You can use the data lineage feature to track data in a deployment. This way, you can efficiently manage and optimize the data streams of the deployment, quickly identify issues, and evaluate the impact of the issues. This topic describes how to view data lineage from the deployment perspective and metadata perspective.
Background information
If the source and change history of data cannot be traced, the data quality and security cannot be ensured, and the efficiency of data analysis and troubleshooting is low. To address this issue, you can use the data lineage feature. Data lineage shows the relationships that are established during data generation, processing, transmission, and consumption. The relationships include the flow directions and dependencies between metadata, and the production and consumption relationships between metadata and streaming or batch deployments. Realtime Compute for Apache Flink allows you to view and analyze data lineage at the table level and the field level for a specific layer of deployments. The following table describes the benefits of data lineage.
Benefit | Description |
Improved data verification efficiency | Data lineage allows you to track data and have a comprehensive understanding of data, including the services, databases, and tables that are involved in your deployment, the properties and associations of table fields, the source of the data, the data processing steps, the transmission path, and the final consumer. This way, you can better learn about the flow directions and dependencies of the data. This helps you verify the credibility and accuracy of the data to better manage and analyze data and improve work efficiency. |
Improved troubleshooting efficiency | If an error occurs during data processing, you can view the data lineage to identify the root cause of the error. This helps you quickly identify and resolve the issue to prevent business loss and reduce labor costs. |
Improved data analysis efficiency | If data assets change or an error occurs, you can view the data lineage to quickly identify the affected online deployments and resolve the issue at the earliest opportunity. This helps you avoid incorrect decisions. |
Reduced data asset costs | Data lineage helps you understand the forwarding paths and dependencies of data to optimize data processing and unpublish services that are not called for a long period of time at the earliest opportunity. This helps improve the data processing efficiency and quality and reduces data costs. |
Data lineage model
The following figure shows the model of data lineage.

The preceding figure contains nodes (entities) and edges (relationships). The combination of entities and relationships is displayed as data lineage.
Item | Description |
Node | Each catalog, data table, and field can be considered a data entity. Entities are abstracted as nodes in data lineage. Data lineage contains the following types of nodes:
|
Relationship | Relationships between entities include the relationship between an entity and the upstream entity that produces data and the relationship between the entity and the downstream entity that consumes the data. Data lineage contains the following relationships:
|
Limits
You can view only the data lineage between deployments and metadata in a namespace. You cannot view data lineage across namespaces.
If you want to view the data lineage from the metadata perspective, you must use a catalog. If you want to view the data lineage from the deployment perspective, you do not need to use a catalog.
You can view and search for the data lineage of only SQL deployments.
You can view the data lineage of only an existing SQL deployment that is started once. The most recent data lineage is retained after the deployment is canceled.
The data lineage feature supports only the QueryOperation, SinkModifyOperation, and CreateTableAsTableOperation operations. This feature cannot track or display the data lineage information about other types of operations, such as the execution of the CREATE DATABASE AS statement, filter operations, and JOIN operations.
View data lineage from the deployment perspective
On the Deployments page in the development console of Realtime Compute for Apache Flink, you can find the desired deployment and view information about deployment nodes and data nodes, the dependencies between tables of the deployment, and the affiliation relationships between tables and fields of the deployment.
By default, the deployment is used as the central node and three-layer data lineage is displayed. The three layers are the upstream table, central deployment, and downstream table. If you want to trace the previous data lineage, click the plus sign on the left side of the upstream table. If you want to track the subsequent data lineage, click the plus sign on the right side of the downstream table.
Log on to the Realtime Compute for Apache Flink console.
Find the workspace that you want to manage and click Console in the Actions column.
In the left-side navigation pane of the development console of Realtime Compute for Apache Flink, choose . On the Deployments page, find the desired deployment and click the name of the deployment.
Click the Lineage tab. On the Lineage tab, click Table Level to view table-level data lineage or Column Level to view field-level data lineage.
Table-level data lineage
Displays the node type, connector type, catalog name, database name, name of the destination table, name of the source table, and deployment information, such as the ID, creation time, and creator of the deployment, the time when the deployment was last modified, and the user who last modified the deployment.
