PolarDB for MySQL integrates the database kernel with remote direct memory access (RDMA) network to provide the strongly consistent cluster (SCC) feature. The SCC feature is also called PolarDB-SCC. This ensures global consistency of data and achieves high performance of data reads and writes. Compared with eventual consistency, the performance loss of a cluster is within 10% if SCC is enabled for the cluster. This topic describes the usage notes, technical principles, and enabling method of SCC and shows the cluster performance comparison results.
Supported versions
If you want to enable SCC, your PolarDB for MySQL enterprise edition cluster must meet one of the following version requirements:
The engine version is 8.0.2 with a revision version of 8.0.2.2.19 or later.
The engine version is 8.0.1 with a revision version of 8.0.1.1.29 or later.
The engine version is 5.7 with a revision version of 5.7.1.0.26 or later.
For more information about how to check the cluster version, see the "Query the engine version" section of the Engine versions topic.
Usage notes
By default, SCC is enabled for all read-only nodes of a serverless cluster.
SCC cannot be enabled for read-only nodes of a secondary cluster in a global database network (GDN).
SCC is compatible with the fast query cache feature. However, if modification tracking table (MTT) optimization is enabled for SCC and you enable both the fast query cache feature and SCC, the MTT optimization becomes invalid.
Technical solution of SCC
SCC is based on PolarTrans. It is a newly designed timestamp-based transaction system, aiming to reconstruct the traditional transaction management method that is based on the number of active transactions in native MySQL. The system not only supports the expansion of distributed transactions, but also significantly improves the performance of a single cluster.
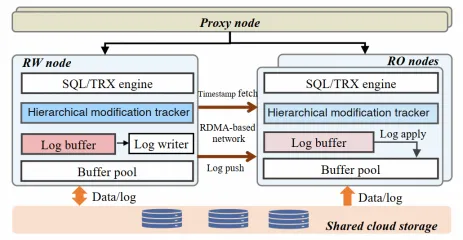
The following figure shows how SCC is implemented. The RDMA network is used to establish interactive and multi-dimensional primary/secondary information synchronization. This replaces the traditional primary/secondary log replication architecture, uses linear Lamport timestamp algorithm to reduce the number of times that a read-only node obtains timestamps, and prevents unnecessary waiting time for log replay.
Linear Lamport timestamp: To optimize the efficiency of a read-only node to obtain the latest modified timestamp, linear Lamport timestamp is used. In the traditional method, a read-only node needs to obtain the timestamp from the primary node each time it processes a request. In this case, a significant overhead is generated under high load even if the network speed is fast. The advantage of linear Lamport timestamp is that a read-only node can locally store the timestamp obtained from the primary node. For a request that reaches a read-only node earlier than the locally stored timestamp, the read-only node can directly use the local timestamp without the need to obtain another timestamp from the primary node. This effectively reduces the overhead generated by frequently timestamp requesting under high load, and improves the performance of a read-only node.
Hierarchical fine-grained modification tracking: To optimize the performance of read-only nodes, three levels of timestamps are used on the primary node: global timestamp, table-level timestamp, and page-level timestamp. When a read-only node processes a request, it first obtains the global timestamp. If the global timestamp is later than the timestamp generated when the read-only node replays logs, the read-only node does not immediately enter the waiting state. Instead, the read-only node continues to check the timestamps of the table and page that the request accesses. The read-only node waits until the log replay is complete only if the page-level timestamp of the request does not meet the condition. This effectively prevents unnecessary waiting time for log replay and improves the response speed of the read-only node.
RDMA-based log shipment: SCC uses a one-sided RDMA interface to ship logs from the primary node to a read-only node, which greatly improves the log shipment speed and reduces the CPU overhead caused by log shipment.
Linear Lamport timestamp
A read-only node can use linear Lamport timestamp to reduce the latency of read requests and bandwidth consumption. When a request reaches a read-only node, if the read-only node detects that a timestamp is obtained from the primary node for another request, the read-only node directly reuses the timestamp to prevent repeated timestamp requesting to the primary node, which ensures strong data consistency and improves the performance.
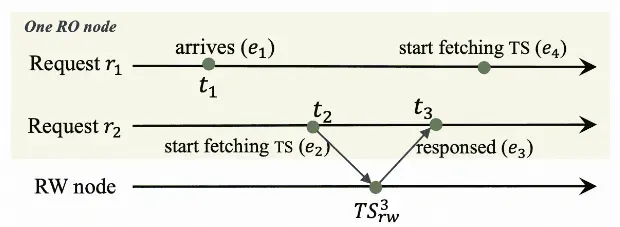
In the preceding figure, two concurrent read requests r1 and r2 reach a read-only node. The read-only node sends a request to the primary node at t2 to obtain a timestamp for r2 and obtains the timestamp TS3rw from the primary node at t3. We can understand the relationship of these events: e2TS3 rw e3. r1 reaches the read-only node at t1. By assigning a timestamp to each event on the read-only node, the sequence of events on the read-only node can be determined. If t1 is earlier than t2, we can get the following event relationship: e1e2TS3 rw e3. In other words, the timestamp obtained for r2 already covers all the updates before r1 reaches the read-only node. In this case, the timestamp for r2 can be directly used for r1 without the need to obtain a new timestamp. Based on this principle, each time the read-only node obtains a timestamp from the primary node, the read-only node locally saves the timestamp and records the time when the timestamp is obtained. If the arrival time of a request is earlier than the time when the locally cached timestamp is obtained, the timestamp can be directly used for the request.
