This topic provides answers to some frequently asked questions about cluster management.
Why does a high-availability EMR cluster have three master nodes?
How do I enable data disk encryption? What are the impacts after I enable data disk encryption?
How do I specify the disk size when I scale out an EMR cluster?
In which scenarios do I need to turn on Add to Deployment Set?
How do I configure the Add to Deployment Set parameter when I scale out an EMR cluster?
How do I associate a public IP address with an ECS instance in an existing EMR cluster?
How do I modify the configurations of ECS instances in a node group?
What do I do if an ECS system event named SystemMaintenance.Redeploy occurs?
What do I do if the error message IdempotentParameterMismatch appears?
What do I do if the error message QuotaExceeded.PrivateIpAddress appears?
FAQ about services:
FAQ about EMR Doctor:
Can I upgrade an EMR cluster?
No, you cannot upgrade an E-MapReduce (EMR) cluster and the services that are deployed in the cluster. To upgrade an EMR cluster or the services that are deployed in the cluster, release the cluster and create another cluster.
What services do EMR clusters support?
The services that are supported by EMR clusters vary based on the cluster version and cluster type. For more information, see Distribution.
Can I add the Zeppelin service in the EMR console?
EMR does not allow you to add the Zeppelin service in the EMR console. You can install Zeppelin on an Elastic Compute Service (ECS) instance that is used as a master node. For other services that cannot be added in the EMR console, you can install and perform O&M operations on them on the underlying ECS instances. For more information about cluster scenarios and supported services, see Add services.
Do EMR clusters support Oozie? What do I do if Oozie is not supported and I want to use the service?
DataLake clusters of EMR V5.8.0 or a later minor version and EMR V3.42.0 or a later minor version do not provide Oozie. If you want to use a workflow to schedule the service, you can use EMR Workflow. For more information, see What is EMR Workflow?
Why does a high-availability EMR cluster have three master nodes?
A high-availability EMR cluster with three master nodes is more reliable than a high-availability EMR cluster with two master nodes. High-availability EMR clusters with only two master nodes are no longer supported.
For high-availability clusters, EMR distributes master nodes across different underlying hardware to reduce the risk of failures.
How do I enable data disk encryption? What are the impacts after I enable data disk encryption?
When you create an EMR cluster, you can determine whether to turn on Data Disk Encryption in the Advanced Settings section of the Basic Configuration step. For more information, see Enable data disk encryption.
You can enable data disk encryption only when you create an EMR cluster. You cannot enable data disk encryption for an existing EMR cluster.
After a data disk is encrypted, data in transit and data at rest on the disk are encrypted. You can use the data disk encryption feature if your business has security compliance requirements. Data disk encryption is transparent to applications at the operating system level of ECS instances and does not affect the running of jobs.
How do I release a cluster that fails to be created?
In most cases, an EMR cluster fails to be created because the RDS configurations are incorrect or the selected ECS instance type is unavailable.
If some ECS instances are created and the cluster status is Startup Failed, you must go to the ECS console to release the ECS instances. After you release the ECS instances, the system releases the EMR cluster.
If the EMR cluster fails to be deployed and the cluster status is Unexpectedly Terminated, the cluster does not have resources and you are not charged for the cluster. You can click Delete in the Actions column to delete the cluster.
Can I add services to an EMR cluster after I create the cluster?
EMR allows you to add specific services to an EMR cluster after you create the cluster. For more information, see Add services.
After you add services, you may need to modify the related configurations of specific existing services and restart the existing services for the configurations to take effect. We recommend that you add services during off-peak hours.
The services that you can add to a cluster vary based on the version of EMR. The actual services that you can add to a cluster are displayed in the EMR console.
Do I need to restart a service after I modify the configurations of the service?
If you modify the sever-side configurations of an EMR cluster, such as the configurations of Spark, Hive, or Hadoop Distributed File System (HDFS), you must restart the service for the modification to take effect. If you modify the client-side configurations of an EMR cluster, you need to only click Deploy Client Configuration for the modification to take effect. For information about how to modify or add a configuration item, see Manage configuration items.
