This topic describes the major updates and bug fixes of the Realtime Compute for Apache Flink version released on May 29, 2024.
The version upgrade is incrementally rolled out across the network by using a canary release strategy. For information about the upgrade schedule, see the latest announcement on the right side of the management console of Realtime Compute for Apache Flink. You can use the new features in this version only after the upgrade is complete for your account. To apply for the upgrade at the earliest opportunity, submit a ticket.
Overview
This release includes platform and engine updates.
Platform updates
Platform updates in this release focus on system stability, O&M, and ease of use.
The cross-zone high availability feature is optimized to ensure stability. You can quickly convert the compute units (CUs) of an existing namespace from the single-zone type to the cross-zone type without the need to create a new namespace and migrate existing deployments.
Operator-level state time-to-live (TTL) is supported in the expert mode of resource configuration. You can precisely configure a state TTL value for each operator to increase stability while using fewer resources.
The Visual Studio Code extension of Realtime Compute for Apache Flink is available. The extension allows you to develop, deploy, and run deployments in the on-premises environment. It also allows you to synchronize updated deployment configurations from the development console of Realtime Compute for Apache Flink.
The UI related to data lineage and deployments is also optimized.
Engine updates
Ververica Runtime (VVR) 8.0.7 is officially released to provide an enterprise-class engine based on Apache Flink 1.17.2. VVR 8.0.7 includes the following updates:
Real-time lakehouse: The Apache Paimon connector SDK is upgraded to support the data lake format used by Apache Paimon 0.9.
SQL optimization: State TTL hints are introduced to configure separate state TTL values for regular join and group aggregation operators to control their state sizes. Named parameters are supported in user-defined functions (UDFs) to improve development efficiency and reduce maintenance costs.
Connector optimization: The MongoDB connector has completed its public preview and is generally available. The MongoDB connector can be used to create change data capture (CDC) source tables, dimension tables, and result tables. MySQL CDC features and the ApsaraDB for Redis connector are also optimized.
MySQL CDC features:
The op_type virtual column is supported to pass the operation types (+ I, +U/-U,-D) of the changed data to downstream systems. This allows you to implement business logic and data cleaning policies based on different operation types.
The read performance is optimized for MySQL tables whose primary keys are of the Decimal type. Data change records (SourceRecords) in large-size tables can be processed in parallel, which improves efficiency.
The source reuse feature is introduced. If the feature is enabled for a Flink deployment that contains multiple MySQL CDC source tables, the deployment merges the tables that have identical configurations (excluding the database name, table name, and server ID). This significantly reduces the load caused by multiple database connections and change listening on the MySQL server.
Buffered execution is supported to improve the processing performance by several times. To enable buffered execution, configure the sink.ignore-null-when-update parameter.
ApsaraDB for Redis connector: Different DDL statements are supported for non-primary keys when you use the connector to create a dimension table or result table that contains data of the HashMap type. This improves code readability. Prefixes and delimiters can be configured for keys to meet data governance requirements.
Catalog management: The view information is no longer displayed for MySQL catalogs. This prevents data operation errors because a MySQL view is a logical structure and cannot read and write data.
Security: Hadoop 2.x is supported for Hadoop clusters that have Kerberos authentication enabled. Sensitive information, such as connector configurations, is masked in logs.
For information about the major updates in this release and the related references, see the next section of this topic. The version upgrade is incrementally rolled out across the network by using a canary release strategy. After the upgrade is complete for your account, we recommend that you upgrade the VVR engine to this version. For more information, see Upgrade the engine version of a deployment. We look forward to your feedback.
Features
Feature | Description | References |
Cross-zone high availability optimization | The CUs of an existing namespace can be converted between the single-zone type and the cross-zone type. | |
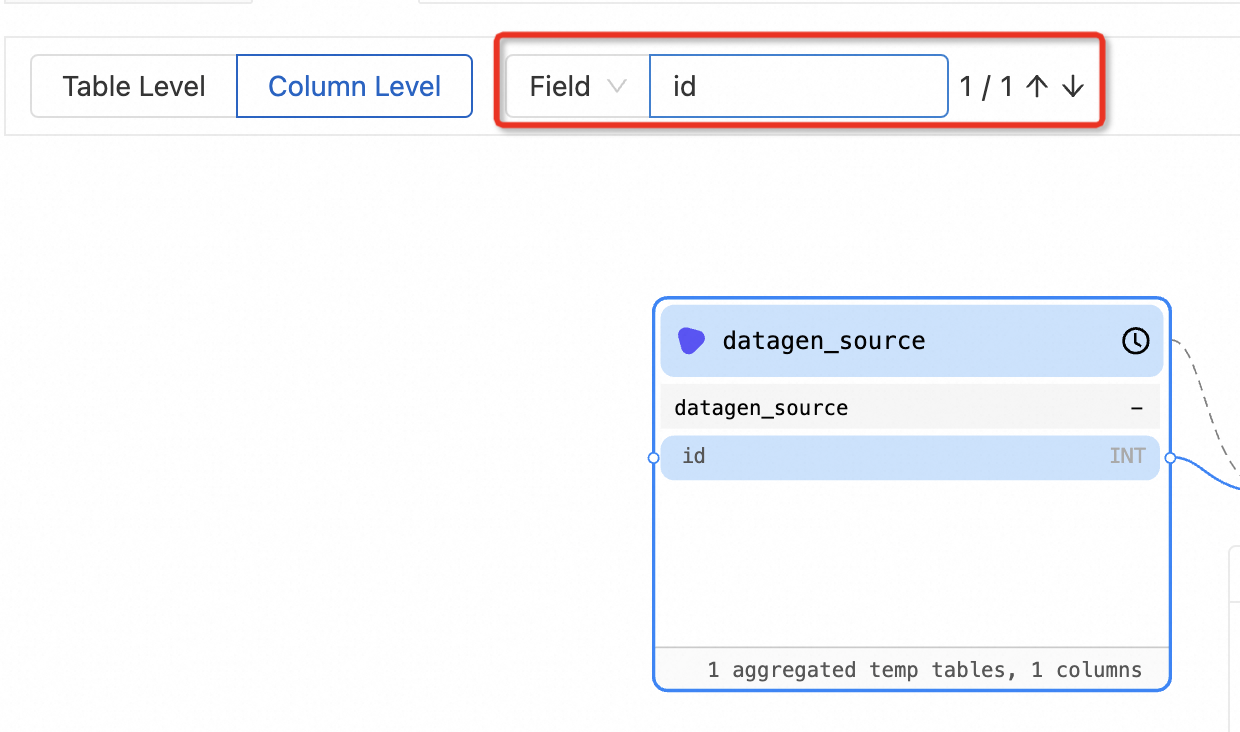
Data lineage optimization | If multiple matches are found during the search for a field by name, you can press the up and down keys to quickly locate a result to view data lineage information.