Hierarchical and fine-grained modification tracking
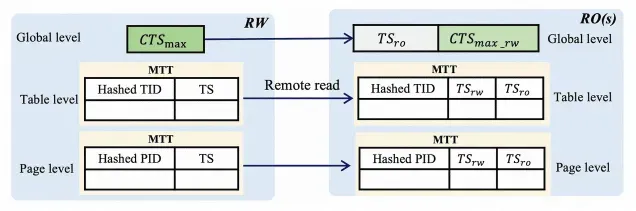
To implement strong consistency of data reads, a read-only node must first obtain the latest timestamp committed by the current transaction of the primary node, replay its logs to the timestamp, and then process a read request. However, during the log replay, the requested data may be the latest and the read-only node does not need to wait until logs are replayed. To prevent unnecessary time consumed for waiting, SCC uses more fine-grained modification tracking. Three levels of modification information are maintained on the primary node: global timestamp, table-level timestamp, and page-level timestamp.
When a read-only node processes a read request, it first obtains the global timestamp to check data consistency. If the global timestamp does not meet the condition, the read-only node obtains the local timestamp of the destination table for more fine-grained verification. If the table-level timestamp still does not meet the condition, the read-only node obtains the timestamp of the destination page for further verification. Only if the timestamp of the current page is later than the timestamp at which the read-only node replays logs, does the read-only node need to wait until log replay is complete to ensure that the latest data is read.
To reduce memory usage, the three levels of timestamps are stored in a hash table in the memory. To further optimize memory usage, the timestamps of multiple tables or pages may be mapped to the same hash table. To ensure consistency, only later timestamps are allowed to replace earlier ones. This design ensures that consistency is not broken even if the read-only node obtains a later timestamp. The following figure shows the principle. In this figure, TID indicates a table ID and PID indicates a page ID. The timestamp obtained by a read-only node is cached locally based on the design of linear Lamport timestamp for other eligible requests.
RDMA-based log shipment
In SCC, the primary node remotely writes logs to the cache of the read-only node over one-sided RDMA. This process does not consume the CPU resource of the read-only node and ensures low latency. As shown in the following figure, both the read-only and primary nodes maintain log buffers of the same size. The background thread of the primary node writes the log buffer of the primary node to the log buffer of the read-only node over RDMA. The read-only node reads the local log buffer instead of reading files to accelerate replication synchronization.
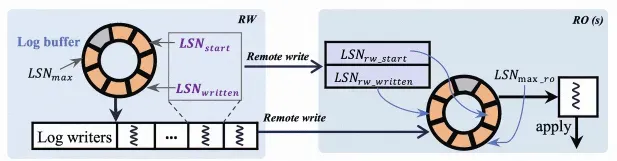
For more information about RDMA-based log shipment, see RDMA-based log shipment.
Enable SCC
Log on to the PolarDB console. On the Clusters page, find the cluster that you want to manage and click its ID to go to the cluster details page. In the Database Connections section of the Basic Information page, move the pointer over the endpoint for which you want to enable SCC and click Configure. For more information, see Configure PolarProxy.
Global consistency (high-performance mode) applies to all endpoints of a cluster after it is enabled. If you enable this mode for one endpoint of a cluster, this mode is enabled for all other endpoints of the cluster.
Performance comparison
Test environment
A PolarDB for MySQL 8.0 cluster of the Cluster Edition with 8 CPU cores and 32 GB of memory.
Test tool
Sysbench
Size of test data
25 tables with 250,000 rows in each table
Test results
Read and write performance
Chart overview
qps: the number of queries per second (QPS) in the sysbench test result.
threads: the number of concurrent sysbench threads used in the test.
RW: the QPS on the primary node. If the read-only node cannot provide globally consistent read operations, all the read and write operations are sent to the primary node.
Global consistency: the QPS with global consistency enabled.
SCC: the QPS with eventual consistency and SCC enabled.
Eventual consistency: the QPS with eventual consistency enabled for read operations and SCC disabled.
In the scenario that tests the read and write performance between two clusters, compared to a cluster with eventual consistency enabled, the overall performance loss of a cluster with SCC enabled is within 10%.
