Realtime Compute for Apache Flink supports monitoring and alerting using Cloud Monitor (free) or Application Real-Time Monitoring Service (ARMS). You can configure alerts for job metrics, job events, and workflows to quickly detect and resolve anomalies. This topic describes how to configure monitoring and alerts for each service.
Limits
Alert rules are not supported for Flink jobs that are submitted to session clusters.
Alert rules are not supported for batch jobs.
Workflow alerts are not supported in ARMS. You can use the free Cloud Monitor service instead.
Configuration overview
The configuration method that you can use depends on the monitoring service type of your workspace. For more information, see How do I check the monitoring service type for my workspace?.
Cloud Monitor (free)
Metric-based alerts: These alerts are triggered based on metric values, such as CPU usage, latency, or data volume. You can apply these alerts to a single job or a batch of jobs.
Event-based alerts (including workflows): These alerts are triggered when specific events, such as job failures, occur. You can apply these alerts to jobs and workflow events.
ARMS monitoring service
Metric-based alerts: These alerts are triggered based on six core metrics. You can apply these alerts to a single job or a batch of jobs.
Event-based alerts: This method supports only job failure events. To configure alerts for other events, use Cloud Monitor event-based alerts (including workflows).
Switch monitoring service types
You can switch monitoring service types to meet different business needs.
In the Realtime Compute console, you can click More in the Actions column for your target workspace to switch to another monitoring service type.
Before you switch the service type, carefully read the notes and select the confirmation checkbox.
Configure monitoring and alerts with Cloud Monitor
Metric-based alerts
Alerts in Cloud Monitor can be configured only by the Alibaba Cloud account that purchased the workspace, or by RAM users and RAM roles that have been granted namespace permissions by that account.
