Keyword analyzer
Introduction: This analyzer does not segment text into terms. It is suitable for exact searches. For example, it can be applied on tags, keywords, strings that need to be processed as a whole, and numbers.
Note: This analyzer applies to fields of the LITERAL, ARRAY and INT types.
Example:
If the value of a field is "菊花茶" in a document and the keyword analyzer is enabled, the document can be retrieved only when a user searches for "菊花茶".
General analyzer for Chinese
Introduction: This analyzer segments text by search unit based on Chinese semantics. It is a general analyzer that applies to most industries. This analyzer is an industry-specific analyzer.
Note: This analyzer applies to fields of the TEXT and SHORT_TEXT types.
Example:
If the value of a field is "菊花茶" in a document and the general analyzer for Chinese is enabled, the document can be retrieved when a user searches for "菊花茶", "菊花", "茶", or "花茶".
E-commerce analyzer for Chinese
Introduction: This analyzer is suitable for the E-commerce industry.
Note: This analyzer applies to fields of the TEXT and SHORT_TEXT types.
Example:
If the value of a field is "大宝SOD蜜" in a document and the E-commerce analyzer for Chinese is enabled, the document can be retrieved when a user searches for "大宝", "sod", "sod蜜", "SOD蜜", or "蜜".
Single character analyzer for Chinese
Introduction: This analyzer segments text into Chinese characters and words. It is suitable for searches that are not based on Chinese semantics, such as searches for author names or store names.
Note: This analyzer applies to fields of the TEXT and SHORT_TEXT types.
Example:
If the value of a field is "菊花茶" in a document and the single character analyzer for Chinese is enabled, the document can be retrieved when a user searches for "菊花茶", "菊花", "茶", "花茶", "菊", "花", or "菊茶".
Fuzzy analyzer
Introduction: This analyzer allows the system to support searches by pinyin, prefix or suffix, and single word or single letter. Chinese text does not support searches by prefix or suffix. Letters, numbers, and pinyin support searches by prefix or suffix. This analyzer supports only fields whose size does not exceed 100 bytes. For more information, see Fuzzy search.
Note: This analyzer applies only to fields of the SHORT_TEXT type.
Example:
If the value of a field is "菊花茶" in a document and the fuzzy analyzer is enabled, the document can be retrieved when a user searches for "菊花茶", "菊花", "茶", "花茶", "菊", "花", "菊茶", "ju", "juhua", "juhuacha", "j", "jh", or "jhc".
If the value of a field is the mobile number "138****5678" in a document and the fuzzy analyzer is enabled, the document can be retrieved when a user searches for "^138" or "5678$." "^138" instructs the system to search for all numbers that start with "138". "5678$" instructs the system to search for all numbers that end with "5678".
If the value of a field is "OpenSearch" in a document and the fuzzy analyzer is enabled, the document can be retrieved when a user searches for a single letter that is contained in the value or a combination of the letters.
Word stemming analyzer for English
Introduction: This analyzer stems each English word to its root form. It is suitable for searches based on English semantics.
Note: This analyzer applies to fields of the TEXT and SHORT_TEXT types.
Example:
If the value of a field is "英文分词器 english analyzer" in a document and the word stemming analyzer for English is enabled, the document can be retrieved when a user searches for "英文分词器", "english", "analyz", "analyzer", "analyzers", "analyze", "analyzed", or "analyzing".
Note that an English text analyzer analyzes consecutive Chinese characters as one word.Unstemmed word analyzer for English
Introduction: This analyzer segments text based on spaces and punctuation marks. It is suitable for searches that are not based on English semantics, such as searches for book titles or author names.
Note: This analyzer applies to fields of the TEXT and SHORT_TEXT types.
Example:
If the value of a field is "英文分词器 english analyzer" in a document and the unstemmed word analyzer for English is enabled, the document can be retrieved when a user searches for "英文分词器", "english", or "analyzer".
