If you use Flink SQL for real-time data processing, out-of-order changelog events may affect data accuracy. This topic describes how the changelog mechanism works in Flink SQL, what causes out-of-order changelog events, and how to handle these events.
Changelog in Flink SQL
Background information
The binary log (binlog) in relational databases, such as MySQL, records all modification operations within a database, including INSERT, UPDATE, and DELETE operations. Similarly, the changelog in Flink SQL records all data changes to facilitate incremental data processing.
In MySQL, you can use the binlog for data backup, recovery, synchronization, and replication. For example, you can read and parse the operation records in the binlog to perform incremental data synchronization and replication. Change data capture (CDC) is a commonly used technology for data synchronization. CDC tools can monitor data changes in a database and convert the changes into event streams to facilitate real-time processing. You can use CDC tools to send data changes in a relational database to a data warehouse or other systems to conduct real-time analysis and reporting. Common CDC tools include Debezium and Maxwell. Apache Flink adds CDC support to address the FLINK-15331 request. This allows you to integrate CDC data from external systems to implement real-time data synchronization and analysis.
Changelog event generation and processing
As mentioned in the "Background information" section of this topic, changelog events can be generated by external sources, such as a binlog file and a CDC tool. Changelog events can also be generated by internal operations of Flink SQL. A changelog stream that contains only INSERT events is called an append stream or a non-update stream. A changelog stream that contains other types of events, such as UPDATE events, is called an update stream. Some operations in Flink, such as group aggregation and deduplication, can generate UPDATE events. In most cases, operators that generate UPDATE events maintain a state and are referred to as stateful operators. Take note that not all stateful operators can consume update streams. For example, the operators of over aggregation and interval join do not support update streams as inputs.
For information about the supported query operations in Realtime Compute for Apache Flink that uses Ververica Runtime (VVR) 6.0 or later, the corresponding runtime operators, and the support for consuming and producing update streams, see Query execution.
Changelog event types
Apache Flink introduced the retraction mechanism as proposed in the FLINK-6047 request to implement the incremental update algorithm for streaming SQL operators. In this mechanism, events are categorized as INSERT or DELETE. This categorization applies to data sources that support only INSERT events. Then, Apache Flink refactored the changelog event system to address the FLINK-16987 request. The refactored system uses the following changelog event types to facilitate integration with the CDC ecosystem:
/**
* A kind of row in a Changelog.
*/
@PublicEvolving
public enum RowKind {
/**
* Insertion operation.
*/
INSERT,
/**
* Previous content of an updated row.
*/
UPDATE_BEFORE,
/**
* New content of an updated row.
*/
UPDATE_AFTER,
/**
* Deletion operation.
*/
DELETE
}As shown in the preceding code, UPDATE_BEFORE and UPDATE_AFTER are separate event types. Apache Flink does not combine these event types into a composite UPDATE event type because of the following reasons:
Events of the UPDATE_BEFORE and UPDATE_AFTER types have the same structure. The only difference is the RowKind property. This makes serialization easier. In contrast, if a composite UPDATE event type is used, the events are heterogeneous or INSERT and DELETE events are aligned with UPDATE events. For example, INSERT events contain only UPDATE_AFTER events and DELETE events contain only UPDATE_BEFORE events.
Data shuffling operations, such as join and aggregation, frequently occur in distributed environments. This requires composite UPDATE events to be split into separate DELETE and INSERT events in specific scenarios, as shown in the following example.
Example
In this sample scenario, composite UPDATE events are split into DELETE and INSERT events. The following SQL code is also used to demonstrate the issue of out-of-order changelog events and the corresponding solution, which are described in subsequent sections of this topic.
