In recommendation scenarios, you can use the FM-Embedding solution that is provided by Machine Learning Designer to obtain the feature vectors of each user and item. Then, you can use the recall module to obtain the product of the feature vectors. This way, you can predict the rating to be assigned by each user to each item. This topic describes how to use the Factorization Machine (FM) and Embedding algorithms to generate feature vectors of users and items.
Prerequisites
A workspace is created. For more information, see Create and manage a workspace.
MaxCompute resources are associated with the workspace. For more information, see Manage the computing resources of a workspace.
Background information
AI-based recommendation is divided into two modules: sorting and recall. The recall module uses feature vectors to represent users and to-be-recommended items. The product of the feature vector of a user and the feature vector of an item indicates the interest of the user in the item. The pipeline that is described in this topic uses real recommendation data. This pipeline can be created from the preset FM-Embedding for Rec-System template of Machine Learning Designer. You can generate the feature vectors of users and items in a fast manner by dragging and dropping the components that are provided by Machine Learning Designer.
Dataset
The following table describes the fields in the dataset.
Parameter | Type | Description |
userid | STRING | The ID of the user. |
age | DOUBLE | The age of the user. |
gender | STRING | The gender of the user. |
itemid | STRING | The ID of the item. |
price | DOUBLE | The price of the item. |
size | DOUBLE | The size of the item. |
label | DOUBLE | Indicates whether the user has purchased the item. Valid values:
|
The following figure shows the sample data that is used in the pipeline. 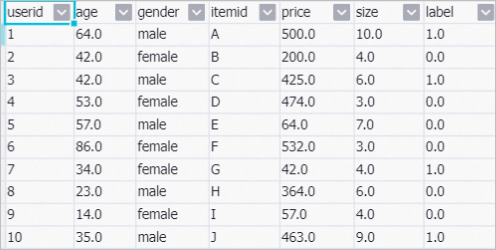
Procedure
Go to the Machine Learning Designer page.
Log on to the PAI console.
In the left-side navigation pane, click Workspaces. On the Workspaces page, click the name of the workspace that you want to manage.
In the left-side navigation pane, choose .
Create a pipeline.
On the Visualized Modeling (Designer) page, click the Preset Templates tab.
On the Preset Templates tab, find the FM-Embedding for Rec-System template and click Create.
In the Create Pipeline dialog box, configure the parameters. You can use their default values.
The value specified for the Pipeline Data Path parameter is the Object Storage Service (OSS) bucket path of the temporary data and models generated during the runtime of the pipeline.
Click OK.
It requires about 10 seconds to create the pipeline.
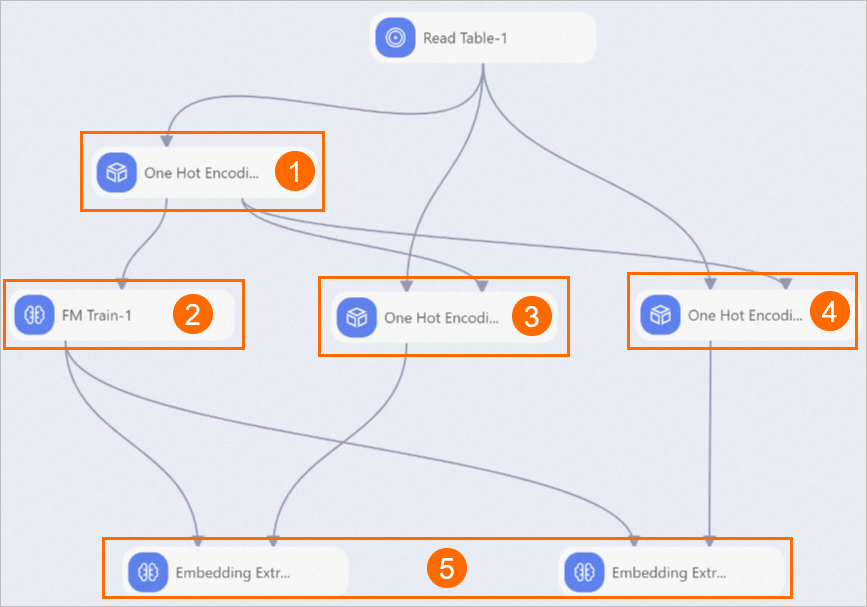
View the components of the pipeline on the canvas, as shown in the following figure. The system automatically creates the pipeline based on the built-in template.
