This topic describes some key parameters that you may need to configure when you develop an SQL draft. This topic also provides examples on how to configure the parameters.
table.exec.sink.keyed-shuffle
The table.exec.sink.keyed-shuffle parameter resolves out-of-orderness of data written to tables with a primary key. Enabling it lets your job perform hash shuffling. This ensures data with the same primary key is routed to the same operator task, reducing the probability of the disorder issue.
Usage notes
Hash shuffling is helpful only when the upstream operator can ensure the valid order of the update records in the primary key field.
If you change the parallelism of an operator for a job that runs in expert mode, the following parallelism rules do not apply.
Valid values
AUTO(default): If the parallelism of the sink operator is not 1 and distinct from the parallelism of the upstream operator, Realtime Compute for Apache Flink automatically performs hash shuffling on the primary key field when data flows to the sink operator.FORCE: If the parallelism of the sink operator is not 1, Realtime Compute for Apache Flink forcefully performs hash shuffling on the primary key field when data flows to the sink operator.NONE: Realtime Compute for Apache Flink does not perform hash shuffling based on the parallelism of the sink operator and the parallelism of the upstream operator.
Examples
AUTO
Copy and paste the code to an SQL streaming draft, and deploy the draft. Explicitly set the sink parallelism to 2:
CREATE TEMPORARY TABLE s1 ( a INT, b INT, ts TIMESTAMP(3) ) WITH ( 'connector'='datagen', 'rows-per-second'='1', 'fields.ts.kind'='random','fields.ts.max-past'='5s', 'fields.b.kind'='random','fields.b.min'='0','fields.b.max'='10' ); CREATE TEMPORARY TABLE sink ( a INT, b INT, ts TIMESTAMP(3), PRIMARY KEY (a) NOT ENFORCED ) WITH ( 'connector'='print', -- Set the parallelism of the sink operator to 2. 'sink.parallelism'='2' ); INSERT INTO sink SELECT * FROM s1; -- You can also configure the dynamic table options to specify the parallelism of the sink operator. --INSERT INTO sink /*+ OPTIONS('sink.parallelism' = '2') */ SELECT * FROM s1;Enable automatic hash shuffling.
Go to the job details page.
On the Configuration tab, find the Resources section and click Edit.
Set Parallelism to 1.
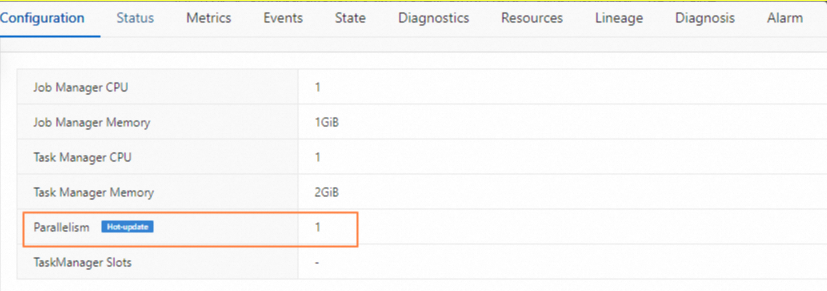
In the Parameters section, click Edit.
In the Other Configuration field, explicitly set
table.exec.sink.keyed-shuffle: AUTO. Alternatively, just leave the field empty.
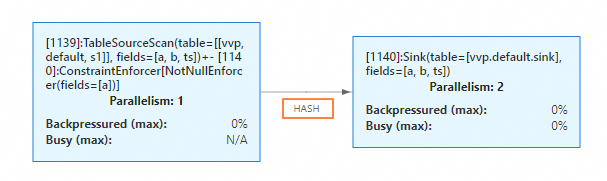
Start the job.
On the Status tab, the data connection mode between the sink operator and the upstream operator is HASH.
FORCE
Copy and paste the code to an SQL streaming draft, and deploy the draft. Do not explicitly set the sink parallelism.