-- CDC source tables: s1 & s2
CREATE TEMPORARY TABLE s1 (
id BIGINT,
level BIGINT,
PRIMARY KEY(id) NOT ENFORCED
)WITH (...);
CREATE TEMPORARY TABLE s2 (
id BIGINT,
attr VARCHAR,
PRIMARY KEY(id) NOT ENFORCED
)WITH (...);
-- sink table: t1
CREATE TEMPORARY TABLE t1 (
id BIGINT,
level BIGINT,
attr VARCHAR,
PRIMARY KEY(id) NOT ENFORCED
)WITH (...);
-- join s1 and s2 and insert the result into t1
INSERT INTO t1
SELECT
s1.*, s2.attr
FROM s1 JOIN s2
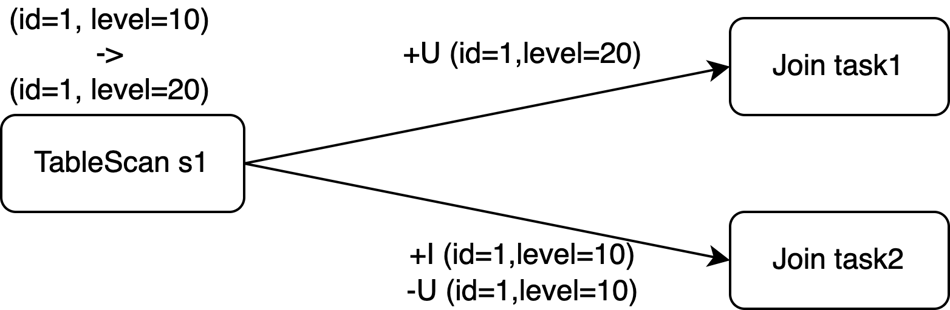
ON s1.level = s2.id;In the changelog stream of table s1, if the (id=1, level=10) record is inserted at time t0 and updated to (id=1, level=20) at time t1, three separate events are generated. The following table describes these events.
s1 | Event type |
+I (id=1, level=10) | INSERT |
-U (id=1, level=10) | UPDATE_BEFORE |
+U (id=1, level=20) | UPDATE_AFTER |
The primary key of table s1 is id. However, the join operation requires data to be shuffled based on the level column, as specified in the ON clause.
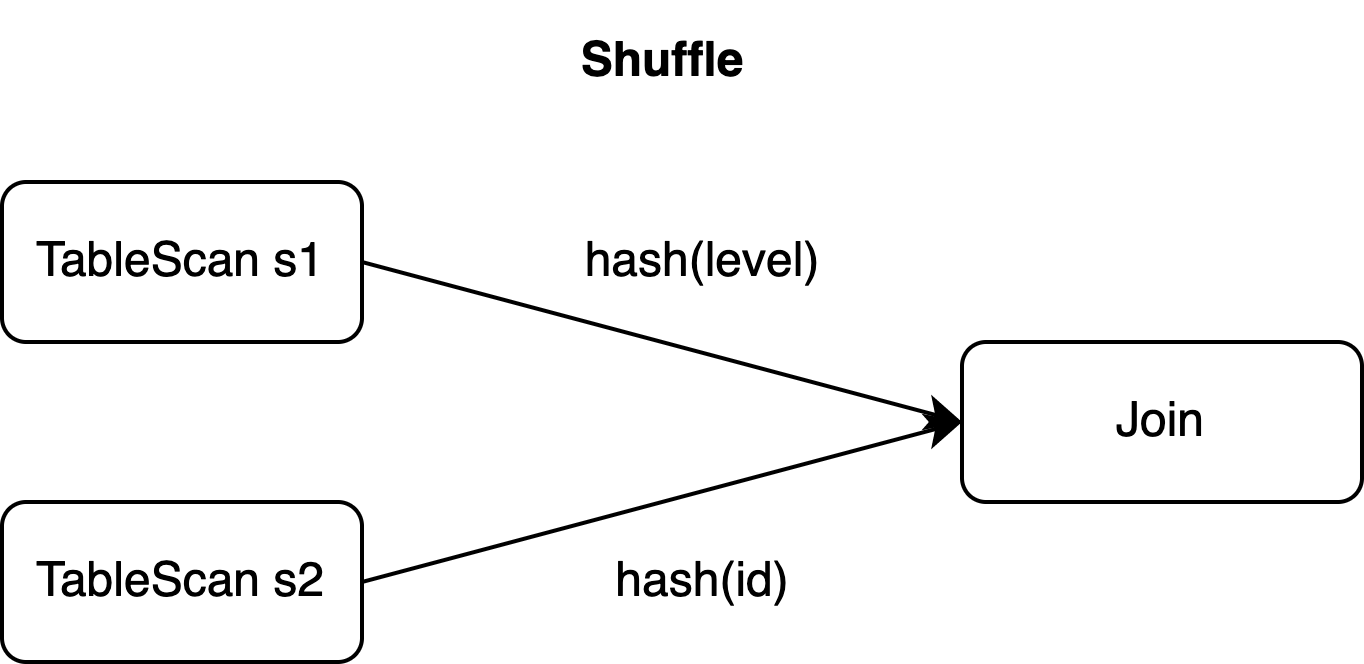
If the Join operator has a parallelism of 2, the preceding three events may be sent to two tasks. In this case, even if the composite UPDATE event type is used, the events still need to be split during shuffling to ensure parallel processing.