What is rolling restart?
Rolling restart refers to the process in which the system restarts an ECS instance only after the previous ECS instance is restarted and all big data services that are deployed on the previous ECS instance are restored. It takes approximately five minutes to restart an ECS instance.
How do I associate a public IP address with an ECS instance in an existing EMR cluster?
You can create an elastic IP address (EIP) and associate the EIP with an ECS instance that is of the virtual private cloud (VPC) network type and has no public IP address. This way, you can access the instance over the Internet. For more information, see Associate an EIP with an instance.
In which scenarios do I need to turn on Add to Deployment Set?
The deployment set feature is provided by Alibaba Cloud ECS and is used to control the distribution of ECS instances. If the core nodes of your cluster use ECS instances that are equipped with local disks, we recommend that you turn on Add to Deployment Set to improve data security. You can turn on Add to Deployment Set to prevent multiple ECS instances from being deployed on the same physical machine. This way, if a physical machine fails, the ECS instances on other physical machines are not affected and the local HDFS data is not lost.
You can add up to 20 ECS instances to a deployment set. For more information, see Add nodes to the deployment set.
How do I configure the Add to Deployment Set parameter when I scale out an EMR cluster?
By default, Add to Deployment Set is turned on for ECS instances that are equipped with local disks and turned off for ECS instances that are equipped with other disks. You can specify whether to turn on Add to Deployment Set based on your business requirements. For more information, see Add nodes to the deployment set.
How do I specify the disk size when I scale out an EMR cluster?
When you scale out an EMR cluster, the disk size of new nodes is the same as the disk size of existing nodes in the node group and cannot be modified. You can expand the disks of a node group based on your business requirements. For more information, see Expand a disk.
Can I resize the disks of EMR clusters?
You can expand but cannot shrink the data disks of EMR clusters. You cannot resize a system disk.
To expand the data disk of an EMR cluster, perform the following steps: On the Nodes tab of the desired cluster, find the node group and click Expand Disk in the Actions column. For more information, see Expand a disk.
Can I scale out or scale in an EMR cluster?
Yes, you can scale out or scale in an EMR cluster. However, the scale-in and scale-out rules vary based on the node type.
Scale-out: You can add only core nodes and task nodes. By default, the configurations of an added node are the same as the configurations of an existing node in the node group. During a scale-out, you must make sure that you complete the payment for your order. If you do not complete the payment for your order, the scale-out fails. For more information, see Scale out an EMR cluster.
Scale-in: The scale-in rules vary based on the node type.
For information about how to scale in a task node group, see Scale in a cluster.
For information about how to scale in a core node group, see Scale in a core node group.
How do I modify the configurations of ECS instances in a node group?
You can upgrade the specifications of a node group in a subscription EMR cluster to modify the configurations of the ECS instances in the node group. You cannot downgrade the specifications of a node group.
To upgrade the specifications of a node group, perform the following steps: On the Nodes tab of the desired cluster, find the desired node group, move the pointer over the  icon in the Actions column, and then select Upgrade Configuration. For more information, see Upgrade node configurations.
icon in the Actions column, and then select Upgrade Configuration. For more information, see Upgrade node configurations.
What do I do if the error message "The specified parameter AddNumber is not valid" appears during the scale-out of a cluster?
Problem description: The error message
The specified parameter AddNumber is not valid. add instances number :xxx larger than deploymentSet availableAmount: xxx deploymentSetId: ds-uf6gwfou0a13kekupt14xxxxappears during the scale-out of a cluster.Cause: Add to Deployment Set is turned on for the cluster that you want to scale out, and the number of nodes in a node group exceeds the upper limit in a deployment set. For more information about the deployment set, see Add nodes to a deployment set.
Solution: Contact ECS technical support to increase the maximum number of nodes that can be added to a deployment set for your current account.
How do I stop collection of service operational logs?
If you do not want EMR to collect your data, you can disable collection of service operational logs.
If you disable collection of service operational logs, the EMR cluster health check and technical support are limited. Other features of your cluster remain available. Proceed with caution.
