MaxCompute is an open computing platform. If the data you want to import to OpenSearch is generated by MaxCompute, you can connect a MaxCompute project to an application. After reindexing is triggered in the application, OpenSearch automatically obtains full data from tables in the MaxCompute project. To obtain incremental data from the MaxCompute project, you must use the API or SDKs of OpenSearch.
Configure the AccessKey pair for your Alibaba Cloud account
After you connect a MaxCompute project to an application in OpenSearch, the OpenSearch system accesses the MaxCompute project by using the AccessKey pair of your Alibaba Cloud account and then downloads data from tables in the MaxCompute project. Make sure that you have configured the AccessKey pair for your Alibaba Cloud account before you connect the MaxCompute project.
Make sure that the MaxCompute project is created within the Alibaba Cloud account that you use to log on to the OpenSearch console.
You can use the AccessKey pair of your Alibaba Cloud account to access tables in MaxCompute projects that are created within your Alibaba Cloud account.
To mitigate security risks, you can also use the AccessKey pair of a RAM user. To create a RAM user and grant permissions to the RAM user, perform the following steps:
Create a RAM user under your Alibaba Cloud account. For more information, see Create a RAM user.
Log on to the MaxCompute console and add a member for the RAM user.
Assign a role to the added member based on your requirements.
Run the
list users;command on the DataStudio page to view the account of the added member.
Copy the account name and run the following commands to grant permissions to the account. xxx indicates the copied account name.
-- 1. Grant the LIST permission on the MaxCompute project.
grant CreateInstance,List on project zy_ts_test to user xxx;
-- 2. Grant the SELECT, DESCRIBE, and DOWNLOAD permissions on MaxCompute tables.
GRANT select,describe,download ON TABLE people_info TO USER xxx;
-- 3. (Optional) Grant label-based permissions on MaxCompute tables.
set label 2 to USER xxx;
-- Query the permissions of a specific user and information about the role that is assigned to the user.
show grants for xxx;After you create a RAM user and grant permissions to the RAM user, you can configure a MaxCompute project in the OpenSearch console.
Configure the MaxCompute data source
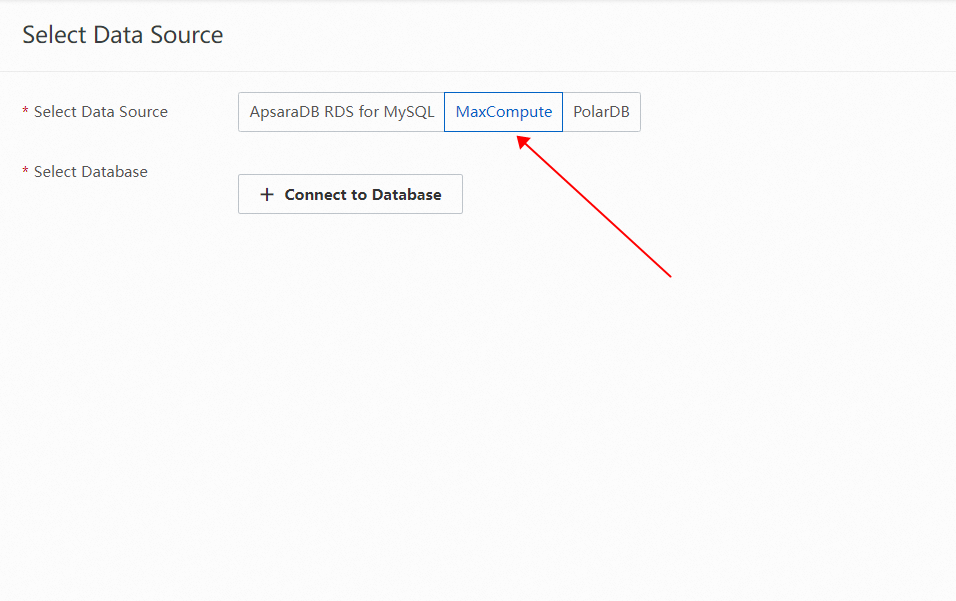
On the Configure Application page, click Use Data Source in the Application Schema Creation Method section.

On the Select Data Source panel that appears, select MaxCompute as the data source.
Click Connect to Database and configure the Project Name, AccessKey ID, and AccessKey Secret parameters.