CREATE TEMPORARY TABLE s1 ( a INT, b INT, ts TIMESTAMP(3) ) WITH ( 'connector'='datagen', 'rows-per-second'='1', 'fields.ts.kind'='random','fields.ts.max-past'='5s', 'fields.b.kind'='random','fields.b.min'='0','fields.b.max'='10' ); CREATE TEMPORARY TABLE sink ( a INT, b INT, ts TIMESTAMP(3), PRIMARY KEY (a) NOT ENFORCED ) WITH ( 'connector'='print' ); INSERT INTO sink SELECT * FROM s1;Enable
FORCEhash shuffling.Go to the job details page.
On the Configuration tab, find the Resources section, click Edit, and set Parallelism to 2.
In the Parameters section, click Edit.
In the Other Configuration field, add
table.exec.sink.keyed-shuffle: FORCE.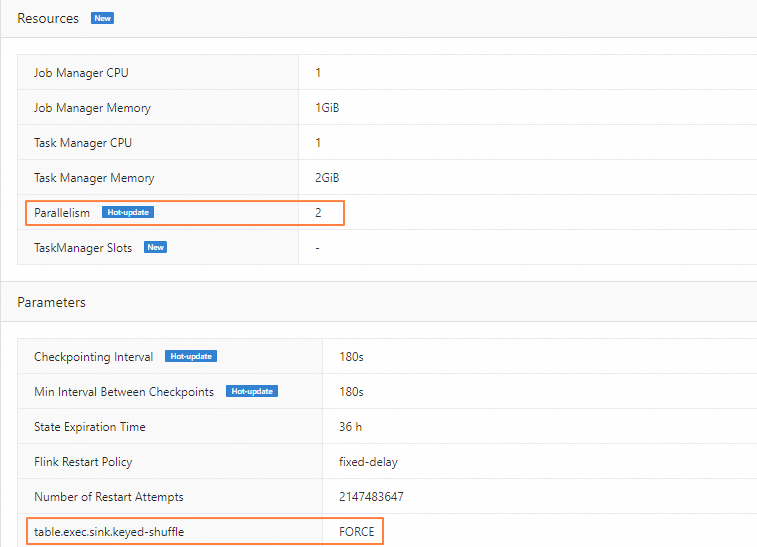
Start the job.
On the Status tab, both the parallelism of the sink operator and its upstream operator are 2 and the data connection mode is HASH.
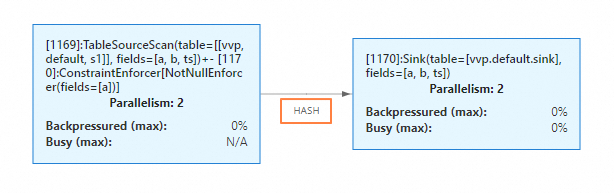
table.exec.mini-batch.size
This parameter specifies the maximum number of input records that can be cached on compute operators for micro-batch operations. If the number of cached data records reaches the MiniBatch size, calculation and data output are triggered. This parameter takes effect only when it is used together with the table.exec.mini-batch.enabled and table.exec.mini-batch.allow-latency parameters. For more information about miniBatch-related optimization, see MiniBatch Aggregation and MiniBatch Regular Joins.
Usage notes
If you do not explicitly configure this parameter in the Parameters section before a job is started, managed memory is used to cache data in miniBatch processing mode. If one of the following conditions is met, final calculation and data output are triggered:
The compute operator receives the watermark message sent by the
MiniBatchAssigneroperator.Managed memory is full.
Before checkpointing.
The job is canceled.
Valid values
-1 (default): The managed memory is used to cache data.
A negative value of the LONG type: The processing mechanism is the same as the processing mechanism for the default value.
A positive value of the LONG type: The heap memory is used to cache data. When the number of cached input records reaches the specified value, data output is triggered.
Example
Create an SQL streaming draft, copy the following test SQL statements, and then deploy the draft.
