This topic describes how to migrate Elasticsearch index data from Amazon OpenSearch Service to Alibaba Cloud Elasticsearch.
Precautions
This solution is not limited to cloud service providers but depends on the Elasticsearch snapshot mechanism. For example, you can use the Data Online Migration service provided by Alibaba Cloud to migrate Elasticsearch data in snapshots from Amazon OpenSearch Service or Tencent Cloud Object Storage (COS) to Alibaba Cloud Object Storage Service (OSS). Then, restore the data to the destination cluster. For information about how to migrate data to Alibaba Cloud OSS, see Migrate data. For information about how to restore data in snapshots, see Create manual snapshots and restore data from manual snapshots.
The version of the destination Elasticsearch cluster must be the same as or later than the source Elasticsearch object. For information about version compatibility, see Version compatibility of data restoration from snapshots.
Background information
The following figure shows the reference architecture for the migration.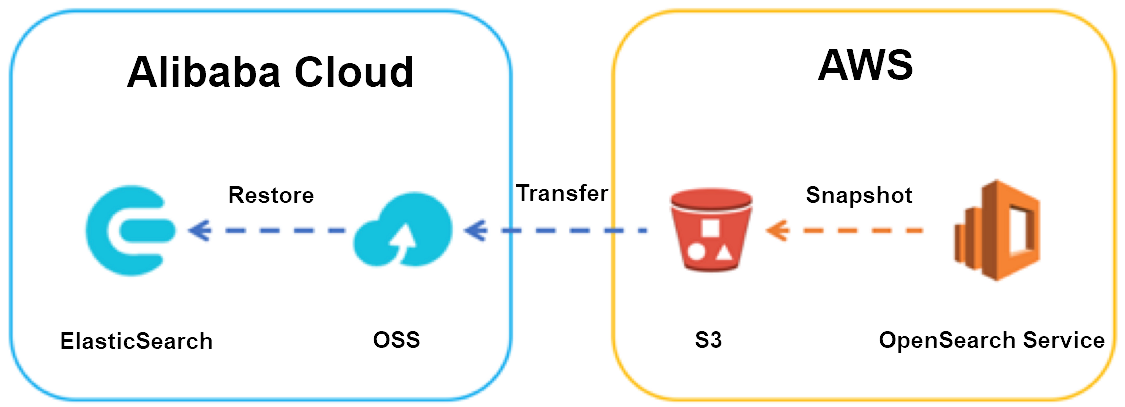
Terms
Elasticsearch: a distributed, RESTful search and analytics engine designed for various scenarios. As the core of the Elastic Stack, Elasticsearch stores your data in a centralized manner and searches for and analyzes data.
Kibana: provides a visual interface for you to search for and analyze data.
Amazon OpenSearch Service: In September 2021, Amazon Elasticsearch Service is renamed to Amazon OpenSearch Service. Amazon OpenSearch Service is a managed service that offers easy-to-use Elasticsearch APIs and real-time analytics capabilities. This service also provides the availability, scalability, and security that are required for production workloads. You can use Amazon OpenSearch Service to easily deploy, protect, manage, and scale Elasticsearch clusters for scenarios such as log analytics, full-text searches, and application monitoring.
Alibaba Cloud Elasticsearch: It is designed based on open source Elasticsearch for scenarios such as data analytics and searches. Based on open source Elasticsearch, Alibaba Cloud Elasticsearch provides enterprise-class access control, security monitoring and alerting, and automatic reporting.
Snapshot and restore: You can store snapshots of individual indexes or an entire cluster in a remote repository like a shared file system, such as Amazon Simple Storage Service (Amazon S3) or HDFS. The snapshots can be used to restore data. However, the data can be restored only to Elasticsearch clusters of specific versions:
Data in a snapshot created in an Elasticsearch 5.x cluster can be restored to an Elasticsearch 6.x cluster.
Data in a snapshot created in an Elasticsearch 2.x cluster can be restored to an Elasticsearch 5.x cluster.
Data in a snapshot created in an Elasticsearch 1.x cluster can be restored to an Elasticsearch 2.x cluster.
