This topic provides answers to some frequently asked questions about Dataflow clusters.
Questions about cluster usage and O&M:
Questions about jobs:
Where are logs stored in a cluster? How do I view the logs?
You can view the logs of a cluster in the following ways based on the status of JobManager:
If JobManager of the Flink cluster has stopped, you can view the logs by running the yarn logs -applicationId application_xxxx_yy command on a node of the cluster to pull the logs to your on-premises machine. You can also access the log link of a completed job on the YARN web UI to view the logs on a web page.
If JobManager of the Flink cluster is running, you can view logs in either of the following ways:
View logs on the web UI of a Flink job.
Run the yarn logs -applicationId application_xxxx_yy -am ALL -logFiles jobmanager.log command to view the JobManager logs. Run the yarn logs -applicationId application_xxxx_yy -containerId container_xxxx_yy_aa_bb -logFiles taskmanager.log command to view the TaskManager logs.
What do I do if a JAR package of a job conflicts with a JAR package of the Flink in a cluster?
In most cases, an error such as NoSuchFieldError, NoSuchMethodError, or ClassNotFoundException is recorded in job logs if this issue occurs. You can perform the following steps to troubleshoot and resolve the issue:
Identify the dependency class that causes the conflict. Check the error logs to find the class that causes the conflict. Find the JAR package in which the class resides. Then, run the mvn dependency:tree command in the directory in which the pom.xml file for the job is stored to view the JAR dependency tree.
Exclude the dependency class that causes the conflict.
If the scope parameter of the JAR package is incorrectly set in the pom.xml file, you can change the value of the scope parameter to provided to exclude the JAR package.
If you must use the JAR package in which the class that causes the conflict resides, you can exclude the class in dependencies.
If the class that causes the conflict cannot be replaced by a class of the corresponding version in the cluster, you can use Maven Shade Plugin to shade the class.
In addition, if multiple versions of a JAR package are specified in the classpath, the class version that is used by the job depends on the loading order of classes. To confirm which JAR package a class is loaded from, you can specify the Java virtual machine (JVM) parameter env.java.opts: -verbose:class in the flink-conf.yaml file or specify the dynamic parameter -Denv.java.opts="-verbose:class". This way, the system records the loaded classes and the JAR packages from which the classes are loaded.
NoteFor JobManager or TaskManager, the preceding information is recorded in the
jobmanager.outortaskmanager.outfile.
How do I submit Flink jobs to a Dataflow cluster by using a client that is not deployed in the Dataflow cluster?
Perform the following steps to submit Flink jobs to a Dataflow cluster by using a client that is not deployed in the Dataflow cluster:
Make sure that the Dataflow cluster is connected to the client.
Configure a Hadoop YARN environment for the client.
In the Dataflow cluster, the Hadoop YARN software is installed in the /opt/apps/YARN/yarn-current directory and the configuration files are stored in the /etc/taihao-apps/hadoop-conf/ directory. You must download the files in the yarn-current and hadoop-conf directories and store the files in the client that is used to submit Flink jobs.
Then, run the following commands on the client to configure environment variables:
export HADOOP_HOME=/path/to/yarn-current && \ export PATH=${HADOOP_HOME}/bin/:$PATH && \ export HADOOP_CLASSPATH=$(hadoop classpath) && \ export HADOOP_CONF_DIR=/path/to/hadoop-confImportantIn Hadoop configuration files such as yarn-site.xml, components such as ResourceManager uses fully qualified domain names (FQDNs) as service addresses. Example: master-1-1.c-xxxxxxxxxx.cn-hangzhou.emr.aliyuncs.com. Therefore, if you submit a Flink job by using a client that is not deployed in the Dataflow cluster, make sure that these FQDNs can be resolved or change the FQDNs to IP addresses.
After you complete the preceding configurations, start a Flink job on the client that is not deployed in the Dataflow cluster. For example, you can run the
flink run -d -t yarn-per-job -ynm flink-test $FLINK_HOME/examples/streaming/TopSpeedWindowing.jarcommand to start a Flink job. Then, you can view the Flink job on the YARN web UI of the Dataflow cluster.
If I use a client that is not deployed in a Dataflow cluster to submit Flink jobs, how do I resolve the hostnames that are specified in configuration files of the Dataflow cluster on the client?
Use one of the following methods to resolve the hostnames that are specified in configuration files of a Dataflow cluster on a client that is not deployed in the Dataflow cluster:
Modify the /etc/hosts file on the client to add mappings between hostnames and IP addresses.