Section
Description
①
This component performs one-hot encoding on all feature data. One-hot encoding converts character-type data to numeric-type data. In this pipeline, the One Hot Encoding-1 component first performs one-hot encoding on all feature data and generates an encoding model. Then, the One Hot Encoding-1 component exports the encoding model to the One Hot Encoding-2 and One Hot Encoding-3 components.
②
This component generates an FM model. You can click the component and view the default parameter settings of the component on the Parameters Setting tab in the right-side panel. The default value of Dimensions is 1,1,10, in which 10 indicates the number of dimensions in each feature vector.
③
This component generates user feature codes. Set Binarization Column to userid, gender, and age and set Appended Columns to userid for this component.
④
This component generates item feature codes. Set Binarization Column to itemid, price, and size and set Appended Columns to itemid for this component.
⑤
These components extract feature vectors of users and items. Each component includes the following parameters:
ID column name of embedding vector: the feature_id parameter of the model that is trained by the FM Train-1 component.
Embedding vector column name: the feature_weights parameter of the model that is trained by the FM Train-1 component.
Weight vector column name: the sparse columns that are exported by the One Hot Encoding-1 component.
Output result column name: the name of the column that contains the generated feature vectors.
Run the pipeline and view the results.
In the upper-left corner of the canvas, click the
 icon.
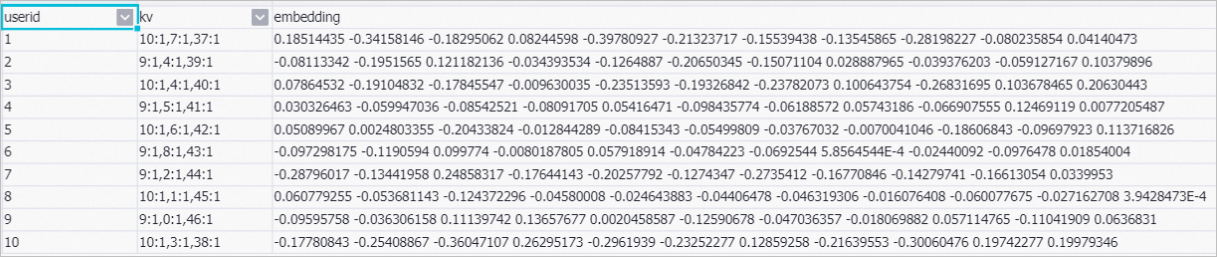
icon. After the pipeline is run, right-click Embedding extract-1 on the canvas and choose . In the dialog box that appears, view the feature vectors of users.
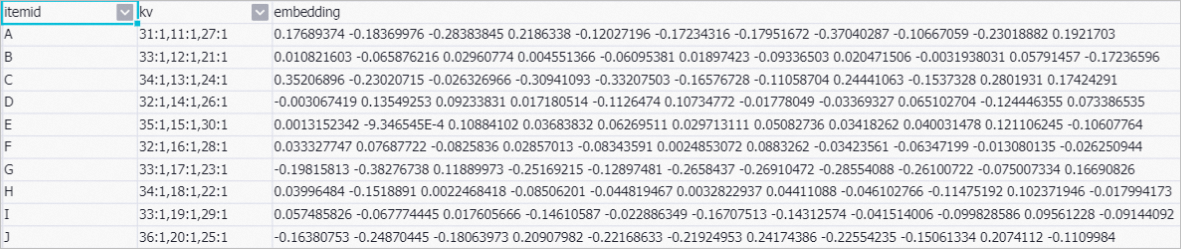
Right-click Embedding extract-2 on the canvas and choose . In the dialog box that appears, view the feature vectors of items.