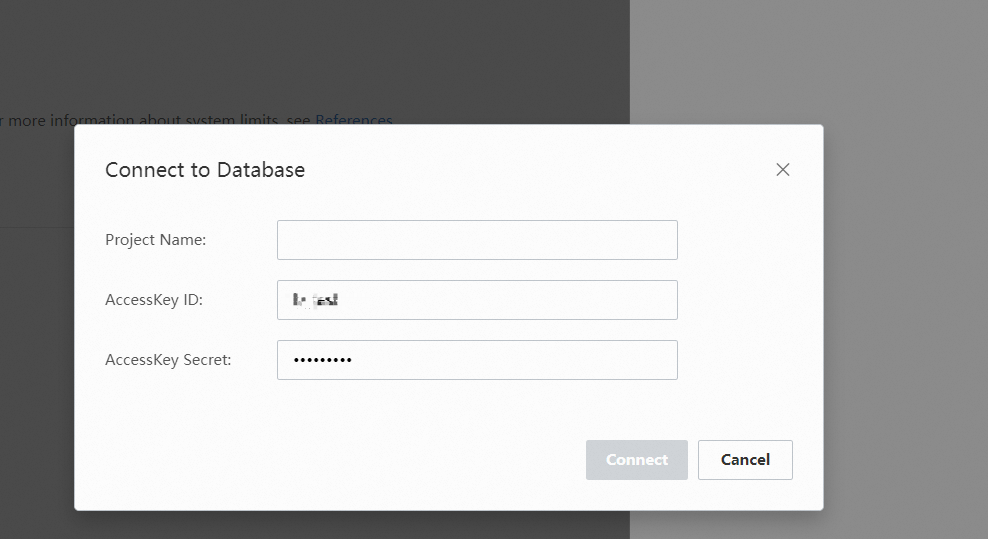
Click Connect. Then, select one or more tables.

The system automatically maps corresponding fields. You can fine-tune the fields based on your business requirements. Click Next.
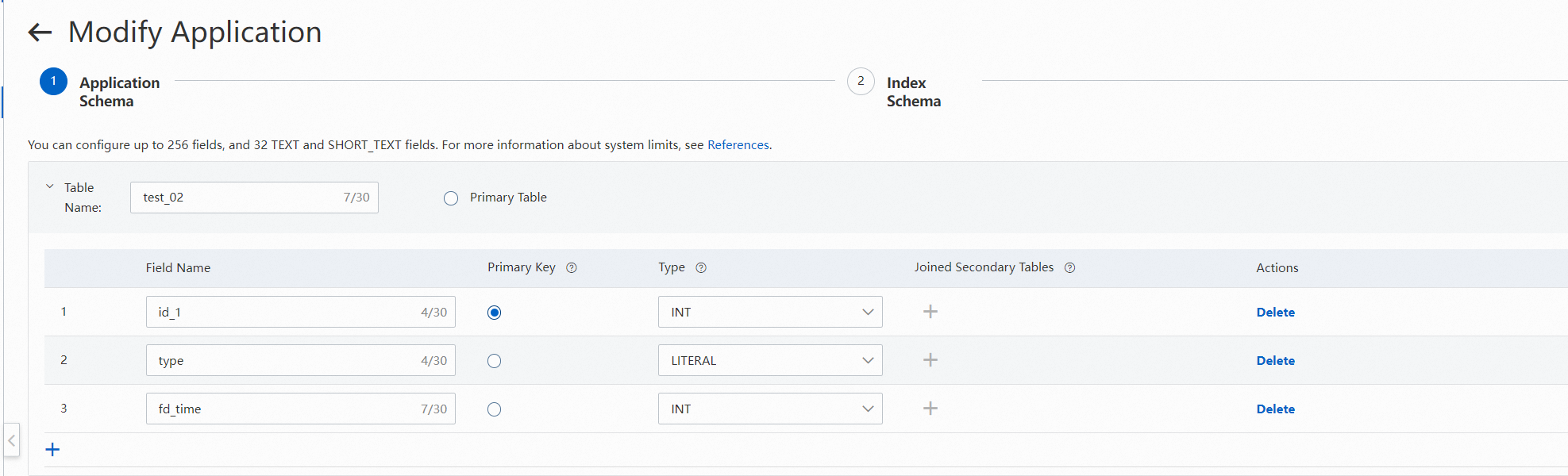
When you configure the application schema, you must create a primary table and a unique primary key field for each table.
Configure the index schema. You can select an appropriate analyzer based on your search requirements. For more information, see Index schema. Then, click Next.