Use Alibaba Cloud DNS PrivateZone.
You can also specify the following JVM parameters to use your own DNS service:
env.java.opts.client: "-Dsun.net.spi.nameservice.nameservers=xxx -Dsun.net.spi.nameservice.provider.1=dns,sun -Dsun.net.spi.nameservice.domain=yyy"
How do I view the status of Flink jobs?
Use the E-MapReduce (EMR) console.
EMR supports Knox that allows you to access web UIs of services such as YARN and Flink over the Internet. You can go to the Apache Flink Dashboard page from the YARN web UI to view the status of Flink jobs. For more information, see View the job status on the web UI of Flink (VVR).
Use an SSH tunnel. For more information, see Create an SSH tunnel to access web UIs of open source components.
Call a RESTful API of YARN.
curl --compressed -v -H "Accept: application/json" -X GET "http://master-1-1:8088/ws/v1/cluster/apps?states=RUNNING&queue=default&user.name=***"NoteMake sure that ports 8443 and 8088 are enabled in your security group to allow calls to a RESTful API of YARN. Alternatively, make sure that the Dataflow cluster and the node that you want to access reside in the same virtual private cloud (VPC).
How do I view the logs of Flink jobs?
If a Flink job is running, you can view the logs of the Flink job on its web UI.
If a Flink job is complete, you can view the statistics of the Flink job on Flink HistoryServer or by running the
yarn logs -applicationId application_xxxx_yyyycommand. By default, the logs of Flink jobs that are complete are saved in the hdfs:///tmp/logs/$USERNAME/logs/ directory of the Hadoop Distributed File System (HDFS) cluster.
How do I access Flink HistoryServer in a Dataflow cluster?
By default, Flink HistoryServer is started at port 18082 of the master-1-1 node, which is the first server of the master server group, in a Dataflow cluster. Flink HistoryServer collects statistics on Flink jobs that are complete. To access Flink HistoryServer, perform the following steps:
Configure security group rules to enable access to port 18082 of the master-1-1 node.
Access http://$master-1-1-ip:18082.
Flink HistoryServer does not store the logs of Flink jobs that are complete. To view the logs, can an YARN API operation or access the YARN web UI.
How do I use commercial connectors that are supported by a Dataflow cluster?
A Dataflow cluster provides various commercial connectors, such as Hologres, Log Service, MaxCompute, DataHub, Elasticsearch, and ClickHouse connectors. You can use open source connectors or the commercial connectors in Flink jobs. In this example, a Hologres connector is used.
Install a connector
Download the JAR package of the Hologres connector and install the Hologres connector to Maven on your on-premises machine. The JAR package of the Hologres connector is stored in the /opt/apps/FLINK/flink-current/opt/connectors directory of the Dataflow cluster.
mvn install:install-file -Dfile=/path/to/ververica-connector-hologres-1.13-vvr-4.0.7.jar -DgroupId=com.alibaba.ververica -DartifactId=ververica-connector-hologres -Dversion=1.13-vvr-4.0.7 -Dpackaging=jarAdd the following dependency to the pom.xml file:
<dependency> <groupId>com.alibaba.ververica</groupId> <artifactId>ververica-connector-hologres</artifactId> <version>1.13-vvr-4.0.7</version> <scope>provided</scope> </dependency>
Run a job
Method 1:
Copy the JAR package of the Hologres connector to a separate directory.
hdfs mkdir hdfs:///flink-current/opt/connectors/hologres/ hdfs cp hdfs:///flink-current/opt/connectors/ververica-connector-hologres-1.13-vvr-4.0.7.jar hdfs:///flink-current/opt/connectors/hologres/ververica-connector-hologres-1.13-vvr-4.0.7.jarAdd the following information to the command that is used to submit a job:
-D yarn.provided.lib.dirs=hdfs:///flink-current/opt/connectors/hologres/
Method 2:
Copy the JAR package of the Hologres connector to the /opt/apps/FLINK/flink-current/opt/connectors/ververica-connector-hologres-1.13-vvr-4.0.7.jar directory of the client that you use to submit Flink jobs. The directory has the same structure as the directory that stores the JAR package of the Hologres connector in the Dataflow cluster.
Add the following information to the command that is used to submit a job:
-C file:///opt/apps/FLINK/flink-current/opt/connectors/ververica-connector-hologres-1.13-vvr-4.0.7.jar
Method 3: Add the JAR package of the Hologres connector to the JAR package of a job that you want to run.