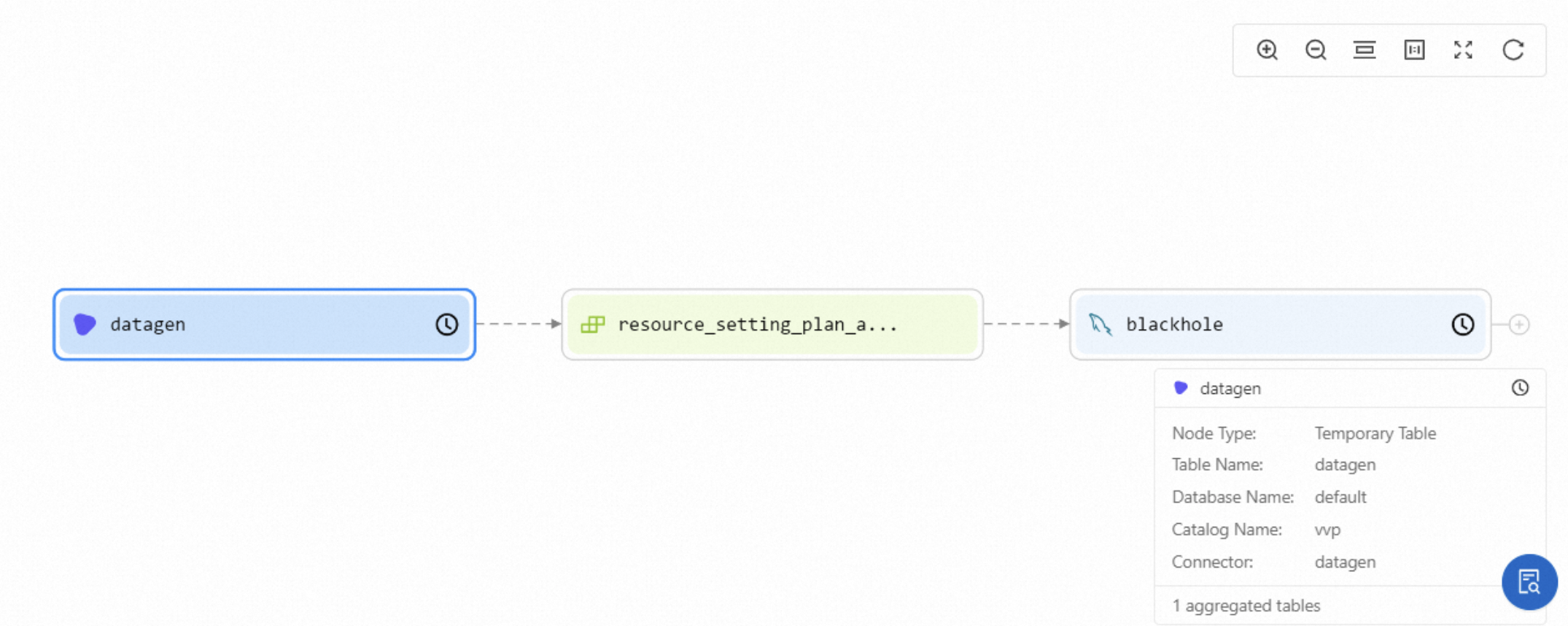
Field-level data lineage
Displays the names and types of table fields, the database names, catalog names, and connector types of tables, and deployment information.
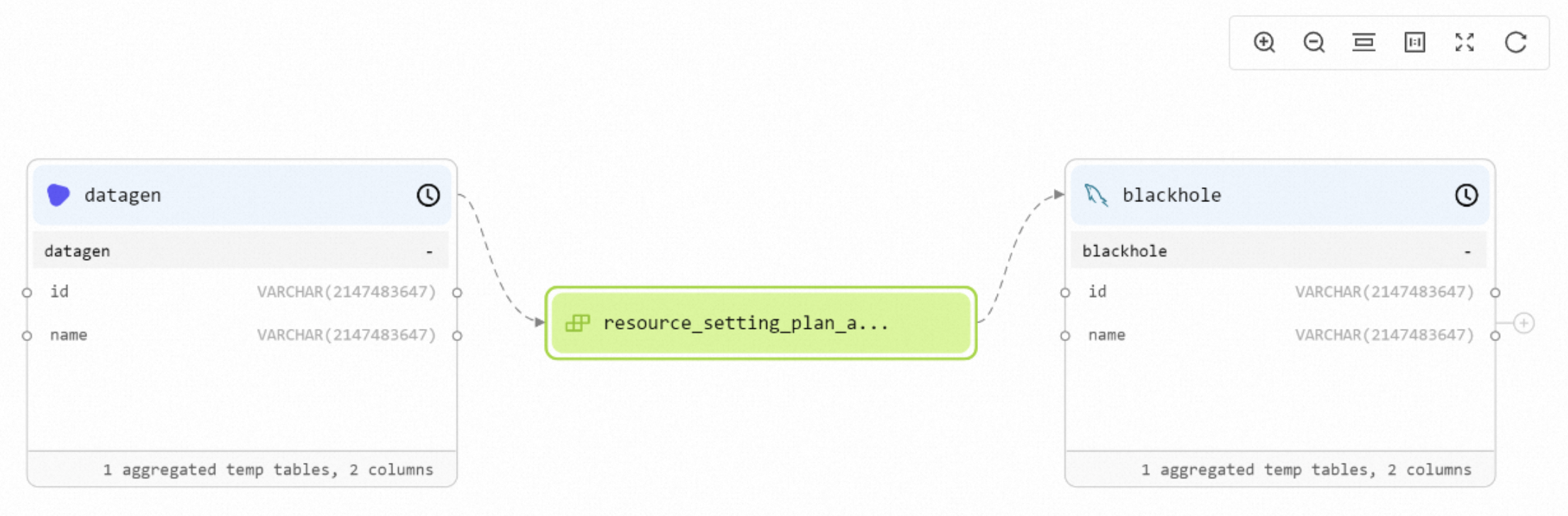
View data lineage from the metadata perspective
If a large number of deployments are associated with a table in a catalog, the data lineage graph may be unclear. In this case, you can zoom in or zoom out on the data lineage graph. You can also turn on Auto focus clicked node. After you turn on this switch and click the desired deployment or table, the related node is automatically centered.
