This topic describes how to use a text embedding model to perform an in-depth semantic analysis on user queries. This helps resolve the limitations of traditional keyword-based matches and accurately extract highly correlative content from large amounts of data. This topic also describes how to use a question answering model to perform fine-grained interpretation on correlative text and accurately provide answers to questions related to the text. The combination of text embedding and question answering models can be used for intelligent search engines and in scenarios such as personalized recommendation to improve the accuracy of information retrieval and question answering.
Preparations
Upload models
In this example, the question answering model luhua/chinese_pretrain_mrc_macbert_large and the text embedding model thenlper/gte-large-zh in a Hugging Face library are used.
Access to Hugging Face over a network in the Chinese mainland is slow. In this example, the models are uploaded to Alibaba Cloud Elasticsearch in offline mode.
Download the models.
Upload the models to an Elastic Compute Service (ECS) instance.
Create a folder in the root directory of an ECS instance and upload the models to the folder. Do not upload the models to the /root/ directory of the ECS instance. In this example, a folder named model is created.
The model files are large in size. We recommend that you use WinSCP to upload the model files. For more information, see Use WinSCP to upload or download a file (on-premises host running the Windows operating system).
Run the following commands in the ECS instance to decompress the models in the model folder:
cd /model/ tar -xzvf luhua--chinese_pretrain_mrc_macbert_large.tar.gz tar -xzvf thenlper--gte-large-zh.tar.gz cdRun the following commands in the ECS instance to upload the models to the Elasticsearch cluster:
Run the following command to upload the question answering model:
eland_import_hub_model --url 'http://es-cn-lbj3l7erv0009****.elasticsearch.aliyuncs.com:9200' --hub-model-id '/model/root/.cache/huggingface/hub/models--luhua--chinese_pretrain_mrc_macbert_large/snapshots/f2d95d06f16a3043002c9702f66c834f4e0aa944' --task-type question_answering --es-username elastic --es-password **** --es-model-id models--luhua--chinese_pretrain_mrc_macbert_large \Run the following command to upload the text embedding model:
eland_import_hub_model --url 'http://es-cn-lbj3l7erv0009****.elasticsearch.aliyuncs.com:9200' --hub-model-id '/model/root/.cache/huggingface/hub/models--thenlper--gte-large-zh/snapshots/952432e6b99137bbfd8397d5ad92f920be5f22e9' --task-type text_embedding --es-username elastic --es-password **** --es-model-id models--thenlper--gte-large-zh \
Deploy the models
Log on to the Kibana console of the Elasticsearch cluster. For more information, see Log on to the Kibana console.
Click the
 icon in the upper-left corner of the Kibana console. In the left-side navigation pane, choose Analytics > Machine Learning.
icon in the upper-left corner of the Kibana console. In the left-side navigation pane, choose Analytics > Machine Learning. In the left-side navigation pane of the page that appears, choose Model Management > Trained Models.
Optional. In the upper part of the Trained Models page, click Synchronize your jobs and trained models. In the panel that appears, click Synchronize.
On the Trained Models page, find the uploaded model and click the
 icon in the Actions column to start the model.
icon in the Actions column to start the model. 
In the dialog box that appears, configure the model and click Start.
If a message indicating that the model is started is displayed in the lower-right corner of the page, the model is deployed.
NoteIf the model cannot be started, the memory of the Elasticsearch cluster may be insufficient. You can start the model again after you upgrade the configuration of the Elasticsearch cluster. In the dialog box that prompts you about the failure, you can click View complete error message to view the failure cause.
Test the models
Click the
icon in the upper-left corner of the Kibana console. In the left-side navigation pane, choose Management > Dev Tools. Test the models.
Run the following command to test the question answering model:
POST /_ml/trained_models/models--luhua--chinese_pretrain_mrc_macbert_large/_infer { "docs":[{"text_field": "Installing multiple sets of antivirus software on your computer is unnecessary. Installing two sets of antivirus software can improve the security of your computer but has multiple disadvantages. For example, the antivirus software occupies large amounts of hard disk resources and system hardware resources such as CPU resources during real-time protection, which degrades computer performance. When the two sets of antivirus software detects viruses, the related system occupies a large amount of resources, which may affect the working capability of the system and cause false positives on components."}], "inference_config": {"question_answering": {"question": "Can I install multiple sets of antivirus software on my computer?"}} }The following result is returned, which meets expectations.