How do I use GeminiStateBackend?
A Dataflow cluster provides GeminiStateBackend, which is an enterprise-edition state backend. The performance of GeminiStateBackend is three to five times that of open source state backends. By default, GeminiStateBackend is used in the configuration files of a Dataflow cluster. For more information about advanced configurations of GeminiStateBackend, see Configurations of GeminiStateBackend.
How do I use an open source state backend?
By default, GeminiStateBackend is used in the configuration files of a Dataflow cluster. If you want to use an open source state backend such as RocksDB for a job, you can use the -D parameter to specify the state backend. Example:
flink run-application -t yarn-application -D state.backend=rocksdb /opt/apps/FLINK/flink-current/examples/streaming/TopSpeedWindowing.jarIf you want the preceding configurations to take effect for subsequent jobs, change the value of the state.backend parameter to the state backend that you want to use in the E-MapReduce (EMR) console. For example, you can change the state backend to RocksDB. Click Save and then click Deploy Client Configuration.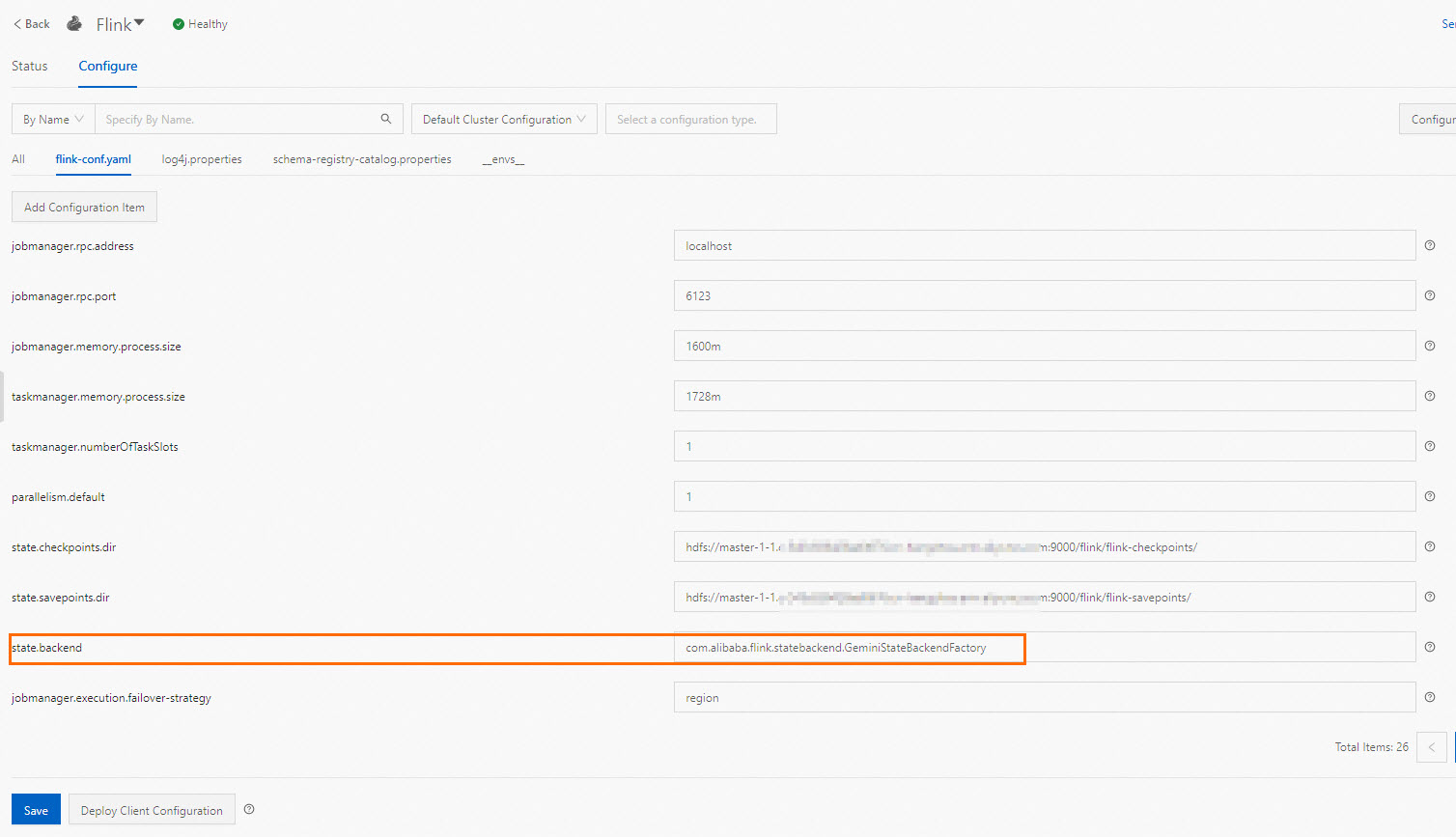
Where are client logs stored? How do I view the client logs?