Log on to the Realtime Compute for Apache Flink console.
Find the workspace that you want to manage and click Console in the Actions column.
In the left-side navigation pane of the development console of Realtime Compute for Apache Flink, click Catalogs. On the Catalogs page, double-click the name of a table below a specific database of a catalog.
On the Lineage tab, click Table Level to view table-level data lineage or Column Level to view field-level data lineage.
Table-level data lineage
You can view the deployments that reference a specific table in the catalog. If the table schema or table data changes, you can quickly handle the deployments that reference the table. For example, you can modify the code of the deployments or cancel the deployments.
Double-click the desired deployment node. You can view the ID, creation information, and modification information of the deployment. To redirect to the Deployments page for the deployment, click the deployment name in the position that is framed in red in the following figure.
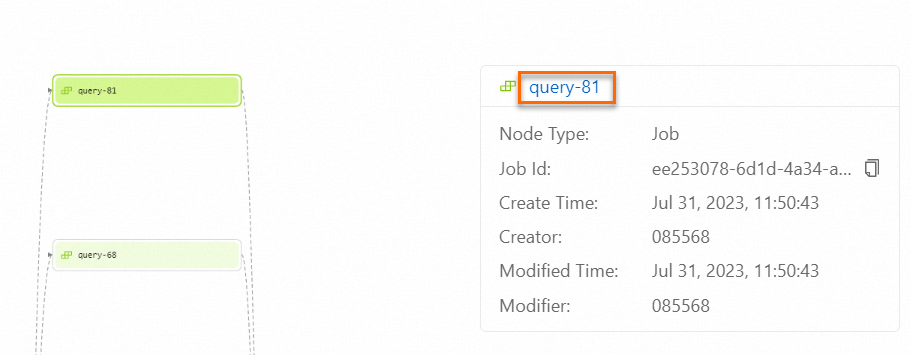
Field-level data lineage
You can click the desired field to identify the deployments and tables that reference the field and find the associated fields based on blue solid lines. If the field is deleted or the name or attribute of the field changes, you can quickly identify deployments and tables that reference the field, find the associated fields, and handle the associated fields.
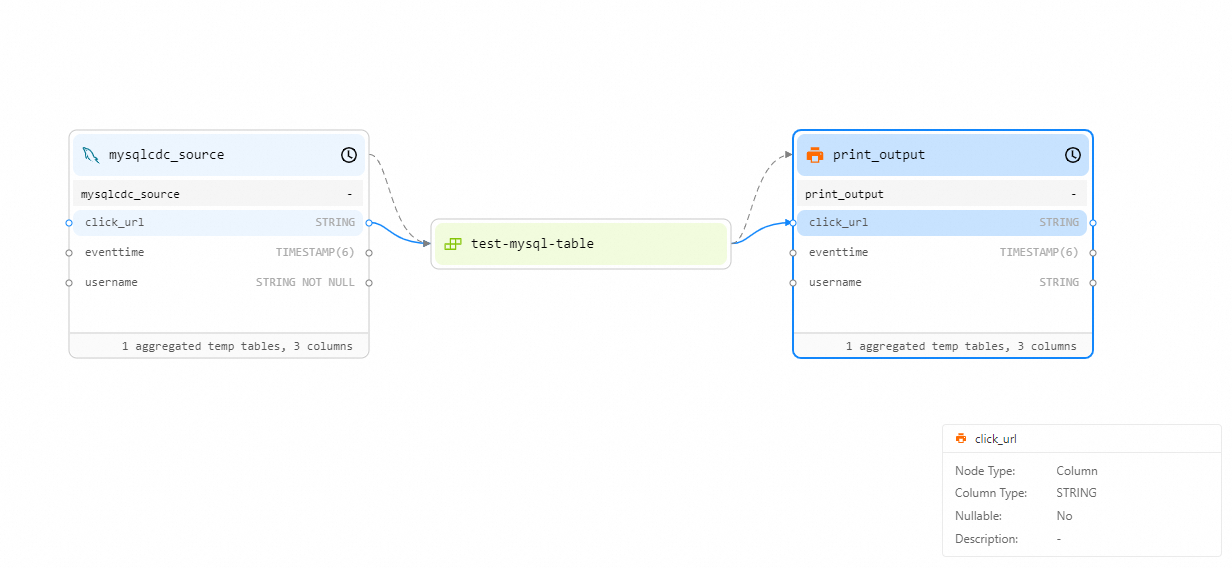
View data lineage by node name or field name
If the data lineage graph is complex, you can search for the desired node or field by name to quickly view information about the node or field.