-
Log on to the Cloud Monitor console.
In the left navigation pane, choose .
Click Create Alert Rule and configure the parameters.
Parameter
Description
Product
Realtime Compute for Apache Flink
Resource Range
Select Instances. The alert rule applies to a specific Realtime Compute for Apache Flink workspace.
Associated Resources
Click Add Instance. In the dialog, select your destination region and your workspace (How do I view information such as the workspace ID?), and click OK.
Rule Description
Click +Add Rule > Simple Metric or Combined Metrics to open the Configure Rule Description panel.
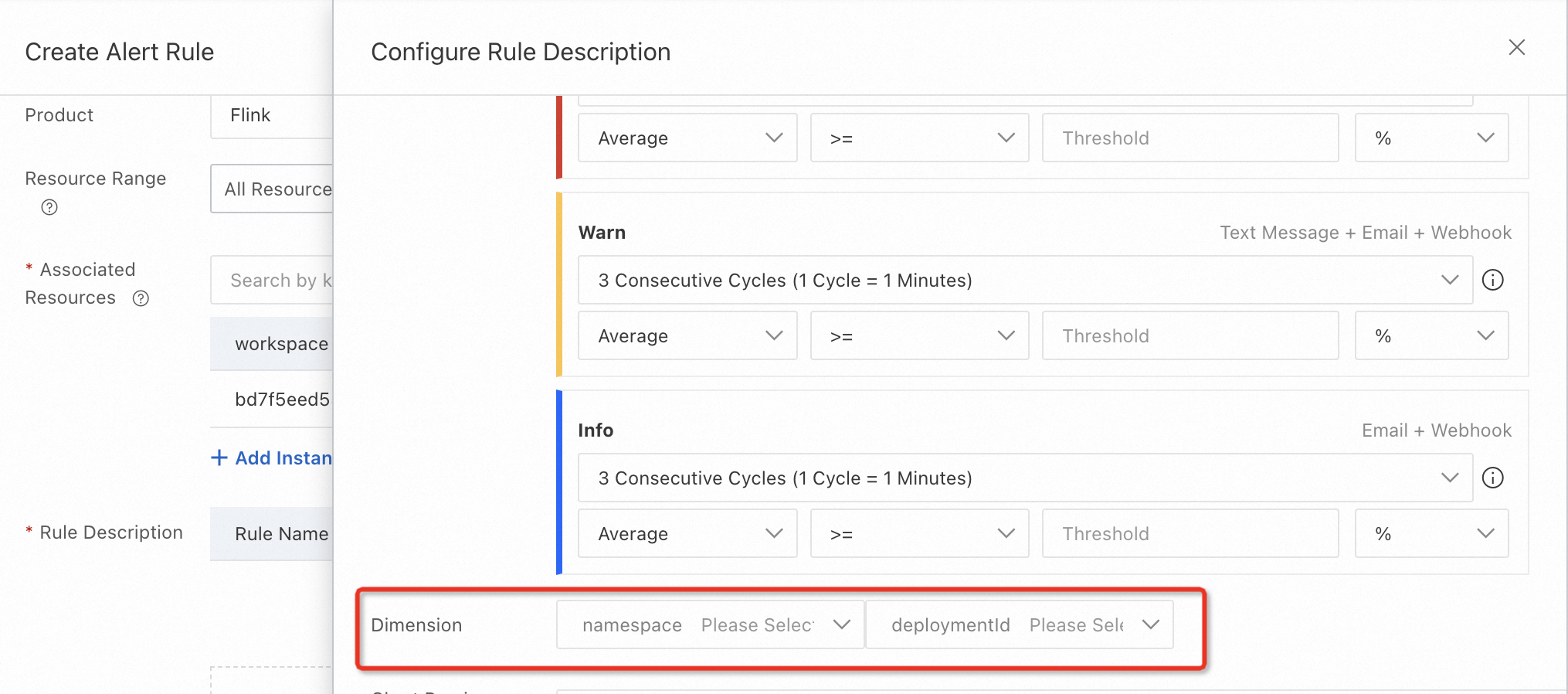
In the Dimension section, you can configure namespace (Flink project name) and deploymentID (the Deployment Job ID from the Deployment Details tab of the corresponding Flink job) to specify the job to monitor.
NoteIf the drop-down lists are empty, enter the namespace and deployment ID manually.
Leaving these fields blank monitors all jobs across all namespaces.
NoteIn a production environment, single-metric alerts may cause false positives or false negatives. Combined-metric alerts can more accurately reflect business anomalies. For more information, see Recommended monitoring configurations.
For more information about the other parameters, see Create an alert rule.
Event-based alerts (including workflows)
Alerts can be configured and events can be subscribed to in Cloud Monitor only by the Alibaba Cloud account that purchased the workspace, or by RAM users and RAM roles that have been granted namespace permissions by that account.
Job event alerts
You can subscribe to system event alerts for jobs by setting conditions and configure batch alerts for events.
-
Log on to the Cloud Monitor console.
In the navigation pane on the left, choose .
On the Subscription Policy tab, you can click Create Subscription Policy.
On the Create Subscription Policy page, you can configure the parameters. For details about other parameters, see Manage event subscriptions.
