If your business workloads fluctuate, we recommend that you enable auto scaling for your E-MapReduce (EMR) cluster and configure auto scaling rules to increase or decrease task nodes based on your business requirements. Auto scaling helps reduce costs and ensures sufficient computing resources for your jobs. This topic describes how to configure auto scaling in the EMR console.
Prerequisites
An EMR Hadoop cluster is created. For more information, see Create a cluster.
Precautions
You can specify the hardware specifications of the nodes that are used to scale in or scale out a cluster. You can configure the hardware specifications only when auto scaling is disabled. If modifications are required in specific scenarios, disable auto scaling, modify the hardware specifications, and then enable auto scaling again.
The system automatically searches for the instance types that match the vCPU and memory specifications you specified and displays the instance types in the Instance Type section. You must select one or more instance types in the Instance Type section. This way, the cluster can be scaled based on the selected instance types.
You can select up to three instance types. This prevents auto scaling failures due to insufficient Elastic Compute Service (ECS) resources.
The minimum size of a data disk is 40 GiB regardless of whether you select an ultra disk or a standard SSD.
Load-based scaling is a feature based on CloudMonitor and allows you to dynamically manage auto scaling groups. After you configure auto scaling rules, CloudMonitor automatically creates corresponding alert rules. To ensure the smooth running of EMR auto scaling activities, do not modify, delete, or disable the alert rules that are created by CloudMonitor.
Procedure
Go to the Auto Scaling tab.
Log on to the EMR console. In the left-side navigation pane, click EMR on ECS.
In the top navigation bar, select the region where your cluster resides and select a resource group based on your business requirements.
On the EMR on ECS page, find the desired cluster and click the name of the cluster in the Cluster ID/Name column.
On the page that appears, click the Auto Scaling tab.
Create an auto scaling group.
On the Configure Scaling tab, click Create Auto Scaling Group.
NoteYou can configure and manage auto scaling groups only on the Auto Scaling tab.
In the Add Auto Scaling Group dialog box, enter a name in the Node Group Name field and click OK.
On the Configure Scaling tab, find the created auto scaling group and click Configure Rule in the Actions column.
In the Basic Information section of the Configure Auto Scaling panel, configure the parameters. The following table describes the parameters.
Parameter
Description
Maximum Number of Instances
The maximum number of task nodes in the auto scaling group. If an auto scaling rule is met but the upper limit is reached, the system does not trigger auto scaling. Maximum value: 1000.
Minimum Number of Instances
The minimum number of task nodes in the auto scaling group. If the number of task nodes that are configured in an auto scaling rule is less than the value of this parameter, the cluster is scaled based on the value of this parameter the first time the rule is triggered.
For example, if this parameter is set to 3 and a scale-out rule is that one node is added at 00:00 every day, the system adds three nodes at 00:00 on the first day. This way, the requirement for the minimum number of nodes is met.
Graceful Shutdown
The timeout period to deprecate the task node on which a job on YARN runs. If the period of time for which a job on YARN has run exceeds the timeout period or no job on YARN has run, the system deprecates the task node. The maximum value of Timeout Period is 3600, in seconds.
ImportantTo enable graceful shutdown, you must first change the value of the yarn.resourcemanager.nodes.exclude-path parameter on the YARN service page to /etc/ecm/hadoop-conf/yarn-exclude.xml.
After you change the value of Timeout Period, restart YARN ResourceManager during off-peak hours for the modification to take effect.
In the middle part of the Configure Auto Scaling panel, configure the following parameters: Instance Type Selection Mode, Billing Method, and Instance Type.
