In general, OSS foreign tables store cold data, which is large in size. If a single CSV-formatted data file is too large, its queries are time-consuming. PolarDB provides the multi-file queries for a single table feature. You can split the data file of a single OSS foreign table into multiple small data files to speed up queries. This topic describes how to perform multi-file queries for a single OSS foreign table.
Prerequisites
Your PolarDB cluster meets one of the following requirements:
A PolarDB for MySQL 8.0.1 cluster whose revision version is 8.0.1.1.28 or later.
A PolarDB for MySQL 8.0.2 cluster whose revision version is 8.0.2.2.5.1 or later.
For more information about how to check the cluster version, see Query the engine version.
Procedure
Split a CSV file.
You can split a CSV file into multiple small CSV files by row. The recommended size of a single CSV file is 128 MB and the maximum size is 1 GB.
NoteYou cannot split the data a row into two CSV files to ensure the integrity of each data file.
File names must comply with the following naming conventions:
You can use the
CONNECTIONparameter in the statement for creating an OSS foreign table to specify the file name. If the parameter does not contain a file name, the data file name isThe name of the current OSS table.CSV. Examples:The CONNECTION parameter contains a file name.CREATE TABLE t1 (id int) engine=csv CONNECTION="server_name/a/b/c/d/t1";In the preceding example, the path of the data file on OSS is
oss_prefix/a/b/c/d/, and the data file name ist1.CSV.The CONNECTION parameter does not contain a file name.CREATE TABLE t1 (id int) engine=csv CONNECTION="server_name";The data file name is
t1.CSV.
The name of the original data file-Any number.CSV. Example:If the name of the original data file is
t1.CSV, the split data files are calledt1.CSV,t1-1.CSV, andt1-2.CSV.
Upload split data files.
After a data file is split, you must manually upload all split CSV files to the same path on OSS. In the following example, the ossutil tool is used to upload CSV files at a time. For more information about the ossutil tool, see ossutil.
./ossutil64 cp localfolder/ oss://examplebucket/desfolder/ --include "*.CSV" -rlocalfolderis the folder name of the CSV files to be uploaded, and oss://examplebucket/desfolder/ is the path of the CSV files on OSS. You can replace them with actual folder names and paths.
Add OSS connection information.
You can add OSS connection information by creating an OSS server. Syntax:
CREATE SERVER <server_name> FOREIGN DATA WRAPPER oss OPTIONS ( EXTRA_SERVER_INFO '{"oss_endpoint": "<my_oss_endpoint>","oss_bucket": "<my_oss_bucket>","oss_access_key_id": "<my_oss_access_key_id>","oss_access_key_secret": "<my_oss_access_key_secret>","oss_prefix":"<my_oss_prefix>","oss_sts_token":"<my_oss_sts_token>"}' );NoteOn a PolarDB for MySQL 8.0.1 cluster whose revision version is 8.0.1.1.29 or later or a PolarDB for MySQL 8.0.2 cluster whose revision version is 8.0.2.2.6 or later, you can use the
my_oss_sts_tokenparameter.The
DATABASEparameter is supported. If bothDATABASEandmy_oss_prefixparameters exist in the OSS server that you create, the final path of the file ismy_oss_prefix/DATABASE. This ensures that the data file path specified in the statement is the same as the path on OSS that you upload split files to.
The following table describes the parameters in the ARN format.
Parameter
Type
Description
server_name
String
The name of the OSS server.
NoteThe name must be globally unique. It is case-insensitive. The name can be up to 64 characters in length. A name that contains more than 64 characters is automatically truncated. You can specify the OSS server name as a quoted string.
my_oss_endpoint
String
The endpoint of the OSS server.
NoteIf you access your database from an Alibaba Cloud server, use an internal endpoint to avoid incurring Internet traffic. An internal endpoint contains keyword internal.
Example:
oss-cn-xxx-internal.aliyuncs.com.my_oss_bucket
String
The bucket where the data file is stored. You must use OSS to create the bucket before you import data.
NoteWe recommend that you deploy the bucket in the same zone as the PolarDB cluster to reduce network latency.
my_oss_access_key_id
String
The AccessKey ID of the account used to access OSS.
my_oss_access_key_secret
String
The AccessKey secret of the account used to access OSS.
my_oss_prefix
String
The path of the current CSV data file on OSS.
my_oss_sts_token
String
The temporary credential used to access OSS. For information about how to obtain temporary credentials used to access OSS, see Use temporary credentials provided by STS to access OSS.
NoteThe
my_oss_sts_tokenvalue has a default expiration time. If themy_oss_sts_tokenvalue expires, you must execute the following statement to reset allEXTRA_SERVER_INFOvalues:ALTER SERVER server_name OPTIONS(EXTRA_SERVER_INFO '{"oss_endpoint": "<my_oss_endpoint>", "oss_bucket": "<my_oss_bucket>", "oss_access_key_id": "<my_oss_access_key_id>", "oss_access_key_secret": "<my_oss_access_key_secret>", "oss_prefix":"<my_oss_prefix>", "oss_sts_token": "<my_oss_sts_token>"}');NoteSERVERS_ADMIN permissions are required when you create an OSS server. You can execute the
SHOW GRANTS FOR the current userstatement to check whether the current user has the SERVERS_ADMIN permissions. A privileged account has the SERVERS_ADMIN permissions by default, and can grant the SERVERS_ADMIN permissions to standard accounts.If you are using a privileged account, you can execute the
SELECT Server_name, Extra_server_info FROM mysql.servers;statement to view the information of the OSS server that you create. The values of theoss_access_key_idandoss_access_key_secretparameters are encrypted for security reasons.