Migration plan
To migrate data from an Amazon OpenSearch Service domain to an Alibaba Cloud Elasticsearch cluster, perform the following steps:
Create a baseline index.
Create a snapshot repository and associate it with an Amazon S3 bucket.
Create the first snapshot for the index whose data you want to migrate. The first snapshot is a full snapshot.
This snapshot is automatically stored in the S3 bucket.
Create an Alibaba Cloud Object Storage Service (OSS) bucket, and register it with the Alibaba Cloud Elasticsearch cluster as a snapshot repository.
Use ossimport to transfer the full snapshot from the S3 bucket to the OSS bucket.
Restore data from the full snapshot to the Alibaba Cloud Elasticsearch cluster.
Process incremental snapshots on a regular basis.
Repeat the preceding steps to restore data from incremental snapshots.
Identify the final snapshot and perform a service switchover.
Stop services that may modify index data.
Create the final snapshot for the Amazon OpenSearch Service domain.
Transfer the final snapshot to the OSS bucket. Then, restore data from the snapshot to the Alibaba Cloud Elasticsearch cluster.
Perform a service switchover to the cluster and view the migrated data in the cluster.
Prerequisites
The following operations are performed:
Create an Amazon OpenSearch Service domain of Elasticsearch 5.5.2 in the Singapore region.
For more information, see Create an Amazon OpenSearch Service domain.
Create an Alibaba Cloud Elasticsearch V5.5.3 cluster in the China (Hangzhou) region.
For more information, see Create an Alibaba Cloud Elasticsearch cluster.
Create an OSS bucket.
In this example, an OSS bucket is created in the China (Hangzhou) region. The storage class of the bucket is Standard, and the access control list (ACL) of the bucket is Private. Default settings are used for other parameters. For more information, see Create buckets.
Prepare the index whose data you want to migrate. The
moviesindex is used in this example.
Prerequisites for creating manual snapshots in an Amazon OpenSearch Service domain
Amazon OpenSearch Service automatically creates snapshots for the primary index shards in a domain every day and stores them in a pre-configured S3 bucket. These snapshots are retained for a maximum of 14 days free of charge. You can use these snapshots to restore data to the domain. However, you cannot use them to migrate data to other domains. To migrate data to another domain, you must use manual snapshots stored in your S3 bucket. Standard S3 charges apply to manual snapshots.
To create manual snapshots and restore data from the snapshots, you must use AWS Identity and Access Management (IAM) and S3. Before you create snapshots, perform the operations that are listed in the following table.
Operation | Description |
Operation | Description |
Create an S3 bucket | The bucket is used to store the manual snapshots of the Amazon OpenSearch Service domain. |
Create an IAM role | The role is used to grant permissions on Amazon OpenSearch Service. When you add a trust relationship for the role, you must specify Amazon OpenSearch Service in the |
Create an IAM policy | This policy specifies the actions that S3 can perform on the S3 bucket. The policy must be attached to the IAM role that is used to grant permissions on Amazon OpenSearch Service. You must specify the S3 bucket in the Resource element of the policy. |
Create an S3 bucket
You need an S3 bucket to store manual snapshots. Take note of its Amazon Resource Name (ARN). The ARN is used by the following items:
Resource element in the IAM policy that is attached to your IAM role
Python client that is used to register a snapshot repository
The following code provides the ARN of an S3 bucket:
arn:aws:s3:::eric-es-index-backupsCreate an IAM role
You must have an IAM role, for which Amazon OpenSearch Service (es.amazonaws.com) is specified in the
Serviceelement in its trust relationship. Example:{ "Version": "2012-10-17", "Statement": [ { "Sid": "", "Effect": "Allow", "Principal": { "Service": "es.amazonaws.com" }, "Action": "sts:AssumeRole" } ] }You can view the trust relationship details in the IAM console.