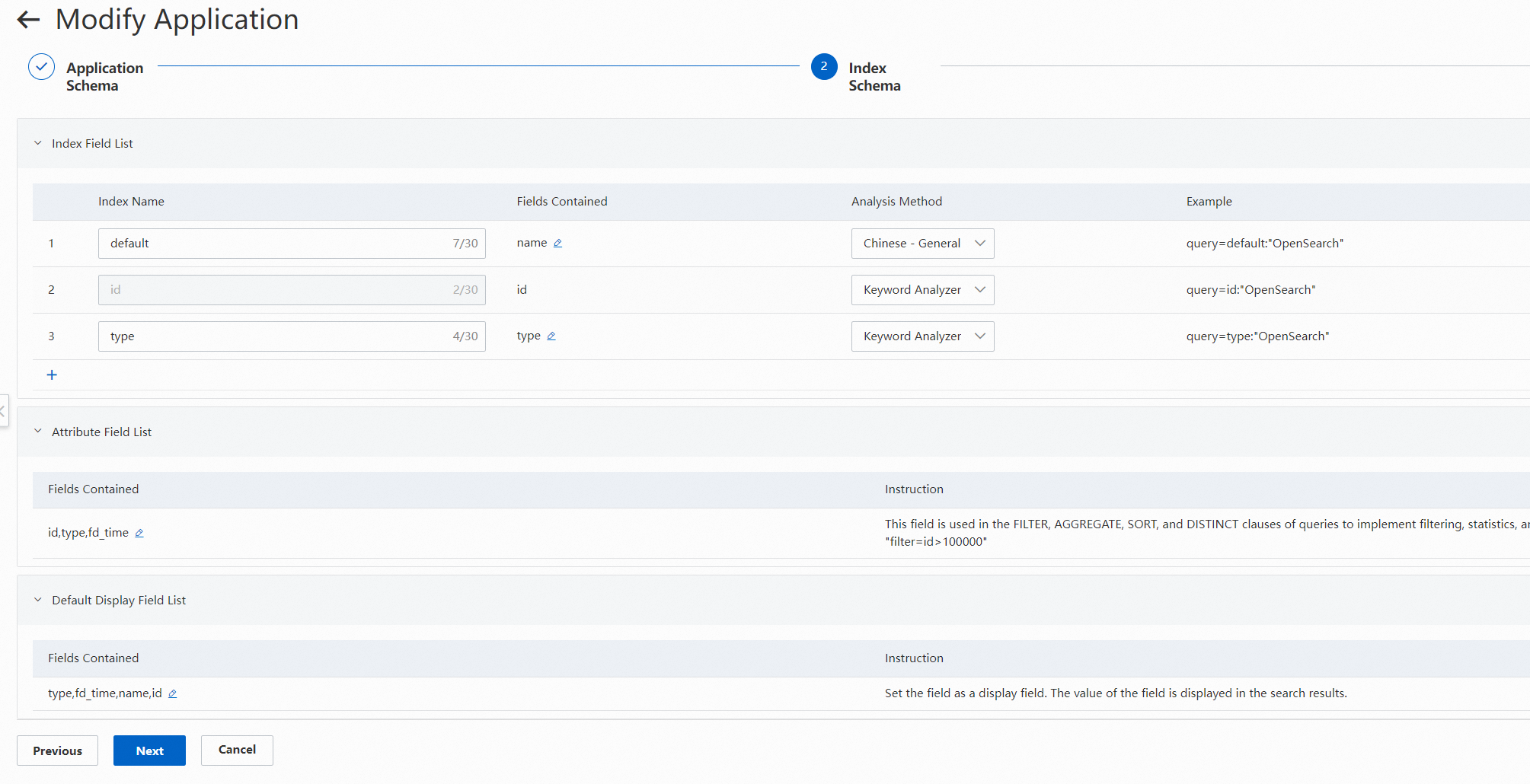
Configure a data source. In this step, you can configure field mappings, partition information, and concurrency control for data synchronization.
5.1 Configure field mappings: Click Edit in the Action column. OpenSearch provides multiple data source plug-ins for MaxCompute data. If you need to use a plug-in, click the plus sign (+) in the Content Conversion column when you configure a field mapping. This way, the source field is converted before it is synchronized to OpenSearch. If the plug-in does not work due to errors such as configuration errors or connection failures, the source field is synchronized to the destination field without content conversion.