CREATE TEMPORARY TABLE s1 ( a INT, b INT, ts TIMESTAMP(3), PRIMARY KEY (a) NOT ENFORCED, WATERMARK FOR ts AS ts - INTERVAL '1' SECOND ) WITH ( 'connector'='datagen', 'rows-per-second'='1', 'fields.ts.kind'='random', 'fields.ts.max-past'='5s', 'fields.b.kind'='random', 'fields.b.min'='0', 'fields.b.max'='10' ); CREATE TEMPORARY TABLE sink ( a INT, b BIGINT, PRIMARY KEY (a) NOT ENFORCED ) WITH ( 'connector'='print' ); INSERT INTO sink SELECT a, sum(b) FROM s1 GROUP BY a;Configure the MiniBatch size.
Go to the job details page.
On the Configuration tab, find the Parameters section, and click Edit.
In Other Configuration, set
table.exec.mini-batch.enabled: trueandtable.exec.mini-batch.allow-latency: 2s.Set
table.exec.mini-batch.sizeto-1or skip this parameter.
Start the job.
On the Status tab, the topology of the job contains the
MiniBatchAssigner,LocalGroupAggregate, andGlobalGroupAggregateoperators.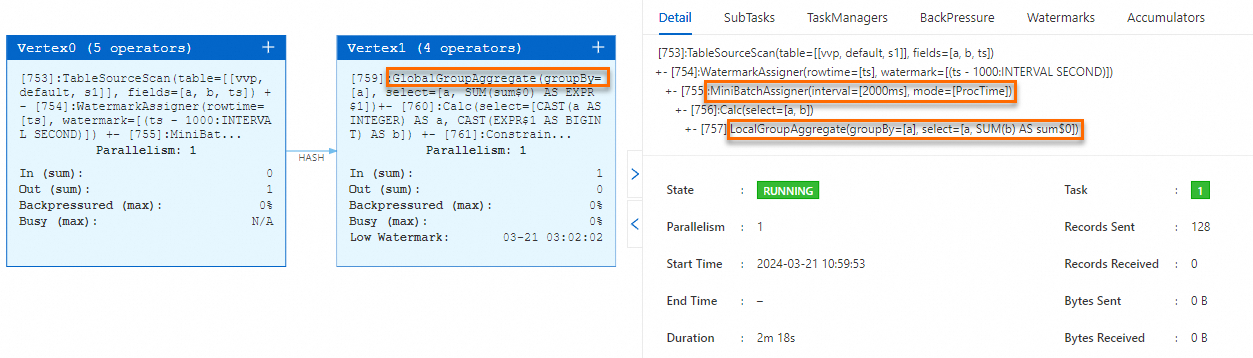
table.exec.agg.mini-batch.output-identical-enabled
This parameter specifies whether to send duplicate data to downstream operators if state TTL is enabled and aggregation results remain unchanged after data is consumed by the MinibatchGlobalAgg and MinibatchAgg operators. By default, duplicate data is not sent. But this behavior can cause the state data of downstream operators to expire because no data is received for an extended period. You can set this parameter to true for the MinibatchGlobalAgg and MinibatchAgg operators. If the change period of the aggregation result of your job is less than the specified state TTL, skip this setting. For more information, see FLINK-33936.
Usage notes
This switch takes effect only in Ververica Runtime (VVR) 8.0.8 or later.
If you change the value from
falsetotrue, the amount of data sent by theMinibatchGlobalAggandMinibatchAggoperators may increase. This may cause pressure on downstream operators.
Valid values
false(default): If the TTL of state data is enabled and the aggregation result remains unchanged after data is consumed by theMinibatchGlobalAggandMinibatchAggoperators, duplicate data is not sent to downstream operators.true: If the TTL of state data is enabled and the aggregation result remains unchanged after data is consumed by theMinibatchGlobalAggandMinibatchAggoperators, duplicate data is sent to downstream operators.