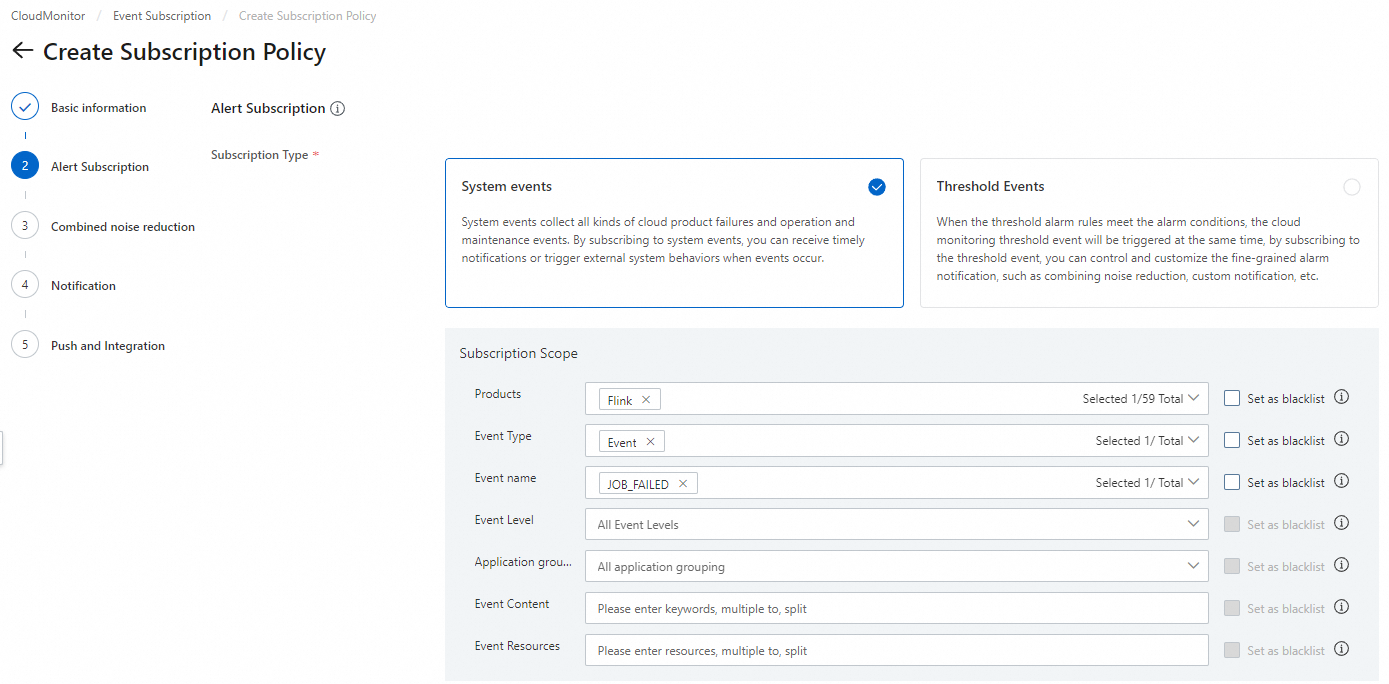
For Subscription Type, select System Events.
For Product, select Realtime Compute for Apache Flink.
Supported events include JOB_FAILED (not supported in ARMS), ECS.SystemFailure, and ECS.SystemMaintenance.
Event Content: Enter the following Flink information to configure alerts for specific jobs or in batches.
Workspace ID: This applies the alert rule to all jobs across all namespaces in the target workspace. For more information, see How do I view information such as the workspace ID?.
Namespace name: This applies the alert rule to all jobs in the target namespace.
Deployment name: This applies the alert rule to specific job deployments. You can separate multiple names with commas (
,). If duplicate deployment names exist, use the deployment ID.Deployment ID: Apply event alerting to specific jobs. Separate multiple IDs with commas (
,). You can find the Deployment ID on the Deployment Details tab of your Flink job, in the Deployment Job ID field.
NoteIf you leave Application group, Event Content, or Event Resources blank, the subscription applies to all workspaces in your account.
Workflow event alerts
You can configure conditions to subscribe to system event alerts for Flink workflows. Batch configuration is supported for event alerting. For more information about workflows, see Manage workflows.
Obtain the resource ID of the workflow task.
-
Log on to the Cloud Monitor console.
In the navigation pane on the left, choose .
On the Event Monitoring tab, set Product to Realtime Compute for Apache Flink, Event Name to Workflow Task State Change, and click Search.
Identify the resource ID of workflow nodes below.

The resource ID is in the
acs:flink:cn-hangzhou:<AlibabaCloudAccountID>:resourceId/workspaceId/<workspaceId-namespaceId>#workflowDefinitionName/<workflowDefinitionName>#taskDefinitionName/<taskDefinitionName>format. You can also construct the resource ID directly using this format.Parameter
Description
<AlibabaCloudAccountID>The Alibaba Cloud account ID that owns the Flink workspace.
<workspaceId-namespaceId>Consists of
workspaceIdandnamespaceId, joined by a hyphen (-).workspaceId: Your workspace ID. For more information, see Workspace and namespace FAQ.namespaceId: Your namespace name.<workflowDefinitionName>The workflow name.