Out-of-order changelog events
Causes
This section uses the preceding example and adds the following conditions: The Join operator receives +I (id=10, attr='a1') and +I (id=20, attr='b1') events from table s2, and then receives three changelog events from table s1. In a distributed environment, the order in which the preceding changelog events arrive at the downstream Sink operator may vary because the join operation is performed in parallel by two tasks. The following table describes the possible event orders.
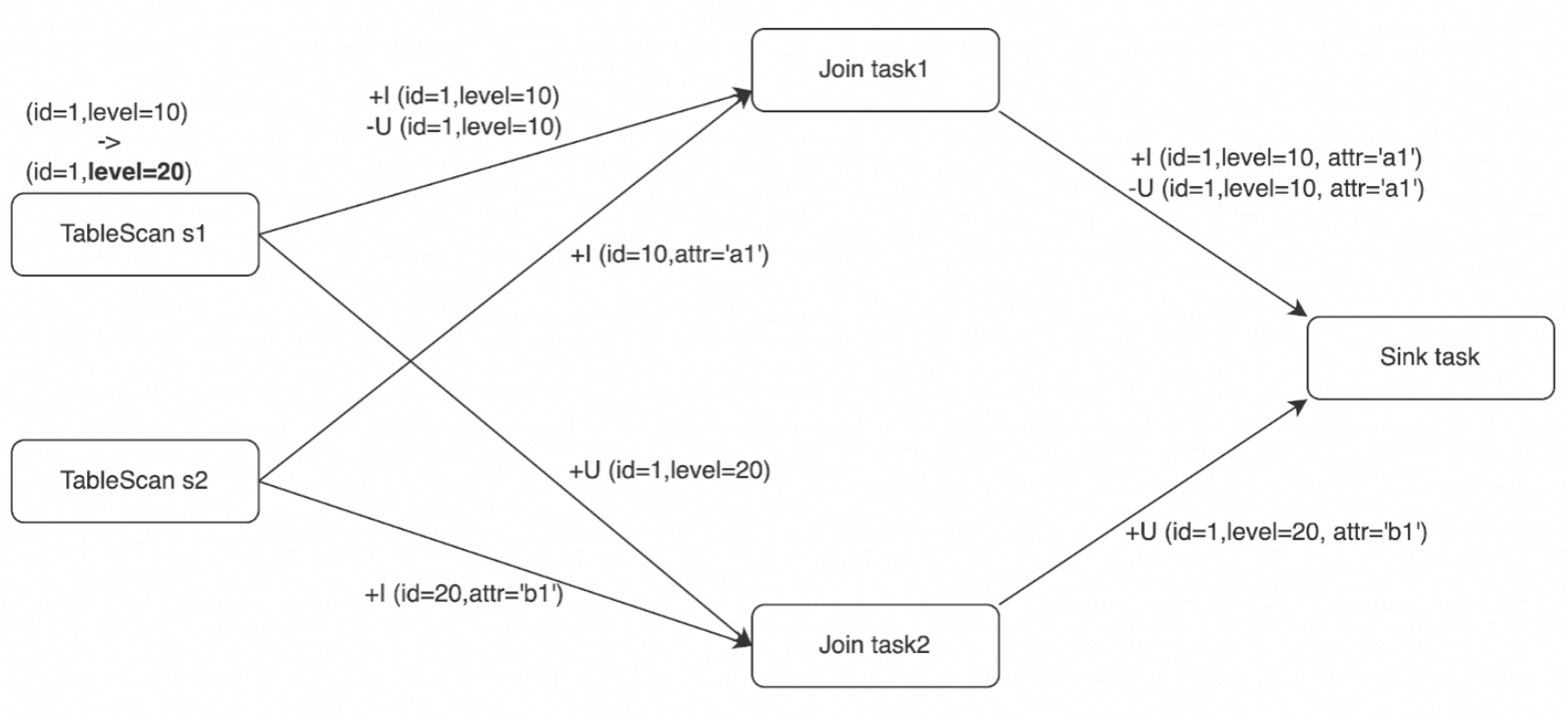
Case 1 | Case 2 | Case 3 |
+I (id=1, level=10, attr='a1') -U (id=1, level=10, attr='a1') +U (id=1, level=20, attr='b1') | +U (id=1, level=20, attr='b1') +I (id=1, level=10, attr='a1') -U (id=1, level=10, attr='a1') | +I (id=1, level=10, attr='a1') +U (id=1, level=20, attr='b1') -U (id=1, level=10, attr='a1') |
The order of events in Case 1 is the same as that in sequential processing. In Case 2 and Case 3, the changelog events arrive out of order at the downstream operator, which may lead to incorrect results in Flink SQL. In this example, the primary key of the sink table is id. If the external storage performs an upsert operation in Case 2 and Case 3, the record whose id is 1 is incorrectly deleted from the external storage. However, the expected result is that a record (id=1, level=20, attr='b1') exists.