{ "inference_results": [ { "predicted_value": "Installing multiple sets of antivirus software on your computer is unnecessary." "start_offset": 0, "end_offset": 4, "prediction_probability": 0.8775923604355836 } ] }Run the following command to test the text embedding model:
POST /_ml/trained_models/models--thenlper--gte-large-zh/_infer { "docs":[{"text_field": "Installing multiple sets of antivirus software on your computer is unnecessary. Installing two sets of antivirus software can improve the security of your computer but has multiple disadvantages. For example, the antivirus software occupies large amounts of hard disk resources and system hardware resources such as CPU resources during real-time protection, which degrades computer performance. When the two sets of antivirus software detects viruses, the related system occupies a large amount of resources, which may affect the working capability of the system and cause false positives on components."}] }The result that contains the following data is returned, which meets expectations.
{ "inference_results": [ { "predicted_value": [ 1.389997959136963, -0.6398589611053467, -0.5746312737464905, -0.5629222393035889, -0.49914881587028503, 0.5277091264724731, -1.2194437980651855, 0.19847321510314941, .............. 0.6711148619651794, 1.6224931478500366, 2.0970489978790283, -0.4506820738315582, -0.298383504152298 ] } ] }
Prepare a dataset
A sample dataset is required during data indexing.
Download a sample dataset.
In this example, the extracted_data.json dataset is used.
Upload the dataset to the ECS instance. In this example, the dataset is uploaded to the /model/ directory.
Step 1: Index data
Use an ingestion pipeline to configure the models in an index to complete text conversion during data writing.
NoteYou must use models to convert existing data in the index into vectors. For more information, see Ingest documents.
PUT _ingest/pipeline/text-embedding-pipeline { "processors": [ { "inference": { "model_id": "models--thenlper--gte-large-zh", "target_field": "text_embedding", "field_map": { "context": "text_field" } } } ] } #####Configure mappings for the index and specify an ingestion pipeline. PUT question_answering { "settings": { "index": { "number_of_shards": 2, "number_of_replicas": 1, "default_pipeline": "text-embedding-pipeline" } }, "mappings": { "properties": { "text_embedding.predicted_value": { "type": "dense_vector", "dims": 1024, "index": true, "similarity": "l2_norm" }, "context": { "type": "text", "fields": { "keyword": { "type": "keyword", "ignore_above": 256 } } }, "title": { "type": "text", "fields": { "keyword": { "type": "keyword", "ignore_above": 256 } } } } } }Use a Python environment to import the prepared dataset. In this example, Python 3.10 is used.
# -*- coding:utf-8 -*- import json from pprint import pprint import os import time from elasticsearch import helpers import time from elasticsearch import Elasticsearch elastic_user="elastic" elastic_password="****" elastic_endpoint="es-cn-lbj3l7erv0009****.elasticsearch.aliyuncs.com" url = f"http://{elastic_user}:{elastic_password}@{elastic_endpoint}:9200" es = Elasticsearch(url) print(es.info()) with open('/model/extracted_data.json') as f: data_json = json.load(f) # Prepare the documents to be indexed documents = [] for doc in data_json: documents.append({ "_index": "question_answering", "_source": doc, }) # Use helpers.bulk to index helpers.bulk(es, documents) print("Done indexing documents into `question_answering` index!") time.sleep(5)
Step 2: Retrieve data in the Kibana console
Use the question "What are the use scenarios of Alibaba Cloud Elasticsearch?" as an example to perform a retrieval in the Kibana console of the Elasticsearch cluster.
Click the
icon in the upper-left corner of the Kibana console. In the left-side navigation pane, choose Management > Dev Tools. Call the inference API operation for Alibaba Cloud Machine Learning to convert documents into vector data.
Elasticsearch clusters of V8.7 or later
If you use an Elasticsearch cluster of V8.7 or later, you can use the query_vector_builder configuration object to build a query vector.
GET question_answering/_search { "_source": ["context","title"], "knn": { "field": "text_embedding.predicted_value", "k": 5, "num_candidates": 10, "query_vector_builder": { "text_embedding": { "model_id": "models--thenlper--gte-large-zh", "model_text": "What are the use scenarios of Alibaba Cloud Elasticsearch?" } } } }The following result is returned. The result shows that the first five documents are highly correlative to Elasticsearch and the first document mainly introduces Alibaba Cloud Elasticsearch.
