This topic describes how to use the EMR Serverless spark-submit command-line interface (CLI) to develop a Spark job by connecting an ECS instance to EMR Serverless Spark.
Prerequisites
Java 1.8 or later must be installed.
If you use a RAM user to submit a Spark job, add the RAM user to the Serverless Spark workspace and grant the Developer role or higher. For more information, see Manage users and roles.
Procedure
Step 1: Download and install the EMR Serverless spark-submit CLI
Click emr-serverless-spark-tool-0.11.3-SNAPSHOT-bin.zip to download the installation package.
Upload the installation package to your ECS instance. For more information, see Upload or download files.
Run the following command to decompress and install the EMR Serverless spark-submit CLI:
unzip emr-serverless-spark-tool-0.11.3-SNAPSHOT-bin.zip
Step 2: Configure parameters
In a Spark-enabled environment, if the SPARK_CONF_DIR environment variable is set, place the configuration file in the directory specified by SPARK_CONF_DIR. For example, in an EMR cluster, this directory is typically /etc/taihao-apps/spark-conf. Otherwise, the system returns an error.
Run the following command to modify the configuration in
connection.properties:vim emr-serverless-spark-tool-0.11.3-SNAPSHOT/conf/connection.propertiesConfigure the file as follows. Use the
key=valueformat. Example:accessKeyId=<ALIBABA_CLOUD_ACCESS_KEY_ID> accessKeySecret=<ALIBABA_CLOUD_ACCESS_KEY_SECRET> regionId=cn-hangzhou endpoint=emr-serverless-spark.cn-hangzhou.aliyuncs.com workspaceId=w-xxxxxxxxxxxxImportantThe RAM user or role associated with this AccessKey must be granted RAM authorization and added to the corresponding Serverless Spark workspace.
For RAM authorization, see RAM user authorization.
For Serverless Spark workspace user and role management, see Manage users and roles.
The following table describes the parameters:
Parameter
Required
Description
accessKeyId
Yes
The AccessKey ID and AccessKey secret of the Alibaba Cloud account or RAM user used to run Spark jobs.
ImportantWhen configuring the
accessKeyIdandaccessKeySecretparameters, ensure that the user associated with the AccessKey has read and write permissions on the OSS bucket bound to the workspace. To view the OSS bucket bound to the workspace, go to the Spark page and click Details in the Actions column.accessKeySecret
Yes
regionId
Yes
The region ID. This example uses the China (Hangzhou) region.
endpoint
Yes
The endpoint of EMR Serverless Spark. For more information about endpoints, see Service endpoints.
This example uses the public endpoint for the China (Hangzhou) region. The parameter value is
emr-serverless-spark.cn-hangzhou.aliyuncs.com.NoteIf your ECS instance cannot access the public network, use the VPC endpoint.
workspaceId
Yes
The ID of the EMR Serverless Spark workspace.
Step 3: Submit a Spark job
Run the following command to go to the EMR Serverless spark-submit tool directory:
cd emr-serverless-spark-tool-0.11.3-SNAPSHOTSelect a submission method based on your job type.
When submitting a job, specify the file resources it depends on, such as JAR packages or Python scripts. These resources can be stored in OSS or locally, depending on your scenario and requirements. This topic uses OSS resources as examples.
Use spark-submit
spark-submitis Spark’s general-purpose job submission tool. It works for Java/Scala and PySpark jobs.Java or Scala jobs
This example uses spark-examples_2.12-3.5.2.jar. Click spark-examples_2.12-3.5.2.jar to download the test JAR package, then upload it to OSS. This JAR package is a built-in Spark example that calculates the value of Pi (π).
NoteYou must use spark-examples_2.12-3.5.2.jar with the esr-4.x engine version. If you use the esr-5.x engine version, download spark-examples_2.13-4.0.1.jar for validation in this topic.
./bin/spark-submit --name SparkPi \ --queue dev_queue \ --num-executors 5 \ --driver-memory 1g \ --executor-cores 2 \ --executor-memory 2g \ --class org.apache.spark.examples.SparkPi \ oss://<yourBucket>/path/to/spark-examples_2.12-3.5.2.jar \ 10000PySpark jobs
This example uses DataFrame.py and employee.csv. Click DataFrame.py and employee.csv to download the test files, then upload them to OSS.
NoteThe DataFrame.py file contains code that uses the Apache Spark framework to process data in OSS.
The employee.csv file contains a list of data, including employee names, departments, and salaries.
./bin/spark-submit --name PySpark \ --queue dev_queue \ --num-executors 5 \ --driver-memory 1g \ --executor-cores 2 \ --executor-memory 2g \ --conf spark.tags.key=value \ oss://<yourBucket>/path/to/DataFrame.py \ oss://<yourBucket>/path/to/employee.csvParameter descriptions follow:
Supported open source parameters
Parameter name
Example
Description
--name
SparkPi
Specify the application name of the Spark job for identification.
--class
org.apache.spark.examples.SparkPi
Specify the entry class name for Java or Scala programs. Do not use this parameter for Python programs.
--num-executors
5
The number of executors for the Spark job.
--driver-cores
1
The number of CPU cores allocated to the Spark driver.
--driver-memory
1g
The amount of memory allocated to the Spark driver.
--executor-cores
2
The number of CPU cores allocated to each executor.
--executor-memory
2g
The amount of memory allocated to each executor.
