参照ください。
PHPで記述されたアプリケーションが短期間の接続を使用してDNSクエリを送信すると、さまざまな解決エラーが発生する可能性があります。 PHP cURLを使用する場合は、
CURL_IPRESOLVE_V4を追加して、ドメイン名をIPv4アドレスにのみ解決できるように指定する必要があります。 詳細については、「cURL_setopt」をご参照ください。
IPVSエラーのためにDNS解決が失敗した場合はどうすればよいですか?
問題の説明
ノードがクラスターに追加またはクラスターから削除されたり、ノードがシャットダウンされたり、CoreDNSがスケールインされたりすると、DNS解決が失敗することがあります。 ほとんどの場合、この状況は約5分間続きます。
原因
kube-proxyの負荷分散モードは、クラスター内のIP仮想サーバー (IPVS) に設定されています。 カーネルバージョンが4.19.91-25.1.al7.x86_64より前のCentOSまたはAlibaba Cloud Linux 2を実行するノードからIPVS UDPバックエンドポッドを削除すると、UDPパケットの送信時にソースポートの競合が発生します。 その結果、UDPパケットはドロップされる。
解決策
NodeLocal DNSCacheを使用して、IPVSモードでのパケット損失を減らします。 詳細については、「NodeLocal DNSCacheの設定」をご参照ください。
IPVSモードでのUDPセッションのタイムアウト期間を短縮します。 詳細については、「CoreDNSを自動的に更新するようにACKを設定する」トピックの「IPVSモードでのUDPタイムアウト期間の変更」をご参照ください。
NodeLocal DNSCacheが機能しない場合はどうすればよいですか?
問題の説明
すべてのDNSクエリは、NodeLocal DNSCacheではなくCoreDNSに送信されます。
原因
DNSConfigはアプリケーションポッドに注入されません。 kube-dns ServiceのIPアドレスは、アプリケーションポッドのDNSサーバーのアドレスとして設定されます。
アプリケーションポッドは、Alpine Linuxベースのイメージを使用してデプロイされます。 その結果、DNSクエリは、ローカルDNSキャッシュとCoreDNSポッドを含むすべてのネームサーバーに同時に送信されます。
解決策
DNSConfigの自動注入を設定します。詳細については、「NodeLocal DNSCacheの設定」をご参照ください。
使用するイメージがAlpine Linuxに基づいている場合は、そのイメージを別のオペレーティングシステムに基づいているイメージに置き換えることをお勧めします。 詳細については、「Alpine」をご参照ください。
Alibaba Cloud DNS PrivateZoneに追加されたドメイン名が解決できない場合はどうすればよいですか。
問題の説明
NodeLocal DNSCacheを使用すると、Alibaba Cloud DNS PrivateZoneに追加されたドメイン名を解決できないか、vpc-proxyを含むAlibaba CloudサービスAPIのエンドポイントを解決できないか、ドメイン名が間違ったIPアドレスに解決されます。
原因
Alibaba Cloud DNS PrivateZoneはTCPをサポートしていません。 UDPを使用する必要があります。
解決策
CoreDNSにprefer_udp設定を追加します。 詳細については、「CoreDNSの設定」をご参照ください。