This topic describes how to modify existing jobs for different scenarios when you migrate from external projects in Data Lakehouse Solution 1.0 to external schemas in Data Lakehouse Solution 2.0. This topic also describes the compatibility of existing jobs after you enable the schema modes for project-level metadata and SQL syntax in Data Lakehouse Solution 2.0.
The features and usage of external projects in Data Lakehouse Solution 1.0 (External Project 1.0) are no longer being developed and will be discontinued. If you use MaxCompute to access federated data sources, you must upgrade the federation solution to Data Lakehouse Solution 2.0.
Background information
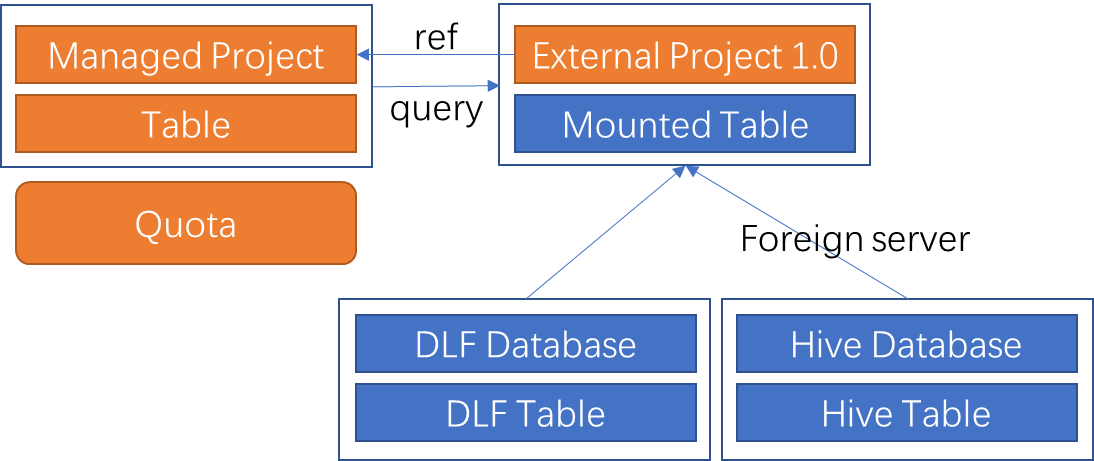
Data Lakehouse Solution 1.0 supports federating with two types of data sources using external projects: DLF+OSS and HMS+HDFS. In Data Lakehouse Solution 1.0, the level above a table is the project. The project level maps to a database in DLF or Hive.
For data lakes federated with DLF and OSS, the external project in Data Lakehouse Solution 1.0 directly contains connection information. The MaxCompute engine connects to DLF metadata and OSS data using the properties of the external project.
For HMS+HDFS Hadoop instances, a Foreign Server object is used to store the connection information for accessing the instance. The MaxCompute engine uses the external data source to read Hive metadata and data.
Comparison between Data Lakehouse Solution 1.0 and Data Lakehouse Solution 2.0
The federation method in Data Lakehouse Solution 1.0 has some limitations. Data Lakehouse Solution 2.0 provides optimizations to address these issues. The following table compares the two solutions.