Use SinkUpsertMaterializer as a solution
In this example, the Join operator produces an update stream because the output contains INSERT events (+I) and UPDATE events (-U and +U). If the out-of-order changelog events are not properly handled, the final result may be incorrect.
Unique keys and upsert keys
Unique keys refer to one or more columns that meet the UNIQUE constraint after a SQL operation. In this example, (s1.id), (s1.id, s1.level), and (s1.id, s2.id) are all unique keys.
The changelog mechanism in Flink SQL is similar to the binlog mechanism but has a simplified implementation. Instead of recording the timestamp of each update, Flink determines the order of update events for a primary key based on the global analysis in the SQL planner. A column that maintains the sorting of a unique key is referred to as an upsert key. If upsert keys exist, the downstream operator can receive the update events in the correct order. If a shuffle operation disrupts the sorting of unique keys, upsert keys become empty. In this case, downstream operators must use algorithms, such as a counting algorithm, to ensure final consistency.
In this example, the rows in table s1 are shuffled based on the level column. As a result, the output of the Join operator contains rows that have the same s1.id value and no sorting exists on the unique key. This means that the upsert key is empty. In this case, Flink must store all input records and compare all columns to distinguish between UPDATE and INSERT operations.
In addition, the primary key of the sink table is the id column, which does not match the upsert key in the output of the Join operator. Therefore, the output rows of the Join operator must be correctly converted to the required rows in the sink table.
SinkUpsertMaterializer
As mentioned in the "Unique keys and upsert keys" section of this topic, if the Join operator produces an update stream whose upsert key does not match the primary key of the sink table, an intermediate step is required to generate changelog events based on the primary key of the sink table. Therefore, Flink introduced the SinkUpsertMaterializer operator to resolve the FLINK-20374 issue to connect the Join operator and its downstream operator.
Out-of-order changelog events, such as the events described in the "Causes" section of this topic, follow specific rules. For example, for a specific upsert key or for all columns if the upsert key is empty, the ADD events (+I and +U) occur before the corresponding RETRACT events (-D and -U). A pair of changelog events that have the same upsert key are processed by the same task even if a data shuffle occurs. This also explains why the changelog event order in this example has only three possible cases, as described in the "Causes" section of this topic.
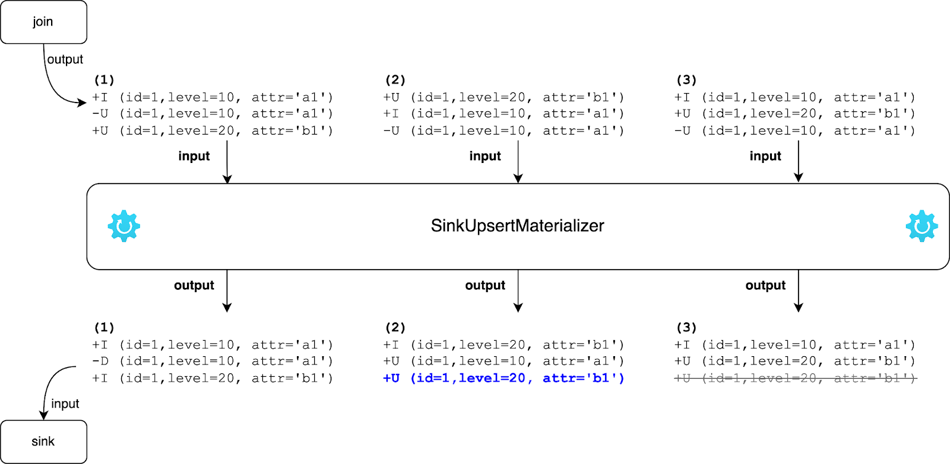
The SinkUpsertMaterializer operator is implemented based on the preceding rules. The following figure shows how the operator works. The SinkUpsertMaterializer operator maintains a list of RowData values in its state. When a row is entered, the operator checks whether the row exists in the RowData list based on the deduced upsert key or the entire row if the upsert key is empty. Then, the operator adds or updates the row in its state in the case of an ADD event, or deletes the row from its state in the case of a RETRACT event. Finally, the operator generates changelog events based on the primary key of the sink table. For more information, see the SinkUpsertMaterializer source code.