--files
oss://<yourBucket>/file1,oss://<yourBucket>/file2
Resource files referenced by the Spark job. These can be OSS resources or local files. Separate multiple files with commas (,).
--py-files
oss://<yourBucket>/file1.py,oss://<yourBucket>/file2.py
Python scripts referenced by the Spark job. These can be OSS resources or local files. Separate multiple files with commas (,). This parameter applies only to PySpark jobs.
--jars
oss://<yourBucket>/file1.jar,oss://<yourBucket>/file2.jar
JAR packages referenced by the Spark job. These can be OSS resources or local files. Separate multiple files with commas (,).
--archives
oss://<yourBucket>/archive.tar.gz#env,oss://<yourBucket>/archive2.zip
Archive packages referenced by the Spark job. These can be OSS resources or local files. Separate multiple files with commas (,).
--queue
root_queue
The queue where the Spark job runs. The queue name must match the one configured in EMR Serverless Spark workspace queue management.
--proxy-user
test
The specified value overwrites the
HADOOP_USER_NAMEenvironment variable. This behavior matches the open source version.--conf
spark.tags.key=value
Custom parameters for the Spark job.
--status
jr-8598aa9f459d****
Check the status of a Spark job.
--kill
jr-8598aa9f459d****
Stop a Spark job.
Enhanced non-open-source parameters
Parameter Name
Example
Description
--detach
N/A
After submitting the job, spark-submit exits immediately without waiting for or checking the job status.
--detail
jr-8598aa9f459d****
View details of a Spark job.
--release-version
esr-4.1.1 (Spark 3.5.2, Scala 2.12)
Specify the Spark version. Use the engine version shown in the console.
--enable-template
N/A
Enable the template feature. The job uses the workspace’s default configuration template.
If you created a configuration template in Configuration Management, specify the template ID by setting the
spark.emr.serverless.templateIdparameter in--conf. The job applies the specified template ID directly. For more information about creating templates, see Configuration management.If you specify only
--enable-template, the job automatically applies the workspace’s default configuration template.If you specify only the template ID in
--conf, the job applies the specified template ID directly.Specifying both
--enable-templateand--conf: If you specify both--enable-templateand--conf spark.emr.serverless.templateId, the template ID in--confoverwrites the default template.No parameters are specified: If you specify neither
--enable-templatenor--conf spark.emr.serverless.templateId, the job does not apply any template configuration.
--timeout
60
Job timeout period, in seconds.
--workspace-id
w-4b4d7925a797****
Specify the workspace ID at the job level. This overrides the
workspaceIdparameter in theconnection.propertiesfile.Unsupported open source parameters
--deploy-mode
--master
--repositories
--keytab
--principal
--total-executor-cores
--driver-library-path
--driver-class-path
--supervise
--verbose
Use spark-sql
spark-sqlis a tool designed specifically for running SQL queries or scripts. It is suitable for scenarios where you execute SQL statements directly.Example 1: Run an SQL statement directly
spark-sql -e "SHOW TABLES"This command lists all tables in the current database.
Example 2: Run an SQL script file
spark-sql -f oss://<yourBucketname>/path/to/your/example.sqlThis example uses example.sql. Click example.sql to download the test file, then upload it to OSS.
The following table describes the parameters:
Parameter Name
Example
Description
-e "<sql>"-e "SELECT * FROM table"Execute an SQL statement inline in the command line.
-f <path>-f oss://path/script.sqlExecute the SQL script file at the specified path.
Step 4: Query a Spark job
Use the CLI
Query the status of a Spark job
cd emr-serverless-spark-tool-0.11.3-SNAPSHOT
./bin/spark-submit --status <jr-8598aa9f459d****>Query the details of a Spark job
cd emr-serverless-spark-tool-0.11.3-SNAPSHOT
./bin/spark-submit --detail <jr-8598aa9f459d****>UI method
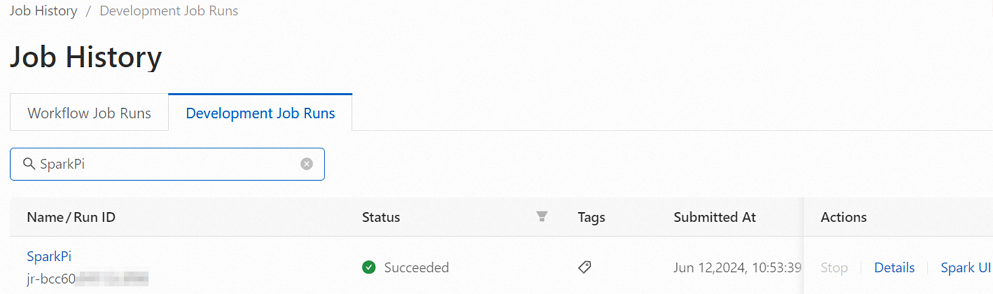
On the EMR Serverless Spark page, click Job History in the navigation pane on the left.
On the Job History page, click the Development Jobs tab to view submitted jobs.
(Optional) Step 5: Stop a Spark job
cd emr-serverless-spark-tool-0.11.3-SNAPSHOT
./bin/spark-submit --kill <jr-8598aa9f459d****>You can stop only jobs in the Running state.
FAQ
How do I specify network connectivity when submitting a batch job using the spark-submit tool?
Prepare a network connection first. For more information, see Add a network connection.
Specify the network connection in the spark-submit command using
--conf:--conf spark.emr.serverless.network.service.name=<networkname>Replace <networkname> with your actual connection name.