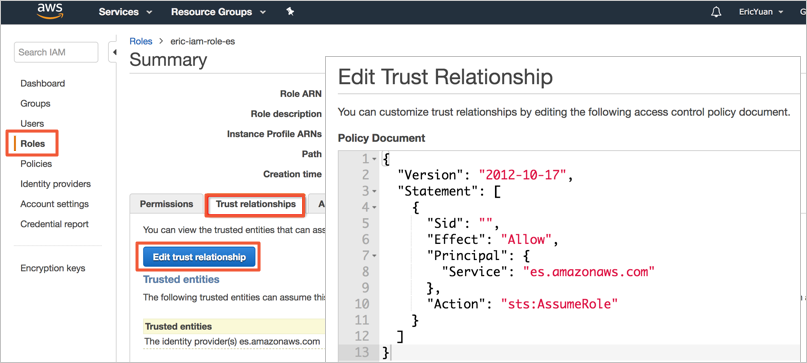
When you create a role in the IAM console, Amazon OpenSearch Service is not included in the Select role type drop-down list. You can select Amazon EC2 from the drop-down list and create the role as prompted. Then, change
ec2.amazonaws.comin the trust relationship of the role toes.amazonaws.com.Create an IAM policy
You must attach an IAM policy to the IAM role. The policy specifies the S3 bucket that is used to store the manual snapshots of the Amazon OpenSearch Service domain. The following code shows a sample policy. In the policy, the ARN of the
eric-es-index-backupsbucket is specified.{ "Version": "2012-10-17", "Statement": [ { "Action": [ "s3:ListBucket" ], "Effect": "Allow", "Resource": [ "arn:aws:s3:::eric-es-index-backups" ] }, { "Action": [ "s3:GetObject", "s3:PutObject", "s3:DeleteObject" ], "Effect": "Allow", "Resource": [ "arn:aws:s3:::eric-es-index-backups/*" ] } ] }Copy the policy content to the Edit policy section.
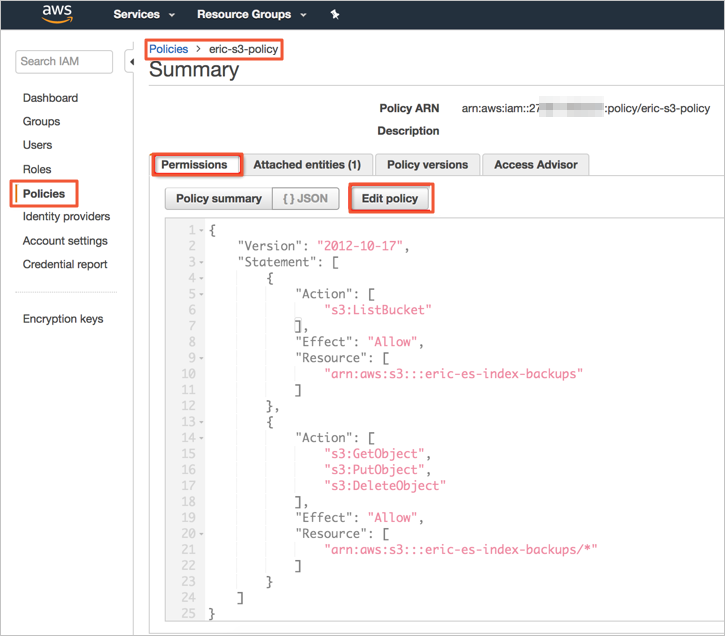
Check whether the policy is correct.
Attach the policy to the role.
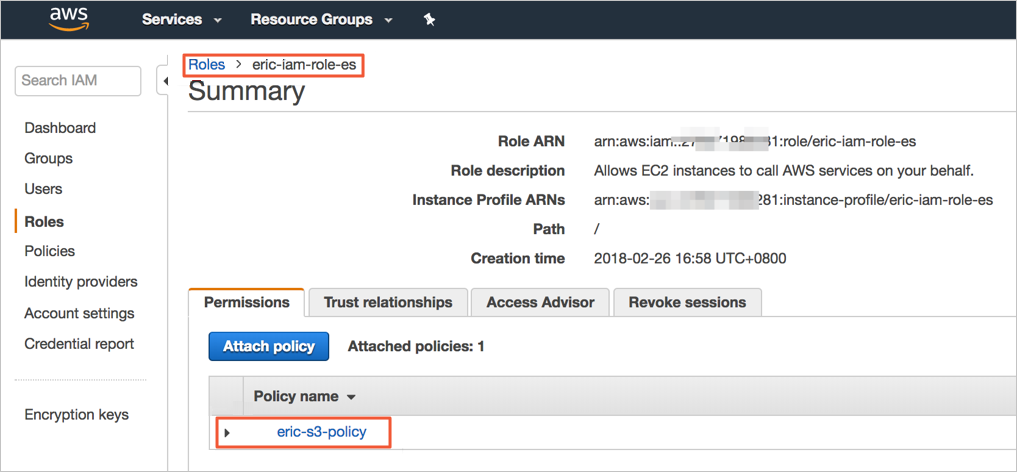
Step 1: Register a manual snapshot repository
You can create manual snapshots only after you register a snapshot repository with Amazon OpenSearch Service. Before you create manual snapshots, sign your AWS request to the user or role specified in the trust relationship of the IAM role. For more information, see Prerequisites for creating manual snapshots in an Amazon OpenSearch Service domain.