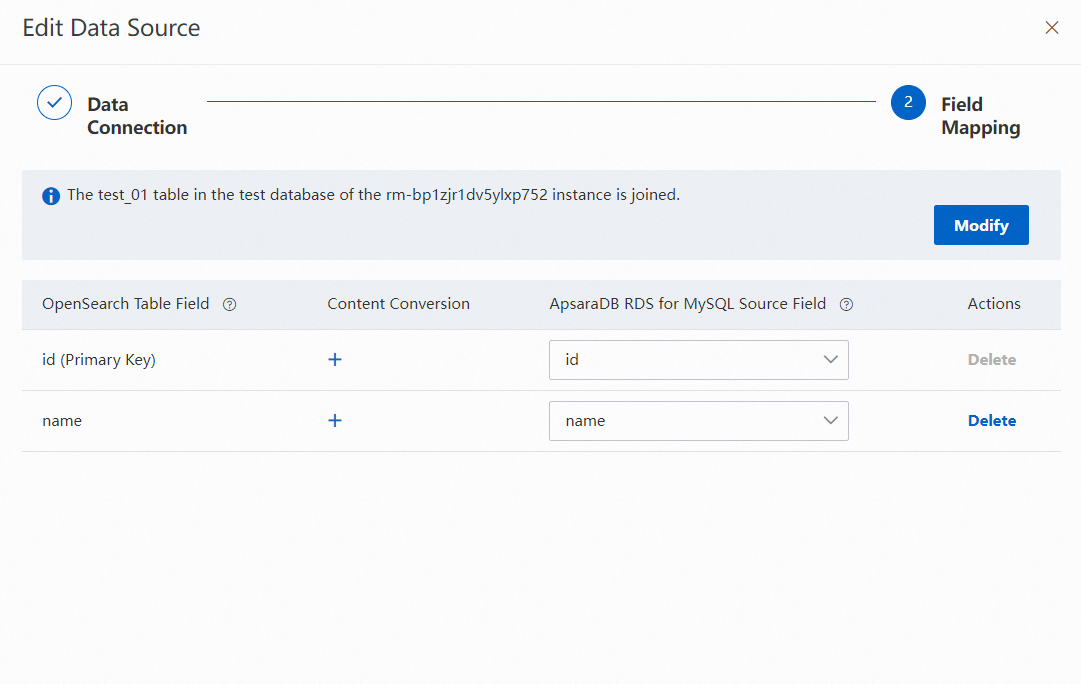
Configure the plug-in.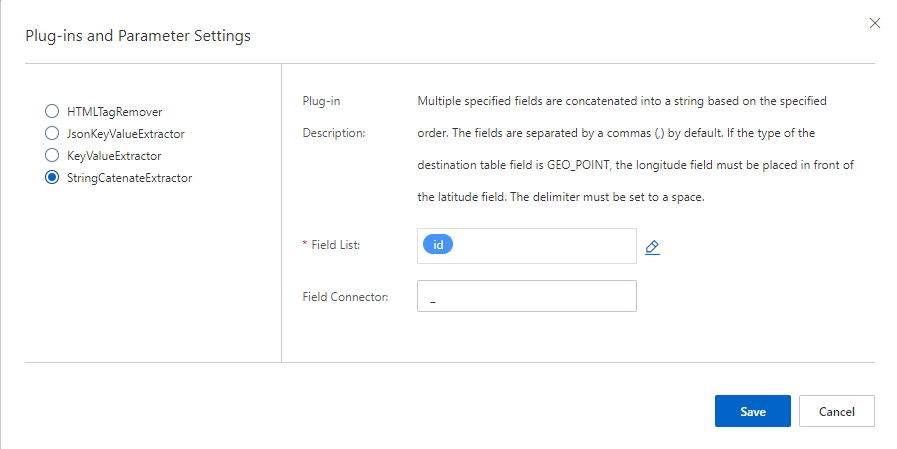
The system automatically converts data of the DATETIME type in MaxCompute tables to milliseconds. You must set the type of the corresponding OpenSearch fields to INT.
The following types of MaxCompute data are supported: BIGINT, DOUBLE, BOOLEAN, DATETIME, STRING, and DECIMAL.
5.2 Select a partition: OpenSearch supports regular expressions for you to select a partition whose data you want to import based on the characteristics of MaxCompute data. For example, the regular expression in the following figure specifies to import the data of the previous day. You can click Reindex on the Application Details page to create a scheduled reindexing task. This way, incremental partition data can be imported every day.
