ApsaraDB RDS for SQL Server provides an instance-level solution to migrate databases to the cloud. You can migrate the full data of multiple or all databases from a self-managed SQL Server instance to an ApsaraDB RDS for SQL Server instance. To do this, you must back up all databases on your self-managed SQL Server instance, upload the full backup files to the same folder in an OSS bucket, and then run the migration script.
If you are performing a database-level migration, which means you only need to migrate one database at a time, see Migrating Full Backups to the Cloud and Migrating Incremental Backups to the Cloud.
Prerequisites
The source database must be a self-managed SQL Server database.
The destination ApsaraDB RDS for SQL Server instance must meet the following conditions:
The available storage space of the instance must be greater than the size of the data files to be migrated. If the space is insufficient, upgrade the instance specifications in advance.
For SQL Server 2008 R2 instances: Create databases on the destination instance that have the same names as the databases to be migrated. This step is not required for other SQL Server versions.
If you use a Resource Access Management (RAM) user, the following conditions must be met:
The RAM user has the AliyunOSSFullAccess and AliyunRDSFullAccess permissions. For more information about how to grant permissions to a RAM user, see Manage OSS permissions using RAM and Manage ApsaraDB RDS permissions using RAM.
Your Alibaba Cloud account has granted the ApsaraDB RDS service account permissions to access your OSS resources.
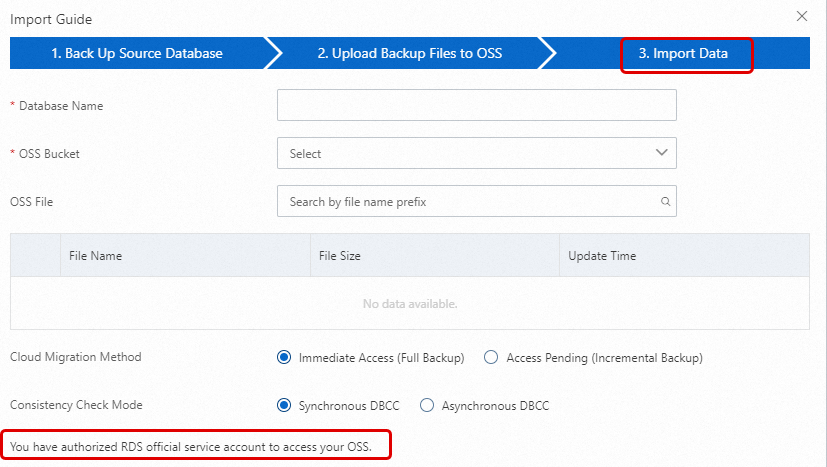
Go to the Backup and Restoration page of the ApsaraDB RDS instance and click Migrate OSS Backup Data to RDS.
In the Import Guide, click Next twice to proceed to step 3. Import Data.
The authorization is complete if the message You have authorized RDS official service account to access your OSS is displayed in the lower-left corner of the page. If not, click the Authorization URL on the page to grant authorization.
Your Alibaba Cloud account must manually create an access policy and then attach the policy to the RAM user.
Limitations
This solution supports only full migration. Incremental migration is not supported.
Billing
If you use the method described in this topic to migrate data, you are charged only for the use of OSS buckets.

Scenario | Billing rule |
Upload backup files to an OSS bucket | Free of charge. |
Store backup files in an OSS bucket | You are charged storage fees. For more information, visit the Pricing page of OSS. |
Migrate backup files from an OSS bucket to your RDS instance |
|
Preparations
1. Install Python 3
Go to the official Python website to download and install the package for your operating system. Select Python 3.12 or later.
For Windows: During installation, select the
Add python.exe to PATHcheckbox to avoid manually configuring environment variables later.For macOS or Linux: You can install Python from the official website or use a system package manager such as Homebrew, apt, or dnf. For more information, see the official Python documentation.
2. Verify the Python installation and version
The name of the executable file may vary based on your operating system and installation method. Common names include python, python3, and py. Try the following commands in order and use the one that corresponds to your installation.
3. Install SDK dependencies
pip install alibabacloud_rds20140815
pip install alibabacloud-oss-v21. Back up all databases on the self-managed SQL Server instance
To ensure data consistency, do not write new data during the full backup. Plan the backup in advance to avoid service interruptions.
If you do not use the backup script, you must name the backup files in the
DatabaseName_BackupType_BackupTime.bakformat. For example,Testdb_FULL_20180518153544.bak. Otherwise, the migration will fail.
Download the backup script.
Double-click the backup script file to open it using Microsoft SQL Server Management Studio (SSMS). For more information about how to connect using SSMS, see the official documentation.
Modify the following parameters as needed.
Configuration item
Description
@backup_databases_list
The databases to be backed up. Separate multiple databases with semicolons (;) or commas (,).
@backup_type
The backup type. Valid values:
FULL: full backup.
DIFF: differential backup.
LOG: log backup.
ImportantIn this solution, set this parameter to FULL.
@backup_folder
The local folder where the backup files are stored. If the folder does not exist, it is automatically created.
@is_run
Specifies whether to perform the backup. Valid values:
1: Perform the backup.
0: Perform only a check without performing the backup.
Run the backup script. The databases are backed up to the specified folder.