<taskDefinitionName>The name of the workflow node.
NoteWorkflow state change events in Cloud Monitor may be delayed by a few minutes.
-
Subscribe to event notifications.
In the left navigation pane, choose .
On the Subscription Policy tab, click Create Subscription Policy.
On the Create Subscription Policy page, configure the policy. For more information, see Manage event subscriptions (Recommended).
Subscription type: System Event.
Product: Select Realtime Compute for Apache Flink.
Event Name: Select Pipeline Task State Change.
Event Content: Filter by transition state, such as
toState: FAILED(workflow failed),toState: SUCCESS(workflow succeeded), orfromState: SCHEDULED, toState: RUNNING(workflow transitioned from scheduled to running).Event Resources: Enter the resource ID that you obtained in Step 1. You can separate multiple IDs with commas (
,).Event Type, Event Level, and Application group: Leave these parameters empty.
Configure monitoring and alerts with ARMS
Metric-based alerts
To monitor multiple metrics in ARMS, you can use a custom PromQL statement. For a simpler setup, use Cloud Monitor metric-based alerts.
Single job configuration (Realtime Compute console)
You can create alert rules for target jobs or use existing alert rule templates to accelerate the configuration.
The Realtime Compute development console displays alert events from the last 48 hours. For the complete alert history, check Alert Management in the ARMS console.
Go to the alert configuration page.
Log on to the Realtime Compute console. Then, in the Actions column for your workspace, click Console.
On the page, click the name of the job that you want to manage.
Click the Alert Configuration tab.
On the Alert Rules tab, choose .
You can also choose to create alert rules directly or to modify them slightly after applying a template.
Enter the alert rule information.
Category
Parameter
Description
Specific Rules
Name
Start with a letter. Use lowercase letters, digits, and underscores (_). Length: 3 to 64 characters.
Description
Notes about the rule.
Content
Configure conditions that trigger the alert. After configuration, the system compares metric values against the threshold at regular intervals and triggers an alert if conditions are met.
Metric:
Restart Count in 1 Minute: Number of JobManager restarts per minute.
Checkpoint Count in 5 Minutes: Number of successful checkpoints per 5 minutes.
Emit Delay: Business latency, measured in seconds as the time difference between data generation and egress from the source operator.
ImportantEmit Delay accuracy depends on accurate timestamps from external systems. If external systems lack timestamps or record incorrect ones, Emit Delay will be inaccurate and fail to reflect true latency. To better reflect actual latency, configure composite metric alerts. For details, see Recommended monitoring configurations.
IN RPS: Input records per second.
OUT RPS: Output records per second.
Source Idle Time: Duration the source operator was idle, in milliseconds.
Job Failed: Job failure.
Time Interval: The length of the historical data window the system queries backward during each check, in minutes.
Comparator: Supports >= and <=.
Threshold: Value compared against the metric.
If you select >=, the system compares the maximum metric value against the threshold. An alert triggers if max_value >= threshold.
If you select <=, the system compares the minimum metric value against the threshold. An alert triggers if min_value <= threshold.
Example: Monitor Checkpoint Count in 5 Minutes with a 10-minute time interval, threshold of 2, and comparator <=.
The system checks every minute over the last 10 minutes. An alert triggers if any 5-minute period has a checkpoint count ≤ 2.
Effective Time
When the alert rule is active. Defaults to 24/7. You can restrict it to business hours (9 AM to 6 PM).
Alert Rate
Minimum interval between alerts. Supports 1 minute to 1440 minutes (24 hours).
Notification Method
Notification Method
Select one or more notification methods:
DingTalk.
Email:
SMS: text message.
Webhook: Specifies the service endpoint.
Phone: Phone number.
Ensure the recipient's phone number is verified, or the notification will not be effective. You can click Notification Recipient Management below, and if the Unverified tag appears in the Phone column for the target contact on the Contacts tab, click the tag to complete the verification.

ImportantEnsure your chosen notification method has a corresponding notification object configured. For DingTalk, this means adding a DingTalk robot notification object after selecting DingTalk as the method.