Example
Create an SQL streaming draft, copy the following test SQL statements, and then deploy the draft.
create temporary table src( a int, b string ) with ( 'connector' = 'datagen', 'rows-per-second' = '10', 'fields.a.min' = '1', 'fields.a.max' = '1', 'fields.b.length' = '3' ); create temporary table snk( a int, max_length_b bigint ) with ( 'connector' = 'blackhole' ); insert into snk select a, max(CHAR_LENGTH(b)) from src group by a;Enable MiniBatch aggregate optimization.
Go to the job details page.
On the Configuration tab, find the Parameters section and click Edit.
In Other Configuration, add
table.exec.mini-batch.enabled: trueandtable.exec.mini-batch.allow-latency: 2s.
Start the job.
On the Status tab, you can see the
MinibatchGlobalAggregateoperator. Click + on the operator to verify theGlobalGroupAggregateoperator has not sent data to downstream operators if the aggregation result remains unchanged.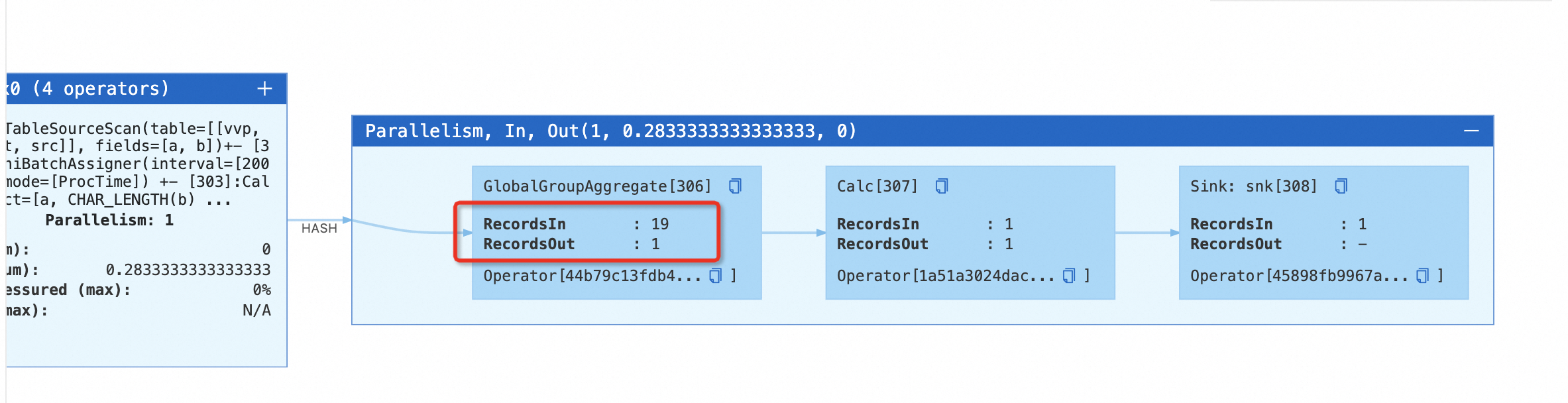
Stop the job. On the Configuration tab, find the Parameters section, and click Edit. In Other Configuration, add
table.exec.agg.mini-batch.output-identical-enabled: true.Start the job.