In the left-side navigation pane of the development console of Realtime Compute for Apache Flink, choose . On the Deployments page, click the name of the desired deployment. On the Lineage tab of the Deployments page, enter the name of the desired node or field in the search box and press Enter. You can enter a field only on the Column Level tab.
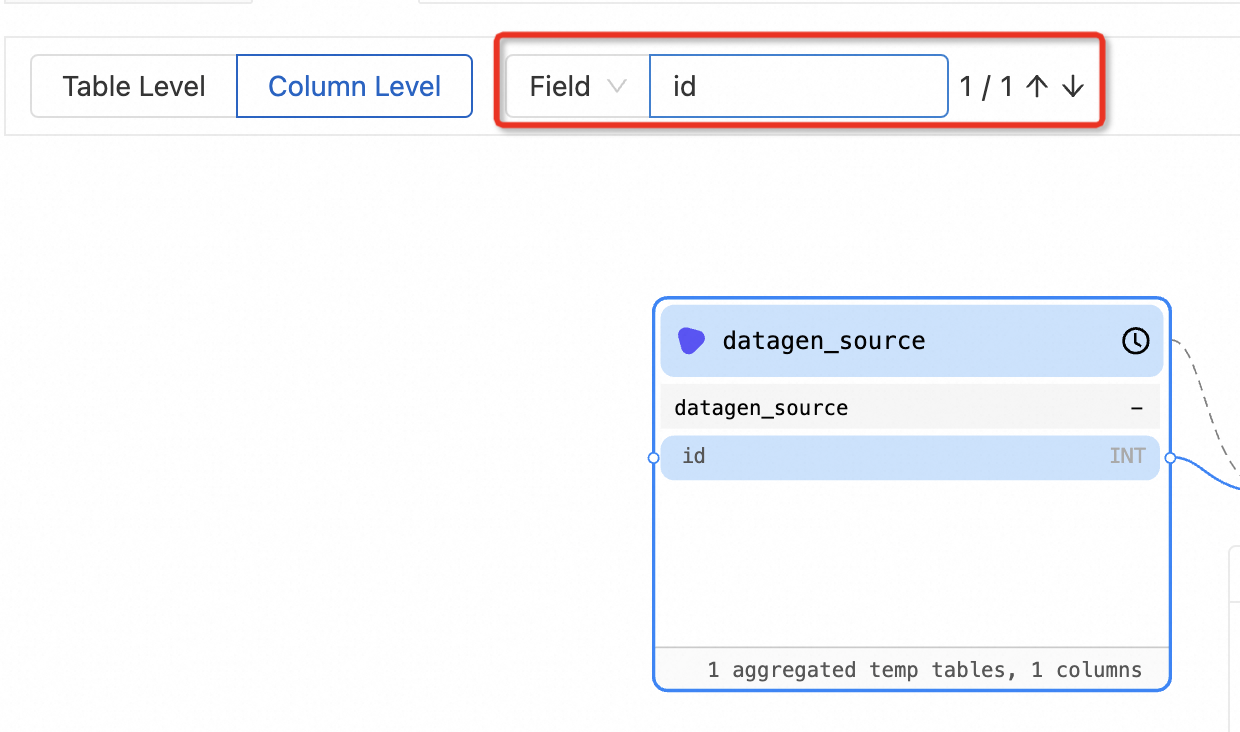
The central node changes from the current deployment to the specified node or field. The color of the node or field changes.
Double-click the name of the node or field to view the data lineage.