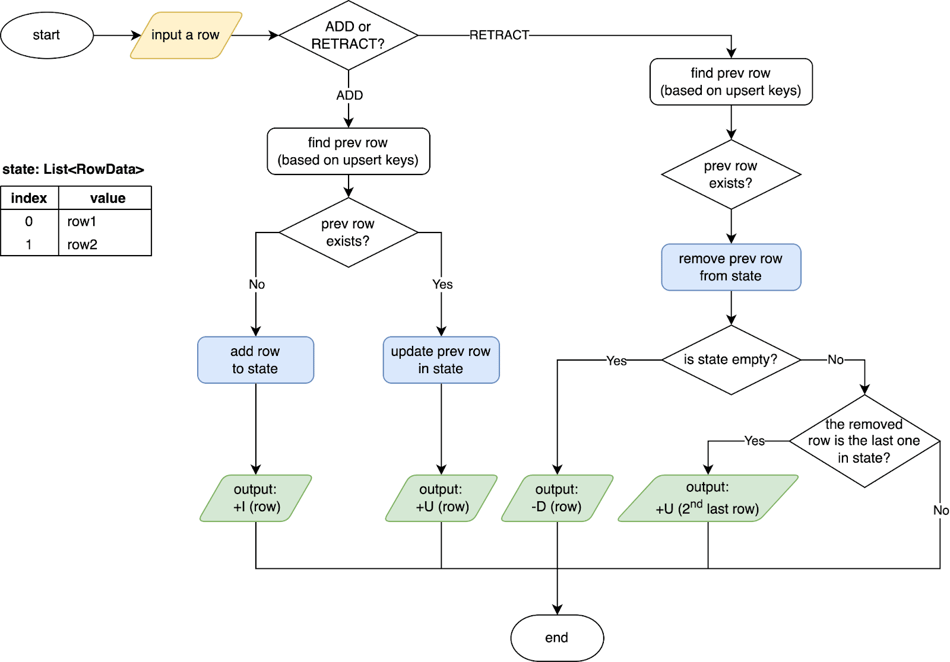
The following figure shows how the SinkUpsertMaterializer operator transforms the output changelog events from the Join operator to the input changelog events of the sink table in this example. In Case 2, the SinkUpsertMaterializer operator removes the last row from its state and generates an UPDATE event for the second-to-last row when the -U (id=1, level=10, attr='a1') event arrives. In Case 3, the SinkUpsertMaterializer operator passes the +U (id=1, level=20, attr='b1') event downstream when the event arrives. Then, the operator removes the corresponding row from its state without generating an event when the -U (id=1, level=10, attr='a1') event arrives. This way, the SinkUpsertMaterializer operator ensures that the final result is as expected in Case 2 and Case 3, which is (id=1, level=20, attr='b1').
Common use cases
The SinkUpsertMaterializer operator is used in the following scenarios:
The sink table has a primary key but the data written to the table does not meet the UNIQUE constraint. Possible causes include but are not limited to the following operations:
Define a primary key for the sink table when the source table does not have a primary key.
Fail to include the primary key column of the source table when data is inserted into the sink table, or use non-primary-key columns of the source table as the primary key of the sink table.
The data type used by the primary key column of the source table becomes less precise after conversion or group aggregation. For example, the column is converted from the BIGINT type to the INT type.
Perform data transformation on the primary key column of the source table or the unique keys generated by group aggregation. For example, concatenate or merge multiple primary keys into a single column.