Note that an English text analyzer analyzes consecutive Chinese characters as one word.Analyzer for fine-grained analysis for English
Introduction: This analyzer segments text by search unit based on English semantics. It is an analyzer that applies to English text analysis in general industries.
Note: This analyzer applies only to fields of the TEXT and SHORT_TEXT types.
This analyzer is specific to exclusive applications.
Example:
If the value of a field is "dataprocess" in a document and the analyzer for fine-grained analysis for English is enabled, the analysis result is "data process". In this case, the document can be retrieved when a user searches for "dataprocess", "data process", "data", or "process".
Full pinyin spelling analyzer
Introduction: This analyzer allows users to search for Chinese characters in short text by using the full pinyin spelling or first letters of the abbreviated pinyin spelling. It is suitable for searches based on full pinyin spellings or abbreviated pinyin spellings, such as searches for movie names or author names. To search for characters based on the full pinyin spelling, a user must enter the full pinyin spelling, not part of the full pinyin spelling.
Note: This analyzer applies only to fields of the SHORT_TEXT type.
Example:
If the value of a field is "大内密探007" in a document and the full pinyin spelling analyzer is enabled, the document can be retrieved when a user searches for "d", "dn", "dnm", "dnmt", "dnmt007", "da", "danei", "daneimi", or "daneimitan". The document cannot be retrieved when a user searches for "an" or "anei".
Abbreviated pinyin spelling analyzer
Introduction: This analyzer allows users to search for Chinese characters in short text by using letters of the abbreviated pinyin spelling. It is suitable for searches based on abbreviated pinyin spellings, such as searches for movie names or author names.
Note: This analyzer applies only to fields of the SHORT_TEXT type.
Example:
If the value of a field is "大内密探007" in a document and the abbreviated pinyin spelling analyzer is enabled, the document can be retrieved when a user searches for "d", "dn", "dnm", "dnmt", "dnmt0", "damt007", "m", "mt", "mt007", or "007".
Simple analyzer
Introduction: This analyzer allows you to fully control searches. It is suitable for special scenarios in which other built-in analyzers cannot meet the requirements. In documents and queries, tab characters (\t) are used to separate terms in field values and search queries. Make sure the field values and search queries are segmented in the same way. Otherwise, the documents cannot be retrieved.
Note: This analyzer applies to fields of the TEXT and SHORT_TEXT types.
Example:
If the value of a field is "菊\t花茶\thao" in a document and the simple analyzer is enabled, the document can be retrieved only when a user searches for "菊", "花茶", "菊\t花茶", "花茶\thao", "菊\thao", or "菊\t花茶\thao".
Numerical value analyzer
Introduction: This analyzer is suitable for searches based on time intervals or numerical value ranges.
Note: This analyzer applies to fields of the INT and TIMESTAMP types.
Example:
query=default:'开放搜索' AND index:[number1,number2]
// In this example, index is the name of the index for which the numerical value analyzer is configured.
Geo-location analyzer
Introduction: This analyzer is suitable for searches based on geographical locations.
Note: This analyzer applies only to fields of the GEO_POINT type.
Example:
query=spatial_index:'circle(116.5806 39.99624, 1000)'
// Queries geographical locations within a circle whose radius can be several kilometers.IT content analyzer
Introduction: This analyzer is suitable for technical content in the IT industry. This analyzer is an industry-specific analyzer. Compared with the general analyzer, the IT content analyzer segments IT-related text in another way.
Note: This analyzer applies only to fields of the TEXT and SHORT_TEXT types.
Example:
Original content: c++数组使用注意事项
General analyzer: c ++数组使用注意事项
IT content analyzer: c++数组使用注意事项General analyzer for E-commerce for Chinese
Introduction: This analyzer is suitable for E-commerce industry scenarios and is industry-specific. With the industry experience accumulated over the years and the Natural Language Processing technology of DAMO Academy, OpenSearch provides query analysis capabilities dedicated to the E-commerce industry to resolve the pain points and meet the needs of the industry.