Item | Data Lakehouse Solution 1.0 | Data Lakehouse Solution 2.0 |
External data source | External data source objects are inconsistent across different federation scenarios. The lack of an abstracted external data source hinders resource sharing and access control at the tenant level. | A unified Foreign Server is abstracted. This better separates tenant-level permissions from data-level permissions and simplifies sharing and permission management. |
Project model | Tables are stored directly in projects. This model is inconsistent with the more common To map to the management object at the level above tables in a data source, such as a database in DLF or a schema in Hologres, you must create many external projects. | Projects are upgraded to support the schema model. You can create new projects that use the |
Computation method | Although an external project in Data Lakehouse Solution 1.0 is a project-level object, it must rely on a data warehouse project to run computing jobs. This increases the complexity of cross-project data access authorization. | Data Lakehouse Solution 2.0 introduces the External Schema to map to the level above table objects in a data source. An external schema uses the computing resources of the data warehouse project to which it belongs. |
Internal and external mappings |
|
|
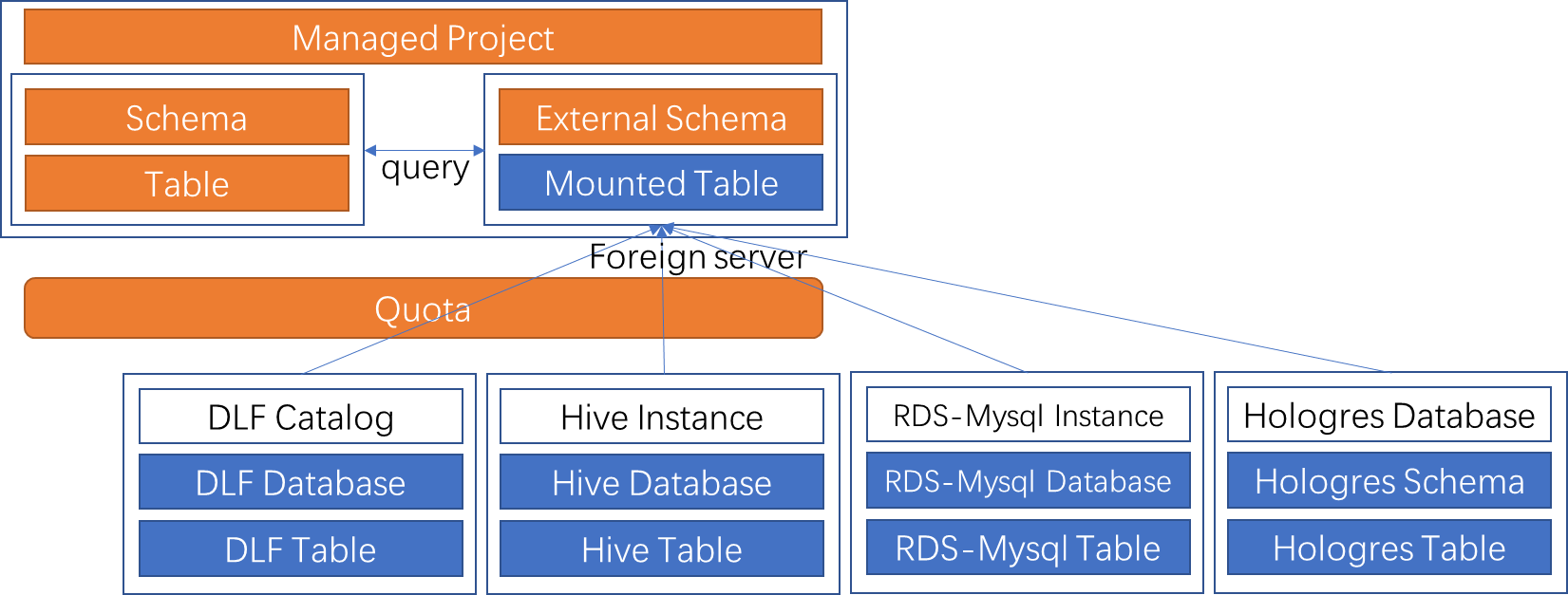
For more information about how to create an external data source and an external project, see User guide for Data Lakehouse Solution 2.0.
Schema modes and compatibility
MaxCompute lets you enable the schema feature. Two switches are available: the schema mode for project-level metadata and the schema mode for SQL syntax.
Schema mode for project-level metadata
You cannot disable this mode after you enable it. Enabling this mode may cause compatibility issues with other tasks in your project and with access to your project. Proceed with caution.
Changes to the project structure
After you enable the schema mode for project-level metadata, the project structure is
Project.Schema.Table.When the schema mode is disabled, the project structure is
Project.Table.
Accessing data in custom schemas
To access data in a custom schema, you must enable the schema mode for SQL syntax. Otherwise, you can access only data in the DEFAULT schema.
Built-in schema
Each project has a built-in schema named Default. You cannot delete this schema.
Procedure
Log on to the MaxCompute console and select a region in the top-left corner.
In the navigation pane on the left, choose .
On the Projects page, find the target project, and in the Actions column, click Enable Schema.
Schema mode for SQL syntax
The schema mode for SQL syntax can be set at two different levels: session level and tenant level. The applicable scope differs for each level.
Session-level settings
These settings affect only the semantics of the current session and take precedence over tenant-level settings. You can run the SET odps.namespace.schema= true | false; command to enable or disable the schema mode for SQL syntax.
Tenant-level settings
After you enable the schema mode for SQL syntax at the tenant level, note the following:
All jobs: You no longer need to add the session-level syntax switch. New projects support the schema mode for metadata by default.