In an EMR cluster, the FLINK_LOG_DIR environment variable specifies the directory in which the logs of Flink clients are stored. The default directory is /var/log/taihao-apps/flink. In EMR versions that are earlier than V3.43.0, the default directory is /mnt/disk1/log/flink. You can view the complete logs of clients, such as SQL Client, in the corresponding files in this directory.
Why do the parameters of a Flink job not take effect when I run the flink run command to start the job?
When you start a Flink job by running a command, you must place the parameters of the Flink job behind the JAR package of the Flink job. Example: flink run -d -t yarn-per-job test.jar arg1 arg2.
What do I do if the following error message is returned: Multiple factories for identifier '...' that implement '...' found in the classpath?
Cause
The error message indicates that multiple implementations of a connector are found in the classpath. In most cases, a dependency conflict occurs because a connector dependency is added to the JAR dependencies of a job but the package of the connector is manually placed in the $FLINK_HOME/ib directory.
Solution
Remove the duplicate dependency. For more information, see What do I do if a JAR package of a job conflicts with a JAR package of the Flink in a cluster?
How do I enable high availability for JobManager to improve the stability of Flink jobs?
In a Dataflow cluster, Flink jobs are deployed and run on YARN. You can follow the instructions that are described in the Configuration section of the documentation provided by the Apache Flink community to enable high availability for JobManager to implement stable running of Flink jobs. Configuration example:
high-availability: zookeeper
high-availability.zookeeper.quorum: 192.168.**.**:2181,192.168.**.**:2181,192.168.**.**:2181
high-availability.zookeeper.path.root: /flink
high-availability.storageDir: hdfs:///flink/recoveryBy default, JobManager can be restarted only once in case of a failure after high availability is enabled. If you want to allow JobManager to be restarted more than once, you must configure the yarn.resourcemanager.am.max-attempts parameter for YARN and the yarn.application-attempts parameter for Flink. For more information, see Apache Flink official documentation. To prevent JobManager from being repeatedly restarted, you can increase the value of the yarn.application-attempt-failures-validity-interval parameter. The default value of this parameter is 10000. Unit: milliseconds. The default value indicates 10 seconds. You can increase the value of this parameter to 300000, which is equal to 5 minutes.
How do I view the metrics of a Flink job?
Log on to the EMR console and go to the Monitoring tab of the cluster that you want to manage. On the Monitoring tab, click Metric Monitoring.
Select FLINK from the Dashboard drop-down list.
Select the application ID and job ID. The metrics of the Flink job are displayed.
NoteThe application IDs and job IDs are available only when existing Flink jobs are running on the cluster.
The output information of some metrics, such as the sourceIdleTime metric, is available only when the source and sink are configured for the metrics.
How do I troubleshoot the issues that are related to upstream and downstream storage?
For more information, see Upstream and downstream storage.
What do I do if an error is reported when I run a Flink job in a Dataflow cluster to read data from and write data to OSS without a password?
Resolve the error based on the specific error message.
Error message:
java.lang.UnsupportedOperationException: Recoverable writers on Hadoop are only supported for HDFSCause: Dataflow clusters use the built-in JindoSDK to implement password-free access to Object Storage Service (OSS) and support APIs such as StreamingFileSink. You do not need to perform additional configurations as described in community documentation. Otherwise, this error may occur due to dependency conflicts.
Solution: Check whether the oss-fs-hadoop directory exists in the $FLINK_HOME/plugins directory of the node that is used to submit the job in your cluster. If the oss-fs-hadoop directory exists, delete the directory and submit the job again.
Error message:
Could not find a file system implementation for scheme 'oss'. The scheme is directly supported by Flink through the following plugin: flink-oss-fs-hadoop. ....Cause: In clusters of EMR V3.40 and earlier versions, the JAR packages related to Jindo may be missing on nodes except master-1-1 in the master server group.