Usage notes
This analyzer applies only to text of the TEXT type.
This analyzer is specific to exclusive applications of Industry-specific Enhanced Edition for E-commerce.
Example:
Original content: 小金管遮瑕膏
General analyzer: 小金管遮瑕膏
General analyzer for E-commerce for Chinese: 小金管 遮瑕 膏General analyzer for Thai
Introduction: This analyzer segments Thai text based on search units. It is a general analyzer that applies to Thai text analysis in general industries.
Note: This analyzer applies only to fields of the TEXT and SHORT_TEXT types.
This analyzer is specific to exclusive applications.
Example:
If the value of a field is "แหล่งดึงดูดนักท่องเที่ยว" in a document and the general analyzer for Thai is enabled, the analysis result is "แหล่ง ดึง ดูด นักท่องเที่ยว". In this case, the document can be retrieved when a user searches for "นักท่องเที่ยว" or "แหล่งดึงดูดนักท่องเที่ยว".
Analyzer for E-commerce for Thai
Introduction: This analyzer is applicable to Thai text analysis in the E-commerce industry.
Note: This analyzer applies only to fields of the TEXT and SHORT_TEXT types.
This analyzer is specific to exclusive applications.
Example:
If the value of a field is "หน้าจอโทรศัพท์" in a document and the analyzer for E-commerce for Thai is enabled, the analysis result is "น้าจอ โทรศัพท์". In this case, the document can be retrieved when a user searches for "หน้าจอโทรศัพท์", "หน้าจอ", or "โทรศัพท์".General analyzer for Vietnamese
Introduction: This analyzer is applicable to Vietnamese text analysis in general industries.
Note: This analyzer applies only to fields of the TEXT and SHORT_TEXT types.
This analyzer is specific to exclusive applications.
General analyzer for Gaming
Introduction: This analyzer is applicable to the gaming industry.
Note: This analyzer applies only to fields of the TEXT and SHORT_TEXT types.
This analyzer is specific to exclusive applications of Industry-specific Enhanced Edition for Gaming.
Example:
If the value of a field is "原神装备" in a document and the general analyzer for gaming is enabled, the analysis result is "原神 装备". In this case, the document can be retrieved when a user searches for "原神装备", "原神", or "装备".General analyzer for E-commerce for English
Introduction: This analyzer is applicable for the E-commerce industry in English scenarios.
Note: This analyzer applies only to fields of the TEXT type.
This analyzer is specific to exclusive applications of Industry-specific Enhanced Edition for E-commerce.
Character analyzer for Chinese
Introduction: This analyzer segments text based on Chinese characters, numbers, English letters, and punctuation marks. This analyzer is applicable to searches that are not based on Chinese semantics.
Note: This analyzer applies only to fields of the TEXT and SHORT_TEXT types.
This analyzer is specific to exclusive applications.
Example:
If the value of a field is "开放搜索OpenSearch123" in a document and the character analyzer for Chinese is enabled, the document can be retrieved when a user searches for "开", "放", "搜", "索", "O", "p", "e", "n", "S", "e", "a", "r", "c", "h", or ".".
Custom analyzer for text
Introduction: This analyzer combines an industry-specific analyzer, which can be the general analyzer, E-commerce analyzer, or person name analyzer, with custom intervention entries. For more information, see Custom analyzers.
Note: This analyzer applies only to fields of the TEXT and SHORT_TEXT types.