Solutions:
Disable collection of service operational logs.
When you create a cluster, turn off Collect Service Operational Logs in the Software Configuration step.
For an existing cluster, turn off Collection Status of Service Operational Logs in the Software Information section of the Basic Information tab of the cluster.
Check whether collection of service operational logs is disabled.
Check whether the
namenode-loginformation exists in the /usr/local/ilogtail/user_log_config.json file. If the namenode-log information does not exist, collection of service operational logs is disabled.NoteAfter you disable collection of service operational logs, it takes about 2 to 3 minutes for the configuration to take effect.
What information is collected in service operational logs?
Service operational logs contain only data about the running of service components on a cluster. You can enable or disable log collection for all services with one click. If you disable log collection, the EMR cluster health check and after-sales technical support are limited.
Collect Service Operational Logs is turned on by default when you create a cluster. You can determine whether to turn off the switch based on your business requirements. For more information, see How do I stop collection of service operational logs?
Which types of clusters support EMR Doctor (health diagnostics feature in the EMR console)?
Only DataLake and Hadoop clusters support the health diagnostics feature. After you create an EMR cluster, you can click the Health Diagnostics subtab on the Monitoring and Diagnostics tab of the cluster to use the health check feature.
If you create an EMR Hadoop cluster, you must activate EMR Doctor before you can use the health diagnostics feature in the cluster. For more information, see Activate EMR Doctor (Hadoop clusters).
Does the installation or upgrade of EMR Doctor exert impacts on services in an EMR cluster and jobs that run on the cluster?
During the installation or upgrade of EMR Doctor, no services in an EMR cluster are restarted, and no impacts are exerted on existing jobs that are run on the cluster. After EMR Doctor is installed, the required parameters for EMR Doctor are automatically configured for the cluster. You do not need to perform any manual configurations.
During the installation or upgrade of EMR Doctor, EMR delivers configurations of services such as YARN, Spark, Tez, and Hive to clusters. Before you install or upgrade EMR Doctor, we recommend that you check whether some service configurations are modified and saved but are not delivered and evaluate the impacts of delivering the service configurations to clusters.
What type of data does EMR Doctor collect?
EMR Doctor does not collect your actual data or scan your actual files or file content.
EMR Doctor collects only necessary event data, such as the start time, end time, metrics, and counters of a job.
Am I charged for EMR Doctor?
EMR Doctor is free of charge.
What are the impacts of job data collection on job execution?
The storage metadata collection feature of EMR Doctor can dynamically adjust the amount of collected resources based on the amount of user resources. This prevents excess user resources from being occupied.
The job collection feature of EMR Doctor works based on the Java probe technology. The feature does not separately start Java process monitoring. Job data is collected in asynchronous mode. It does not block the main process of a job. If the job collection pressure is heavy, the collected data is automatically discarded, and you can adjust the collection frequency by configuring parameters.
The following table lists the data of some TPC-DS tests.
SQL and engine | Collection duration when EMR Doctor is used (average duration of job collection based on 10 calculation rounds) | Collection duration when EMR Doctor is not used (average duration of job collection based on 10 calculation rounds) |
query7 (Spark) | 21.0s | 21.2s |
query71 (Tez) | 50.8s | 49.8s |
query19 (MapReduce) | 68.6s | 68.2s |
In this example, a test based on the TPC-DS benchmark is performed, but the test does not meet all requirements of a TPC-DS benchmark test. As a result, the test results may not match the published results of the TPC-DS benchmark test.
When can I obtain the collection report?
After EMR Doctor is installed or upgraded in an EMR cluster, the daily cluster report feature performs an analysis based on the jobs that users want to run and whether the storage metadata collection feature is enabled. In this case, the EMR cluster must contain jobs.
Computing jobs: After computing jobs in an EMR cluster are collected, the latest reports for the jobs can be viewed on the next day. The content of the reports is an overall evaluation on the cluster based on the execution status of the jobs in the cluster.
