This topic describes how to use the reindex API to migrate data from a multi-type index to a single-type index. The multi-type index is on an Alibaba Cloud Elasticsearch V5.X cluster. The single-type index is on an Alibaba Cloud Elasticsearch V6.X cluster.
Limits
The network architecture of Alibaba Cloud Elasticsearch was adjusted in October 2020. In the new network architecture, the cross-cluster reindex operation is limited. You need to use the PrivateLink service to establish private connections between VPCs before you perform the operation. The following table provides data migration solutions in different scenarios.
Alibaba Cloud Elasticsearch clusters created before October 2020 are deployed in the original network architecture. Alibaba Cloud Elasticsearch clusters created in October 2020 or later are deployed in the new network architecture.
Scenario | Network architecture | Solution |
Migrate data between Alibaba Cloud Elasticsearch clusters | Both clusters are deployed in the original network architecture. | reindex API. For more information, see Use the reindex API to migrate data between Alibaba Cloud Elasticsearch clusters. |
One of the clusters is deployed in the original network architecture. Note The other cluster can be deployed in the original or new network architecture |
| |
Migrate data from a self-managed Elasticsearch cluster that runs on ECS instances to an Alibaba Cloud Elasticsearch cluster | The Alibaba Cloud Elasticsearch cluster is deployed in the original network architecture. | reindex API. For more information, see Use the reindex API to migrate data from a self-managed Elasticsearch cluster to an Alibaba Cloud Elasticsearch cluster. |
The Alibaba Cloud Elasticsearch cluster is deployed in the new network architecture. | reindex API. For more information, see Migrate data from a self-managed Elasticsearch cluster to an Alibaba Cloud Elasticsearch cluster deployed in the new network architecture. |
Procedure
Create an Elasticsearch V5.X cluster, an Elasticsearch V6.X cluster, and a Logstash cluster in the same virtual private cloud (VPC).
The Elasticsearch clusters are used to store index data.
The Logstash cluster is used to migrate processed data based on pipelines.
Step 1: Convert the multi-type index into one or more single-type indexes
Use the reindex API to convert the multi-type index on the Elasticsearch V5.X cluster into one or more single-type indexes. You can use one of the following methods to implement the conversion:
Combine types: Call the reindex API with the script condition specified to combine the types of the index.
Split the index: Call the reindex API to split the index into multiple indexes. Each of these indexes has only one type.
Step 2: Use Logstash to migrate data
Use the Logstash cluster to migrate the processed index data to the Elasticsearch V6.X cluster.
Step 3: View the data migration results
View the migrated data in the Kibana console.
Make preparations
Create an Elasticsearch V5.5.3 cluster and an Elasticsearch V6.7.0 cluster. Then, create a multi-type index on the Elasticsearch V5.5.3 cluster and insert data into the index.
For more information about how to create an Elasticsearch cluster, see Create an Alibaba Cloud Elasticsearch cluster.
Create a Logstash cluster in the VPC where the Elasticsearch clusters reside.
For more information, see Step 1: Create a Logstash cluster.
Step 1: Convert the multi-type index into one or more single-type indexes
In the following steps, the types of the index are combined to convert the index into one single-type index.
Enable the Auto Indexing feature for the Elasticsearch V5.5.3 cluster.
Log on to the Elasticsearch console.
In the left-side navigation pane, click Elasticsearch Clusters.
In the top navigation bar, select a resource group and a region.
On the Elasticsearch Clusters page, find the Elasticsearch V5.5.3 cluster and click its ID.
In the left-side navigation pane of the page that appears, click Cluster Configuration.
Click Modify Configuration on the right side of YML File Configuration.
In the YML File Configuration panel, set Auto Indexing to Enable.
 Warning
WarningThis operation will restart the cluster. Therefore, before you change the value of Auto Indexing, make sure that the restart does not affect your services.
Select This operation will restart the cluster. Continue? and click OK.
Log on to the Kibana console of the Elasticsearch cluster.
For more information, see Log on to the Kibana console.
In the left-side navigation pane, click Dev Tools.
On the Console tab of the page that appears, run the following command to combine the types of the index:
POST _reindex { "source": { "index": "twitter" }, "dest": { "index": "new1" }, "script": { "inline": """ ctx._id = ctx._type + "-" + ctx._id; ctx._source.type = ctx._type; ctx._type = "doc"; """, "lang": "painless" } }In this example, a custom type field is added for the new1 index. ctx._source.type specifies the custom type field, and this field is set to the value of the original _type parameter. In addition, _id of the new1 index includes _type-_id. This prevents documents of different types from having the same ID.
Run the
GET new1/_mappingcommand to view the mapping after the combination.Run the following command to view data in the new index with types combined:
GET new1/_search { "query":{ "match_all":{ } } }
In the following steps, the multi-type index is split into multiple single-type indexes.
