Background
Keyword search and limitations
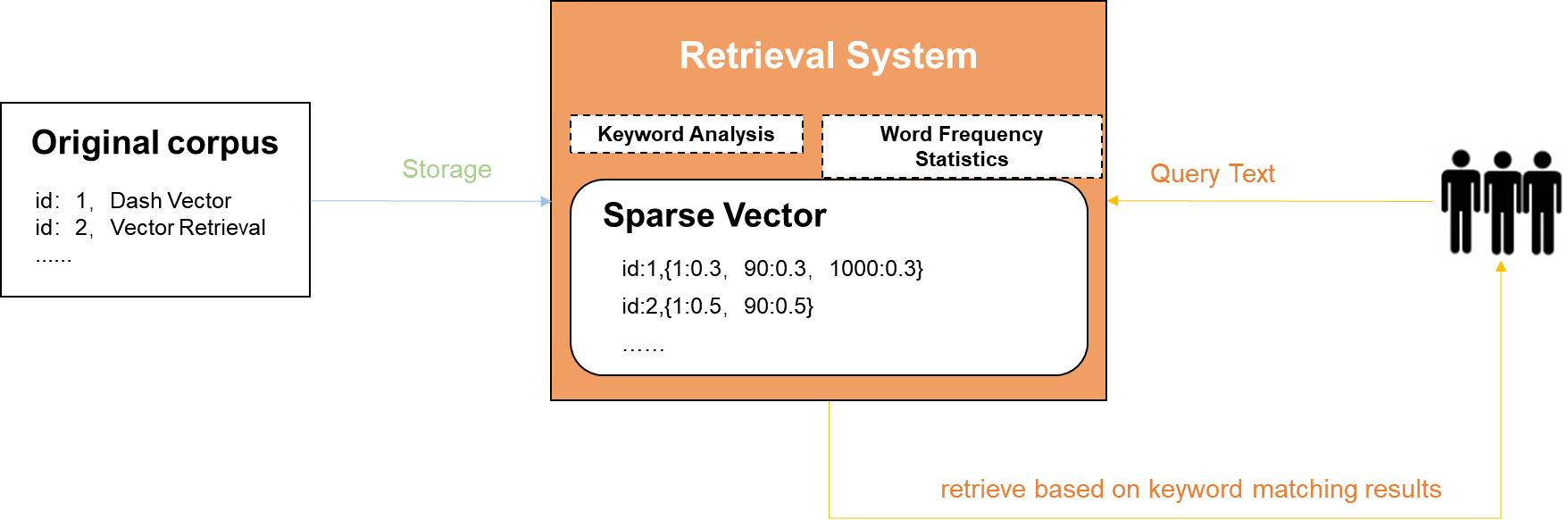
Traditionally, information search is implemented based on keywords in the following process:
Keywords are extracted from corpuses, such as web pages.
Mappings are established between these keywords and corpuses by creating inverted indexes and applying algorithms such as Term Frequency - Inverse Document Frequency (TF-IDF) and Best Match 25 (BM25). In TF-IDF and BM25, sparse vectors are usually used to represent term frequency.
During a search, keywords are extracted from the search terms and are used to recall top K corpuses by similarity based on the mappings established in step 2.

However, keyword search lacks the ability to determine the contextual meaning of the search terms. For example, if you search for "rain cats and dogs," which is an idiom meaning "raining heavily," the search may return documents about the keywords "rain," "cats," and "dogs" but not the idiomatic meaning.
Semantic vector search
Semantic embedding models are getting stronger thanks to evolving AI technologies. Gradually, semantic vector search becomes a mainstream method for information recall. The implementation process is as follows:
Vectors, more specifically, dense vectors, are generated from corpuses (such as web pages) by using an embedding model.
Vectors are stored in a vector search system.
During a search, a vector is generated from the search term by using the embedding model and used to recall top K corpuses with the shortest distance from the vector search system.
Undoubtedly, semantic vector search has its limitations. That is, it relies on continuous optimization of the embedding model in terms of semantic understanding to get better results. For example, if the model cannot tell that "rice irrigating" and "irrigating rice" have similar meanings, corpuses about "irrigating rice" cannot be recalled for the search term "rice irrigating." Keyword search performs better in this case, as it can effectively recall corpuses based on the keywords "rice" and "irrigating."
Keyword search + Semantic vector search
To overcome the preceding disadvantages, some services and systems are developed to implement both keyword search and semantic vector search and rank records recalled using both methods together, as shown in the following figure. This way, better search performance can be achieved compared to the sole implementation of keyword search or semantic vector search.