Notification Object
You can notify multiple Notification Recipients simultaneously. You can either select or search for them directly. Before you select Notification Recipients, you need to click Notification Recipient Management on the right to create them. For more information, see Storage Management and Operations.
Alert Noise Reduction
Click Advanced Settings and turn on Alert Noise Reduction.
When enabled, alerts are sent only when thresholds are met continuously. This prevents alerts for temporary issues, such as brief failovers caused by cluster scheduling or auto-tuning.
No Data Alerts
Click Advanced Settings, turn on No Data Alerts, and specify the duration.
Triggers an alert if no monitoring data is reported within the selected time period. Common causes: JobManager exceptions, job stops, or reporting link failures.
You can click OK.
After you save the alert rule, it is enabled by default and appears in the alert rule list. You can then stop, edit, or delete the rule.
Single job/multi-job configuration (ARMS console)
If you rename a job in the Flink console, the alert rules that are configured in the ARMS console using the original job name will no longer be valid. You must select the renamed job and reconfigure the alert rule.
Log on to the Realtime Compute console.
In the Actions column for your workspace, click to access the ARMS console.
The workspace name, workspace ID, and the corresponding Prometheus instance name appear at the top of the page.
In the navigation pane on the left, click Alert Rules to create an alert rule.
Detection type: supports metric-based alerting through static thresholds and custom PromQL, except for metrics that Flink already supports for alerting.
Filter Conditions enable batch alert configuration. For Namespace, enter the namespace name. Select All to apply to all namespaces in the workspace. For Deployment, enter the Deployment Job ID for the target job within the namespace (you can find this ID on the Deployment Details tab of the Flink job). Select All to apply to all jobs in the namespace.
For more information about the other configuration parameters, see Create a Prometheus alert rule. You can also create a Prometheus alert rule template. For more information, see Create a Prometheus alert rule template.
Event-based alerts
Only job failure events are supported. To configure an alert for this event, follow the instructions in Metric-based alerts and select the Job Failed metric. To configure alerts for other events, use Cloud Monitor event-based alerts (including workflows).
FAQ
How do I check the monitoring service type for my workspace?
You select the monitoring service type when creating a workspace. To verify it after creation, go to and click your job deployment name. If the Alert Configuration tab appears, your workspace uses ARMS (pay-as-you-go Prometheus monitoring). If it does not appear, your workspace uses Cloud Monitor (free).

How do I add a DingTalk robot for alerts in the Realtime Compute development console?
Add a custom DingTalk robot and obtain its webhook address. For more information, see Add a custom DingTalk robot and get its webhook address.
ImportantTo receive alert notifications, in Security Settings, you must select at least Custom Keywords and set at least one keyword to Alert.
Add a notification object.
On the page, click the name of your job deployment and select the Alert Configuration tab.
Choose or Rule Template.
On the Create Rule or Create Alert Rule Template page, click Notification Object Management.
On the DingTalk Robot tab, click Add DingTalk Robot.
Enter the DingTalk robot Name and URL, and then click Submit.
Return to the Create Rule or Create Alert Rule Template page in step 2. Set Notification Method to DingTalk and Notification Object to your DingTalk robot.
For more information about the other parameters, see Single job configuration (Realtime Compute console).
Click OK.
How do I create a webhook in the Realtime Compute development console?
References
Realtime Compute for Apache Flink supports Cloud Monitor (free) and ARMS (Managed Service for Prometheus) for job monitoring and alerting. For a comparison of features and pricing, see Cloud Monitor vs. ARMS alerting features.
ARMS supports the configuration of features such as alert escalation, and scheduling. For more information, see Escalation Policy, and Related Practice Tutorials.
Cloud Monitor supports receiving alert notifications using DingTalk and Lark groups. For more information about the configuration, see Alert notification methods for Cloud Monitor.
For more information about the supported monitoring metrics, see Monitoring metrics.
You can disable monitoring and alerts or discard specific metrics when you use ARMS to reduce costs. You can resume metric collection at a later time. For more information, see Discard or resume monitoring metrics.