Storage analysis: The Collect Information About Storage Resources feature of EMR Doctor is disabled by default. You can manually enable this feature. After you enable the Collect Information About Storage Resources feature, the related information is collected at 10:00 in the morning on the current day. After data is collected, the data is analyzed in the morning on the next day and reports are generated based on the analysis results. If data is collected in the afternoon on the current day, you can view reports on the day after the next day.
Can specific values be provided for parameters?
Optimization suggestions that are provided by EMR Doctor are directional. For example, we recommend that you decrease the amount of memory and modify the garbage collection parameters without providing specific parameter values. EMR Doctor collects job data by using the recording and sampling method. EMR Doctor aims to prevent impacts on your program. You need to adjust parameters based on suggestions and check whether the configuration is suitable.
What do I do if an error message that indicates insufficient ECS resources appears when I scale out a cluster?
Problem description: A cluster fails to be scaled out, and the "Insufficient ECS resources_OutofStock" or "Insufficient ECS resources_OperationDenied.NoStock" error message appears.
Cause: ECS instances of the specified instance type that you want to add to a node group are insufficient.
Solution: Perform the scale-out operation after ECS instances of the specified instance type are sufficient. Alternatively, create a node group that contains ECS instances of another instance type. For more information, see Create a node group.
What do I do if an error message that indicates insufficient ECS resources appears when I create a cluster or a node group?
Problem description: A cluster or a node group fails to be created and the "Insufficient ECS resources_OutofStock" or "Insufficient ECS resources_OperationDenied.NoStock" error message appears.
Cause: ECS instances of the instance type that you select when you create a cluster or a node group are insufficient.
Solution: Select another ECS instance type of which ECS instances are sufficient and that meets your business requirements when you create a cluster or a node group.
How do I remove a service that is no longer needed?
You cannot remove existing services that are deployed in a cluster. After a service is started, you cannot remove the service in the console or by calling an API operation.
How do I log on to a node of a cluster?
After an EMR cluster is created, you can use the password that you specified when you created the cluster to log on to the master node of the cluster. For information about how to log on to other nodes of the cluster, see Log on to other nodes of a cluster.
How do I view the vSwitch with which a node is associated?
In Alibaba Cloud EMR on ECS, vSwitches are associated with nodes in node groups. You cannot view the associations on the Basic Information tab. To view the vSwitch with which a node is associated, perform the following steps: Go to the Nodes tab of your cluster, find the node group to which the node belongs, and then click the node group name. In the Node Group Attributes panel, view the setting of the vSwitch parameter.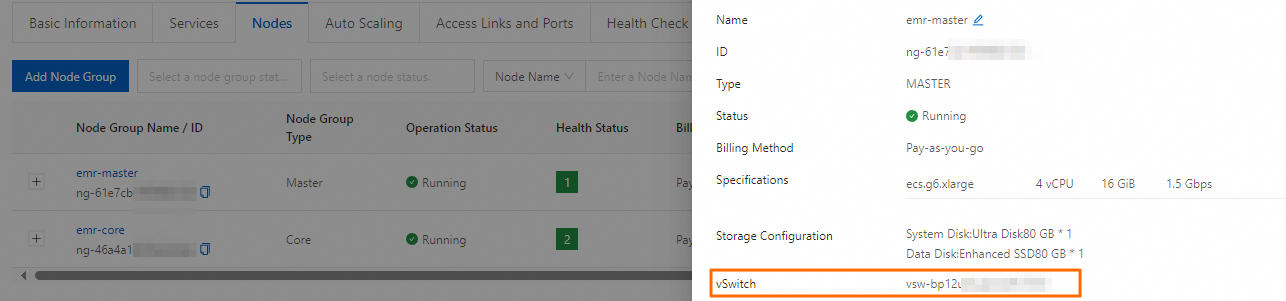
What do I do if packet loss frequently occurs in clusters?