All projects: All projects support the schema mode for SQL syntax. You cannot disable this mode after you enable it.
If existing jobs in your project are incompatible with the schema mode for SQL syntax, enabling this switch causes the existing jobs to fail. Therefore, you must first enable the schema mode for SQL syntax at the session level. After you verify that the jobs run as expected, you can enable the schema mode for SQL syntax at the tenant level.
Procedure
Log on to the MaxCompute console and select a region in the top-left corner.
In the navigation pane on the left, choose .
On the Tenants page, click the Tenant Property tab.
If no projects exist under the current tenant
On the Tenant Property tab, turn on the Tenant-level Schema Syntax.
If projects exist under the current tenant
Do not modify the setting.
For more information, see Tenant properties.
Compatibility impact
Compatibility errors occur if the schema mode for project-level metadata and the schema mode for SQL syntax in Data Lakehouse Solution 2.0 are not in the same state (one is enabled while the other is disabled).
Consider a data warehouse project where both the schema mode for project-level metadata and the schema mode for SQL syntax are disabled. The project structure is project(p).table(t), and existing jobs run normally.
When you enable the schema mode for metadata for the data warehouse project
Or when you enable the schema mode for SQL syntax for query jobs in the data warehouse project
If you run the original query jobs without changing the SQL expressions, compatibility errors may occur. The following table describes the details.
Schema mode status | Job type | Compatibility | Suggestion |
| Existing job |
|
|
New Task |
| No modification is required. | |
| Existing job |
| No modification is required. |
New Job |
Note In the current state, you cannot access custom schemas or use | No modification is required. | |
| Existing job |
|
|
New Task | You can use the supported schema mode and syntax rules. | No modification is required. |
Migration guide
Based on your scenario, you can select an existing project or create a new one, and then enable the schema mode for project-level metadata. After you enable this mode, a Default schema is automatically generated. All internal tables in the project belong to the Default schema. For more information about schemas, see Schema and Schema operations.
You cannot disable the schema mode for project-level metadata after you enable it. Enabling this mode may cause compatibility issues with other tasks in your project and with access to your project. Proceed with caution. For more information about schema compatibility, see Schema modes and compatibility.
You can create an external schema in the project for which the schema mode for metadata is enabled. The creation details vary based on your data source type. For more information, see User guide for Data Lakehouse Solution 2.0.
Set the name of the external schema to be the same as the name of the external project.
Scenario 1: Create an external schema in the project that runs existing jobs and access data in the external schema
Example scenario: The project that runs the existing jobs is project (p1). The query targets an external project that is specified as
external_project(e).table(t). After the migration, the federated data source is remapped to the structureproject (p1).external_schema(e).table(t).If the existing job is
SELECT * FROM e.t;After you enable the schema mode for SQL syntax, the structure of
e.tis parsed asexternal_schema(e).table(t). The job can run normally in project (p1) without modification.If you do not enable the schema mode for SQL syntax, the structure of
e.tin the existing jobSELECT * FROM e.t;is parsed asproject (e).table(t). The system queries an internal or external project namede. This is inconsistent with the remapped structure, and the existing access job fails.
If project (p1) is associated with an external project for a data query, for example,
SELECT * FROM e.t1 JOIN p1.t2;.After you enable the schema mode for SQL syntax,
p1inp1.t2is parsed as a schema. Therefore, you must change the SQL statement to:SELECT * FROM e.t1 JOIN p1.default.t2;.
Scenario 2: Create an external schema in another project and access data in the external schema
Example scenario: The project that runs the existing jobs is project (p1). The external project structure is
external_project(e).table(t). If it is not suitable to enable the schema mode for metadata for project (p1), you can select or create another project, project (p2), for the migration. After the migration, the federated data source is remapped to the structureproject (p2).external_schema(e).table(t).If an existing job in Project p1 contains the statement
SELECT * FROM e.t;, you must change the statement toSELECT * FROM p2.e.t;after you enable the schema mode for SQL syntax.If you run the preceding job in project (p2), no modification is required.
When you perform a cross-project join query between an external schema and a data warehouse project, if you run
SELECT * FROM e.t1 JOIN p1.t2;in project (p1), the system still queries for schema (p1) within project (p1) forp1.t2. This happens because the schema mode for SQL syntax is enabled, even though the schema mode for metadata is not enabled for project (p1). Therefore, you must change the SQL statement toSELECT * FROM p2.e.t1 JOIN p1.default.t2;.