You cannot use a cURL command to register a snapshot repository because the command does not support AWS request signing. Instead, use the sample Python client (register_snapshot_repository.py) to register a snapshot repository.
Download the register_snapshot_repository.py file.
Modify the file.
Change the values highlighted in yellow in the file based on actual conditions. Then, copy the content into a Python file named snapshot.py.
The following table describes the parameters in the Sample Python Client file.
Parameter
Description
Parameter
Description
region
The AWS region in which the snapshot repository is created.
host
The endpoint of the Amazon OpenSearch Service domain.
aws_access_key_id
The ID of your IAM credential.
aws_secret_access_key
The key of your IAM credential.
path
The path of the snapshot repository.
data
The value must include the name and ARN of the S3 bucket for the IAM role that you created in Prerequisites for creating manual snapshots in an Amazon OpenSearch Service domain.
If you want to enable server-side encryption with S3-managed keys for the snapshot repository, add
"server_side_encryption": trueto the settings JSON array.If the S3 bucket resides in the ap-southeast-1 region, replace
"region": "ap-southeast-1"with"endpoint": "s3.amazonaws.com".
Install Amazon Web Services Library boto-2.48.0.
The preceding sample Python client requires that you install the boto package of version 2.x on the computer where you register a snapshot repository.
# wget https://pypi.python.org/packages/66/e7/fe1db6a5ed53831b53b8a6695a8f134a58833cadb5f2740802bc3730ac15/boto-2.48.0.tar.gz#md5=ce4589dd9c1d7f5d347363223ae1b970 # tar zxvf boto-2.48.0.tar.gz # cd boto-2.48.0 # sudo python setup.py installRun the Python client to register the snapshot repository.
# python snapshot.pyLog on to the Kibana console of the Amazon OpenSearch Service domain. In the left-side navigation pane, click Dev Tools. On the Console tab of the page that appears, run the following command to view the registration result:
GET _snapshot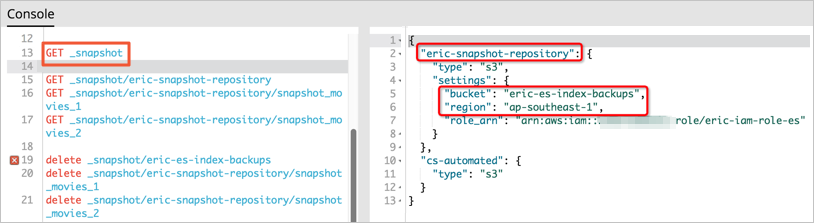
Step 2: Create the first snapshot and restore data from the snapshot
Create a snapshot in the Amazon OpenSearch Service domain.
You can run the following commands in the Kibana console or by using cURL commands in the Linux or Mac OS X command line interface (CLI).
Create a snapshot named
snapshot_movies_1for themoviesindex in theeric-snapshot-repositorysnapshot repository.PUT _snapshot/eric-snapshot-repository/snapshot_movies_1 { "indices": "movies" }View the status of the snapshot.