{ "took": 30, "timed_out": false, "_shards": { "total": 2, "successful": 2, "skipped": 0, "failed": 0 }, "hits": { "total": { "value": 5, "relation": "eq" }, "max_score": 0.003581697, "hits": [ { "_index": "question_answering", "_id": "evdbaI0BU_1of7kX5_Hn", "_score": 0.003581697, "_source": { "context": "Alibaba Cloud Elasticsearch is a fully managed cloud service that is developed based on open source Elasticsearch. This service is fully compatible with the features provided by open source Elasticsearch. It is out-of-the-box and supports the pay-as-you-go billing method. In addition to Elastic Stack components such as Elasticsearch, Logstash, Kibana, and Beats, Alibaba Cloud provides the X-Pack plug-in (advanced features of the open source Elasticsearch Platinum edition) free of charge together with Elastic. X-Pack is integrated into Kibana to provide features, such as security, alerting, monitoring, and machine learning. It also provides SQL capabilities. Alibaba Cloud Elasticsearch is widely used in scenarios such as real-time log analysis and processing, information retrieval, multidimensional data queries, and statistical data analytics.", "title": "What is Alibaba Cloud Elasticsearch?" } }, { "_index": "question_answering", "_id": "2VBdaI0Bg5EzGjIAN-Tx", "_score": 0.003581697, "_source": { "context": "Alibaba Cloud Elasticsearch is a fully managed cloud service that is developed based on open source Elasticsearch. This service is fully compatible with the features provided by open source Elasticsearch. It is out-of-the-box and supports the pay-as-you-go billing method. In addition to Elastic Stack components such as Elasticsearch, Logstash, Kibana, and Beats, Alibaba Cloud provides the X-Pack plug-in (advanced features of the open source Elasticsearch Platinum edition) free of charge together with Elastic. X-Pack is integrated into Kibana to provide features, such as security, alerting, monitoring, and machine learning. It also provides SQL capabilities. Alibaba Cloud Elasticsearch is widely used in scenarios such as real-time log analysis and processing, information retrieval, multidimensional data queries, and statistical data analytics.", "title": "What is Alibaba Cloud Elasticsearch?" } }, { "_index": "question_answering", "_id": "t49gaI0BNqB2ciGcDbmF", "_score": 0.003581697, "_source": { "context": "Alibaba Cloud Elasticsearch is a fully managed cloud service that is developed based on open source Elasticsearch. This service is fully compatible with the features provided by open source Elasticsearch. It is out-of-the-box and supports the pay-as-you-go billing method. In addition to Elastic Stack components such as Elasticsearch, Logstash, Kibana, and Beats, Alibaba Cloud provides the X-Pack plug-in (advanced features of the open source Elasticsearch Platinum edition) free of charge together with Elastic. X-Pack is integrated into Kibana to provide features, such as security, alerting, monitoring, and machine learning. It also provides SQL capabilities. Alibaba Cloud Elasticsearch is widely used in scenarios such as real-time log analysis and processing, information retrieval, multidimensional data queries, and statistical data analytics.", "title": "What is Alibaba Cloud Elasticsearch?" } }, { "_index": "question_answering", "_id": "efdbaI0BU_1of7kX5_Hn", "_score": 0.0027631863, "_source": { "context": "For information about how to log on to the Kibana console, see the "Log on to the Kibana console" topic. The username that you can use to log on to the Kibana console is elastic. The password is the one that you specified when you create your Elasticsearch cluster. If you forget your password, you can reset it. For information about the procedure and precautions for resetting the password, see the "Reset the access password for an Elasticsearch cluster" topic.", "title": "How do I log on to the Kibana console? What are the username and password that I can use to log on to the Kibana console?" } }, { "_index": "question_answering", "_id": "2FBdaI0Bg5EzGjIAN-Tx", "_score": 0.0027631863, "_source": { "context": "For information about how to log on to the Kibana console, see the "Log on to the Kibana console" topic. The username that you can use to log on to the Kibana console is elastic. The password is the one that you specified when you create your Elasticsearch cluster. If you forget your password, you can reset it. For information about the procedure and precautions for resetting the password, see the "Reset the access password for an Elasticsearch cluster" topic.", "title": "How do I log on to the Kibana console? What are the username and password that I can use to log on to the Kibana console?" } } ] } }Elasticsearch clusters earlier than V8.7
Call the inference API operation for Elasticsearch Machine Learning.