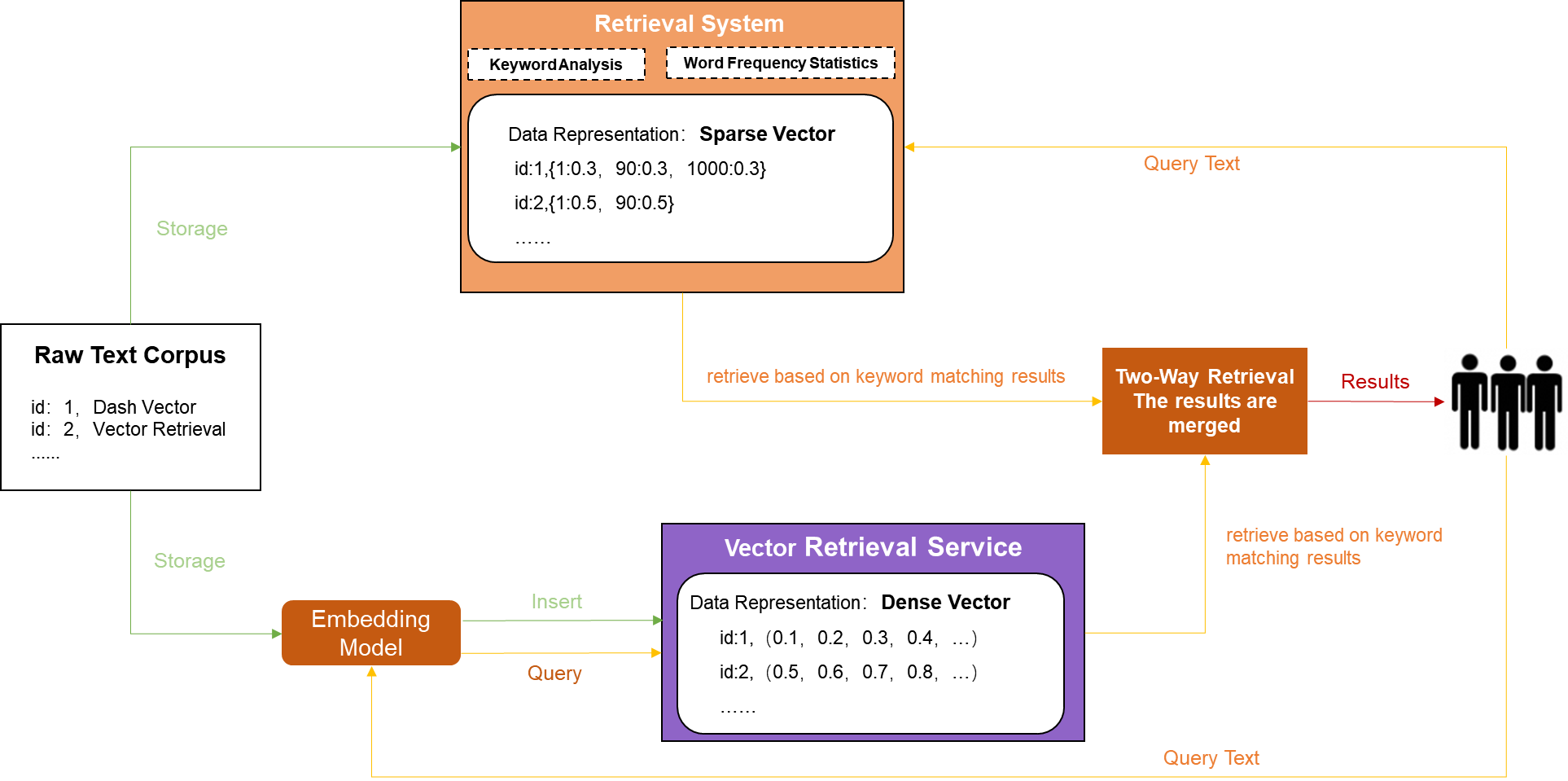
However, this compound search method brings the following disadvantages:
System complexity increases.
More hardware resources (memory, CPU, and disk resources) are consumed.
Maintainability is compromised.
......
Keyword-aware semantic search
DashVector supports both dense vectors and sparse vectors. Dense vectors are used to represent features of high-dimensional data through embedding, and sparse vectors are used to represent keywords and term frequency. When DashVector employs both vectors in its search mechanism, it performs a keyword-aware semantic search.

This search method leverages the strengths of the above three search methods while minimizing their limitations, such as increased system complexity and resource overheads, at the same time. This balance between effectiveness and efficiency makes DashVector a versatile tool, suitable for most business scenarios.
A sparse vector consists of many zero values and very few non-zero values. In DashVector, a sparse vector can be used to represent information such as term frequency. For example, in the sparse vector {1:0.4, 10000:0.6, 222222:0.8}, only elements 1, 10000, and 222222, which represent three different keywords, have non-zero values. These values represent the weights of the keywords.
Example
Prerequisites
A cluster is created. For more information, see Create a cluster.
An API key is obtained. For more information, see Manage API keys.
The SDK of the latest version is installed. For more information, see Install DashVector SDK.
Step1. Create a collection that supports sparse vectors
You need to replace YOUR_API_KEY with your API key and YOUR_CLUSTER_ENDPOINT with your cluster endpoint in the sample code for the code to run properly.
This example demonstrates a search by using sparse vectors. For simplicity, the number of dense vector dimensions is set to 4.
import dashvector
client = dashvector.Client(
api_key='YOUR_API_KEY',
endpoint='YOUR_CLUSTER_ENDPOINT'
)
ret = client.create('hybrid_collection', dimension=4, metric='dotproduct')
collection = client.get('hybrid_collection')
assert collectionOnly collections that use the dot product metric (metric='dotproduct') support sparse vectors.
Step 2. Insert a document containing a sparse vector
from dashvector import Doc
collection.insert(Doc(
id='A',
vector=[0.1, 0.2, 0.3, 0.4],
sparse_vector={1: 0.3, 10:0.4, 100:0.3}
))Step 3. Initiate a vector search containing a sparse vector
docs = collection.query(
vector=[0.1, 0.1, 0.1, 0.1],
sparse_vector={1: 0.3, 20:0.7}
)Sparse vector encoder
DashText is a sparse vector encoder recommended for DashVector. For more information, see Quick start.