Analyzer test
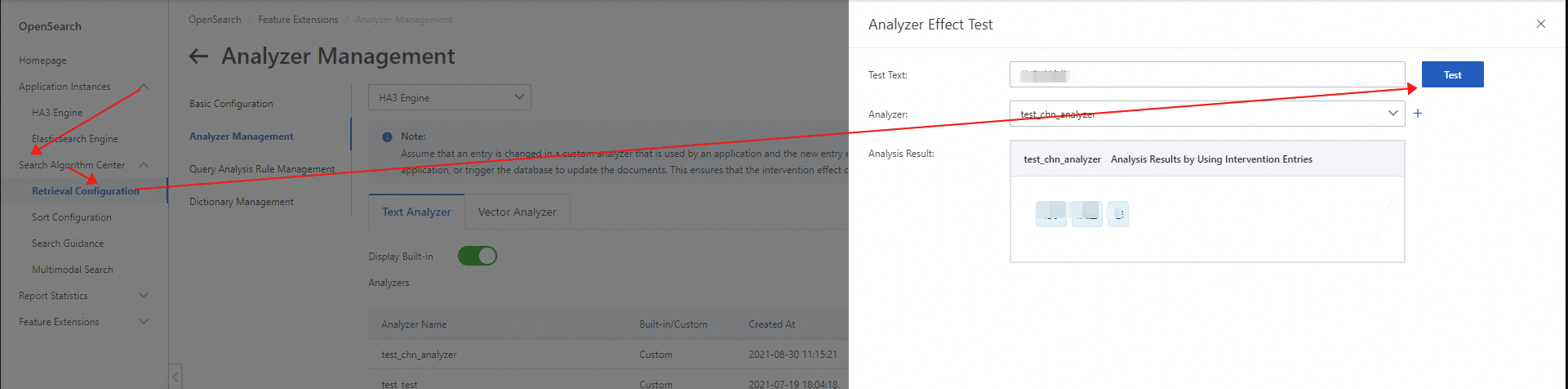
You can test an industry-specific analyzer or a custom analyzer to check its analysis result. Log on to the OpenSearch console. In the left-side navigation pane, choose Search Algorithm Center > Retrieval Configuration. On the Basic Configuration page, click Analyzer Management in the left-side pane. On the Analyzer Management page, find the analyzer that you want to test and click Word Analysis Test in the Actions column. See the following figure.
Scenarios
In scenarios where searches are based on Chinese semantics, we recommend that you use the general analyzer for Chinese or the E-commence analyzer for Chinese.
In short Chinese text search scenarios or Chinese search scenarios that are not based on semantics, stringent sorting is not required. In these scenarios, we recommend that you use the single character analyzer for Chinese to increase the number of documents that can be retrieved.
In search scenarios based on pinyin, use the fuzzy analyzer.
In English search scenarios, use the word stemming analyzer for English.
In some scenarios, you can use a semantics-based analyzer for Chinese and the single character analyzer for Chinese together to obtain better search results. Sample query: query=title_index:'菊花茶' OR sws_title_index:'菊花茶'. Fine sort expression: text_relevance(title)*5+field_proximity(sws_title). The preceding configuration allows users to retrieve all documents that contain "xx菊xx花xx茶xx". In addition, documents that contain "菊花茶" are ranked first.
Usage notes
Fields of the following types can be configured as index fields:
INT, INT_ARRAY, TEXT, SHORT_TEXT, LITERAL, LITERAL_ARRAY, TIMESTAMP, and GEO_POINT
Fields of the following types cannot be configured as index fields:
FLOAT, FLOAT_ARRAY, DOUBLE, and DOUBLE_ARRAY
If the search result summary is configured for a field of the TEXT type, some terms in the extended search units, such as "菊花茶" in the preceding example, are not added to the HTML tags for highlighting.
The single character analyzer for Chinese considers a number or an English word as a single character. For example, if a document contains a field whose value is "hello word" and the single character analyzer for Chinese is enabled, the document can be retrieved when a user searches for "hello." However, the document cannot be retrieved when a user searches for "he". To allow the system to return documents when a user searches for a part of an English word, use the fuzzy analyzer.
By default, the primary key of the primary table in the application schema is set as the index field, and the name of the index field is id. You cannot modify this index field.