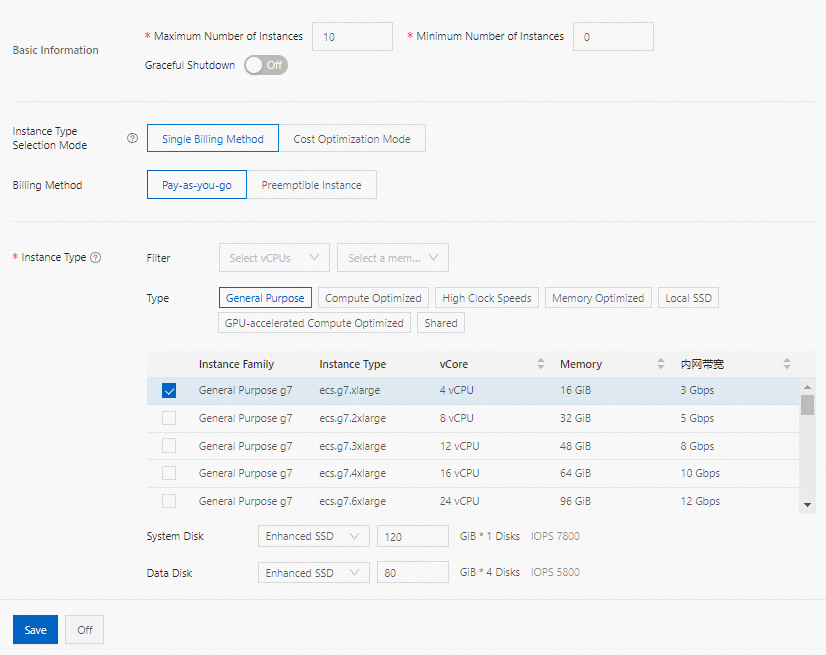
Single Billing Method
The system automatically searches for the instance types that match the vCPU and memory specifications you specified and displays the instance types in the Instance Type section. You must select one or more instance types in the Instance Type section so that the cluster can be scaled based on the selected instance types. Single Billing Method supports the following billing methods:
Pay-as-you-go
The order in which you select instance types determines the priorities of the instances that are used. The hourly price of each instance is displayed below the disk specifications in the Instance Type section. The price is the sum of the EMR service price and ECS instance price.
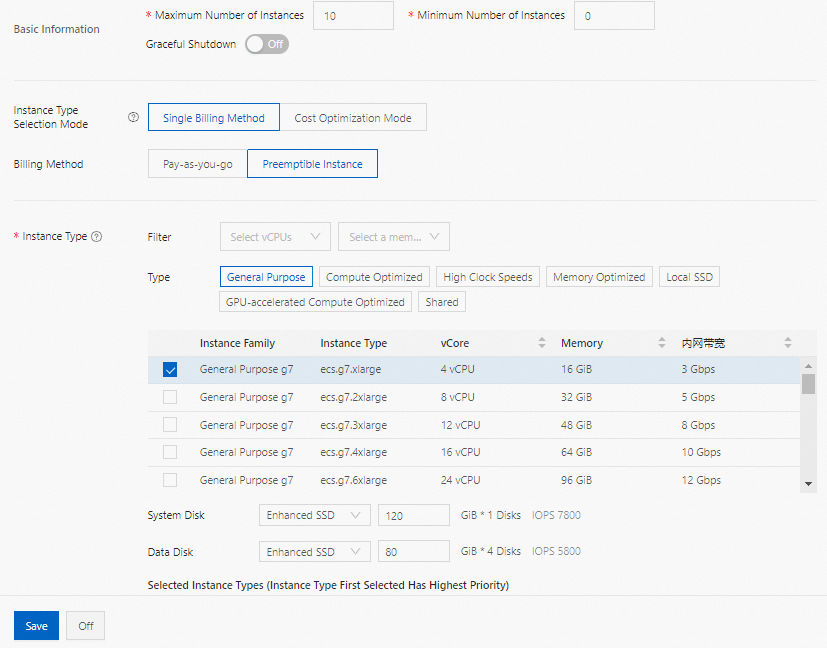
Preemptible Instance
ImportantIf you have high service level agreement (SLA) requirements for your jobs, do not select this option to use preemptible instances because the instances may be released due to a failed bid or other reasons.
The order in which you select instance types determines the priorities of the instances that are used. The hourly price of each instance based on the pay-as-you-go billing method is displayed below the disk specifications in the Instance Type section. You can also specify an upper limit for the hourly price of each instance. The instance is displayed if its price does not exceed the upper limit. For more information about preemptible instances, see What are preemptible instances?
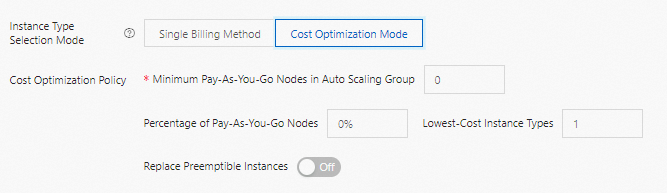
Cost Optimization Mode
In this mode, you can develop a detailed cost optimization policy to achieve a balance between cost and stability.