Regular expression: Equal signs (=), commas (,), semicolons (;), and double vertical bars (||) are reserved characters of the system. For example, ds=%Y%m%d || -1 days specifies automatic import of the full data of the specified partition of the previous day.
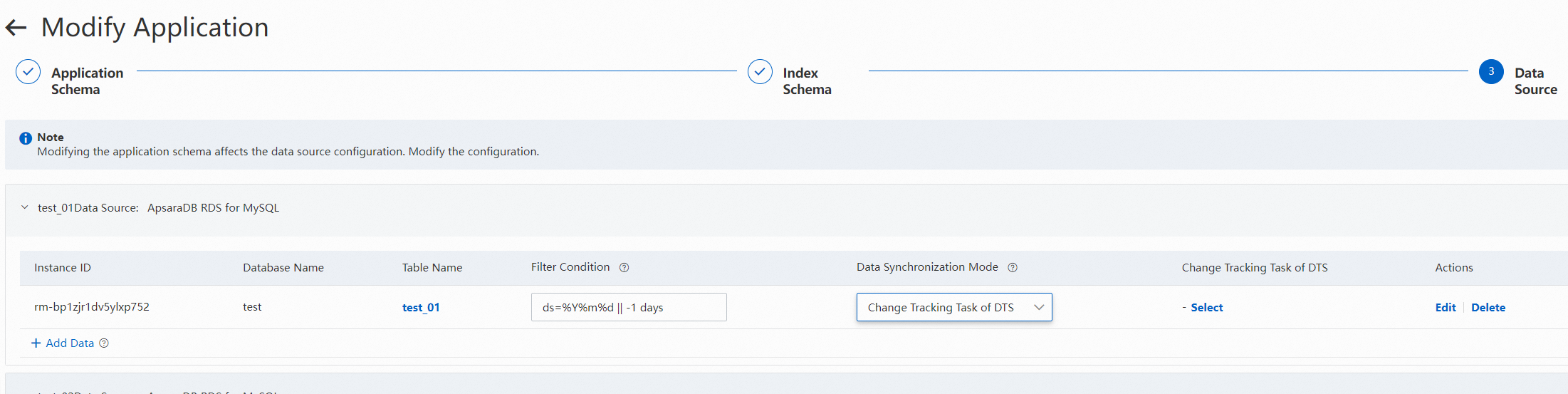
ds specifies the name of the partition field. No other invisible characters such as spaces are allowed on either side of the equal sign (=).
The following section describes how to configure partition conditions of MaxCompute:
1: You can specify multiple partition filter rules by separating them with semicolons (;). For example, pt=1;pt=2 matches all partitions that meet the partition filter rule pt=1 or pt=2.
2: You can set multiple partition fields in a partition filter rule by separating them with commas (,). For example, pt1=1,pt2=2,pt3=3 matches all partitions that meet all the partition filter conditions pt1=1, pt2=2, and pt3=3. Functions such as %Y%m%d || -1 days do not support multiple partition fields, but support a single partition field.
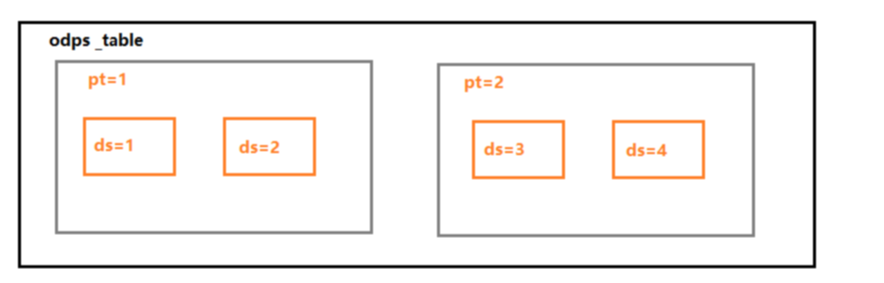
Example: The pt partitions in a MaxCompute table contain ds child partitions, as shown in the preceding figure.
Specify multiple partitions: pt=1;pt=2 specifies the synchronization of all data in pt=1 and pt=2 partitions.
Set multiple partition fields: pt=1,ds=1 specifies the synchronization of the data in the ds=1 child partition of the pt=1 partition.
pt=1,ds=%Y%m%d || -1 days or pt=1;pt=%Y%m%d || -1 days is not supported.