| |
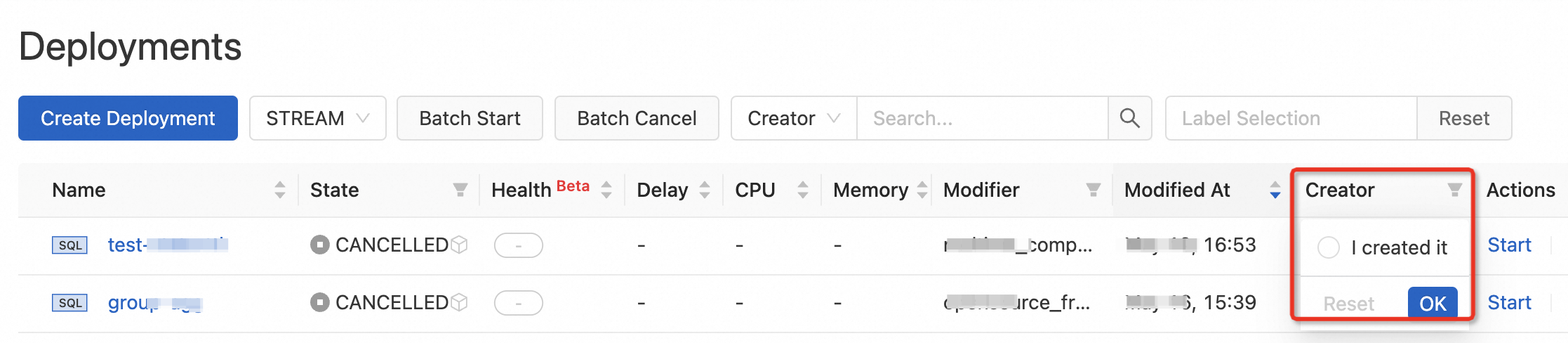
Creator field on the Deployments page | The Creator field can be displayed on the Deployments page. To display the Creator field, click the
| N/A |
Optimized permission management | By default, the creator of a workspace, such as an Alibaba Cloud account, a Resource Access Management (RAM) user, or a RAM role, is assigned the owner role in the namespaces that belong to the workspace. | |
Optimized state compatibility check for SQL deployments | If you start a SQL deployment by resuming from the latest state, the system automatically detects deployment changes. We recommend that you click Click to detect next to State Compatibility to perform a state compatibility check and determine the subsequent actions based on the compatibility result. | |
Visual Studio Code extension | This extension allows you to develop, deploy, and run SQL, JAR, and Python deployments in the on-premises environment. It also allows you to synchronize updated deployment configurations from the development console of Realtime Compute for Apache Flink. | |
Operator-level state TTL | This feature is suitable for scenarios in which only specific operators require a large state TTL value. You can use multiple methods to configure a state TTL value for an operator to control its state size. This reduces the resource consumption of large-state deployments.
| |
Named parameters in UDFs | This feature improves development efficiency and reduces maintenance costs. | |
Enhanced MySQL connector |
| |
Enhanced ApsaraDB for Redis connector |
| |
Buffered reading for ApsaraMQ for RocketMQ instances | This feature improves processing efficiency and reduces resource costs. | |
Removal of view information in MySQL catalogs | The view information is no longer displayed for MySQL catalogs because a MySQL view is a logical structure and does not store data. | |
Enhanced compatibility for Hadoop clusters that have Kerberos authentication enabled. | Hadoop 2.x is supported for Hadoop clusters that have Kerberos authentication enabled. | Register a Hive cluster that supports Kerberos authentication |
Enhanced Apache Iceberg connector | Apache Iceberg 1.5 is supported. |

Fixed issues
If the Hologres connector is used in VVR 8.0.5 or 8.0.6, the pushdown of a WHERE clause may affect data correctness.
If the Simple Log Service connector is used to create a source table, data loss may occur during a failover because the source table continues to commit data at the consumer offset.
If TTL is configured for a ValueState object but not configured for a MapState object, the states stored in the ValueState object may be lost.
Deserialization results for the WithinType.PREVIOUS_AND_CURRENT parameter in dynamic complex event processing (CEP) may be inconsistent.
The value of the currentEmitEventTimeLag metric displayed on the web UI of Realtime Compute for Apache Flink is inconsistent with that displayed on the monitoring page of the console.
All issues in Apache Flink 1.17.2. For more information, see Apache Flink 1.17.2 Release Announcement.