POST /_ml/trained_models/thenlper__gte-large-zh/_infer { "docs":[{"text_field": "What are the use scenarios of Alibaba Cloud Elasticsearch?"}] }The following result is returned.
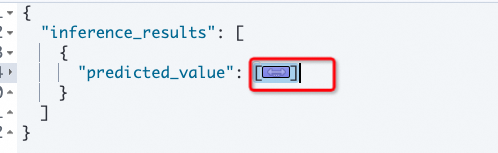
Copy the vector data and call the kNN search API to search for similar documents in the index.
GET question_answering/_search { "_source": ["context","title"], "knn": { "field": "text_embedding.predicted_value", "k": 5, "num_candidates": 10, "query_vector": [ 0.2767493426799774, 0.05577810853719711, 0.2760164141654968, -0.9484721422195435, .............. 0.8358230590820312, 0.6053569316864014, -0.5380803942680359 ] } }
Copy the value of the context parameter for the first document and call the question answering model to implement question answering.
POST /_ml/trained_models/models--luhua--chinese_pretrain_mrc_macbert_large/_infer { "docs":[{"text_field": "Alibaba Cloud Elasticsearch is a fully managed cloud service that is developed based on open source Elasticsearch. This service is fully compatible with the features provided by open source Elasticsearch. It is out-of-the-box and supports the pay-as-you-go billing method. In addition to Elastic Stack components such as Elasticsearch, Logstash, Kibana, and Beats, Alibaba Cloud provides the X-Pack plug-in (advanced features of the open source Elasticsearch Platinum edition) free of charge together with Elastic. X-Pack is integrated into Kibana to provide features, such as security, alerting, monitoring, and machine learning. It also provides SQL capabilities. Alibaba Cloud Elasticsearch is widely used in scenarios such as real-time log analysis and processing, information retrieval, multidimensional data queries, and statistical data analytics."}], "inference_config": {"question_answering": {"question": "What are the use scenarios of Alibaba Cloud Elasticsearch?"}} }The following result is returned:
{ "inference_results": [ { "predicted_value": "Real-time log analysis and processing", "start_offset": 220, "end_offset": 228, "prediction_probability": 0.014678373776954107 } ] }
Step 3: Simulate a question answering scenario
Run the Python3 command in the ECS instance to load the Python environment. Then, run the following command to simulate a question answering scenario:
# -*- coding:utf-8 -*-
import json
from pprint import pprint
import os
import time
from elasticsearch import helpers
import time
from elasticsearch import Elasticsearch
elastic_user="elastic"
elastic_password="Es123456"
elastic_endpoint="es-cn-lbj3l7erv0009bz81.public.elasticsearch.aliyuncs.com"
url = f"http://{elastic_user}:{elastic_password}@{elastic_endpoint}:9200"
es = Elasticsearch(url)
question = input("Enter your question: ")
query_args = {
"field": "text_embedding.predicted_value",
"k": 5,
"num_candidates": 10,
"query_vector_builder": {
"text_embedding": {
"model_id": "models--thenlper--gte-large-zh",
"model_text": question
}
}
}
result=es.search(index="question_answering",source=["context","title"],knn=query_args)
# print(result["hits"]["hits"])
concatenated_content = ""
for hit in result["hits"]["hits"]:
context=hit["_source"]["context"]
concatenated_content += context+" "
#print(concatenated_content)
docs=[{"text_field": concatenated_content}]
inference_config= {"question_answering": {"question": question}}
response=es.ml.infer_trained_model(model_id="models--luhua--chinese_pretrain_mrc_macbert_large",docs=docs,inference_config=inference_config)
print("Inference result: ")
print(response["inference_results"][0]["predicted_value"])The following result is returned:
Enter your question:
Where is the location of Zhangjiagang High-Speed Railway Station?
Inference result:
Zhangjiagang High-speed Railway Station is located on the east side of the new National Highway 204, north of Renmin Road in Tangqiao Town.