On the Console tab, run the following command to split the multi-type index into multiple single-type indexes:
POST _reindex { "source": { "index": "twitter", "type": "tweet", "size": 10000 }, "dest": { "index": "twitter_tweet" } } POST _reindex { "source": { "index": "twitter", "type": "user", "size": 10000 }, "dest": { "index": "twitter_user" } }In this example, the twitter index is split into the twitter_tweet and twitter_user indexes based on types.
Run the following command to view data in the new indexes:
GET twitter_tweet/_search { "query":{ "match_all":{ } } }GET twitter_user/_search { "query":{ "match_all":{ } } }
Step 2: Use Logstash to migrate data
Go to the Logstash Clusters page of the Alibaba Cloud Elasticsearch console.
Navigate to the desired cluster.
In the top navigation bar, select the region where the cluster resides.
On the Logstash Clusters page, find the cluster and click its ID.
In the left-side navigation pane of the page that appears, click Pipelines.
On the Pipelines page, click Create Pipeline.
In the Create wizard, enter a pipeline ID and configure the pipeline.
In this example, the following configurations are used for the pipeline:
input { elasticsearch { hosts => ["http://es-cn-0pp1f1y5g000h****.elasticsearch.aliyuncs.com:9200"] user => "elastic" index => "*" password => "your_password" docinfo => true } } filter { } output { elasticsearch { hosts => ["http://es-cn-mp91cbxsm000c****.elasticsearch.aliyuncs.com:9200"] user => "elastic" password => "your_password" index => "test" } }For more information, see Logstash configuration files.
Click Next to configure pipeline parameters.
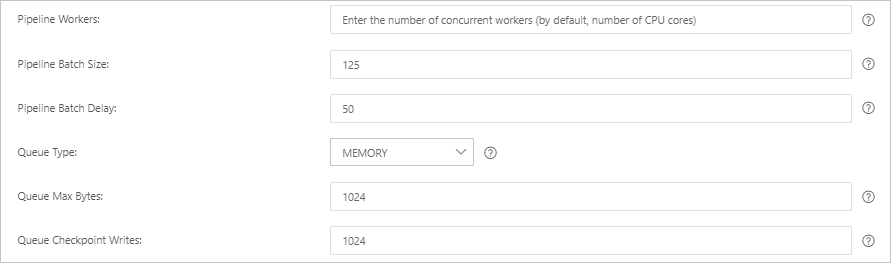
Parameter
Description
Pipeline Workers
The number of worker threads that run the filter and output plug-ins of the pipeline in parallel. If a backlog of events exists or some CPU resources are not used, we recommend that you increase the number of threads to maximize CPU utilization. The default value of this parameter is the number of vCPUs.
Pipeline Batch Size
The maximum number of events that a single worker thread can collect from input plug-ins before it attempts to run filter and output plug-ins. If you set this parameter to a large value, a single worker thread can collect more events but consumes larger memory. If you want to make sure that the worker thread has sufficient memory to collect more events, specify the LS_HEAP_SIZE variable to increase the Java virtual machine (JVM) heap size. Default value: 125.
Pipeline Batch Delay
The wait time for an event. This time occurs before you assign a small batch to a pipeline worker thread and after you create batch tasks for pipeline events. Default value: 50. Unit: milliseconds.
Queue Type
The internal queue model for buffering events. Valid values:
MEMORY: traditional memory-based queue. This is the default value.
PERSISTED: disk-based ACKed queue, which is a persistent queue.
Queue Max Bytes
The value must be less than the total capacity of your disk. Default value: 1024. Unit: MB.
Queue Checkpoint Writes
The maximum number of events that are written before a checkpoint is enforced when persistent queues are enabled. The value 0 indicates no limit. Default value: 1024.
WarningAfter you configure the parameters, you must save the settings and deploy the pipeline. This triggers a restart of the Logstash cluster. Before you can proceed, make sure that the restart does not affect your business.
Click Save or Save and Deploy.
Save: After you click this button, the system stores the pipeline settings and triggers a cluster change. However, the settings do not take effect. After you click Save, the Pipelines page appears. On the Pipelines page, find the created pipeline and click Deploy Now in the Actions column. Then, the system restarts the Logstash cluster to make the settings take effect.
Save and Deploy: After you click this button, the system restarts the Logstash cluster to make the settings take effect.
Step 3: View the data migration results
Log on to the Kibana console of the Elasticsearch V6.7.0 cluster.
For more information, see Log on to the Kibana console.
In the left-side navigation pane, click Dev Tools.
On the Console tab of the page that appears, run the following command to view the index that stores the migrated data:
GET _cat/indices?v