On the Status tab, you can see the
MinibatchGlobalAggregateoperator. Click + on the operator to check that theGlobalGroupAggregateoperator sends data to downstream operators if the aggregation result remains unchanged.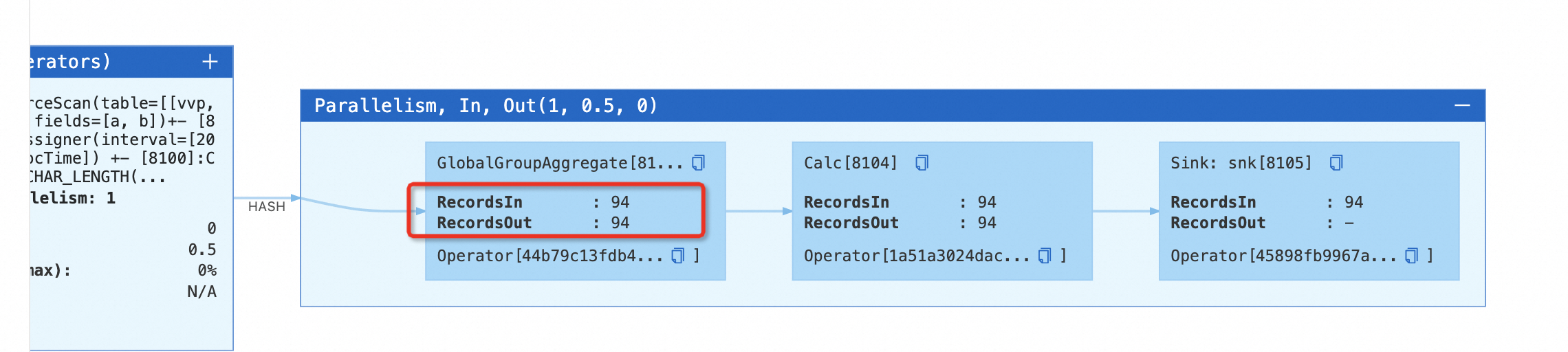
table.exec.async-lookup.key-ordered-enabled
In use cases involving lookup joins, you can enable the asynchronous mode to increase throughput. The following table describes the data ordering of asynchronous I/O operations based on the setting of the table.exec.async-lookup.output-mode parameter in lookup joins and whether an input stream is an update stream.
| Update stream | Non-update stream |
ORDERED | Ordered mode | Ordered mode |
ALLOW_UNORDERED | Ordered mode | Unordered mode |
If table.exec.async-lookup.output-mode is set to ALLOW_UNORDERED for an update stream, data correctness is ensured through the ordered mode but the throughput reduces. To resolve this issue, the table.exec.async-lookup.key-ordered-enabled parameter is introduced to ensure both the data correctness of update streams and the throughput of asynchronous I/O operations. Messages with the same update key (regarded as the primary key of the change log) in a stream are processed based on the order in which the messages enter an operator.
Ordered mode: In this mode, the order of streams remains unchanged. The order in which result messages are sent is the same as the order in which asynchronous requests are triggered (the order in which messages enter an operator).
Unordered mode: In this mode, result messages are sent as soon as the asynchronous requests are completed. The order of the messages in streams is changed after the messages are processed by the asynchronous I/O operator. For more information, see Async I/O | Apache Flink.
Scenarios
The number of messages with the same update key in a stream is small over a period of time. For example, the update key is regarded as the primary key and the data with the same primary key is not frequently updated. In addition, the processing order based on the update key is required when dimension tables are joined. In this case, you can perform optimization by specifying the table.exec.async-lookup.key-ordered-enabled parameter. This can ensure the data processing order based on the update key.
In a Change Data Capture (CDC) stream that contains a primary key, dimension tables are joined to generate a wide table for data writing to the sink. The primary key of the sink is consistent with the primary key of the source. In addition, the join key of the JOIN operation on the dimension tables is inconsistent with the primary key. The join key is considered as the primary key. In this case, you can perform optimization by specifying the table.exec.async-lookup.key-ordered-enabled parameter. This allows the system to shuffle data based on the CDC primary key, which is regarded as the update key. You can also enable the SHUFFLE_HASH join policy to optimize this scenario. In high-concurrency scenarios, compared with this method, optimization by specifying the table.exec.async-lookup.key-ordered-enabled parameter can prevent the generation of the SinkMaterializer operator before data is written to the sink. This prevents potential performance issues caused by the operator, especially the issue that a large amount of state data is generated during the long-term running of the operator. For more information about the SinkUpsertMaterializer operator, see Usage notes.
The join key of the JOIN operation on dimension tables is inconsistent with the primary key. The join key of the dimension tables is regarded as the primary key and a rank operator is available after the JOIN operation is performed. In this case, optimization by specifying the table.exec.async-lookup.key-ordered-enabled parameter allows the system to shuffle data based on the CDC primary key, which is regarded as the update key. You can also enable the SHUFFLE_HASH join policy to optimize this scenario. Compared with this method, optimization by specifying the table.exec.async-lookup.key-ordered-enabled parameter can prevent UpdateFastRank from degrading into RetractRank. For more information about how to change RetractRank to UpdateFastRank, see TopN practices.