2. Upload the backup files to OSS
Before you upload the backup file to OSS, you must create a bucket in OSS.
If a bucket already exists in OSS, ensure that it meets the following requirements:
The storage class of the bucket is Standard. Other storage classes, such as Infrequent Access, Archive, Cold Archive, and Deep Cold Archive, are not supported.
Server-side encryption is disabled for the bucket.
If no bucket exists in OSS, you must create one. (Make sure that you have activated OSS.)
Log on to the OSS console, click Buckets, and then click Create Bucket.
Configure the following key parameters. You can retain the default values for other parameters.
ImportantThe bucket is created primarily for this data migration. you need to configure only the key parameters. You can delete the bucket after the migration is complete to prevent data breaches and reduce costs.
When you create the bucket, do not enable server-side encryption.
Parameter
Description
Example
Bucket Name
The name of the bucket. The name must be globally unique and cannot be changed after the bucket is created.
Naming conventions:
The name can contain only lowercase letters, digits, and hyphens (-).
The name must start and end with a lowercase letter or a digit.
The name must be 3 to 63 characters in length.
migratetest
Region
The region where the bucket resides. If you upload data to the bucket from an ECS instance over the internal network and restore the data to an ApsaraDB RDS instance over the internal network, the bucket, ECS instance, and ApsaraDB RDS instance must be in the same region.
China (Hangzhou)
Storage Class
Select Standard. The migration operation in this topic does not support buckets of other storage classes.
Standard
Upload the backup file to OSS.
After you back up the local database, upload the backup file to an OSS bucket that is in the same region as your ApsaraDB RDS instance. If the bucket and the instance are in the same region, you can use the internal network for service interconnection. This method is free of charge for outbound internet traffic and provides faster data upload speeds. You can use one of the following methods:
Download ossbrowser.
The following steps use a Windows x64 operating system as an example. Decompress the downloaded
oss-browser-win32-x64.zippackage and double-click theoss-browser.exeapplication.Select Log On With AK, configure the AccessKeyId and AccessKeySecret parameters, keep the default values for the other parameters, and then click Log On.
NoteAn AccessKey pair is used for identity verification. Keep your AccessKey pair confidential to ensure data security.

Click the destination bucket.

Click
 , select the backup file that you want to upload, and then click Open. The local file is uploaded to OSS.
, select the backup file that you want to upload, and then click Open. The local file is uploaded to OSS.
NoteIf the backup file is smaller than 5 GB, we recommend that you upload it from the OSS console.
Log on to the OSS console.
Click Buckets and then the name of the destination bucket.
In the Objects list, click Upload Object.
You can drag a backup file to the Files to Upload area, or click Select Files to select a file.
Click the Upload Object button at the bottom of the page to upload a local backup file to OSS.
3. Run the migration script to migrate the databases to ApsaraDB RDS
Download the SQL Server migration script.
After you decompress the package, run the following command to view the required parameters for the script.
python ~/Downloads/RDSSQLCreateMigrateTasksBatchly.py -hThe following result is returned:
RDSSQLCreateMigrateTasksBatchly.py -k <access_key_id> -s <access_key_secret> -i <rds_instance_id> -e <oss_endpoint> -b <oss_bucket> -d <directory>The following table describes the parameters.
Parameter
Description
access_key_id
The AccessKey ID of the Alibaba Cloud account that owns the destination ApsaraDB RDS instance.
access_key_secret
The AccessKey secret of the Alibaba Cloud account that owns the destination ApsaraDB RDS instance.
rds_instance_id
The ID of the destination ApsaraDB RDS instance.
oss_endpoint
The endpoint of the bucket where the backup files are stored.
oss_bucket
The name of the bucket where the backup files are stored.
directory
The folder in the OSS bucket where the backup files are stored. If the files are in the root directory, enter
/.Run the migration script to complete the migration task.
This example shows how to migrate all eligible backup files from the
Migrationdatafolder in thetestdatabucketOSS bucket to an ApsaraDB RDS for SQL Server instance with the ID rm-2zesz5774ud8s****.python ~/Downloads/RDSSQLCreateMigrateTasksBatchly.py -k yourAccessKeyID -s yourAccessKeySecret -i rm-2zesz5774ud8s**** -e oss-cn-beijing.aliyuncs.com -b testdatabucket -d Migrationdata
4. View the migration task progress
Select a method based on the version of your ApsaraDB RDS for SQL Server instance.
SQL Server 2012 and later
In the navigation pane on the left of the ApsaraDB RDS instance, click Backup and Restoration. On the Cloud Migration Records of Backup Datas tab, you can view the migration records, including the task status, start time, and end time. By default, records from the last week are displayed. You can adjust the time range as needed.