Create an OSS foreign table. For more information, see Create an OSS foreign table. After the foreign table is created, PolarDB can find the data files based on the specified path.
Query data.
The
t1table is used in the following examples.# Query the number of records in the t1 table. SELECT count(*) FROM t1; # Query records in a specified range. SELECT id FROM t1 WHERE id < 10 AND id > 1; # Query a specified record. SELECT id FROM t1 where id = 3; # Query records by joining multiple tables. SELECT id FROM t1 left join t2 on t1.id = t2.id WHERE t2.name like "%er%";The following table describes common error messages and causes when you query data.
NoteIf no error message is reported but a warning message is displayed when you query data, you must execute the
SHOW WARNINGS;statement to view the error message.Error message
Cause
Solution
OSS error: No corresponding data file on the OSS engine.
The data file is not found on OSS.
Check whether the data file exists in the specified path on OSS based on the preceding rules.
If yes, check whether the data file complies with the naming rule: The CSV file name must be
OSS foreign table name.CSVand the CSV extension must be in uppercase.If not, you must upload the data file to the specified path.
There is not enough memory space for OSS transmission. Currently requested memory %d.
Insufficient memory for OSS queries.
You can use one of the following methods to fix this error:
On the Parameters page of the console, modify
loose_csv_max_oss_threadsparameter values to allow more OSS threads to run.Execute the flush table statement to close threads for some OSS tables.
ERROR 8054 (HY000): OSS error: error message : Couldn't connect to server. Failed connect to aliyun-mysql-oss.oss-cn-hangzhou-internal.aliyuncs.com:80;
The current cluster cannot connect to the OSS server.
Check whether the current cluster is in the same zone as the OSS bucket.
If not, you must move the current cluster and the OSS bucket in the same zone.
If they are in the same zone, you can change the endpoint of the cluster to a public endpoint. If the error persists after the endpoint is modified, contact Alibaba Cloud technical support.
(Optional) Upload new data files.
If you want to upload new data files and read the data in the files from the
t1table, perform Step 1 to upload the files. After the files are uploaded, execute the following statement on thet1table before you can query the data in the newly uploaded files.FLUSH TABLE t1;
Query optimization
The query optimization feature is supported on a cluster that meets one of the following requirements:
A PolarDB for MySQL 8.0.1 cluster whose revision version is 8.0.1.1.34 or later.
A PolarDB for MySQL 8.0.2 cluster whose revision version is 8.0.2.2.14 or later.
After a multi-file OSS foreign table is created, PolarDB scans the data files of the current table on OSS in advance to obtain an estimate of the total number of rows in the table, starts multiple workers in a cost-based manner, and distributes multiple data files to different workers for parallel scans to speed up the scan process. The following figure shows how the feature works. 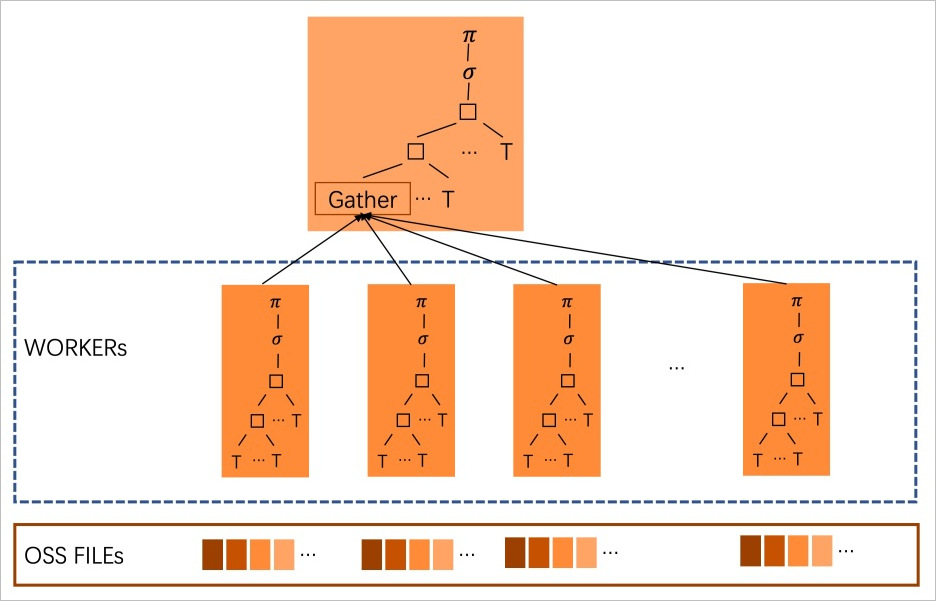
Enable parallel scan for multiple OSS data files
You can turn on the parallel scan switch for the CSV engine by specifying the loose_csv_max_oss_threads parameter to an integer which is greater than 1. For more information about the loose_csv_max_oss_threads parameter, see Parameters. For more information about how to set the parameter, see Set cluster and node parameters.