Solution:
In clusters of EMR V3.40.0 or clusters of a minor version earlier than EMR V3.40.0, check whether JAR packages related to Jindo, such as jindo-flink-4.0.0-full.jar, exist in the $FLINK_HOME/lib directory of the node that is used to submit the job in your cluster. If the JAR packages related to Jindo do not exist, run the following command in the cluster to copy the JAR packages related to Jindo to the $FLINK_HOME/lib directory and then submit the job again:
cp /opt/apps/extra-jars/flink/jindo-flink-*-full.jar $FLINK_HOME/libMinor versions later than EMR V3.40.0
Flink on YARN mode: The mechanism for OSS access is optimized. Even if the JAR packages related to Jindo do not exist in the $FLINK_HOME/lib directory, the jobs used to read data from and write data to OSS can run as expected.
Other deployment modes: Check whether JAR packages related to Jindo, such as jindo-flink-4.0.0-full.jar, exist in the $FLINK_HOME/lib directory of the node that is used to submit the job in your cluster. If the JAR packages related to Jindo do not exist, run the following command in the cluster to copy the JAR packages related to Jindo to the $FLINK_HOME/lib directory and then submit the job again:
cp /opt/apps/extra-jars/flink/jindo-flink-*-full.jar $FLINK_HOME/lib
What do I do if the following error message is returned: java.util.concurrent.TimeoutException: Heartbeat of TaskManager with id timed out?
Cause
The direct cause is that the TaskManager heartbeat times out. You can view the specific error in the TaskManager logs to identify the cause. In addition, an out of memory (OOM) error may occur due to the limited heap memory size of TaskManager or memory leaks in the job code. For more information, see What do I do if the following error message is returned: java.lang.OutOfMemoryError: GC overhead limit exceeded?
Solution
If an OOM error occurs, increase the memory size or analyze the memory usage of the job to further identify the cause.
What do I do if the following error message is returned: java.lang.OutOfMemoryError: GC overhead limit exceeded?
Cause
This error message indicates that garbage collection (GC) times out because the memory that is configured for the job is insufficient. A common cause is that the job code, such as user-defined functions (UDFs), causes a memory leak or the memory size does not meet the business requirements.
Solution
When you submit the job again to reproduce the error, use the -D parameter to specify the JVM parameter for creating a heap dump upon an OOM error. Example:
-D env.java.opts="-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp/dump.hprof".Add the
env.java.opts: -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp/dump.hprofparameter to the flink-conf.yaml file to create a heap dump upon an OOM error.
After the error is reproduced, analyze the heap dump file in the path specified by the HeapDumpPath parameter. For example, you can use Memory Analyzer Tool (MAT) or Java VisualVM to analyze the file and identify the root cause of the error.
Why only one operator is displayed for a job in the Flink web UI and the value of the Records Received metric is 0?
This is a normal situation. The Records Received metric of Flink is used to indicate data communication between different operators. If a job is optimized to have only one operator, the value of this metric is always 0.
How do I enable a flame graph for a Flink job?
Flame graphs visualize the CPU load of each method in a process. This helps you resolve the performance bottleneck issues of Flink jobs. The flame graph feature is supported since Flink 1.13. However, to avoid the impact of flame graphs on jobs in the production environment, the flame graph feature is disabled by default. If you want to use the flame graph feature to analyze the performance of Flink jobs, perform the following operations: Log on to the EMR console and go to the Configure tab of the Flink service page. On the Configure tab, click flink-conf.yaml. On the flink-conf.yaml tab, add the rest.flamegraph.enabled configuration item and set the value to true. For more information about how to add a configuration item, see Manage configuration items.
For more information about flame graphs, see Flame Graphs.
What do I do if the following error message is returned: Exception in thread "main" java.lang.NoSuchFieldError: DEPLOYMENT_MODE?
Cause
The JAR package of your job contains a flink-core dependency that is incompatible with the version of Flink in the cluster.
Solution
Add the following dependency to the pom.xml file. In this dependency, the
scopeparameter is set toprovided.<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-core</artifactId> <!-- Change to your own flink version --> <version>1.16.1</version> <scope>provided</scope> </dependency>NoteChange the
versionin the preceding dependency to the version of Flink that you use.For more information about how the incompatible dependency is introduced, see What do I do if a JAR package of a job conflicts with a JAR package of the Flink in a cluster?.