GET _snapshot/eric-snapshot-repository/snapshot_movies_1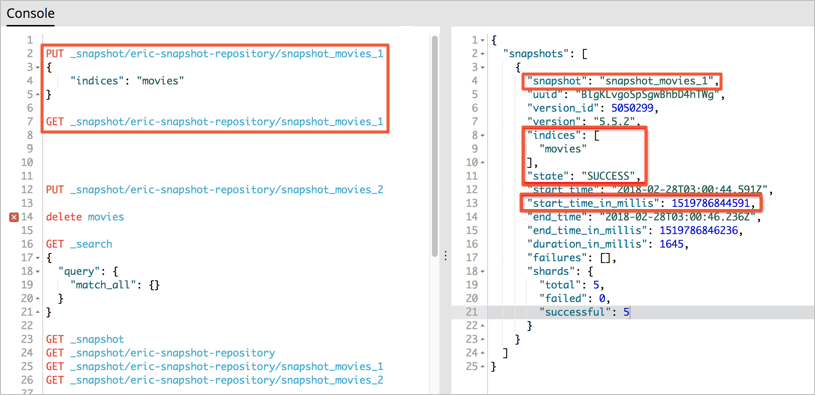
In the S3 console, view snapshot objects.
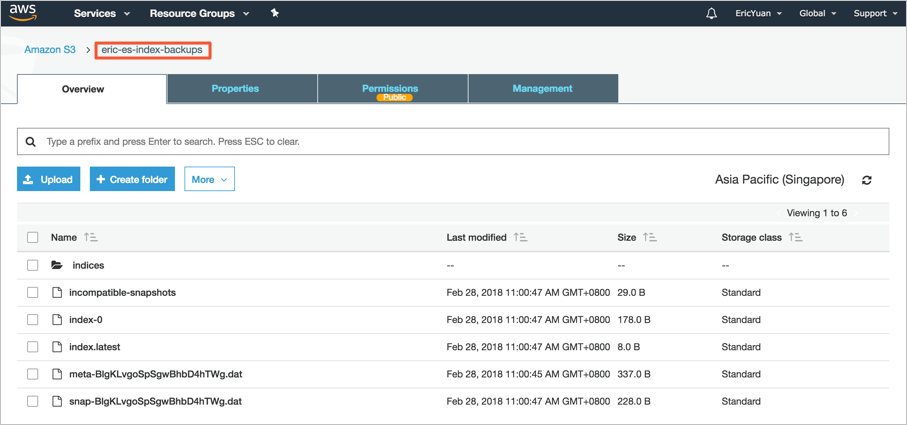
Transfer the created snapshot from the S3 bucket to the OSS bucket.
For more information, see Migrate data from Amazon S3 to Alibaba Cloud OSS.
After the snapshot is transferred, view the snapshot in the OSS console.
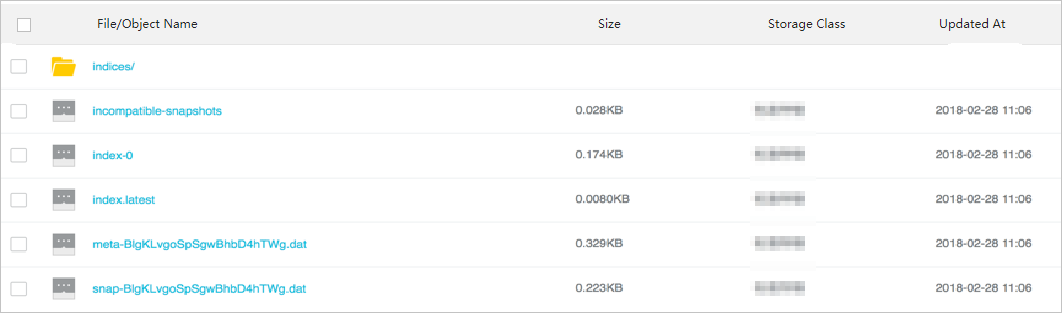
Restore data from the snapshot to the Alibaba Cloud Elasticsearch cluster.
Create a snapshot repository.
Log on to the Kibana console of the Elasticsearch cluster. For more information, see Log on to the Kibana console. Then, in the left-side navigation pane, click Dev Tools. On the Console tab of the page that appears, run the following command to create a snapshot repository. The name of the snapshot repository must be the same as that of the snapshot repository registered with Amazon OpenSearch Service.