Problem description: Packet loss frequently occurs in clusters, and error messages such as
neighbour: arp_cache: neighbor table overflow!may appear in system logs. This indicates that the Address Resolution Protocol (ARP) cache table reaches its upper capacity limit and cannot effectively map media access control (MAC) addresses to IP addresses. As a result, the network performance is decreased.Problem analysis: In a large-scale distributed system, especially when your EMR cluster is of a minor version earlier than EMR V5.18.0 or V3.52.0 and has more than 1,000 servers, the network may be unstable and packet loss may occur. You can configure system parameters to optimize the management of ARP caches.
An ARP cache table stores MAC and IP address pairs. Related parameters:
net.ipv4.neigh.default.gc_thresh1: If the number of entries in an ARP cache table is less than the value of this parameter, the garbage collector does not collect the entries. Default value: 128.net.ipv4.neigh.default.gc_thresh2: If the number of entries in an ARP cache table is greater than the value of this parameter, the garbage collector collects the entries within 5 seconds. Default value: 512.net.ipv4.neigh.default.gc_thresh3: The maximum number of entries to keep in an ARP cache table. Default value: 1024.
NoteThe default values for the parameters are small. As a result, packet loss and network instability occur when the cluster has more than 1,000 servers. In this case, you need to change the default values based on your business requirements.
Solutions:
Add the following code to the
/etc/sysctl.conffile to increase the values of the preceding parameters and the maximum number of connections that are allowed to come into the servers.net.ipv4.neigh.default.gc_thresh1 = 512 net.ipv4.neigh.default.gc_thresh2 = 2048 net.ipv4.neigh.default.gc_thresh3 = 10240 net.nf_conntrack_max = 524288Run the
sudo sysctl -pcommand to make the modifications take effect.NoteIf the error message
sysctl: cannot stat /proc/sys/net/nf_conntrack_max: No such file or directoryappears when you run thesysctl -pcommand, you can run thesudo modprobe nf_conntrackcommand to load the nf_conntrack module and then run thesysctl -pcommand again.
What do I do if an ECS system event named SystemMaintenance.Redeploy occurs?
The SystemMaintenance.Redeploy event indicates that Alibaba Cloud has detected potential risks of software and hardware failures on the underlying host of the ECS instances of a cluster. This may cause the ECS instances to be redeployed. In this case, do not click Redeploy in the ECS console to prevent data loss.
Solutions:
Identify the node on which the event occurs based the event details.
Add a node in the node group to which the faulty node belongs. For more information, see Scale out an EMR cluster.
Remove the faulty node.
For information about how to scale in a core node group or a subscription task node group in a cluster, follow the instructions described in Scale in a core node group.
NoteECS calculates and displays the refund amount when you unsubscribe from a subscription ECS instance. If you have any questions, submit a ticket. Select Elastic Compute Service (ECS) when you submit a ticket.
For information about how to scale in a task node group that contains pay-as-you-go instances, see Scale in a cluster.
What do I do if I want the disks of ECS instances in an EMR cluster to automatically inherit the tags of the EMR cluster?
If you want the disks of ECS instances in an EMR cluster to automatically inherit the tags of the EMR cluster, you can use the Associated Resource Tagging feature provided by Resource Management. This way, if you attach a cloud disk to an ECS instance, the cloud disk automatically inherits the existing tags of the ECS instance and also inherits the tag changes that are made to the ECS instance later.
Procedure:
Log on to the Resource Management console.
In the left-side navigation pane, choose .
On the Associated Resource Tag Settings page, read the feature description and select the check box for creating a service-linked role.
When you enable the Associated Resource Tagging feature, the system creates the AliyunServiceRoleForTag service-linked role. The role is used to perform tag-related operations on associated resources. For more information, see Service-linked role for Tag.
Click Enable and Configure Rules.
In the upper-right corner of the Associated Resource Tag Settings page, click Edit and configure an associated resource tagging rule.
You can set the tag inheritance scope for different types of associated resources to All Tag Keys or Specific Tag Keys.

Click OK.
For more information about the Associated Resource Tagging feature, see Use the Associated Resource Tagging feature.
What do I do if the error message IdempotentParameterMismatch appears?
Problem description: The following error message may appear when you release a cluster or upgrade the cluster configuration.
Cause: The same client token is used in multiple requests.