Parameter
Description
Minimum Pay-As-You-Go Nodes in Auto Scaling Group
The minimum number of pay-as-you-go instances required by the auto scaling group. If the number of pay-as-you-go instances in the auto scaling group is less than the value of this parameter, pay-as-you-go instances are preferentially created.
Percentage of Pay-As-You-Go Nodes
The proportion of pay-as-you-go instances in the auto scaling group after the number of created pay-as-you-go instances reaches the value of the Minimum Pay-As-You-Go Nodes in Auto Scaling Group parameter.
Lowest-Cost Instance Types
The number of instance types that have the lowest prices. If preemptible instances are required, the system evenly creates the preemptible instances of the instance types that have the lowest prices. Maximum value: 3.
Replace Preemptible Instances
Specifies whether to enable preemptible instance supplementation. If this feature is enabled, the system automatically replaces the current preemptible instance with a pay-as-you-go instance approximately 5 minutes before the preemptible instance is reclaimed.
If you do not configure the Minimum Pay-As-You-Go Nodes in Auto Scaling Group, Percentage of Pay-As-You-Go Nodes, or Lowest-Cost Instance Types parameter, the group is a common cost optimization scaling group. If you configure the parameters, the group is a mixed-instance cost optimization scaling group. The two types of cost optimization scaling groups are fully compatible with each other in terms of interfaces and features.
You can use a mixed-instance cost optimization scaling group to achieve the same effect as a specific common cost optimization scaling group by configuring appropriate mixed-instance policies. Examples:
In a common cost optimization scaling group, only pay-as-you-go instances are created.
In your mixed-instance cost optimization scaling group, set Minimum Pay-As-You-Go Nodes in Auto Scaling Group to 0, Percentage of Pay-As-You-Go Nodes to 100%, and Lowest-Cost Instance Types to 1.
In a common cost optimization scaling group, preemptible instances are preferentially created.
In your mixed-instance cost optimization scaling group, set Minimum Pay-As-You-Go Nodes in Auto Scaling Group to 0, Percentage of Pay-As-You-Go Nodes to 0%, and Lowest-Cost Instance Types to 1.
In the lower part of the Configure Auto Scaling panel, configure the Trigger Mode and Trigger Rule parameters.
Time-based Scaling: If the computing workloads of the Hadoop cluster fluctuate on a regular basis, you can add and remove a specific number of task nodes at fixed points in time every day, every week, or every month to supplement or save the computing resources. This ensures that jobs can be complete at low costs.
Auto scaling rules are divided into scale-out rules and scale-in rules. The following table describes the parameters for a scale-out rule. If you disable auto scaling for a cluster, all auto scaling rules are cleared. If you enable auto scaling for the cluster again, you must reconfigure auto scaling rules.
Parameter
Description
Rule Name
The name of the scale-out rule. The names of auto scaling rules must be unique in a cluster.
Execution Rule
Execute Repeatedly: Auto scaling is performed at a specific point in time every day, every week, or every month.
Execute Only Once: Auto scaling is performed only once at a specific point in time.
Execution Time
The specific point in time at which the scale-out rule is executed.
Rule Expiration Time
The expiration time of the scale-out rule.
Retry Time Range
The retry interval. Auto scaling may fail at the specified point in time due to various reasons. If the retry interval is specified, the system retries auto scaling every 30 seconds during the retry interval specified by this parameter until auto scaling is performed. Valid values: 0 to 21600. Unit: seconds.
For example, auto scaling operation A needs to be performed within a specified period of time. If auto scaling operation B is still in progress or is in the cooldown state during this period, operation A cannot be performed. In this case, the system tries to perform operation A every 30 seconds within the retry interval you specified. If required conditions are met, the cluster immediately performs auto scaling.
Number of Adjusted Instances
The number of task nodes that are added to the cluster each time the scale-out rule is triggered.
Cooldown Time (s)
The interval between two scale-out activities. Scale-out activities are forbidden during the cooldown.
Load-based Scaling: You can add load-based scaling rules for task node groups in a cluster for which you cannot accurately estimate the fluctuation of big data computing workloads.