PUT _snapshot/eric-snapshot-repository { "type": "oss", "settings": { "base_path": "my/snapshot/directory" "endpoint": "http://oss-cn-hangzhou-internal.aliyuncs.com", "access_key_id": "your AccessKeyID", "secret_access_key": "your AccessKeySecret ", "bucket": "eric-oss-aws-es-snapshot-s3", "compress": true } }View the status of the snapshot named
snapshot_movies_1.GET _snapshot/eric-snapshot-repository/snapshot_movies_1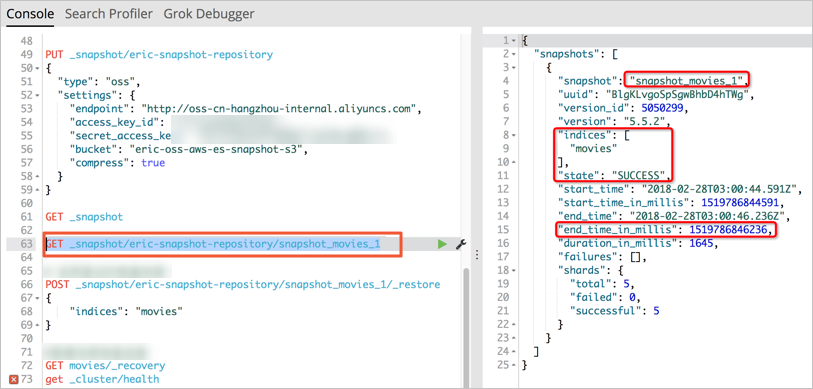
Take note of the start time and end time of the snapshot creation operation. This record is used when you use ossimport to migrate data in incremental snapshots. Example:
"start_time_in_millis": 1519786844591
"end_time_in_millis": 1519786846236
Restore data from the snapshot.
POST _snapshot/eric-snapshot-repository/snapshot_movies_1/_restore { "indices": "movies" }Run the following command to check the availability of the
moviesindex:GET movies/_recoveryAfter the command is successfully run, you can view three sets of data in the
moviesindex. In addition, the data is the same as that in the Amazon OpenSearch Service domain.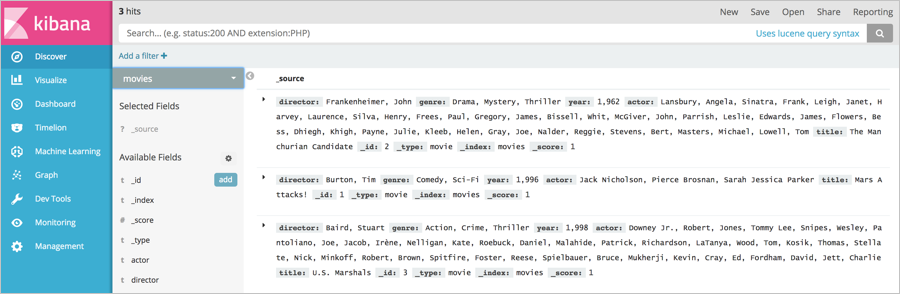
Step 3: Create the final snapshot and restore data from the snapshot
Insert data into the
moviesindex in the Amazon OpenSearch Service domain.The
moviesindex contains three sets of data. Insert another two sets of data.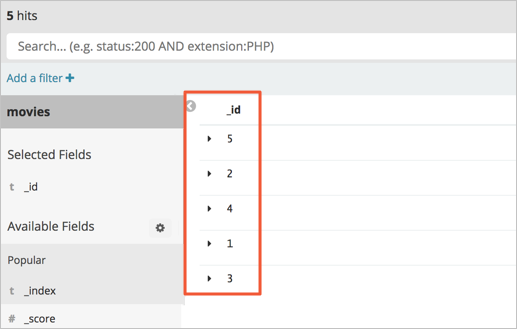
You can run the
GET movies/_countcommand to view the data volume of the index.Create a snapshot.
Run the following command to create a snapshot. For more information, see Create a snapshot in the Amazon OpenSearch Service domain.