Usage notes
If no update key is available in a stream, the entire row of data is used as the key.
The throughput decreases when the same update key is frequently updated in a short period of time. This is because the data with the same update key is processed in a strict order.
Compared with JOIN operations on dimension tables in asynchronous mode before optimization, the Key-Ordered mode provides Keyed State. If you enable or disable the Key-Ordered mode, the state data compatibility is affected.
The optimization takes effect only when you add the
table.exec.async-lookup.output-mode='ALLOW_UNORDERED'andtable.exec.async-lookup.key-ordered-enabled='true'configurations to the JOIN operation on a dimension table in VVR 8.0.10 or later and the input stream is an update stream.
Valid values
false(default): disables the Key-Ordered mode.true: enables the Key-Ordered mode.
Example
Copy and paste the following code to a streaming draft and deploy it:
create TEMPORARY table bid_source( auction BIGINT, bidder BIGINT, price BIGINT, channel VARCHAR, url VARCHAR, dateTime TIMESTAMP(3), extra VARCHAR, proc_time as proctime(), WATERMARK FOR dateTime AS dateTime - INTERVAL '4' SECOND ) with ( 'connector' = 'kafka', -- A non-insert-only stream connector. 'topic' = 'user_behavior', 'properties.bootstrap.servers' = 'localhost:9092', 'properties.group.id' = 'testGroup', 'scan.startup.mode' = 'earliest-offset', 'format' = 'csv' ); CREATE TEMPORARY TABLE users ( user_id STRING PRIMARY KEY NOT ENFORCED, -- Define the primary key. user_name VARCHAR(255) NOT NULL, age INT NOT NULL ) WITH ( 'connector' = 'hologres', -- The connector that supports the asynchronous lookup feature. 'async' = 'true', 'dbname' = 'holo db name', -- The name of the Hologres database. 'tablename' = 'schema_name.table_name', -- The name of the Hologres table that is used to receive data. 'username' = 'access id', -- The AccessKey ID of your Alibaba Cloud account. 'password' = 'access key', -- The AccessKey secret of your Alibaba Cloud account. 'endpoint' = 'holo vpc endpoint', -- The virtual private cloud (VPC) endpoint of your Hologres instance. ); CREATE TEMPORARY TABLE bh ( auction BIGINT, age int ) WITH ( 'connector' = 'blackhole' ); insert into bh SELECT bid_source.auction, u.age FROM bid_source JOIN users FOR SYSTEM_TIME AS OF bid_source.proc_time AS u ON bid_source.channel = u.user_id;Go to the job details page. On the Configuration tab, find the Parameters section, and click Edit. In Other Configuration, add
table.exec.async-lookup.output-mode='ALLOW_UNORDERED'andtable.exec.async-lookup.key-ordered-enabled='true'.Start the job.
On the Status tab, you can view KEY_ORDERED:true in the async attribute of the job.