The request uses the same client token as a previous, but non-identical request. Do not reuse a client token with different requests, unless the requests are identical.Solution: Check whether you are releasing a cluster or upgrading the cluster configuration. If you are releasing a cluster or upgrading the cluster configuration, you do not need to perform the operation again. If you are not releasing a cluster or upgrading the cluster configuration, refresh the console page. Then, a new client token is automatically generated in the EMR console.
What do I do if the error message QuotaExceeded.PrivateIpAddress appears?
Problem description: The following error message may appear when you create or scale out a cluster.
[QuotaExceeded.PrivateIpAddress] The specified VSwitch "vsw-xxxx" does not have enough IP addresses.Cause: The number of available IP addresses for the vSwitch that you selected is insufficient for cluster creation or scale-out.
Solution: Create a node group and select a vSwitch with sufficient IP addresses.
What do I do if the LostProxy error message appears?
Problem description: The error message "taihao-proxy disconnect" appears when you create a cluster, scale out a cluster, or update the service configuration.
Cause: The EMR proxy on the cluster node is disconnected.
Solutions:
Check the cluster status and fix node issues.
If a batch of nodes are disconnected, check the CPU utilization and memory usage.
If the CPU utilization or memory usage is high, the cluster is overloaded. You can upgrade the cluster configuration or scale out the cluster.
If the CPU utilization or memory usage is low, check the configuration of the network security group to ensure that the network communication is normal.
If only specific nodes are disconnected, check whether the CPU utilization or memory usage of the nodes reaches 100%. If the nodes are overloaded, check whether abnormal processes occupy resources. If abnormal processes exist, terminate the processes and check whether the node status becomes normal. If no abnormal processes exist, perform the following operations:
If the master nodes are disconnected, check the processes with high CPU utilization. You can upgrade the specifications of the master nodes or add Master-Extend nodes to share the workloads.
If a non-master node is disconnected due to high workloads or does not respond, you can undeploy the node or add a new node.
Log on to the node and run the following command to restart the service:
service taihao-proxy restart
After you complete the preceding operations, create a cluster, scale out a cluster, or update the service configuration again.
What do I do if an error message that indicates insufficient account balance appears when I create a cluster, scale out a cluster, or upgrade the cluster configuration?
Problem description: The following error message appears when you create a cluster, scale out a cluster, or upgrade the cluster configuration.
nvalidAccountStatus.NotEnoughBalance Message: Your account does not have enough balance to order postpaid product.Cause: Your account balance is insufficient.
Solution: Check your account balance to ensure that your account balance is greater than the cost of the required resources. After ensuring that your account balance is sufficient, perform the related operations again.
What do I do if the error message QuotaExceed.DiskCapacity appears when I scale out a cluster or disk?
Problem description: The following error message may appear when you scale out a cluster or disk.
[QuotaExceed.DiskCapacity] The used capacity of disk type has exceeded the quota in the zone, quota check fail.Cause: The disk quota of the instance reaches the upper limit.
Solution: The occupied capacity of the specific disk type exceeds the quota limit in the zone. You can go to Quota Center to view and increase the quota.
What do I do if the error message QuotaExceed.DiskCapacity appears when I create or scale out a cluster?
Problem description: The following error message may appear when you create or scale out a cluster.
QuotaExceed.ElasticQuota Message: The number of the specified ECS instances has exceeded the quota of the specified instance type.Cause: The quota of the ECS instance reaches the upper limit.
Solution: Select another instance type or reduce the number of instances that you want to create. You can also go to the ECS console or Quota Center to request a quota increase.
What do I do if a boot script fails to be executed?
View the execution log of the boot script that fails to be executed on the operation history details page.
If the log contains a specific error message, modify the boot script based on the error message and re-execute the script.
If the log contains the
exitCodekeyword without a specific error message, add more logging statements to the boot script for better debugging and re-execute the script.If the log shows that the task times out or does not contain any output, check the following items:
Check whether you have the read and write permissions on the OSS bucket in which the boot script is stored.
Check whether the ECS instance can access the internal OSS endpoint. Then, re-execute the script.