If the Task Status is Failed, check the Task Description or click View File Details for the failed migration task to identify the cause of the failure. After you fix the issue, run the data migration script again.
SQL Server 2008 R2
In the navigation pane on the left of the ApsaraDB RDS instance, click Data Migration To Cloud. Find the target migration task to view its progress.
If the Task Status is Failed, check the Task Description or click View File Details for the failed migration task to identify the cause of the failure. After you fix the issue, run the data migration script again.
Common errors
Error message | Cause | Solution |
| The AccessKey ID used to call the OpenAPI operation is incorrect. | Enter the correct AccessKey ID and AccessKey secret. |
| The AccessKey secret used to call the OpenAPI operation is incorrect. | |
| This solution supports only ApsaraDB RDS for SQL Server. Other database engines are not supported. | Use an ApsaraDB RDS for SQL Server instance as the destination instance. |
| The ApsaraDB RDS instance ID does not exist. | Check whether the ApsaraDB RDS instance ID is correct. |
| The endpoint is incorrect, which causes the connection to fail. | Check whether the specified endpoint is correct. |
| The OSS bucket does not exist. | Check whether the specified OSS bucket is correct. |
| The specified folder does not exist in the OSS bucket, or the folder does not contain eligible database backup files. | Check whether the folder exists in the OSS bucket and whether the folder contains eligible database backup files. |
| The backup file name does not follow the naming convention. | If you do not use the backup script, you must name the backup files in the |
| The RAM user does not have sufficient permissions. | You must grant the RAM user the permissions to use OSS and ApsaraDB RDS (the AliyunOSSFullAccess and AliyunRDSFullAccess permissions). |
| An error message was returned when calling an OpenAPI operation. | Analyze the cause based on the error code and error message. |
OpenAPI error codes
HTTP Status Code | Error | Description | Description |
403 | InvalidDBName | The specified database name is not allowed. | The database name is invalid. You cannot use system database names. |
403 | IncorrectDBInstanceState | Current DB instance state does not support this operation. | The ApsaraDB RDS instance is in an invalid state. For example, the instance status is Creating. |
400 | IncorrectDBInstanceType | Current DB instance type does not support this operation. | The database engine is not supported. This feature is available only for ApsaraDB RDS for SQL Server. |
400 | IncorrectDBInstanceLockMode | Current DB instance lock mode does not support this operation. | The database is in an invalid lock state. |
400 | InvalidDBName.NotFound | Specified one or more DB name does not exist or DB status does not support. | The database does not exist.
|
400 | IncorrectDBType | Current DB type does not support this operation. | The database type does not support this operation. |
400 | IncorrectDBState | Current DB state does not support this operation. | The database is in an invalid state. For example, the database is being created or a migration task is in progress. |
400 | UploadLimitExceeded | UploadTimesQuotaExceeded: Exceeding the daily upload times of this DB. | The number of migration operations exceeds the limit. You can perform a maximum of 20 migration operations per database on each instance per day. |
400 | ConcurrentTaskExceeded | Concurrent task exceeding the allowed amount. | The number of migration operations exceeds the limit. You can perform a maximum of 500 migration operations on each instance per day. |
400 | IncorrectFileExtension | The file extension does not support. | The file extension of the backup file is invalid. |
400 | InvalidOssUrl | Specified oss url is not valid. | The provided OSS download URL is unavailable. |
400 | BakFileSizeExceeded | Exceeding the allowed bak file size. | The database backup file exceeds the size limit. The maximum size is 3 TB. |
400 | FileSizeExceeded | Exceeding the allowed file size of DB instance. | The restored backup file will exceed the storage capacity of the current instance. |
Related API operations
API | Description |
Restores a backup file from OSS to an ApsaraDB RDS for SQL Server instance and creates a data migration task. | |
Opens the database of an ApsaraDB RDS for SQL Server data migration task. | |
Queries the list of data migration tasks for an ApsaraDB RDS for SQL Server instance. | |
Queries the file details of an ApsaraDB RDS for SQL Server data migration task. |