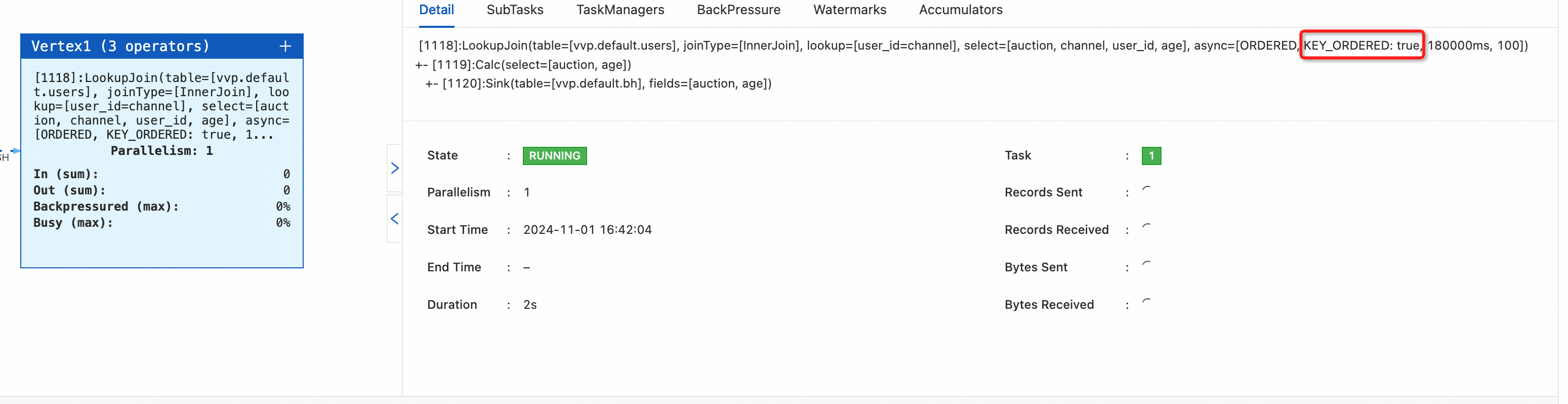
table.optimizer.window-join-enabled
This parameter controls whether to enable window joins. When it is enabled, Flink optimizes the execution plan based on the window join approach. For small windows, this can reduce state size and improve performance. Additionally, unlike regular joins, enabling window join can avoid sending update messages to downstream operators. This suits use cases that require joins over small windows.
Window joins vs. regular joins
Window joins have additional syntax limitations. Additionally, they don't support update streams.
Window joins typically have higher latency. The actual latency depends on the window size and how fast watermarks advance.
After you enable event-time window joins, late data is discarded. Regular joins don't discard late data.
After enabling or disabling window joins, you cannot recover from existing checkpoints. This is because the underlying state structures of window joins and regular joins are incompatible.
Valid values
false(default value): Window join statements are transformed into regular joins for execution.true: Corresponding statements are transformed into window joins for execution.
Example
Create an SQL streaming draft and run the following code. We directly set
table.optimizer.window-join-enabledtotruevia theSETstatement:SET 'table.optimizer.window-join-enabled' = 'true'; CREATE TEMPORARY TABLE LeftTable ( id VARCHAR, row_time TIMESTAMP_LTZ(3), num INT, WATERMARK FOR row_time as row_time - INTERVAL '5' SECONDS ) WITH ( 'connector'='datagen' ); CREATE TEMPORARY TABLE RightTable ( id VARCHAR, row_time TIMESTAMP_LTZ(3), num INT, WATERMARK FOR row_time as row_time - INTERVAL '10' SECONDS ) WITH ( 'connector'='datagen' ); EXPLAIN SELECT L.num as L_Num, L.id as L_Id, R.num as R_Num, R.id as R_Id, COALESCE(L.window_start, R.window_start) as window_start, COALESCE(L.window_end, R.window_end) as window_end FROM ( SELECT * FROM TABLE(TUMBLE(TABLE LeftTable, DESCRIPTOR(row_time), INTERVAL '5' MINUTES)) ) L JOIN ( SELECT * FROM TABLE(TUMBLE(TABLE RightTable, DESCRIPTOR(row_time), INTERVAL '5' MINUTES)) ) R ON L.num = R.num AND L.window_start = R.window_start AND L.window_end = R.window_end;You can see a
WindowJoinoperator in the optimized execution plan.== Optimized Execution Plan == Calc(select=[num AS L_Num, id AS L_Id, num0 AS R_Num, id0 AS R_Id, CASE(window_start IS NOT NULL, window_start, window_start0) AS window_start, CASE(window_end IS NOT NULL, window_end, window_end0) AS window_end]) +- WindowJoin(leftWindow=[TUMBLE(win_start=[window_start], win_end=[window_end], size=[5 min])], rightWindow=[TUMBLE(win_start=[window_start], win_end=[window_end], size=[5 min])], joinType=[InnerJoin], where=[(num = num0)], select=[id, num, window_start, window_end, id0, num0, window_start0, window_end0]) :- Exchange(distribution=[hash[num]]) : +- Calc(select=[id, num, window_start, window_end]) : +- WindowTableFunction(window=[TUMBLE(time_col=[row_time], size=[5 