CREATE TABLE students ( student_id BIGINT NOT NULL, student_name STRING NOT NULL, course_id BIGINT NOT NULL, score DOUBLE NOT NULL, PRIMARY KEY(student_id) NOT ENFORCED ) WITH (...); CREATE TABLE performance_report ( student_info STRING NOT NULL PRIMARY KEY NOT ENFORCED, avg_score DOUBLE NOT NULL ) WITH (...); CREATE TEMPORARY VIEW v AS SELECT student_id, student_name, AVG(score) AS avg_score FROM students GROUP BY student_id, student_name; -- The concatenated results no longer meet the UNIQUE constraint but are used as the primary keys of the sink table. INSERT INTO performance_report SELECT CONCAT('id:', student_id, ',name:', student_name) AS student_info, avg_score FROM v;
The original sorting of the input data is disrupted before being written to the sink table, as shown in the example in this topic. The join operation performed on tables s1 and s2 is not based on the primary key of s1, but the sink table has the same primary key as table s1. This leads to disruption in data sorting.
The
table.exec.sink.upsert-materializeparameter is set to'force'. For more information, see the "Parameter configuration" section of this topic.
Usage notes
The SinkUpsertMaterializer operator maintains a list of RowData values in its state. This may increase the state size and require extra I/O overhead to access state data, which affects the throughput. We recommend that you avoid using the SinkUpsertMaterializer operator.
Parameter configuration
Use the table.exec.sink.upsert-materialize parameter to configure the SinkUpsertMaterializer operator. Valid values:
auto (default): Flink infers whether the changelog events are out of order and adds the SinkUpsertMaterializer operator if necessary.
none: Do not use the SinkUpsertMaterializer operator.
force: Always use the SinkUpsertMaterializer operator. In this case, the operator is added even if no primary key is specified for the sink table. This ensures data materialization.
Take note that if you set the parameter to auto, the addition of the SinkUpsertMaterializer operator does not necessarily mean that the events are out of order. For example, if you use the GROUPING SETS clause together with a COALESCE function to convert null values, the SQL planner may fail to determine whether the generated upsert key matches the primary key of the sink table. In this case, Flink adds the SinkUpsertMaterializer operator to ensure the correctness of the result. However, if the final result is correct without the SinkUpsertMaterializer operator, we recommend that you set the table.exec.sink.upsert-materialize parameter to none.
Avoid using SinkUpsertMaterializer
To avoid using the SinkUpsertMaterializer operator, take note of the following items:
Make sure that the partition key used for operations such as deduplication and group aggregation is the same as the primary key of the sink table.
To prevent out-of-order data when a single parallelism fits your dataset, set parallelism to 1. In this scenario, disable the
SinkUpsertMaterializeroperator by settingtable.exec.sink.upsert-materializetonone.If an operator chain is created for the Sink operator and the upstream operator, such as the deduplication or group aggregation operator, and if no data accuracy issues occur when you use VVR versions earlier than 6.0, you can migrate the deployment to use VVR 6.0 or later. Make sure that you set the table.exec.sink.upsert-materialize parameter to none and retain other configurations. For more information about how to migrate a deployment, see Upgrade the engine version of deployments.
If you need to use the SinkUpsertMaterializer operator, take note of the following items:
Do not add columns generated by non-deterministic functions, such as CURRENT_TIMESTAMP and NOW, when you write data to the sink table. This prevents abnormal inflation in the state of the SinkUpsertMaterializer operator when upsert keys are unavailable.
If the state of the SinkUpsertMaterializer operator is large and affects performance, increase the deployment parallelism. For more information, see Configure resources for a deployment.
Known issues
The SinkUpsertMaterializer operator resolves the issue of out-of-order changelog events, but may cause a continuous increase in state size due to the following reasons:
The state retention period is excessively long because no state time-to-live (TTL) is configured or the state TTL is excessively long. However, an excessively short TTL can result in unnecessary retention of dirty data in the state, as described in the FLINK-29225 issue. This issue occurs when the time interval between a DELETE event and the corresponding ADD event exceeds the configured TTL. In this case, Flink produces the following warning message in the logs:
int index = findremoveFirst(values, row); if (index == -1) { LOG.info(STATE_CLEARED_WARN_MSG); return; }We recommend that you configure the TTL based on your business requirements. For more information, see Configure a deployment. Realtime Compute for Apache Flink that uses VVR 8.0.7 or later allows you to configure different TTL values for different operators to reduce the resource consumption of large-state deployments. For more information, see Configure the parallelism, chaining strategy, and TTL of an operator.
If the upsert key cannot be deduced for the update stream received by the SinkUpsertMaterializer operator and the update stream includes non-deterministic columns, historical data cannot be deleted as expected. This results in a continuous increase in state size.
References
For information about the engine version mapping between Realtime Compute for Apache Flink and Apache Flink, see Release notes.