3: The value of a partition field can be an asterisk (*), which indicates that the value of the partition field can be an arbitrary value. In this case, this field is optional in the filter rule.
4: The value of a partition field can contain a regular expression. For example, pt=[0-9]* matches all partitions whose pt value is a number.
5: The value of a partition field supports time matching. The filter rule is in the following format: pt=Partition field value that contains formatted time || Time interval expression. For example, ds=%Y%m%d || -1 days indicates that the partition field is ds, the formatted time is 20150510, and the data of the previous day is required.
5.1 Formatted time parameters can be standard time format parameters.
5.2 The time interval expression can be in the following format: +/- n week|weeks|day|days|hour|hours|minute|minutes|second|seconds|microsecond|microseconds. The plus sign (+) indicates N weeks, days, hours, minutes, seconds, or milliseconds after a scheduled reindexing task is created. The minus sign (-) indicates N weeks, days, hours, minutes, seconds, or milliseconds before a scheduled reindexing task is created.
5.3 By default, the system converts time parameters in all filter rules by using the +0 days condition. Therefore, the field values that are used for filtering cannot contain the following strings as regular string parameters. For example, for tasks that are created on Wednesday, pt=%abc matches the partitions whose pt value is Wedbc instead of pt=%abc.
The following list describes all parameters that can be contained in regular expressions:
%d: the sequence number of the day in the month.
%H: the hour in a 24-hour system. Valid values: [0, 23].
%m: the sequence number of the month in the year. Valid values: [01, 12].
%M: the minute. Valid values: [00, 59].
%S: the second. Valid values: [00, 61].
%y: the year represented by two digits.
%Y: the year represented by four digits.5.3. Configure concurrency control for data synchronization:
If you select Use DONE File, you can upload a DONE file to control the timing for OpenSearch to pull full data. This ensures the data integrity. Before OpenSearch pulls full data from MaxCompute, OpenSearch checks whether the DONE file of the current day exists. If the file does not exist, OpenSearch waits for the DONE file to appear. The default timeout period is 1 hour.
You must download the MaxCompute client (odpscmd) from the official website of MaxCompute. The file name of the package is odps_clt_release_64.tar.gz.
You must have the CreateResource permission on the required MaxCompute project.
After you install the MaxCompute client, run the following command on your MaxCompute client. The DONE file is named in the $prefix_%Y-%m-%d format. $prefix: By default, the prefix of the name of the DONE file is the table name. %Y-%m-%d specifies the date of a scheduled reindexing task. The minimum interval for scheduled reindexing tasks is one day.
odpscmd -u accessid -p accesskey --project=<prj_name>-e "add file <done file>;"For more information about how to use odpscmd in the MaxCompute client, see MaxCompute client (odpscmd).
The content of DONE files is in the JSON format. A DONE file needs to contain only the timestamp in milliseconds of the current full data. The system retains only the incremental data in the recent three days. Therefore, the point in time that is specified by the timestamp must be within the latest three days.
The timestamp in a DONE file indicates the point in time of the incremental data to be pulled. If you do not specify the timestamp, incremental data from the start time of the scheduled reindexing task is appended. OpenSearch retains only the incremental data in the recent three days. Therefore, the point in time must be within the last three days.
For example, full data is generated at 09:00 on the current day, MaxCompute processes the full data at 10:00, and the scheduled reindexing task in OpenSearch starts at 10:30. After MaxCompute processes the full data, the incremental data after 09:00 on the current day is appended. You must specify the timestamp that corresponds to 09:00 on the current day in milliseconds in the DONE file to ensure data integrity. Otherwise, the incremental data after 10:30, the default start time of the scheduled reindexing task, is appended. The incremental data from 09:00 to 10:30 is lost. Proceed with caution. If no incremental data is generated, you do not need to specify the timestamp.
The following sample code shows an example of the content of a DONE file for an advanced application. The timestamp in the DONE file is used to append incremental data. You can use a similar method to specify the timestamp in DONE files for standard applications.
{
"timestamp":"1234567890000"
}Priorities of a DONE file and the data time:
The data time of MaxCompute data sources is required and takes precedence over a DONE file.
If you create only one version for an application, you need to specify only the data time. In this case, you cannot use a DONE file alone.
If you need to use a scheduled reindexing task, you must specify both the data time and a DONE file. The data time takes precedence over the DONE file for the first version. The DONE file takes precedence over the data time for subsequent versions.
Usage notes
MaxCompute data sources support only full synchronization, but do not support incremental synchronization.