min])]) : +- WatermarkAssigner(rowtime=[row_time], watermark=[(row_time - 5000:INTERVAL SECOND)]) : +- TableSourceScan(table=[[vvp, default, LeftTable]], fields=[id, row_time, num]) +- Exchange(distribution=[hash[num]]) +- Calc(select=[id, num, window_start, window_end]) +- WindowTableFunction(window=[TUMBLE(time_col=[row_time], size=[5 min])]) +- WatermarkAssigner(rowtime=[row_time], watermark=[(row_time - 10000:INTERVAL SECOND)]) +- TableSourceScan(table=[[vvp, default, RightTable]], fields=[id, row_time, num])Change the value of
table.optimizer.window-join-enabledin theSETstatement tofalse, and run the code:-- set to 'false' or remove this setting clause SET 'table.optimizer.window-join-enabled' = 'false'; CREATE TEMPORARY TABLE LeftTable ( id VARCHAR, row_time TIMESTAMP_LTZ(3), num INT, WATERMARK FOR row_time as row_time - INTERVAL '5' SECONDS ) WITH ( 'connector'='datagen' ); CREATE TEMPORARY TABLE RightTable ( id VARCHAR, row_time TIMESTAMP_LTZ(3), num INT, WATERMARK FOR row_time as row_time - INTERVAL '10' SECONDS ) WITH ( 'connector'='datagen' ); EXPLAIN SELECT L.num as L_Num, L.id as L_Id, R.num as R_Num, R.id as R_Id, COALESCE(L.window_start, R.window_start) as window_start, COALESCE(L.window_end, R.window_end) as window_end FROM ( SELECT * FROM TABLE(TUMBLE(TABLE LeftTable, DESCRIPTOR(row_time), INTERVAL '5' MINUTES)) ) L JOIN ( SELECT * FROM TABLE(TUMBLE(TABLE RightTable, DESCRIPTOR(row_time), INTERVAL '5' MINUTES)) ) R ON L.num = R.num AND L.window_start = R.window_start AND L.window_end = R.window_end;A regular
Joinoperator has replaced theWindowJoinoperator:== Optimized Execution Plan == Calc(select=[num AS L_Num, id AS L_Id, num0 AS R_Num, id0 AS R_Id, CASE(window_start IS NOT NULL, window_start, window_start0) AS window_start, CASE(window_end IS NOT NULL, window_end, window_end0) AS window_end]) +- Join(joinType=[InnerJoin], where=[((num = num0) AND (window_start = window_start0) AND (window_end = window_end0))], select=[id, num, window_start, window_end, id0, num0, window_start0, window_end0], leftInputSpec=[NoUniqueKey], rightInputSpec=[NoUniqueKey]) :- Exchange(distribution=[hash[num, window_start, window_end]]) : +- Calc(select=[id, num, window_start, window_end]) : +- WindowTableFunction(window=[TUMBLE(time_col=[row_time], size=[5 min])]) : +- WatermarkAssigner(rowtime=[row_time], watermark=[(row_time - 5000:INTERVAL SECOND)]) : +- TableSourceScan(table=[[vvp, default, LeftTable]], fields=[id, row_time, num]) +- Exchange(distribution=[hash[num, window_start, window_end]]) +- Calc(select=[id, num, window_start, window_end]) +- WindowTableFunction(window=[TUMBLE(time_col=[row_time], size=[5 min])]) +- WatermarkAssigner(rowtime=[row_time], watermark=[(row_time - 10000:INTERVAL SECOND)]) +- TableSourceScan(table=[[vvp, default, RightTable]], fields=[id, row_time, num])