Auto scaling rules are divided into scale-out rules and scale-in rules. The following table describes the parameters for a scale-out rule. If you disable auto scaling for a cluster, all auto scaling rules are cleared. If you enable auto scaling for the cluster again, you must reconfigure auto scaling rules. If you switch the scaling policy, such as from load-based scaling to time-based scaling, the auto scaling rules that you added to the original scaling policy are invalid and cannot be triggered. The nodes that are added based on the rules are retained and are not released.
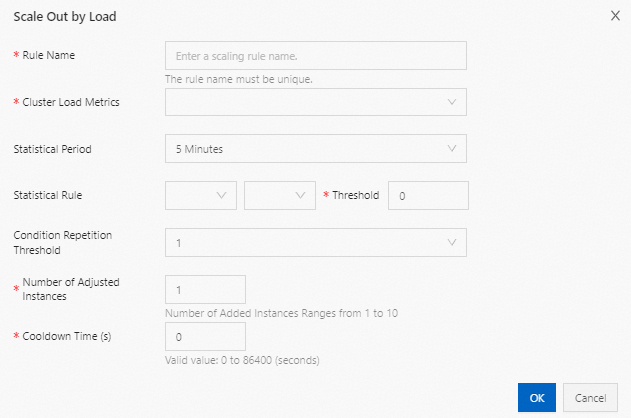
Parameter
Description
Rule Name
The name of the scale-out rule. The names of auto scaling rules must be unique in a cluster.
Cluster Load Metrics
The load metric of the current cluster. The load metrics are obtained from YARN. For more information, see Hadoop official documentation.
For information about the mappings between EMR auto scaling metrics and YARN load metrics, see Description of EMR auto scaling metrics that match YARN load metrics.
Statistical Period
The statistical period for measuring whether the value of the specified aggregation dimension (average, maximum, or minimum) for the specified cluster load metric reaches the threshold.
Statistical Rule
Condition Repetition Threshold
The required number of times that the value of the specified aggregation dimension for the specified cluster load metric reaches the threshold before the scale-out rule can be triggered.
Number of Adjusted Instances
The number of task nodes that are added to the cluster each time the scale-out rule is triggered.
Cooldown Time (s)
The interval between two scale-out activities. During the cooldown time, the scale-out rule is not triggered even if the scale-out conditions are met. A scale-out activity is performed after the cooldown time ends and the scale-out conditions are met again.
Click Save.
You can enable auto scaling based on your business requirements. For more information about how to enable auto scaling, see Enable or disable auto scaling (Hadoop clusters).
Description of EMR auto scaling metrics that match YARN load metrics
EMR auto scaling metric | Service | Description |
YARN.AvailableVCores | YARN | The number of available vCPUs. |
YARN.PendingVCores | YARN | The number of to-be-allocated vCPUs. |
YARN.AllocatedVCores | YARN | The number of allocated vCPUs. |
YARN.ReservedVCores | YARN | The number of reserved vCPUs. |
YARN.AvailableMemory | YARN | The amount of available memory. Unit: MB. |
YARN.PendingMemory | YARN | The amount of to-be-allocated memory. Unit: MB. |
YARN.AllocatedMemory | YARN | The amount of allocated memory. Unit: MB. |
YARN.ReservedMemory | YARN | The amount of reserved memory. Unit: MB. |
YARN.AppsRunning | YARN | The number of running tasks. |
YARN.AppsPending | YARN | The number of pending tasks. |
YARN.AppsKilled | YARN | The number of terminated tasks. |
YARN.AppsFailed | YARN | The number of failed tasks. |
YARN.AppsCompleted | YARN | The number of completed tasks. |
YARN.AppsSubmitted | YARN | The number of submitted tasks. |
YARN.AllocatedContainers | YARN | The number of allocated containers. |
YARN.PendingContainers | YARN | The number of to-be-allocated containers. |
YARN.ReservedContainers | YARN | The number of reserved containers. |
YARN.MemoryAvailablePrecentage | YARN | The percentage of remaining memory to total memory, which is calculated by using the following formula: |
YARN.ContainerPendingRatio | YARN | The ratio of to-be-allocated containers to allocated containers, which is calculated by using the following formula: |