PUT _snapshot/eric-snapshot-repository/snapshot_movies_2 { "indices": "movies" }After the snapshot is created, run the following command to view the status of the snapshot:
GET _snapshot/eric-snapshot-repository/snapshot_movies_2View objects in the S3 bucket.
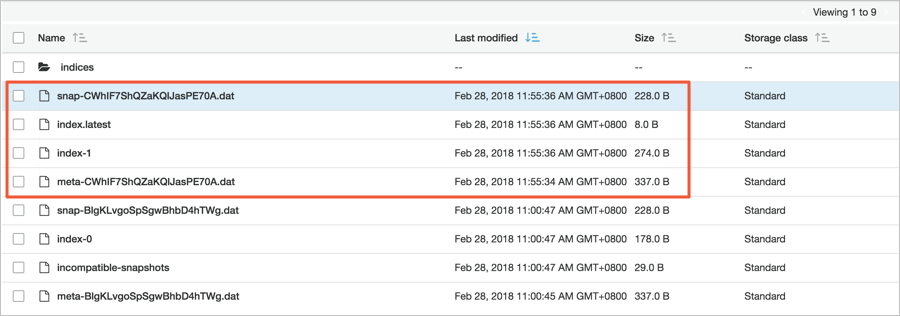
Transfer the snapshot from the S3 bucket to the OSS bucket.
You can use ossimport to transfer the snapshot. The S3 bucket stores two snapshot objects. You can change the value of the
isSkipExistFilevariable in the local_job.cfg file to migrate the incremental snapshot object.The
isSkipExistFilevariable indicates whether existing objects are skipped during data migration. The value of this variable is of the Boolean type. The default value is false. If you set the value to true, objects are skipped based on thesizeandLastModifiedTimesettings. If you set the value to false, existing objects are overwritten. IfjobTypeis set toaudit, this variable is invalid.Then, you can view the incremental snapshot object in the OSS bucket.
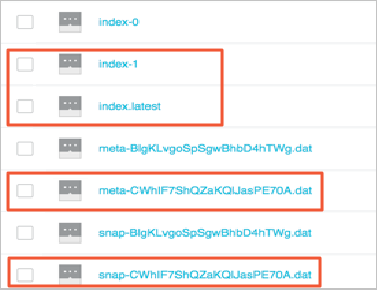
Restore data from the incremental snapshot.
For more information, see Step 2: Create the first snapshot and restore data from the snapshot. Before you restore data, you must disable the
moviesindex. After the restoration, you can enable themoviesindex.Disable the
moviesindexPOST /movies/_closeView the status of the
moviesindexGET movies/_statsRestore data from the snapshot
POST _snapshot/eric-snapshot-repository/snapshot_movies_2/_restore { "indices": "movies" }Enable the
moviesindexPOST /movies/_open
After data is restored from the snapshot, the number of documents in the
moviesindex of the Elasticsearch cluster is5. This number is the same as that in the index of the Amazon OpenSearch Service domain.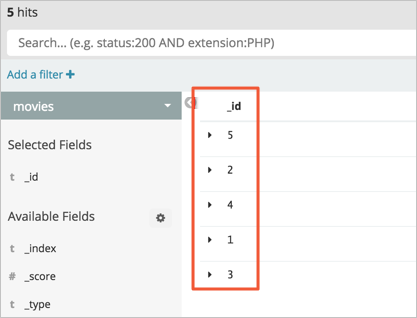
Summary
You can use the snapshot and restore feature to migrate data from an Amazon OpenSearch Service domain to an Alibaba Cloud Elasticsearch cluster. This feature requires that you disable the index whose data you want to migrate to avoid requests and write operations during the migration.
For more information, see the following topics:
FAQ
Q: Why is an error returned when I restore index data from a snapshot in OSS to an Alibaba Cloud Elasticsearch cluster?
A: It may be because the name of the snapshot object in OSS is a special character, such as a forward slash (/).
When you restore index data from snapshots in OSS to Alibaba Cloud Elasticsearch clusters, the names of the snapshot objects in OSS cannot be special characters. You can use the graphical management tool ossbrowser to move the snapshot object to a normal folder.





